MetaWorld: Scaling Multi-Agent Video World Model from Single-view Video Data
Pith reviewed 2026-06-28 14:50 UTC · model grok-4.3
The pith
MetaWorld generates consistent multi-agent videos in shared 3D spaces directly from ordinary single-view footage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
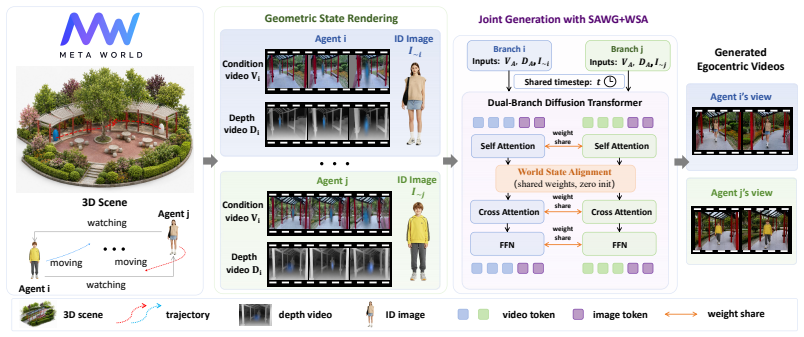
MetaWorld shows that monocular footage can be unrolled via MWSU into camera ego-motion and visible-subject trajectories to produce aligned multi-agent motion data; a Subject-Aware World Generator supplies per-agent identity control; and World-State Alignment applies per-frame inter-branch cross-attention inside every transformer layer of the video DiT to enforce both static geometric and dynamic motion consistency across the resulting egocentric views.
What carries the argument
Monocular World-State Unrolling (MWSU) that decomposes single-view video into ego-motion and subject trajectory, combined with World-State Alignment (WSA) cross-attention inserted at every layer of the video DiT.
If this is right
- Training data for multi-agent world models can be drawn from the vast existing pool of single-view videos instead of rare multi-camera recordings.
- Generated videos maintain both static scene geometry and dynamic physical events across independent agent viewpoints.
- Per-agent identity images allow appearance-driven control while preserving cross-view identity fidelity.
- The resulting models operate in open-domain environments without requiring explicit 3D supervision or multi-view capture hardware.
Where Pith is reading between the lines
- If the decomposition step generalizes beyond two agents, the same pipeline could support larger coordinated groups from single cameras.
- Downstream tasks such as multi-robot planning or interactive simulation could use the aligned outputs as drop-in consistent world simulators.
- Accuracy of the initial 3D trajectory extraction becomes the practical limit; failures in crowded or fast-moving scenes would directly limit scalability.
Load-bearing premise
Monocular video can be decomposed into the camera operator's ego-motion and the visible subject's spatial trajectory to obtain synchronized multi-agent motion data inside one shared 3D space.
What would settle it
Generate paired egocentric videos from the same single-view input and measure whether object positions, contact events, or trajectories remain consistent across the two outputs when viewed in 3D reconstruction; large discrepancies would falsify the alignment claim.
Figures






read the original abstract
Video world models are a foundational generative technology for embodied AI and the Metaverse, yet existing approaches are inherently limited to a single agent observing from a single perspective. Extending these models to multi-agent settings introduces two critical challenges: data scarcity (coordinated multi-view recordings are prohibitively expensive to collect for general open-domain scenarios) and world state alignment (independently generated video streams cannot ensure that shared physical environments and events evolve consistently across views). To address these challenges, we propose MetaWorld, a novel framework that scales multi-agent video world models to open-domain environments directly from single-view videos. First, we introduce Monocular World-State Unrolling (MWSU) to explicitly decompose monocular footage into the camera operator's ego-motion and the visible subject's spatial trajectory. This camera-trajectory decomposition naturally extracts synchronized multi-agent motion data within a shared 3D space, completely bypassing the need for multi-camera setups. Second, for precise visual control, we develop the Subject-Aware World Generator to enable appearance-driven simulation conditioned on per-agent identity images. Finally, to ensure both views are grounded in the identical physical reality, we propose World-State Alignment, a per-frame inter-branch cross-attention mechanism inserted at every transformer layer of the video DiT. By jointly synchronizing the denoising process, WSA enforces both static geometric consistency and dynamic motion consistency, encouraging that the shared 3D environment and physical events remain well-aligned across both egocentric views. Extensive experiments demonstrate that MetaWorld achieves superior cross-view consistency and identity fidelity, establishing a highly scalable, physics-driven paradigm for multi-agent video world modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce MetaWorld, a framework for scaling multi-agent video world models directly from single-view videos. It proposes Monocular World-State Unrolling (MWSU) to decompose monocular footage into camera ego-motion and subject spatial trajectories (thereby extracting synchronized multi-agent 3D motion data without multi-camera setups), a Subject-Aware World Generator for appearance-conditioned simulation, and World-State Alignment (WSA) via per-frame inter-branch cross-attention inserted at every transformer layer of a video DiT to enforce static geometric and dynamic motion consistency across egocentric views. The abstract asserts that extensive experiments demonstrate superior cross-view consistency and identity fidelity.
Significance. If the MWSU decomposition proves sufficiently accurate and WSA successfully compensates for any residual trajectory noise, the approach could meaningfully advance scalable, physics-driven multi-agent video world modeling for embodied AI and Metaverse applications by removing the need for coordinated multi-view recordings.
major comments (2)
- [§3.1] §3.1 (MWSU): the claim that the decomposition “naturally extracts” synchronized multi-agent motion data within a shared 3D space is load-bearing for all downstream consistency claims, yet the manuscript supplies no error bounds, ground-truth 3D validation protocol, or ablation on how WSA tolerates upstream trajectory noise; monocular ego-motion + multi-agent trajectory recovery remains classically underconstrained.
- [Experiments / abstract] Experiments / abstract: the central claims of “superior cross-view consistency and identity fidelity” are stated without any reported quantitative metrics, ablation studies, baseline comparisons, or implementation details, so it is impossible to assess whether the proposed mechanisms actually deliver the asserted improvements.
minor comments (2)
- [§3.3] The description of WSA as “per-frame inter-branch cross-attention inserted at every transformer layer” would benefit from an explicit equation or diagram showing the attention mask and how the two branches are synchronized during denoising.
- [§3.2] Notation for the Subject-Aware World Generator (e.g., how identity images are injected) is introduced at a high level; a short pseudocode block or conditioning diagram would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on MetaWorld. We address the two major comments point by point below, acknowledging where additional validation and reporting are needed.
read point-by-point responses
-
Referee: [§3.1] the claim that the decomposition “naturally extracts” synchronized multi-agent motion data within a shared 3D space is load-bearing for all downstream consistency claims, yet the manuscript supplies no error bounds, ground-truth 3D validation protocol, or ablation on how WSA tolerates upstream trajectory noise; monocular ego-motion + multi-agent trajectory recovery remains classically underconstrained.
Authors: We agree that monocular decomposition is underconstrained and that explicit validation is required to support the downstream claims. MWSU relies on off-the-shelf monocular estimators, and WSA is intended to compensate for noise via cross-attention, but the current manuscript does not provide quantitative error analysis. In revision we will add: (i) error bounds measured on synthetic multi-agent scenes with known ground-truth trajectories, (ii) a validation protocol comparing MWSU outputs against multi-view datasets, and (iii) an ablation measuring WSA robustness across increasing levels of injected trajectory noise. These additions will directly address the load-bearing nature of the decomposition. revision: yes
-
Referee: Experiments / abstract: the central claims of “superior cross-view consistency and identity fidelity” are stated without any reported quantitative metrics, ablation studies, baseline comparisons, or implementation details, so it is impossible to assess whether the proposed mechanisms actually deliver the asserted improvements.
Authors: The abstract summarizes results that appear in the experiments section, yet we accept that the current presentation omits explicit numerical values, ablations, and baseline tables, making independent assessment difficult. In the revised manuscript we will: (i) report concrete metrics for cross-view consistency (e.g., optical-flow endpoint error, LPIPS between synchronized frames) and identity fidelity (e.g., ArcFace cosine similarity, CLIP image-text alignment), (ii) include component-wise ablations, (iii) add comparisons against single-agent DiT baselines and naive multi-branch generation, and (iv) move all implementation hyperparameters and training details to a dedicated section or supplementary material. These changes will make the claimed improvements verifiable. revision: yes
Circularity Check
No circularity: claims rest on novel architectural components without self-referential reduction
full rationale
The paper proposes three new modules—MWSU for monocular decomposition, Subject-Aware World Generator for identity-conditioned simulation, and WSA cross-attention for alignment—directly from single-view video inputs. The abstract and description contain no equations, parameter-fitting procedures, or self-citations that define outputs in terms of themselves or rename fitted quantities as predictions. The derivation chain therefore remains independent of its own results and does not reduce by construction to its inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
N. N. Agarwal, A. Ali, M. Bala, et al. Cosmos world foundation model platform for physical ai. arXiv preprint arXiv:2501.03575, 2025
Pith/arXiv arXiv 2025
-
[2]
P. J. Ball, J. Bauer, F. Belletti, B. Brownfield, A. Ephrat, et al. Genie 3: A new frontier for world models. 2025
2025
-
[3]
Brooks, B
T. Brooks, B. Peebles, C. Holmes, W. DePue, Y . Guo, L. Jing, D. Schnurr, J. Tay- lor, T. Luhman, E. Luhman, C. Ng, R. Wang, and A. Ramesh. Video genera- tion models as world simulators. 2024. URL https://openai.com/research/ video-generation-models-as-world-simulators
2024
-
[4]
S. Cai, C. Yang, L. Zhang, Y . Guo, J. Xiao, Z. Yang, Y . Xu, Z. Yang, A. Yuille, L. Guibas, et al. Mixture of contexts for long video generation.arXiv preprint arXiv:2508.21058, 2025
arXiv 2025
-
[5]
Esser, S
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. Müller, H. Saini, Y . Levi, D. Lorenz, A. Sauer, F. Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. In Forty-first international conference on machine learning, 2024
2024
-
[6]
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
Pith/arXiv arXiv 2023
-
[7]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[8]
Y . Hong, Y . Mei, C. Ge, Y . Xu, Y . Zhou, S. Bi, Y . Hold-Geoffroy, M. Roberts, M. Fisher, E. Shechtman, et al. Relic: Interactive video world model with long-horizon memory.arXiv preprint arXiv:2512.04040, 2025
arXiv 2025
-
[9]
T. Hu, Z. Yu, G. Zhang, Z. Su, Z. Zhou, Y . Zhang, Y . Zhou, Q. Lu, and R. Yi. Harmony: Harmo- nizing audio and video generation through cross-task synergy.arXiv preprint arXiv:2511.21579, 2025
arXiv 2025
-
[10]
T. Hu, Z. Yu, Z. Zhou, S. Liang, Y . Zhou, Q. Lin, and Q. Lu. Hunyuancustom: A multimodal- driven architecture for customized video generation.arXiv preprint arXiv:2505.04512, 2025
arXiv 2025
-
[11]
T. Hu, Z. Yu, Z. Zhou, J. Zhang, Y . Zhou, Q. Lu, and R. Yi. Polyvivid: Vivid multi-subject video generation with cross-modal interaction and enhancement.arXiv preprint arXiv:2506.07848, 2025
arXiv 2025
-
[12]
T. Hu, J. Zhang, Z. Su, and R. Yi. Ultragen: High-resolution video generation with hierarchical attention.arXiv preprint arXiv:2510.18775, 2025
arXiv 2025
-
[13]
T. Hu, J. Zhang, H. Huang, R. Yi, Z. Su, J. Weng, Z. Xue, L. Ma, M.-H. Yang, and D. Tao. Evolution of video generative foundations.arXiv preprint arXiv:2604.06339, 2026
Pith/arXiv arXiv 2026
-
[14]
X. Huang, Z. Li, G. He, M. Zhou, and E. Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025
Pith/arXiv arXiv 2025
-
[15]
Huang, Y
Z. Huang, Y . He, J. Yu, F. Zhang, C. Si, Y . Jiang, Y . Zhang, T. Wu, Q. Jin, N. Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
2024
-
[16]
H. Kong, X. Yang, X. Zheng, and X. Wang. Worldwarp: Propagating 3d geometry with asynchronous video diffusion.arXiv preprint arXiv:2512.19678, 2025
arXiv 2025
-
[17]
W. Kong, Q. Tian, Z. Zhang, R. Min, Z. Dai, J. Zhou, J. Xiong, X. Li, B. Wu, J. Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 10
Pith/arXiv arXiv 2024
-
[18]
LeCun et al
Y . LeCun et al. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27. Open Review, 62(1):1–62, 2022
2022
-
[19]
R. Li, P. Torr, A. Vedaldi, and T. Jakab. Vmem: Consistent interactive video scene generation with surfel-indexed view memory.arXiv preprint arXiv:2506.18903, 2025
arXiv 2025
-
[20]
W. Li, W. Pan, P.-C. Luan, Y . Gao, and A. Alahi. Stable video infinity: Infinite-length video generation with error recycling.arXiv preprint arXiv:2510.09212, 2025
arXiv 2025
-
[21]
L. Liu, T. Ma, B. Li, Z. Chen, J. Liu, Q. He, and X. Wu. Phantom: Subject-consistent video generation via cross-modal alignment.arXiv preprint arXiv:2502.11079, 2025
arXiv 2025
-
[22]
Parker-Holder, P
J. Parker-Holder, P. Ball, J. Bruce, V . Dasagi, K. Holsheimer, C. Kaplanis, A. Moufarek, G. Scully, J. Shar, J. Shi, et al. Genie 2: A large-scale foundation world model.URL: https://deepmind.google/discover/blog/genie-2-a-large-scale-foundation-world-model, 2024
2024
-
[23]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[24]
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. Rädle, C. Rolland, L. Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
Pith/arXiv arXiv 2024
-
[25]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
- [26]
-
[27]
W. Sun, H. Zhang, H. Wang, J. Wu, Z. Wang, Z. Wang, Y . Wang, J. Zhang, T. Wang, and C. Guo. Worldplay: Towards long-term geometric consistency for real-time interactive world modeling. arXiv preprint arXiv:2512.14614, 2025
Pith/arXiv arXiv 2025
-
[28]
Wan: Open and advanced large-scale video generative models
Wan Team. Wan: Open and advanced large-scale video generative models. 2025
2025
-
[29]
R. Wang, S. Xu, Y . Dong, Y . Deng, J. Xiang, Z. Lv, G. Sun, X. Tong, and J. Yang. Moge-2: Accu- rate monocular geometry with metric scale and sharp details.arXiv preprint arXiv:2507.02546, 2025
Pith/arXiv arXiv 2025
-
[30]
H. Wu, J. Yu, Y . Zou, and X. Liu. Multiworld: Scalable multi-agent multi-view video world models.arXiv preprint arXiv:2604.18564, 2026
Pith/arXiv arXiv 2026
-
[31]
T. Wu, S. Yang, R. Po, Y . Xu, Z. Liu, D. Lin, and G. Wetzstein. Video world models with long-term spatial memory.arXiv preprint arXiv:2506.05284, 2025
arXiv 2025
-
[32]
Z. Xiao, Y . Lan, Y . Zhou, W. Ouyang, S. Yang, Y . Zeng, and X. Pan. Worldmem: Long-term consistent world simulation with memory.arXiv preprint arXiv:2504.12369, 2025
arXiv 2025
-
[33]
Z. Xue, J. Zhang, T. Hu, H. He, Y . Chen, Y . Wang, C. Wang, Y . Liu, X. Li, D. Tao, et al. Ultravideo: High-quality uhd video dataset with comprehensive captions. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025
2025
-
[34]
L. Yang, B. Kang, Z. Huang, X. Xu, J. Feng, and H. Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10371–10381, 2024
2024
-
[35]
Z. Yang, J. Teng, W. Zheng, M. Ding, S. Huang, J. Xu, Y . Yang, W. Hong, X. Zhang, G. Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 11
Pith/arXiv arXiv 2024
-
[36]
J. Yu, J. Bai, Y . Qin, Q. Liu, X. Wang, P. Wan, D. Zhang, and X. Liu. Context as memory: Scene-consistent interactive long video generation with memory retrieval.arXiv preprint arXiv:2506.03141, 2025
arXiv 2025
-
[37]
S. Yuan, J. Huang, X. He, Y . Ge, Y . Shi, L. Chen, J. Luo, and L. Yuan. Identity-preserving text-to-video generation by frequency decomposition. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12978–12988, 2025
2025
-
[38]
J. Zhao, F. Wei, Z. Liu, H. Zhang, C. Xu, and Y . Lu. Spatia: Video generation with updatable spatial memory.arXiv preprint arXiv:2512.15716, 2025
arXiv 2025
-
[39]
S. Zheng, M. Yin, W. Hu, X. Li, Y . Shan, and Y . Fu. Versecrafter: Dynamic realistic video world model with 4d geometric control.arXiv preprint arXiv:2601.05138, 2026. 12 A Overview In the appendix, we offer further details on implementation, present additional experimental results, and provide more comprehensive analyses, structured as follows: • Implem...
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.