Verifiable Foundation Models for Robot Safety
Pith reviewed 2026-06-26 08:52 UTC · model grok-4.3
The pith
A modular split separates a large expressive controller from a small verifiable safety module in foundation-model robot policies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
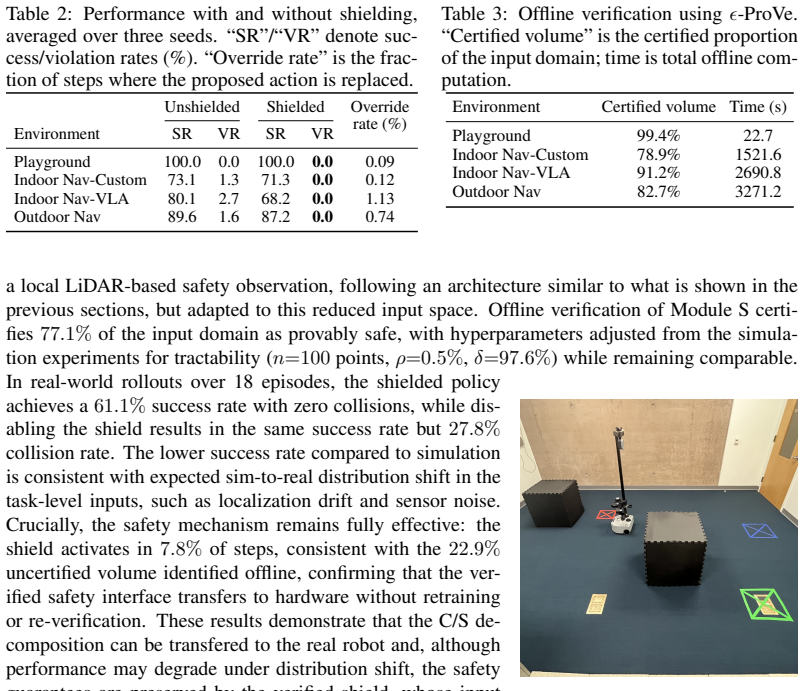
FEARL decomposes the policy into a Controller C that performs high-dimensional perception and task reasoning and a Safety module S that receives low-dimensional safety observations together with a bounded context embedding from C and outputs the final action; because many safety requirements can be stated over the safety observations, formal verification applies to S alone while the Controller keeps its full expressive power, as confirmed by task success in three simulated domains and successful transfer to a physical robot.
What carries the argument
The modular architectural decomposition into Controller and Safety module with a low-dimensional safety interface.
If this is right
- Formal verification of safety properties becomes tractable without analyzing the full foundation-model backbone.
- The decomposed policy continues to solve diverse tasks when the Controller uses pretrained vision-language-action models or other backbones.
- The low-dimensional safety interface supports sim-to-real transfer on at least one evaluated task.
- Multiple training procedures for the Controller remain compatible with the Safety module.
Where Pith is reading between the lines
- If a safety requirement inherently needs high-dimensional scene information, the low-dimensional Safety module may be insufficient to capture it.
- The same separation could be tested on other safety-critical control problems where dedicated low-dimensional sensors already exist.
- Standardizing the bounded context embedding passed from Controller to Safety module might allow reusable Safety modules across different foundation-model backbones.
Load-bearing premise
Robot safety requirements such as collision avoidance and workspace limits can be expressed and enforced using only the low-dimensional observations available to the Safety module.
What would settle it
A case in which the Safety module passes formal verification yet the physical robot still violates a safety constraint during execution, or in which the decomposed policy fails to reach task performance levels achieved by an undecomposed foundation-model baseline.
Figures


read the original abstract
Deploying foundation models for robot control raises a central challenge: the expressive power that enables rich, multimodal perception also makes these models opaque and difficult to analyze formally, rendering them intractable for existing verification tools. In this paper, we present FEARL (Foundation-Enabled Assured Robot Learning), a framework that addresses this tension through a modular architectural decomposition. FEARL separates the policy into a large Controller (C) responsible for high-dimensional perception and task reasoning, and a small Safety module (S) that receives low-dimensional observations from dedicated safety sensors together with a bounded context embedding from C and produces the final action. Since many robot safety requirements, such as collision avoidance and workspace boundary constraints, can be expressed over these safety sensor observations, formal verification can be applied to S rather than to the full foundation-model backbone. This makes formal analysis tractable with existing tools while preserving the Controller's expressive power for task reasoning. To show that the decomposed policy remains capable of solving diverse tasks, we evaluate FEARL on three simulated robotic domains using multiple Controller backbones and training procedures, including pretrained off-the-shelf vision-language-action models. We further transfer the learned policy from one of our simulated tasks to a physical robot, suggesting that the low-dimensional safety interface supports practical sim-to-real transfer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FEARL, a modular architecture for robot control that decomposes the policy into a large Controller module handling high-dimensional perception and task reasoning using foundation models, and a smaller Safety module that operates on low-dimensional safety sensor observations augmented by a bounded context embedding from the Controller. The framework claims to enable formal verification of safety properties on the Safety module while maintaining the Controller's expressiveness, supported by evaluations across three simulated robotic domains with various backbones including pretrained vision-language-action models, and a sim-to-real transfer to a physical robot.
Significance. If the assumption that key safety constraints can be adequately captured and enforced via the low-dimensional interface holds, this work could provide a practical pathway to combining the capabilities of foundation models with formal safety guarantees in robotics, addressing a key barrier to their deployment in real-world settings. The inclusion of sim-to-real transfer and multiple backbone evaluations strengthens the practical relevance.
major comments (3)
- [Abstract] Abstract, paragraph 3: The central claim that formal verification can be applied to S rests on the assertion that 'many robot safety requirements, such as collision avoidance and workspace boundary constraints, can be expressed over these safety sensor observations.' No argument, concrete examples, or evidence is supplied showing that the chosen low-dimensional observations are sufficient for the evaluated tasks, particularly when safety may require semantic distinctions available only to C.
- [Abstract] Abstract: Despite the framework's emphasis on making formal analysis tractable, the manuscript reports no quantitative verification results, proof sketches, or description of verification tools applied to S. Claims therefore rest entirely on qualitative policy success and transfer, leaving the primary promised benefit undemonstrated.
- [Abstract] Abstract: No ablation or analysis is provided on the effect of the bounded context embedding from C on S's safety enforcement capability or on the tightness of the resulting verification bounds, which is load-bearing for assessing whether the decomposition preserves both verifiability and task performance.
minor comments (1)
- The evaluation description could more explicitly separate results on policy capability from any verification-related metrics, even if the latter are absent.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each of the three major comments point-by-point below, indicating planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract, paragraph 3: The central claim that formal verification can be applied to S rests on the assertion that 'many robot safety requirements, such as collision avoidance and workspace boundary constraints, can be expressed over these safety sensor observations.' No argument, concrete examples, or evidence is supplied showing that the chosen low-dimensional observations are sufficient for the evaluated tasks, particularly when safety may require semantic distinctions available only to C.
Authors: We agree that more explicit justification is warranted. In the revised manuscript, we will augment the abstract and add a subsection detailing how the safety sensors (e.g., joint encoders, distance sensors) suffice for the safety properties in our domains. We provide examples such as enforcing minimum distance to obstacles using raw sensor data in S, independent of semantic perception handled by C. This will be supported by task descriptions. revision: yes
-
Referee: [Abstract] Abstract: Despite the framework's emphasis on making formal analysis tractable, the manuscript reports no quantitative verification results, proof sketches, or description of verification tools applied to S. Claims therefore rest entirely on qualitative policy success and transfer, leaving the primary promised benefit undemonstrated.
Authors: This is a valid observation. While the paper establishes that S is small and thus verifiable in principle, we did not include explicit verification experiments. We will revise by adding a verification subsection that applies an off-the-shelf tool (e.g., a reachability analyzer) to S, providing quantitative results on verified properties and computation times for the simulated domains. revision: yes
-
Referee: [Abstract] Abstract: No ablation or analysis is provided on the effect of the bounded context embedding from C on S's safety enforcement capability or on the tightness of the resulting verification bounds, which is load-bearing for assessing whether the decomposition preserves both verifiability and task performance.
Authors: We concur that this analysis is important for validating the decomposition. The revision will incorporate an ablation study varying the context embedding (including a no-context baseline), evaluating impacts on safety metrics and verification complexity (e.g., state-space size). Results will be presented in the experiments section. revision: yes
Circularity Check
No circularity: framework defined by explicit architectural choice with independent empirical support
full rationale
The paper defines FEARL by construction as a decomposition into Controller C and Safety module S, with the latter receiving low-dimensional safety observations plus bounded context; the claim that formal verification applies to S follows directly from this interface choice and the stated assumption that many safety requirements (collision avoidance, workspace limits) can be expressed over those observations. No equations, fitted parameters, or self-citations are invoked to derive the safety guarantee from the framework's own outputs. The evaluations on simulated domains with multiple backbones and the sim-to-real transfer constitute independent content that does not reduce to the definition itself. This is a standard non-circular presentation of a proposed modular architecture.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Safety requirements such as collision avoidance can be expressed over low-dimensional safety sensor observations
Reference graph
Works this paper leans on
-
[1]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding.arXiv preprint arXiv:1810.04805, 2019
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[2]
G. Comanici, E. Bieber, M. Schaekermann, I. Pasupat, N. Sachdeva, I. Dhillon, M. Blistein, O. Ram, D. Zhang, E. Rosen, et al. Gemini 2.5: Pushing the frontier with advanced rea- soning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. De- hghani, M. Minderer, G. Heigold, S. Gelly, et al. An image is worth 16x16 words: Transform- ers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[4]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
M. Shukor, D. Aubakirova, F. Capuano, P. Kooijmans, S. Palma, A. Zouitine, M. Aractingi, C. Pascal, M. Russi, A. Marafioti, et al. Smolvla: A vision-language-action model for afford- able and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
H. Wu, O. Isac, A. Zelji ´c, T. Tagomori, M. Daggitt, W. Kokke, I. Refaeli, G. Amir, K. Julian, S. Bassan, et al. Marabou 2.0: A versatile formal analyzer of neural networks. InInternational Conference on Computer Aided Verification, pages 249–264. Springer, 2024
2024
-
[7]
Stooke, J
A. Stooke, J. Achiam, and P. Abbeel. Responsive Safety in Reinforcement Learning by Pid Lagrangian Methods. InProc. 37th Int. Conf. on Machine Learning (ICML), pages 9133–9143, 2020
2020
-
[8]
Q. Yang, T. Sim ˜ao, N. Jansen, S. Tindemans, and M. Spaan. Training and Transferring Safe Policies in Reinforcement Learning. InAAMAS 2022 Workshop on Adaptive Learning Agents, 2022
2022
-
[9]
Achiam, D
J. Achiam, D. Held, A. Tamar, and P. Abbeel. Constrained policy optimization. InInternational Conference on Machine Learning, pages 22–31. PMLR, 2017
2017
-
[10]
Corsi, G
D. Corsi, G. Amir, A. Rodr´ıguez, C. S´anchez, G. Katz, and R. Fox. Verification-guided shield- ing for deep reinforcement learning. In1st Reinforcement Learning Conference (RLC), 2024
2024
-
[11]
K. Kim, D. Corsi, A. Rodr ´ıguez, J. Lanier, B. Parellada, P. Baldi, C. S ´anchez, and R. Fox. Realizable continuous-space shields for safe reinforcement learning. In7th Annual Learning for Dynamics & Control Conference (L4DC), 2025
2025
-
[12]
Marzari, D
L. Marzari, D. Corsi, E. Marchesini, A. Farinelli, and F. Cicalese. Enumerating safe regions in deep neural networks with provable probabilistic guarantees. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 21387–21394, 2024
2024
-
[13]
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, O. Cortes, B. David, C. Finn, C. Fu, K. Gopalakr- ishnan, K. Hausman, et al. Do as I can, not as I say: Grounding language in robotic affordances. InConference on Robot Learning. PMLR, 2023
2023
-
[14]
Huang, P
W. Huang, P. Abbeel, D. Pathak, and I. Mordatch. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. InInternational conference on machine learning, pages 9118–9147. PMLR, 2022
2022
-
[15]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning. PMLR, 2023. 9
2023
-
[16]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Meng, A. Walsman, R. Rafailov, J. Hejna, T. Leal, T. Gupta, S. Bahl, et al. OpenVLA: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[18]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
G. Katz, C. Barrett, D. L. Dill, K. Julian, and M. J. Kochenderfer. Reluplex: An efficient smt solver for verifying deep neural networks. InInternational conference on computer aided verification, pages 97–117. Springer, 2017
2017
-
[20]
Zhang, T.-W
H. Zhang, T.-W. Weng, P.-Y . Chen, C.-J. Hsieh, and L. Daniel. Efficient neural network robust- ness certification with general activation functions.Advances in neural information processing systems, 31, 2018
2018
-
[21]
Alshiekh, R
M. Alshiekh, R. Bloem, R. Ehlers, B. K ¨onighofer, S. Niekum, and U. Topcu. Safe Reinforce- ment Learning via Shielding. InProc. of the AAAI Conference on Artificial Intelligence, 2018
2018
-
[22]
C. Lazarus, J. G. Lopez, and M. J. Kochenderfer. Runtime safety assurance using reinforce- ment learning. In2020 AIAA/IEEE 39th Digital Avionics Systems Conference (DASC), 2020. doi:10.1109/DASC50938.2020.9256446
-
[23]
X. Sun, H. Khedr, and Y . Shoukry. Formal Verification of Neural Network Controlled Au- tonomous Systems. InProc. 22nd ACM Int. Conf. on Hybrid Systems: Computation and Control (HSCC), 2019
2019
-
[24]
C. C. Kemp, A. Edsinger, H. M. Clever, and B. Matulevich. The design of stretch: A com- pact, lightweight mobile manipulator for indoor human environments. In2022 International Conference on Robotics and Automation (ICRA), pages 3150–3157. IEEE, 2022
2022
-
[25]
Rudin, D
N. Rudin, D. Hoeller, P. Reist, and M. Hutter. Learning to walk in minutes using massively parallel deep reinforcement learning. InConference on Robot Learning, pages 91–100. PMLR, 2022
2022
-
[26]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, and W. Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Rep- resentations, 2022
2022
-
[28]
S. Ross, G. Gordon, and D. Bagnell. A reduction of imitation learning and structured predic- tion to no-regret online learning. InProceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, pages 627–635. JMLR Workshop and Conference Pro- ceedings, 2011. 10 A Proof of Propositions Proof of Proposition 1 (Probabilistic...
2011
-
[29]
Reach the red circle with a black number zero (0) inside it
-
[30]
Move to the red circle labeled 0
-
[31]
Navigate to the red target marked with zero
-
[32]
Go toward the red goal with the digit 0
-
[33]
Your task is to touch the red circle labeled 0
-
[34]
Approach the red dot containing a black 0
-
[35]
Find and reach the red zero-marked circle
-
[36]
Drive the agent to the red goal labeled zero
-
[37]
Head to the red circle with a number zero inside
-
[38]
Target 1: Green circle
Move the agent to the red destination marked 0. Target 1: Green circle
-
[39]
Reach the green circle with a black number one (1) inside it
-
[40]
Move to the green circle labeled 1
-
[41]
Navigate to the green target marked with one
-
[42]
Go toward the green goal with the digit 1
-
[43]
Your task is to touch the green circle labeled 1
-
[44]
Approach the green dot containing a black 1
-
[45]
Find and reach the green one-marked circle
-
[46]
Drive the agent to the green goal labeled one
-
[47]
Head to the green circle with a number one inside
-
[48]
Target 2: Blue circle
Move the agent to the green destination marked 1. Target 2: Blue circle
-
[49]
Reach the blue circle with a black number two (2) inside it
-
[50]
Move to the blue circle labeled 2
-
[51]
Navigate to the blue target marked with two
-
[52]
Go toward the blue goal with the digit 2
-
[53]
Your task is to touch the blue circle labeled 2
-
[54]
Approach the blue dot containing a black 2
-
[55]
Find and reach the blue two-marked circle
-
[56]
Drive the agent to the blue goal labeled two
-
[57]
Head to the blue circle with a number two inside
-
[58]
Move the agent to the blue destination marked 2. D Safety Specifications Safety properties are expressed as input-domain-conditioned output constraints on Module S: for a specified regionR ⊂ Sof the safety-sensor space, certain actions are declared unsafe and must not 13 be selected by Module S foranycontext embeddingz t ∈ Z. The formal statement iss t ∈ ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.