SCOPE: Scale-Consistent One-Pass Estimation of 3D Geometry
Pith reviewed 2026-06-26 14:45 UTC · model grok-4.3
The pith
SCOPE produces consistent 3D point maps from long monocular videos by sharing parameters across the full sequence to enforce scale invariance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
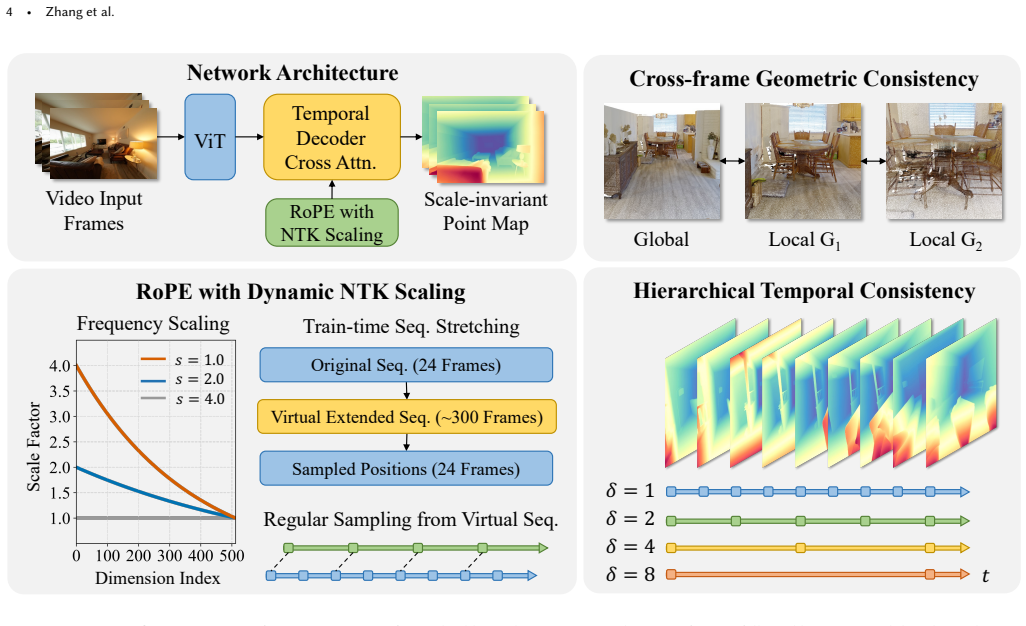
SCOPE generates affine-invariant 3D point maps with shared parameters across entire sequences, enabling consistent scale-invariant representations. Viewpoint-invariant geometry aligns multi-perspective points in a unified reference frame, appearance-invariant learning enforces consistency across exponential timescales, and frequency-modulated positioning enables extrapolation to sequences that greatly exceed training length.
What carries the argument
affine-invariant 3D point maps generated with parameters shared across the full video sequence
If this is right
- Relative point map error drops 24.2 percent and temporal alignment error drops 34.9 percent on ScanNet versus prior methods.
- The single shared-parameter model processes extended sequences in one forward pass without accumulating drift.
- Frequency-modulated positioning lets the model handle videos far longer than the length used during training.
- The same model works on sequences with complex trajectories and varying illumination without separate retraining.
Where Pith is reading between the lines
- If the shared-parameter maps remain stable, downstream tasks such as visual odometry could run continuously without periodic bundle adjustment.
- The approach might reduce reliance on stereo or multi-view input for long indoor mapping by making monocular video sufficient.
- Appearance-invariant consistency over exponential timescales could be tested on video with sudden scene changes to see whether the invariance generalizes beyond the reported datasets.
Load-bearing premise
Viewpoint-invariant alignment and appearance-invariant learning will keep geometric accuracy and temporal consistency intact across hundreds of frames even under complex motion and lighting changes.
What would settle it
Run the method on a 300-frame monocular sequence with rapid lighting shifts and erratic camera motion; if relative point map error or temporal alignment error exceeds the best prior method after frame 150, the consistency claim does not hold.
Figures



read the original abstract
We present SCOPE (Scale-Consistent One-Pass Estimation of 3D Geometry), a novel approach for estimating 3D geometry from extended monocular video sequences, where existing methods struggle to maintain both geometric accuracy and temporal consistency across hundreds of frames. Our approach generates affine-invariant 3D point maps with shared parameters across entire sequences, enabling consistent scale-invariant representations. We introduce three key innovations: viewpoint-invariant geometry aligning multi-perspective points in a unified reference frame; appearance-invariant learning enforcing consistency across exponential timescales; and frequency-modulated positioning enabling extrapolation to sequences vastly exceeding training length. Experiments across diverse datasets demonstrate significant improvements, reducing relative point map error by 24.2% and temporal alignment error by 34.9% on ScanNet compared to state-of-the-art methods. Our approach handles challenging scenarios with complex camera trajectories and lighting variations while efficiently processing extended sequences in a single pass. Project page: https://scope3d.github.io/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents SCOPE, a method for one-pass estimation of 3D geometry from extended monocular video sequences. It produces affine-invariant 3D point maps using shared parameters across sequences via three innovations: viewpoint-invariant geometry to align multi-perspective points, appearance-invariant learning for consistency across exponential timescales, and frequency-modulated positioning for extrapolation beyond training lengths. On ScanNet it reports 24.2% lower relative point map error and 34.9% lower temporal alignment error versus prior state-of-the-art, while handling complex trajectories and lighting in a single pass.
Significance. If the empirical claims are substantiated by the full methods and experiments, the work would address a recognized limitation in monocular video 3D reconstruction—drift and scale inconsistency over hundreds of frames—by enforcing shared parameters and multi-timescale consistency. The one-pass efficiency and reported gains on standard benchmarks would be of practical interest to the community.
Simulated Author's Rebuttal
We thank the referee for their summary of the manuscript and for the positive assessment of its potential significance in addressing scale inconsistency and drift in extended monocular video 3D reconstruction. The recommendation of 'uncertain' appears to stem from the need to confirm that the reported empirical gains are fully supported by the methods and experiments. No specific major comments were listed in the report, so we have no point-by-point items to address. We remain available to supply any additional details from the full manuscript that would resolve the uncertainty.
Circularity Check
No derivation chain or equations present; empirical results only
full rationale
The abstract and available text present only high-level claims of empirical improvements (e.g., error reductions on ScanNet) with no equations, derivations, fitted parameters, or self-citations forming a load-bearing chain. No mathematical steps exist that could reduce to inputs by construction, making circularity analysis inapplicable. The paper is self-contained as an empirical method description without internal derivation that requires verification for circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
CVPR , year=
MoGe: Unlocking Accurate Monocular Geometry Estimation for Open-Domain Images with Optimal Training Supervision , author=. CVPR , year=
-
[2]
NeurIPS , year=
MoGe-2: Accurate Monocular Geometry with Metric Scale and Sharp Details , author=. NeurIPS , year=
-
[3]
Wang, Yifan and Zhou, Jianjun and Zhu, Haoyi and Chang, Wenzheng and Zhou, Yang and Li, Zizun and Chen, Junyi and Pang, Jiangmiao and Shen, Chunhua and He, Tong , booktitle=
-
[4]
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second , booktitle =
Aleksei Bochkovskii and Ama\". Depth Pro: Sharp Monocular Metric Depth in Less Than a Second , booktitle =
-
[5]
ICCV , year=
Enforcing geometric constraints of virtual normal for depth prediction , author=. ICCV , year=
-
[6]
TPAMI , year=
Virtual Normal: Enforcing Geometric Constraints for Accurate and Robust Depth Prediction , author=. TPAMI , year=
-
[7]
ICCV , year =
Wang, Yiran and Shi, Min and Li, Jiaqi and Huang, Zihao and Cao, Zhiguo and Zhang, Jianming and Xian, Ke and Lin, Guosheng , title =. ICCV , year =
-
[8]
TPAMI , year=
Wang, Yiran and Shi, Min and Li, Jiaqi and Hong, Chaoyi and Huang, Zihao and Peng, Juewen and Cao, Zhiguo and Zhang, Jianming and Xian, Ke and Lin, Guosheng , title=. TPAMI , year=
-
[9]
CVPR , year=
Video Depth Anything: Consistent Depth Estimation for Super-Long Videos , author=. CVPR , year=
-
[10]
CVPR , year=
Buffer Anytime: Zero-Shot Video Depth and Normal from Image Priors , author=. CVPR , year=
-
[11]
CVPR , year =
Hu, Wenbo and Gao, Xiangjun and Li, Xiaoyu and Zhao, Sijie and Cun, Xiaodong and Zhang, Yong and Quan, Long and Shan, Ying , title =. CVPR , year =
-
[12]
CVPR , year=
VGGT: Visual Geometry Grounded Transformer , author=. CVPR , year=
-
[13]
TMLR , year=
Dinov2: Learning robust visual features without supervision , author=. TMLR , year=
-
[14]
ICLR , year =
Honghui Yang and Di Huang and Wei Yin and Chunhua Shen and Haifeng Liu and Xiaofei He and Binbin Lin and Wanli Ouyang and Tong He , title =. ICLR , year =
-
[15]
CVPR , year=
Video Depth without Video Models , author=. CVPR , year=
-
[16]
CVPR , year=
Learning Temporally Consistent Video Depth from Video Diffusion Priors , author=. CVPR , year=
-
[17]
Roformer: Enhanced transformer with rotary position embedding , author=. arXiv:2104.09864 , year=
-
[18]
A length-extrapolatable transformer , author=. arXiv:2212.10554 , year=
-
[19]
Extending context window of large language models via positional interpolation , author=. arXiv:2306.15595 , year=
-
[20]
Ntk-aware scaled rope allows llama models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation , author=
-
[21]
NeurIPS , year=
Depth map prediction from a single image using a multi-scale deep network , author=. NeurIPS , year=
-
[22]
CVPR , year=
Deep ordinal regression network for monocular depth estimation , author=. CVPR , year=
-
[23]
Zoedepth: Zero-shot transfer by combining relative and metric depth , author=. arXiv:2302.12288 , year=
-
[24]
CVPR , year=
Adabins: Depth estimation using adaptive bins , author=. CVPR , year=
-
[25]
TPAMI , year=
Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer , author=. TPAMI , year=
-
[26]
1--A Model Zoo for Robust Monocular Relative Depth Estimation , author=
MiDaS v3. 1--A Model Zoo for Robust Monocular Relative Depth Estimation , author=. arXiv:2307.14460 , year=
-
[27]
ICCV , year=
Vision transformers for dense prediction , author=. ICCV , year=
-
[28]
ICCV , year=
Metric3D: Towards zero-shot metric 3d prediction from a single image , author=. ICCV , year=
-
[29]
TPAMI , year=
Metric3d v2: A versatile monocular geometric foundation model for zero-shot metric depth and surface normal estimation , author=. TPAMI , year=
-
[30]
NeurIPS , year=
Depth Anything V2 , author=. NeurIPS , year=
-
[31]
CVPR , year=
Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data , author=. CVPR , year=
-
[32]
CVPR , year=
Repurposing diffusion-based image generators for monocular depth estimation , author=. CVPR , year=
-
[33]
DepthFM: Fast Monocular Depth Estimation with Flow Matching , author=. arXiv:2403.13788 , year=
-
[34]
GeoWizard: Unleashing the Diffusion Priors for 3D Geometry Estimation from a Single Image , author=. arXiv:2403.12013 , year=
-
[35]
CVPR , year=
Learning to recover 3d scene shape from a single image , author=. CVPR , year=
-
[36]
CVPR , year=
UniDepth: Universal Monocular Metric Depth Estimation , author=. CVPR , year=
-
[37]
UniDepthV2: Universal Monocular Metric Depth Estimation Made Simpler , author=. arXiv:2502.20110 , year=
-
[38]
Bowen Peng and Jeffrey Quesnelle and Honglu Fan and Enrico Shippole , booktitle=. Ya
-
[39]
and Kaiser, Łukasz and Polosukhin, Illia , title =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser, Łukasz and Polosukhin, Illia , title =. NeurIPS , year =
-
[40]
Harley and Bokui Shen and Gordon Wetzstein and Leonidas J
Yang Zheng and Adam W. Harley and Bokui Shen and Gordon Wetzstein and Leonidas J. Guibas , title =. ICCV , year =
-
[41]
IROS , year=
Tartanair: A dataset to push the limits of visual slam , author=. IROS , year=
- [42]
-
[43]
ICCV , year=
Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding , author=. ICCV , year=
-
[44]
ECCV , year=
Long-term Human Motion Prediction with Scene Context , author=. ECCV , year=
-
[45]
CVPR , year =
Huang, Po-Han and Matzen, Kevin and Kopf, Johannes and Ahuja, Narendra and Huang, Jia-Bin , title =. CVPR , year =
-
[46]
Flow-Motion and Depth Network for Monocular Stereo and Beyond , author=. arXiv:1909.05452 , year=
arXiv 1909
-
[47]
ICME , year=
Irs: A large naturalistic indoor robotics stereo dataset to train deep models for disparity and surface normal estimation , author=. ICME , year=
-
[48]
CVPRW , year =
Michael Fonder and Marc Van Droogenbroeck , title =. CVPRW , year =
-
[49]
CVPR , year =
Lukas Mehl and Jenny Schmalfuss and Azin Jahedi and Yaroslava Nalivayko and Andr\'es Bruhn , title =. CVPR , year =
-
[50]
LightwheelOcc: A 3D Occupancy Synthetic Dataset in Autonomous Driving , author=
-
[51]
CVPR , year =
Fabio Tosi and Yiyi Liao and Carolin Schmitt and Andreas Geiger , title =. CVPR , year =
-
[52]
ECCV , year =
A naturalistic open source movie for optical flow evaluation , author =. ECCV , year =
-
[53]
CVPR , year =
ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes , author=. CVPR , year =
-
[54]
CVPR , year=
Scannet++: A high-fidelity dataset of 3d indoor scenes , author=. CVPR , year=
-
[55]
Perazzi, Federico and Pont-Tuset, Jordi and McWilliams, Brian and Van Gool, Luc and Gross, Markus and Sorkine-Hornung, Alexander , booktitle=
-
[56]
Palazzolo and J
E. Palazzolo and J. Behley and P. Lottes and P. Gigu\`ere and C. Stachniss , title =. IROS , year =
-
[57]
IJRR , year =
Andreas Geiger and Philip Lenz and Christoph Stiller and Raquel Urtasun , title =. IJRR , year =
-
[58]
CVPR , year =
Vitor Guizilini and Rares Ambrus and Sudeep Pillai and Allan Raventos and Adrien Gaidon , title =. CVPR , year =
-
[59]
CVPR , year=
Dust3r: Geometric 3d vision made easy , author=. CVPR , year=
-
[60]
Zhang, Junyi and Herrmann, Charles and Hur, Junhwa and Jampani, Varun and Darrell, Trevor and Cole, Forrester and Sun, Deqing and Yang, Ming-Hsuan , booktitle=
-
[61]
CVPR , year =
MegaSaM: Accurate, Fast and Robust Structure and Motion from Casual Dynamic Videos , author =. CVPR , year =
-
[62]
CVPR , year =
Shotton, Jamie and Glocker, Ben and Zach, Christopher and Izadi, Shahram and Criminisi, Antonio and Fitzgibbon, Andrew , title =. CVPR , year =
-
[63]
, booktitle =
Murai, Riku and Dexheimer, Eric and Davison, Andrew J. , booktitle =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.