For How Long Should We Be Punching? Learning Action Duration in Fighting Games
Pith reviewed 2026-05-21 04:33 UTC · model grok-4.3
The pith
Reinforcement learning agents in fighting games learn both the action and how long to hold it instead of using fixed decision intervals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
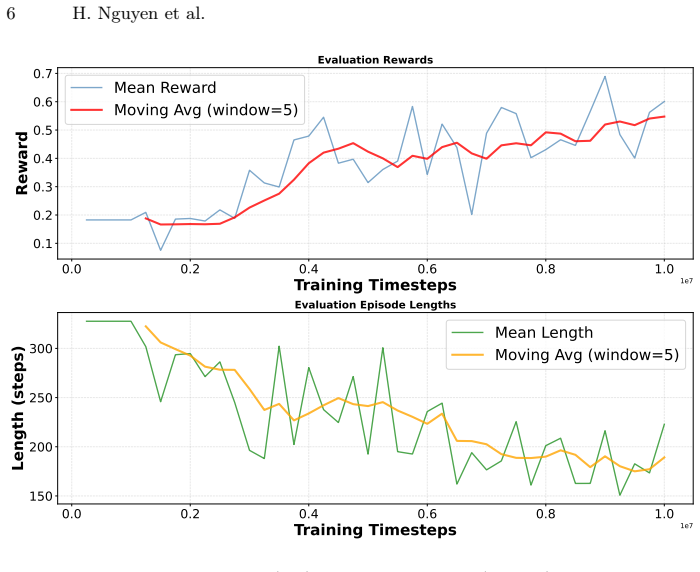
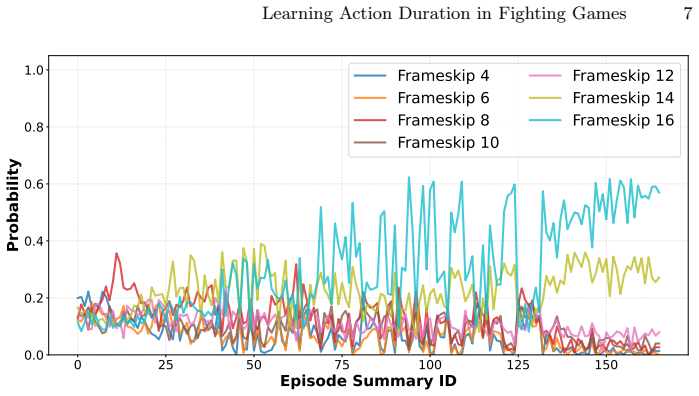
Jointly predicting action and duration lets agents reach win rates comparable to the best fixed frame-skip baselines while producing repeatable action sequences that exploit scripted opponents, although the learned policies still perform best when they default to consistently high frame skips and do not automatically gain robustness.
What carries the argument
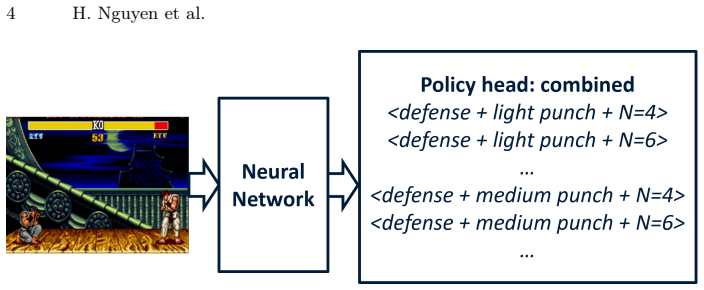
Joint prediction of action and execution duration inside the reinforcement learning policy, allowing the agent to choose variable hold times rather than a single fixed interval.
If this is right
- Learned duration policies match the win rates obtained with well-chosen fixed frame skips.
- Agents converge on high frame-skip values for best performance, reducing decision frequency.
- Duration learning promotes repeatable action patterns rather than varied responses.
- Robustness against different opponents is not guaranteed by adding duration prediction alone.
Where Pith is reading between the lines
- Duration learning may be more valuable against human opponents who change timing than against static scripted bots.
- The method could reduce the need for manual frame-skip tuning if extended to other real-time game environments.
- Pairing duration prediction with additional mechanisms might be required to obtain both performance and robustness.
Load-bearing premise
That performance against scripted built-in bots is a sufficient test for both the effectiveness and the robustness of the learned duration policies.
What would settle it
If agents using learned durations achieve lower win rates than a fixed high frame-skip baseline when matched against the same scripted bots or against more varied opponents, the claim that learned timing matches or improves on fixed intervals would be refuted.
Figures




read the original abstract
Fighting games such as Street Fighter II present unique challenges to reinforcement learning (RL) agents due to their fast-paced, real-time nature. In most RL frameworks, agents are hard-coded to make decisions at a fixed interval, typically every frame or every N frames. Although this design ensures timely responses, it restricts the agent's ability to adjust its reaction timing. Acting every frame grants frame-perfect reflexes, which are unrealistic compared to human players, whereas longer fixed intervals reduce computational cost but hinder responsiveness. We consider an alternative decision-making framework in which the agent learns not only what action to take but also for how long to execute it. By jointly predicting both action and duration, the agent can dynamically adapt its responsiveness to different situations in the game. We implement this method using the open-source FightLadder environment with agents trained against scripted built-in bots, systematically testing different frame skip configurations to analyze their influence on performance, responsiveness, and learned behavior. Experiments show that learned timing can match the performance of well-chosen fixed frame skips and encourages repeatable action patterns, but does not ensure robustness on its own. In most cases, we see agents performing best with consistently high frame skip values (i.e., low responsiveness). This strategy makes it easier to learn exploitative strategies where the same action is repeated over and over, which the scripted bots appear to be susceptible to.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a reinforcement learning approach for fighting games where agents jointly learn both the action to perform and its execution duration (frame skip) rather than relying on fixed intervals. Implemented in the FightLadder environment and evaluated against scripted built-in bots, the work systematically varies frame-skip configurations and concludes that learned timing achieves performance comparable to well-chosen fixed skips, promotes repeatable action patterns, yet does not ensure robustness, with agents performing best under consistently high frame skips.
Significance. If the empirical results hold under stronger evaluation, the approach could enable more efficient and adaptive decision-making in real-time game environments, reducing computational demands while approximating human-like timing variability. The use of an open-source testbed supports potential reproducibility, and the comparison to fixed baselines provides concrete insight into the trade-offs of learned versus static responsiveness.
major comments (2)
- Abstract: The abstract states that experiments were performed and reports qualitative outcomes, but provides no quantitative results, statistical tests, ablation details, or error bars; therefore the data support for the stated claims cannot be verified from the given text.
- Experiments section: The evaluation relies exclusively on scripted built-in bots, which the abstract acknowledges are susceptible to repeated actions. This creates a risk that the observed preference for high frame skips and repeatable patterns simply reflects optimization against a narrow, non-adaptive opponent rather than genuine dynamic timing learning, undermining the robustness conclusions.
minor comments (2)
- Abstract: The qualifier 'in most cases' is imprecise; specify the exact frame-skip values, number of runs, or conditions under which high skips were optimal.
- Introduction: Consider adding a short reference to prior RL work on variable action durations or hierarchical policies to better situate the contribution.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment point by point below, indicating where revisions will be made.
read point-by-point responses
-
Referee: Abstract: The abstract states that experiments were performed and reports qualitative outcomes, but provides no quantitative results, statistical tests, ablation details, or error bars; therefore the data support for the stated claims cannot be verified from the given text.
Authors: We agree that the abstract would benefit from the inclusion of quantitative results to support the claims. In the revised manuscript, we will update the abstract to include key quantitative findings from our experiments, such as specific performance metrics comparing learned action durations to fixed frame skips. revision: yes
-
Referee: Experiments section: The evaluation relies exclusively on scripted built-in bots, which the abstract acknowledges are susceptible to repeated actions. This creates a risk that the observed preference for high frame skips and repeatable patterns simply reflects optimization against a narrow, non-adaptive opponent rather than genuine dynamic timing learning, undermining the robustness conclusions.
Authors: We acknowledge this limitation in our evaluation setup. The use of scripted bots was to facilitate systematic and reproducible testing within the FightLadder environment. The manuscript already points out the bots' vulnerability to repeatable patterns. We will expand the discussion to highlight this as a current limitation and suggest directions for future work with more robust opponents to strengthen the robustness claims. revision: partial
Circularity Check
No circularity: purely empirical RL evaluation
full rationale
The paper reports experimental results from training RL agents to jointly predict actions and durations in the FightLadder environment, comparing them to fixed frame-skip baselines against scripted bots. No mathematical derivations, equations, or first-principles claims are present that could reduce outputs to inputs by construction. All performance, repeatability, and robustness observations are direct empirical measurements rather than fitted parameters renamed as predictions or self-referential definitions. The work is therefore self-contained with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The FightLadder environment accurately models the real-time dynamics and state transitions of fighting games for the purpose of RL training.
- domain assumption Performance against scripted built-in bots is a valid proxy for general agent capability and robustness.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2406.02081 , year=
FightLadder: A benchmark for competitive multi-agent reinforcement learning , author=. arXiv preprint arXiv:2406.02081 , year=
-
[2]
Journal of machine learning research , volume=
Stable-baselines3: Reliable reinforcement learning implementations , author=. Journal of machine learning research , volume=
-
[3]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Human-level control through deep reinforcement learning , author=. nature , volume=. 2015 , publisher=
work page 2015
-
[5]
Mastering the game of Go with deep neural networks and tree search , author=. nature , volume=. 2016 , publisher=
work page 2016
-
[6]
A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play , author=. Science , volume=. 2018 , publisher=
work page 2018
-
[7]
arXiv preprint arXiv:2102.03718 , year=
An analysis of frame-skipping in reinforcement learning , author=. arXiv preprint arXiv:2102.03718 , year=
-
[8]
Reinforcement learning: An introduction , author=. 1998 , publisher=
work page 1998
-
[9]
M. Abbas and F. A. Jam and T. I. Khan. Is it harmful or helpful? Examining the causes and consequences of generative AI usage among university students. International Journal of Educational Technology in Higher Education. 2024
work page 2024
-
[10]
A. Abid and A. Abdalla and A. Abid and D. Khan and A. Alfozan and James Zou. Gradio: Hassle-Free Sharing and Testing of ML Models in the Wild. 2019 ICML Workshop on Human in the Loop Learning. 2019
work page 2019
- [11]
-
[12]
R. Achtibat and M. Dreyer and I. Eisenbraun and S. Bosse and T. Wiegand and W. Samek and S. Lapuschkin. From Attribution Maps to Humand-understandable Explanations through Concept Relevance Propagation. Nature Machine Intelligence. 2023
work page 2023
-
[13]
A. Afshar and W. Li. DeLF : Designing Learning Environments with Foundation Models. AAAI 2024 Workshop on Synergy of Reinforcement Learning and Large Language Models. 2024
work page 2024
-
[14]
Advances in Neural Information Processing Systems , year=
Deep Reinforcement Learning at the Edge of the Statistical Precipice , author=. Advances in Neural Information Processing Systems , year=
-
[15]
R. Agarwal and M. Schwarzer and P. S. Castro and A. C. Courville and M. Bellemare , booktitle =. Reincarnating Reinforcement Learning: Reusing Prior Computation to Accelerate Progress , volume =
-
[16]
A. Ahmadian and C. Cremer and M. Gall \'e and M. Fadee and J. Kreutzer and O. Pietquin and A. \"U st \"u n and S. Hooker. Back to Basics: Revisiting REINFORCE -Style Optimization for Learning from Human Feedback in LLM s. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024
work page 2024
-
[17]
Z. Ahmed and N. Le Roux and M. Norouzi and D. Schuurmans. Understanding the Impact of Entropy on Policy Optimization. Proceedings of the 36th International Conference on Machine Learning. 2019
work page 2019
-
[18]
M. Ahn and D. Dwibedi and C. Finn and M. Gonzalez Arenas and K. Gopalakrishnan and K. Hausman and B. Ichter and A. Irpan and N. Joshi and R. Julian and S. Kirmani and I. Leal and E. Lee and S. Levine and Y. Lu and S. Maddineni and K. Rao and D. Sadigh and P. Sanketi and P. Sermanet and Q. Vuong and S. Welker and F. Xia and T. Xiao and P. Xu and S. Xu and ...
work page 2024
-
[19]
Lessons in Play: An Introduction to Combinatorial Game Theory , author=. 2007 , publisher=
work page 2007
-
[20]
A. Alharin and T.-N. Doan and M. Sartipi. Reinforcement Learning Interpretation Methods: A Survey. IEEE Access. 2020
work page 2020
-
[21]
E. Aljalbout and N. Sotirakis and P. van der Smagt and M. Karl and N. Chen. LIMT : Language-Informed Multi-Task Visual World Models. 2024
work page 2024
-
[22]
C. Allen and K. Asadi and M. Roderick and A. Mohamed and G. Konidaris and M. Littman. Mean Actor Critic. 2018
work page 2018
-
[23]
L. V. Allis and M. van der Meulen and H. J. van den Herik. Proof-number Search. Artificial Intelligence. 1994
work page 1994
-
[24]
Alth\"ofer, Ingo , Institution =
-
[25]
Proceedings of the SIGCHI Conference on Human Factors in Computing Systems , pages =
Andersen, Erik and O'Rourke, Eleanor and Liu, Yun-En and Snider, Rich and Lowdermilk, Jeff and Truong, David and Cooper, Seth and Popovic, Zoran , title =. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems , pages =. 2012 , publisher =
work page 2012
-
[26]
J. Andreas and D. Klein and S. Levine. Modular Multitask Reinforcement Learning with Policy Sketches. Proceedings of the 34th International Conference on Machine Learning. 2017
work page 2017
-
[27]
M. Andrychowicz and A. Raichuk and P. Sta \'n' czyk and M. Orsini and S. Girgin and R. Marinier and L. Hussenot and M. Geist and O. Pietquin and M. Michalski and S. Gelly and O. Bachem. What Matters for On-Policy Deep Actor-Critic Methods? A Large-Scale Study. 2021 International Conference on Learning Representations. 2021
work page 2021
-
[28]
T. Anthony and Z. Tian and D. Barber. Thinking Fast and Slow with Deep Learning and Tree Search. Advances in Neural Information Processing Systems 30. 2017
work page 2017
-
[29]
D. Apeldoorn and V. Volz. Measuring Strategic Depth in Games Using Hierarchical Knowledge Bases. Proceedings of the 2017 IEEE Conference on Computational Intelligence and Games. 2017
work page 2017
-
[30]
N. Araki and K. Yoshida and Y. Tsuruoka and J. Tsujii. Move Prediction in G o with the Maximum Entropy Method. Proceedings of the 2007 IEEE Symposium on Computational Intelligence and Games. 2007
work page 2007
-
[31]
M. Aram and G. Neumann. Multilayered analysis of co-development of business information systems. Journal of Internet Services and Applications. 2015
work page 2015
-
[32]
M. Ascher. M u T orere: An analysis of a M aori game. Mathematics Magazine. 1987
work page 1987
-
[33]
COLT 2010 - The 23rd Conference on Learning Theory , pages=
Best Arm Identification in Multi-Armed Bandits , author=. COLT 2010 - The 23rd Conference on Learning Theory , pages=
work page 2010
-
[34]
P. Auer and N. Cesa-Bianchi and P. Fischer. Finite-time Analysis of the Multiarmed Bandit Problem. Machine Learning. 2002
work page 2002
- [35]
- [36]
-
[37]
H. Baier and P. D. Drake. The Power of Forgetting: Improving the Last-Good-Reply Policy in M onte C arlo G o. IEEE Transactions on Computational Intelligence and AI in Games. 2010
work page 2010
-
[38]
H. Baier and P. D. Drake. The Power of Forgetting: Improving the Last-Good-Reply Policy in M onte C arlo G o. IEEE Trans. Comput. Intell. AI Games. 2010
work page 2010
-
[39]
H. Baier and M. H. M. Winands. Monte C arlo Tree Search and Minimax Hybrids with Heuristic Evaluation Functions. Computer Games. 2014
work page 2014
-
[40]
H. Baier and M. H. M. Winands. MCTS-M inimax Hybrids. IEEE Transactions on Computational Intelligence and AI in Games. 2015
work page 2015
-
[41]
H. Baier and M. H. M. Winands. Time Management for M onte C arlo Tree Search. IEEE Transactions on Computational Intelligence and AI in Games. 2015
work page 2015
-
[42]
H. Baier and M. H. M. Winands. MCTS-M inimax Hybrids with State Evaluations. Journal of Artificial Intelligence Research. 2018
work page 2018
-
[43]
H. Baier and M. Kaisers. Explainable Search. 2020 IJCAI-PRICAI Workshop on Explainable Artificial Intelligence. 2020
work page 2020
-
[44]
H. Baier and M. Kaisers. Towards Explainable MCTS. 2021 AAAI Workshop on Explainable Agency in AI. 2021
work page 2021
- [45]
-
[46]
T. Bansal and J. Pachocki and S. Sidor and I. Sutskever and I. Mordatch. Emergent Complexity via Multi-Agent Competition. International Conference on Learning Representations (ICLR 2018). 2018
work page 2018
-
[47]
N. Bard and J. N. Foerster and S. Chandar and N. Burch and M. Lanctot and H. F. Song and E. Parisotto and V. Dumoulin and S. Moitra and E. Hughes and I. Dunning and S. Mourad and H. Larochelle and M. G. Bellemare and M. Bowling. The H anabi challenge: A new frontier for AI research. Artificial Intelligence. 2020
work page 2020
-
[48]
D. Barman and Z. Guo and O. Conlan. The Dark Side of Language Models: Exploring the Potential of LLM s in Multimedia Disinformation Generation and Dissemination. Machine Learning with Applications. 2024
work page 2024
-
[49]
T. Bartz-Beielstein and C. Doerr and D. van den Berg and J. Bossek and S. Chandrasekaran and T. Eftimov and A. Fischbach and P. Kerschke and W. La Cava and M. L \'o pez-Ib \'a \ n ez and K. M. Malan and J. H. Moore and B. Naujoks and P. Orzechowski and V. Volz and M. Wagner and T. Weise. Benchmarking in Optimization: Best Practice and Open Issues. 2020
work page 2020
-
[50]
D. Beal and M. Clarke. The Construction of Economical and Correct Algorithms for King and Pawn against King. Advances in Computer Chess 2. 1980
work page 1980
- [51]
-
[52]
J. Beck and R. Vuorio and E. Z. Liu and Z. Xiong and L. Zintgraf and C. Finn and S. Whiteson. A Survey of Meta-Reinforcement Learning. 2023
work page 2023
-
[53]
Journal of Artificial Intelligence Research , volume = 47, number = 1, pages =
The Arcade Learning Environment: An Evaluation Platform for General Agents , author =. Journal of Artificial Intelligence Research , volume = 47, number = 1, pages =
-
[54]
M. G. Bellemare and S. Candido and P. S. Castro and J. Gong and M. C. Machado and S. Moitra and S. S. Ponda and Z. Wang. Autonomous navigation of stratospheric balloons using reinforcement learning. Nature. 2020
work page 2020
-
[55]
R. Bellman. Dynamic Programming. 1957
work page 1957
-
[56]
R. Bellman. An Introduction to Artificial Intelligence: Can Computers Think?. 1978
work page 1978
-
[57]
M. Bettini and R. Kortvelesy and J. Blumenkamp and A. Prorok , year =. Proceedings of the 16th International Symposium on Distributed Autonomous Robotic Systems , publisher =
-
[58]
C. Benjamins and T. Eimer and F. Schubert and A. Mohan and S. D \"o hler and A. Biedenkapp and B. Rosenhahn and F. Hutter and M. Lindauer. Contextualize Me – The Case for Context in Reinforcement Learning. Transactions on Machine Learning Research. 2023
work page 2023
-
[59]
S. G. Bennett. The Adventures of S ir G alahad. 1949
work page 1949
-
[60]
L. Beyer and P. Izmailov and A. Kolesnikov and M. Caron and S. Kornblith and X. Zhai and M. Minderer and M. Tschannen and I. Alabdulmohsin and F. Pavetic. FlexiViT : One Model for All Patch Sizes. Proceedings of the 2023 Conference on Computer Vision and Pattern Recognition (CVPR). 2023
work page 2023
-
[61]
CadiaPlayer: A simulation-based general game player , author =. IEEE Transactions on Games
-
[62]
Proceedings of the Twentieth European Conference on Artificial Intelligence , pages =
Learning Rules of Simplified Boardgames by Observing , author =. Proceedings of the Twentieth European Conference on Artificial Intelligence , pages =
-
[63]
Handbook of Digital Games and Entertainment Technologies , publisher =
General Game Playing , author =. Handbook of Digital Games and Entertainment Technologies , publisher =
-
[64]
B. Blili-Hamelin and C. Graziul and L. Hancox-Li and H. Hazan and E.-M. El-Mhamdi and A. Ghosh and K. Heller and J. Metcalf and F. Murai and E. Salvaggio and A. Smart and T. Snider and M. Tighanimine and T. Ringer and M. Mitchell and S. Dori-Hacohen. Position: Stop treating ` AGI ' as the north-star goal of AI research. Proceedings of the 42nd Internation...
work page 2025
-
[65]
A. Blattmann and T. Dockhorn and S. Kulal and D. Mendelevitch and M. Kilian and D. Lorenz and Y. Levi and Z. English anda V. Voleti and A. Letts and V. Jampani and R. Rombach. Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets. 2023
work page 2023
-
[66]
J. Bloch. Effective Java. 2008
work page 2008
-
[67]
On the Opportunities and Risks of Foundation Models , author=. 2021 , howpublished=
work page 2021
-
[68]
C. Bonnet and D. Luo and D. Byrne and S. Surana and S. Abramowitz and P. Duckworth and V. Coyette and L. I. Midgley and E. Tegegn and T. Kalloniatis and O. Mahjoub and M. Macfarlane and A. P. Smit and N. Grinsztajn and R. Bolge and C. N. Waters and M. A. Mimouni and U. A. Mbou Sob and R. de Kock and S. Singh and D. Furelos-Blanco and V. Le and A. Pretoriu...
-
[69]
Matching Games and Algorithms for General Video Game Playing , author=. AIIDE , year=
-
[70]
A. Borvo. Anatomie D'un Jeu de Cartes: L'Aluette ou le Jeu de Vache. 1977
work page 1977
- [71]
-
[72]
H. Bou Ammar and E. Eaton and P. Ruvolo and M. E. Taylor. Online Multi-Task Learning for Policy Gradient Methods. Proceedings of the 31st International Conference on Machine Learning. 2014
work page 2014
-
[73]
H. Bou Ammar and E. Eaton and M. E. Taylor and D. C. Mocanu and K. Driessens and G. Weiss and K. Tuyls. An Automated Measure of MDP Similarity for Transfer in Reinforcement Learning. Proceedings of the Interactive Systems Workshop at the American Association of Artificial Intelligence (AAAI). 2014
work page 2014
-
[74]
H. Bou Ammar and S. Chen and K. Tuyls and G. Weiss. Automated Transfer for Reinforcement Learning Tasks. K \"u nstliche Intelligenz. 2014
work page 2014
-
[75]
Accounting for Variance in Machine Learning Benchmarks , volume =
Bouthillier, Xavier and Delaunay, Pierre and Bronzi, Mirko and Trofimov, Assya and Nichyporuk, Brennan and Szeto, Justin and Mohammadi Sepahvand, Nazanin and Raff, Edward and Madan, Kanika and Voleti, Vikram and Ebrahimi Kahou, Samira and Michalski, Vincent and Arbel, Tal and Pal, Chris and Varoquaux, Gael and Vincent, Pascal , booktitle =. Accounting for...
-
[76]
B. Bouzy and G. Chaslot. Bayesian Generation and Integration of K -Nearest-Neighbor Patterns for 19x19 G o. Proceedings of the 2005 IEEE Symposium on Computational Intelligence in Games. 2005
work page 2005
-
[77]
B. Bouzy. Associating domain-dependent knowledge and M onte C arlo approaches within a G o program. Information Sciences. 2005
work page 2005
-
[78]
Bowling, Michael and Burch, Neil and Johanson, Michael and Tammelin, Oskari , year = 2015, journal =. Heads-Up Limit Hold
work page 2015
-
[79]
J. Bradbury and R. Frostig and P. Hawkins and M. J. Johnson and C. Leary and D. Maclaurin and G. Necula and A. Paszke and J. Vander
-
[80]
S. R. K. Branavan and D. Silver and R. Barzilay. Learning to Win by Reading Manuals in a M onte- C arlo Framework. Journal of Artificial Intelligence Research. 2012
work page 2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.