Curriculum Group Policy Optimization: Adaptive Sampling for Unleashing the Potential of Text-to-Image Generation
Pith reviewed 2026-05-20 12:30 UTC · model grok-4.3
The pith
Text-to-image models train more efficiently when prompts are sampled according to the variance of rewards across their generated images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
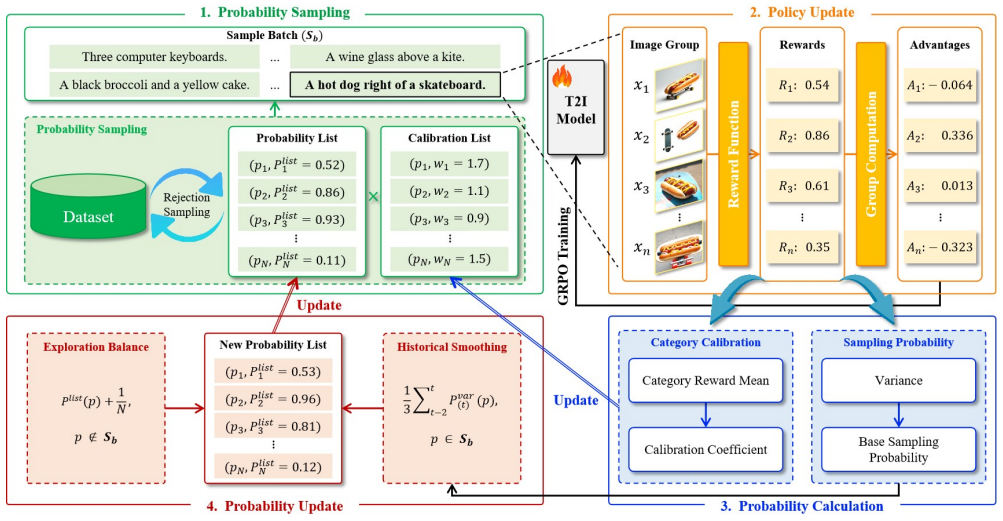
We propose Curriculum Group Policy Optimization (CGPO), an adaptive curriculum training framework. During training, each prompt produces a group of images scored by a reward model. We use the variance of group rewards as an online proxy for prompt inconsistency. A higher variance suggests that the model has partially captured the prompt requirements but has not yet achieved stable mastery. Such prompts are more likely to provide useful learning signals, so we increase their sampling probabilities accordingly. Additionally, to address data imbalance in multi-category datasets, we design a category calibration method based on proportional fairness optimization, which balances training across c
What carries the argument
Variance of group rewards from images generated by the same prompt, serving as the proxy that dynamically raises sampling probability for prompts at the model's current frontier of capability.
If this is right
- Training compute is redirected toward prompts that still produce inconsistent but improvable outputs rather than wasting steps on already-mastered or hopeless ones.
- Category calibration prevents easier prompt types from dominating the training distribution in mixed datasets.
- The same variance signal can be computed on top of existing Group Relative Policy Optimization without changing the underlying reward model or policy update rule.
- Final generation quality rises on composition, attribute, and prompt-following benchmarks because learning signals are more consistently informative.
Where Pith is reading between the lines
- The same group-variance proxy might transfer to other reinforcement-learning settings that already sample multiple outputs per input, such as text or code generation.
- If the reward model is updated during training, the variance threshold may need to be adjusted periodically to keep the difficulty signal aligned with the improving policy.
- Controlled experiments that insert prompts of known human-rated difficulty could test whether reward variance reliably tracks actual learning progress rather than reward-model artifacts.
Load-bearing premise
The variance of rewards within a group of images generated from the same prompt serves as a reliable online proxy for whether the prompt is at the right difficulty level for the model's current capability and will provide useful learning signals.
What would settle it
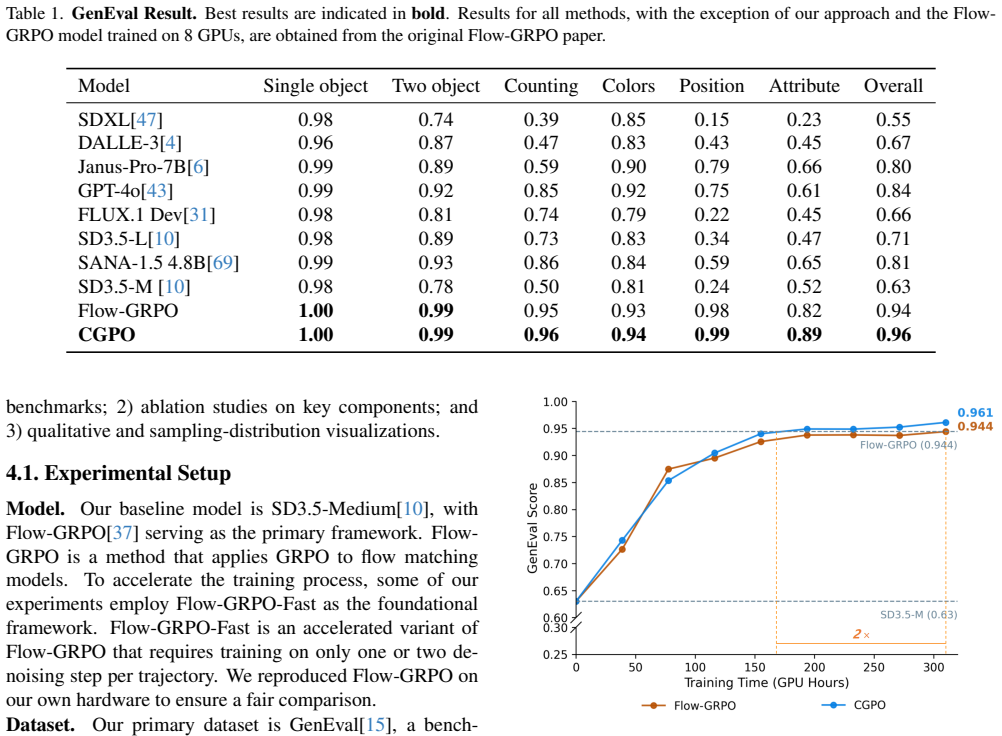
Training the identical base model with uniform prompt sampling versus the proposed variance-based sampling and finding equal or lower scores on GenEval, T2I-CompBench++, and DPG Bench would falsify the benefit of the adaptive schedule.
Figures






read the original abstract
Text-to-Image (T2I) generation has achieved remarkable progress in recent years. Meanwhile, reinforcement learning methods, particularly those based on Group Relative Policy Optimization (GRPO), have attracted widespread attention and been successfully applied to T2I tasks. However, the uniform sampling strategy commonly used during training often ignores the match between sample difficulty and the model's current learning capability, leading to low training efficiency. We argue that improving training efficiency requires continuously prioritizing prompts that match the model's evolving capability and remain actively learnable. To this end, we propose Curriculum Group Policy Optimization (CGPO), an adaptive curriculum training framework. During training, each prompt produces a group of images scored by a reward model. We use the variance of group rewards as an online proxy for prompt inconsistency. A higher variance suggests that the model has partially captured the prompt requirements but has not yet achieved stable mastery. Such prompts are more likely to provide useful learning signals, so we increase their sampling probabilities accordingly. Additionally, to address data imbalance in multi-category datasets, we design a category calibration method based on proportional fairness optimization, which balances training difficulty across categories. Experiments on GenEval, T2I-CompBench++, and DPG Bench demonstrate that our framework effectively improves generation performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Curriculum Group Policy Optimization (CGPO), an adaptive curriculum framework extending Group Relative Policy Optimization (GRPO) for text-to-image generation. It uses the variance of reward scores across groups of images generated from the same prompt as an online proxy for prompt difficulty, increasing sampling probability for high-variance prompts on the grounds that they indicate partial learning without stable mastery. A category calibration step based on proportional fairness optimization is added to balance training across categories in imbalanced datasets. The authors report that the framework improves generation performance on GenEval, T2I-CompBench++, and DPG Bench.
Significance. If the variance-based proxy reliably identifies prompts that yield greater learning progress, the method could meaningfully improve training efficiency for RL-based T2I models by focusing compute on appropriately challenging examples. The category calibration addresses a practical issue in multi-category training. These elements represent a targeted contribution to curriculum learning in generative model training, but the overall significance depends on stronger empirical grounding for the core proxy assumption.
major comments (3)
- Abstract: The claim that experiments on GenEval, T2I-CompBench++, and DPG Bench demonstrate effective improvement lacks any quantitative details on effect sizes, chosen baselines, statistical significance, or ablations isolating the variance proxy from simpler heuristics such as uniform sampling or fixed-probability adjustments.
- Methods (variance proxy description): The central assumption that higher intra-group reward variance reliably signals partial capture of prompt requirements (rather than reward-model noise, prompt ambiguity, or sampling stochasticity) is not supported by any correlation analysis or ablation showing larger per-prompt reward deltas for high-variance prompts over training steps.
- Experiments: No ablation is presented that compares CGPO against plain GRPO with equivalent extra compute or against a random high-variance selection baseline, making it impossible to attribute reported benchmark gains specifically to the proposed adaptive sampling.
minor comments (2)
- The scaling factor or threshold applied to the variance when computing sampling probabilities is listed among free parameters but receives no sensitivity analysis or default-value justification.
- The fairness parameter in the proportional fairness optimization for category calibration is introduced without discussion of how its value was chosen or its impact on final results.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight important areas for improving clarity, empirical support, and attribution of results. We address each major comment below and outline the revisions we will make.
read point-by-point responses
-
Referee: Abstract: The claim that experiments on GenEval, T2I-CompBench++, and DPG Bench demonstrate effective improvement lacks any quantitative details on effect sizes, chosen baselines, statistical significance, or ablations isolating the variance proxy from simpler heuristics such as uniform sampling or fixed-probability adjustments.
Authors: We agree that the abstract would be strengthened by including quantitative details. In the revised manuscript, we will update the abstract to report specific effect sizes (e.g., relative gains on each benchmark), explicitly name the primary baselines, and reference the key ablations performed. Where multiple runs were conducted, we will note result consistency; if formal statistical significance tests were not performed, we will clarify this limitation while emphasizing the observed trends. revision: yes
-
Referee: Methods (variance proxy description): The central assumption that higher intra-group reward variance reliably signals partial capture of prompt requirements (rather than reward-model noise, prompt ambiguity, or sampling stochasticity) is not supported by any correlation analysis or ablation showing larger per-prompt reward deltas for high-variance prompts over training steps.
Authors: The manuscript presents the variance proxy through a conceptual argument that high intra-group variance reflects prompts for which the model has achieved partial but unstable mastery. We acknowledge that this would be more convincing with direct empirical support. In the revision, we will add a correlation-style analysis or ablation that tracks per-prompt reward improvements over training steps, stratified by variance level at the time of sampling. This will help distinguish the intended signal from potential confounds such as reward noise. revision: yes
-
Referee: Experiments: No ablation is presented that compares CGPO against plain GRPO with equivalent extra compute or against a random high-variance selection baseline, making it impossible to attribute reported benchmark gains specifically to the proposed adaptive sampling.
Authors: We agree that the current experimental design leaves room for stronger isolation of the adaptive sampling contribution. While the manuscript already compares CGPO to standard GRPO, we will add two targeted ablations in the revision: (1) a plain GRPO run with compute budget matched to CGPO, and (2) a random high-variance prompt selection baseline that does not use the curriculum scheduling. These additions will allow clearer attribution of gains to the variance-driven adaptive mechanism. revision: yes
Circularity Check
No circularity: heuristic proxy and calibration are independent of target benchmarks
full rationale
The paper's core proposal defines an online sampling rule that increases probability for prompts whose generated group exhibits high reward variance, treating this variance as a proxy for partial mastery. This variance is computed directly from the reward model outputs on the current batch and is not fitted or calibrated against the final GenEval, T2I-CompBench++, or DPG scores. The category calibration step invokes proportional fairness optimization with an explicit tunable fairness parameter; the paper does not report optimizing this parameter on the evaluation benchmarks. Because the claimed performance gains are shown via separate held-out experiments rather than by construction from the proxy itself, the derivation chain remains self-contained and does not reduce to self-definition, fitted-input renaming, or self-citation load-bearing.
Axiom & Free-Parameter Ledger
free parameters (2)
- variance threshold or scaling factor for sampling probability
- fairness parameter in proportional fairness optimization
axioms (2)
- domain assumption The reward model provides a consistent and meaningful scalar score for image-prompt alignment.
- ad hoc to paper Higher intra-group reward variance indicates partial learning rather than noise or prompt ambiguity.
Reference graph
Works this paper leans on
-
[1]
Sotiris Anagnostidis, Gregor Bachmann, Yeongmin Kim, Jonas Kohler, Markos Georgopoulos, Artsiom Sanakoyeu, Yuming Du, Albert Pumarola, Ali Thabet, and Edgar Sch¨onfeld. Flexidit: Your diffusion transformer can easily generate high-quality samples with less compute, 2025. 3
work page 2025
-
[2]
Stefan Andreas Baumann, Felix Krause, Michael Neumayr, Nick Stracke, Melvin Sevi, Vincent Tao Hu, and Bj¨orn Om- mer. Continuous, subject-specific attribute control in t2i models by identifying semantic directions, 2025. 3
work page 2025
-
[3]
Yoshua Bengio, J ´erˆome Louradour, Ronan Collobert, and Ja- son Weston. Curriculum learning. InProceedings of the 26th Annual International Conference on Machine Learn- ing, page 41–48, New York, NY , USA, 2009. Association for Computing Machinery. 1, 3
work page 2009
-
[4]
Im- proving image generation with better captions
James Betker, Gabriel Goh, Li Jing, † TimBrooks, Jian- feng Wang, Linjie Li, † LongOuyang, † JuntangZhuang, † JoyceLee, † YufeiGuo, † WesamManassra, † PrafullaDhari- wal, † CaseyChu, † YunxinJiao, and Aditya Ramesh. Im- proving image generation with better captions. 6
-
[5]
Make it count: Text-to-image gen- eration with an accurate number of objects, 2024
Lital Binyamin, Yoad Tewel, Hilit Segev, Eran Hirsch, Royi Rassin, and Gal Chechik. Make it count: Text-to-image gen- eration with an accurate number of objects, 2024. 3
work page 2024
-
[6]
Janus- pro: Unified multimodal understanding and generation with data and model scaling, 2025
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus- pro: Unified multimodal understanding and generation with data and model scaling, 2025. 6
work page 2025
-
[7]
Brown, Miljan Martic, Shane Legg, and Dario Amodei
Paul Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforcement learn- ing from human preferences, 2023. 1
work page 2023
-
[8]
Acquire and then adapt: Squeezing out text-to-image model for image restoration,
Junyuan Deng, Xinyi Wu, Yongxing Yang, Congchao Zhu, Song Wang, and Zhenyao Wu. Acquire and then adapt: Squeezing out text-to-image model for image restoration,
-
[9]
Lunhao Duan, Shanshan Zhao, Wenjun Yan, Yinglun Li, Qing-Guo Chen, Zhao Xu, Weihua Luo, Kaifu Zhang, Ming- ming Gong, and Gui-Song Xia. Unic-adapter: Unified image-instruction adapter with multi-modal transformer for image generation, 2024. 3
work page 2024
-
[10]
Scaling rectified flow trans- formers for high-resolution image synthesis, 2024
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, Kyle Lacey, Alex Goodwin, Yan- nik Marek, and Robin Rombach. Scaling rectified flow trans- formers for high-resolution image synthesis, 2024. 6, 7
work page 2024
-
[11]
Dpok: Reinforcement learning for fine-tuning text-to-image diffu- sion models, 2023
Ying Fan, Olivia Watkins, Yuqing Du, Hao Liu, Moonkyung Ryu, Craig Boutilier, Pieter Abbeel, Moham- mad Ghavamzadeh, Kangwook Lee, and Kimin Lee. Dpok: Reinforcement learning for fine-tuning text-to-image diffu- sion models, 2023. 1
work page 2023
-
[12]
Curran Associates Inc., Red Hook, NY , USA, 2019
Meng Fang, Tianyi Zhou, Yali Du, Lei Han, and Zhengyou Zhang.Curriculum-guided hindsight experience replay. Curran Associates Inc., Red Hook, NY , USA, 2019. 5
work page 2019
-
[13]
Towards understanding and quantifying uncertainty for text-to-image generation, 2024
Gianni Franchi, Dat Nguyen Trong, Nacim Belkhir, Guox- uan Xia, and Andrea Pilzer. Towards understanding and quantifying uncertainty for text-to-image generation, 2024. 3
work page 2024
-
[14]
Prompt curriculum learning for efficient llm post-training, 2025
Zhaolin Gao, Joongwon Kim, Wen Sun, Thorsten Joachims, Sid Wang, Richard Yuanzhe Pang, and Liang Tan. Prompt curriculum learning for efficient llm post-training, 2025. 3
work page 2025
-
[15]
Geneval: An object-focused framework for evaluating text- to-image alignment, 2023
Dhruba Ghosh, Hanna Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text- to-image alignment, 2023. 6
work page 2023
-
[16]
Walter R Gilks and Pascal Wild. Adaptive rejection sampling for gibbs sampling.Journal of the Royal Statistical Society: Series C (Applied Statistics), 41(2):337–348, 1992. 4
work page 1992
-
[17]
Bellemare, Jacob Menick, Remi Munos, and Koray Kavukcuoglu
Alex Graves, Marc G. Bellemare, Jacob Menick, Remi Munos, and Koray Kavukcuoglu. Automated curriculum learning for neural networks, 2017. 1, 2, 3
work page 2017
-
[18]
Deep poisson gamma dynamical systems.Advances in Neu- ral Information Processing Systems, 31, 2018
Dandan Guo, Bo Chen, Hao Zhang, and Mingyuan Zhou. Deep poisson gamma dynamical systems.Advances in Neu- ral Information Processing Systems, 31, 2018. 4
work page 2018
-
[19]
Ella: Equip diffusion models with llm for en- hanced semantic alignment, 2024
Xiwei Hu, Rui Wang, Yixiao Fang, Bin Fu, Pei Cheng, and Gang Yu. Ella: Equip diffusion models with llm for en- hanced semantic alignment, 2024. 6
work page 2024
-
[20]
Zijian Hu, Xiaoguang Gao, Kaifang Wan, Qianglong Wang, and Yiwei Zhai. Asynchronous curriculum experience re- play: A deep reinforcement learning approach for uav au- tonomous motion control in unknown dynamic environ- ments, 2022. 5
work page 2022
-
[21]
Kaiyi Huang, Chengqi Duan, Kaiyue Sun, Enze Xie, Zhen- guo Li, and Xihui Liu. T2i-compbench++: An enhanced and comprehensive benchmark for compositional text-to-image generation, 2025. 6
work page 2025
-
[22]
Silent branding attack: Trigger-free data poisoning attack on text-to-image diffusion models,
Sangwon Jang, June Suk Choi, Jaehyeong Jo, Kimin Lee, and Sung Ju Hwang. Silent branding attack: Trigger-free data poisoning attack on text-to-image diffusion models,
-
[23]
Chatgen: Automatic text- to-image generation from freestyle chatting, 2024
Chengyou Jia, Changliang Xia, Zhuohang Dang, Weijia Wu, Hangwei Qian, and Minnan Luo. Chatgen: Automatic text- to-image generation from freestyle chatting, 2024. 3
work page 2024
- [24]
-
[25]
Charging and rate control for elastic traffic
Frank Kelly. Charging and rate control for elastic traffic. European transactions on telecommunications, (1):8, 1997. 2
work page 1997
-
[26]
Frank P Kelly, Aman K Maulloo, and David Kim Hong Tan. Rate control for communication networks: shadow prices, proportional fairness and stability.Journal of the Opera- tional Research society, 49(3):237–252, 1998. 5
work page 1998
-
[27]
Eunji Kim, Siwon Kim, Minjun Park, Rahim Entezari, and Sungroh Yoon. Rethinking training for de-biasing text-to- image generation: Unlocking the potential of stable diffu- sion, 2025. 3
work page 2025
-
[28]
Pick-a-pic: an open dataset of user preferences for text-to-image generation
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Ma- tiana, Joe Penna, and Omer Levy. Pick-a-pic: an open dataset of user preferences for text-to-image generation. InPro- ceedings of the 37th International Conference on Neural In- formation Processing Systems, Red Hook, NY , USA, 2023. Curran Associates Inc. 1
work page 2023
-
[29]
Pascal Klink, Hany Abdulsamad, Boris Belousov, Carlo D’Eramo, Jan Peters, and Joni Pajarinen. A probabilistic interpretation of self-paced learning with applications to re- inforcement learning, 2021. 3
work page 2021
-
[30]
Pawan Kumar, Benjamin Packer, and Daphne Koller
M. Pawan Kumar, Benjamin Packer, and Daphne Koller. Self-paced learning for latent variable models.Curran As- sociates Inc., 2010. 3
work page 2010
-
[31]
Flux.1 kontext: Flow matching for in-context image generation and editing in latent space,
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dock- horn, Jack English, Zion English, Patrick Esser, Sumith Ku- lal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas Muller, Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer, and Luke Smith. Flux.1 kontext: Flow matching for in-context im...
-
[32]
2d-curri-dpo: Two- dimensional curriculum learning for direct preference opti- mization, 2025
Mengyang Li and Zhong Zhang. 2d-curri-dpo: Two- dimensional curriculum learning for direct preference opti- mization, 2025. 3
work page 2025
-
[33]
Curriculum-rlaif: Cur- riculum alignment with reinforcement learning from ai feed- back, 2025
Mengdi Li, Jiaye Lin, Xufeng Zhao, Wenhao Lu, Peilin Zhao, Stefan Wermter, and Di Wang. Curriculum-rlaif: Cur- riculum alignment with reinforcement learning from ai feed- back, 2025. 3
work page 2025
-
[34]
Yang Li, Yichuan Mo, Liangliang Shi, and Junchi Yan. Improving generative adversarial networks via adversarial learning in latent space.Advances in neural information pro- cessing systems, 35:8868–8881, 2022. 4
work page 2022
-
[35]
Dual diffusion for unified image generation and understanding, 2025
Zijie Li, Henry Li, Yichun Shi, Amir Barati Farimani, Yu- val Kluger, Linjie Yang, and Peng Wang. Dual diffusion for unified image generation and understanding, 2025. 3
work page 2025
-
[36]
Rich hu- man feedback for text-to-image generation, 2024
Youwei Liang, Junfeng He, Gang Li, Peizhao Li, Arseniy Klimovskiy, Nicholas Carolan, Jiao Sun, Jordi Pont-Tuset, Sarah Young, Feng Yang, Junjie Ke, Krishnamurthy Dj Dvi- jotham, Katie Collins, Yiwen Luo, Yang Li, Kai J Kohlhoff, Deepak Ramachandran, and Vidhya Navalpakkam. Rich hu- man feedback for text-to-image generation, 2024. 1
work page 2024
-
[37]
Flow-grpo: Training flow matching models via on- line rl, 2025
Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via on- line rl, 2025. 3, 6
work page 2025
-
[38]
Generating images from captions with attention, 2016
Elman Mansimov, Emilio Parisotto, Jimmy Lei Ba, and Rus- lan Salakhutdinov. Generating images from captions with attention, 2016. 1
work page 2016
-
[39]
Noise diffusion for enhancing semantic faithfulness in text-to-image synthesis,
Boming Miao, Chunxiao Li, Xiaoxiao Wang, Andi Zhang, Rui Sun, Zizhe Wang, and Yao Zhu. Noise diffusion for enhancing semantic faithfulness in text-to-image synthesis,
-
[40]
Ai alignment and social choice: Funda- mental limitations and policy implications, 2023
Abhilash Mishra. Ai alignment and social choice: Funda- mental limitations and policy implications, 2023. 1
work page 2023
-
[41]
Sanmit Narvekar, Bei Peng, Matteo Leonetti, Jivko Sinapov, Matthew E. Taylor, and Peter Stone. Curriculum learning for reinforcement learning domains: A framework and survey,
-
[42]
Jerzy Neyman. On the two different aspects of the rep- resentative method: the method of stratified sampling and the method of purposive selection. InBreakthroughs in statistics: Methodology and distribution, pages 123–150. Springer, 1992. 4
work page 1992
-
[43]
OpenAI, Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, and et al. Gpt-4o system card, 2024. 6
work page 2024
-
[44]
Rishubh Parihar, Vaibhav Agrawal, Sachidanand VS, and R. Venkatesh Babu. Compass control: Multi object orien- tation control for text-to-image generation, 2025. 1, 3
work page 2025
-
[45]
Curry-dpo: En- hancing alignment using curriculum learning & ranked pref- erences, 2024
Pulkit Pattnaik, Rishabh Maheshwary, Kelechi Ogueji, Vikas Yadav, and Sathwik Tejaswi Madhusudhan. Curry-dpo: En- hancing alignment using curriculum learning & ranked pref- erences, 2024. 3
work page 2024
- [46]
-
[47]
Sdxl: Improving latent diffusion models for high-resolution image synthesis, 2023
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Muller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis, 2023. 6
work page 2023
-
[48]
Automatic curriculum learning for deep rl: A short survey, 2020
R ´emy Portelas, C´edric Colas, Lilian Weng, Katja Hofmann, and Pierre-Yves Oudeyer. Automatic curriculum learning for deep rl: A short survey, 2020. 3
work page 2020
-
[49]
Samira Pouyanfar, Yudong Tao, Anup Mohan, Haiman Tian, Ahmed S. Kaseb, Kent Gauen, Ryan Dailey, Sarah Agha- janzadeh, Yung-Hsiang Lu, Shu-Ching Chen, and Mei-Ling Shyu. Dynamic sampling in convolutional neural networks for imbalanced data classification. In2018 IEEE Confer- ence on Multimedia Information Processing and Retrieval (MIPR), pages 112–117, 2018. 2
work page 2018
-
[50]
Self-cross diffu- sion guidance for text-to-image synthesis of similar subjects,
Weimin Qiu, Jieke Wang, and Meng Tang. Self-cross diffu- sion guidance for text-to-image synthesis of similar subjects,
-
[51]
Steps: Sequential probability tensor estimation for text-to-image hard prompt search
Yuning Qiu, Andong Wang, Chao Li, Haonan Huang, Guoxu Zhou, and Qibin Zhao. Steps: Sequential probability tensor estimation for text-to-image hard prompt search. InCVPR, pages 28640–28650, 2025. 3
work page 2025
-
[52]
Zero-shot text-to-image generation, 2021
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea V oss, Alec Radford, Mark Chen, and Ilya Sutskever. Zero-shot text-to-image generation, 2021. 3
work page 2021
-
[53]
High-resolution image syn- thesis with latent diffusion models, 2022
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bjorn Ommer. High-resolution image syn- thesis with latent diffusion models, 2022. 3
work page 2022
-
[54]
Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet, and Mohammad Norouzi. Photorealistic text-to-image diffusion models with deep language understanding, 2022. 3
work page 2022
-
[55]
Probabilistic curriculum learning for goal-based reinforcement learning, 2025
Llewyn Salt and Marcus Gallagher. Probabilistic curriculum learning for goal-based reinforcement learning, 2025. 3
work page 2025
-
[56]
Proximal policy optimization algo- rithms, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Rad- ford, and Oleg Klimov. Proximal policy optimization algo- rithms, 2017. 1, 3
work page 2017
-
[57]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. 1, 3, 5
work page 2024
-
[58]
Koushik Srivatsan, Fahad Shamshad, Muzammal Naseer, Vishal M. Patel, and Karthik Nandakumar. Stereo: A two- stage framework for adversarially robust concept erasing from text-to-image diffusion models, 2025. 3
work page 2025
-
[59]
Metropolis-hastings generative adversarial net- works
Ryan Turner, Jane Hung, Eric Frank, Yunus Saatchi, and Ja- son Yosinski. Metropolis-hastings generative adversarial net- works. InInternational Conference on Machine Learning, pages 6345–6353. PMLR, 2019. 4
work page 2019
-
[60]
Minority-focused text-to- image generation via prompt optimization, 2025
Soobin Um and Jong Chul Ye. Minority-focused text-to- image generation via prompt optimization, 2025. 3
work page 2025
-
[61]
John V on Neumann et al. Various techniques used in con- nection with random digits.John von Neumann, Collected Works, 5:768–770, 1963. 4
work page 1963
-
[62]
Wang, Songwei Ge, Tero Karras, Ming-Yu Liu, and Yogesh Balaji
Andrew Z. Wang, Songwei Ge, Tero Karras, Ming-Yu Liu, and Yogesh Balaji. A comprehensive study of decoder-only llms for text-to-image generation, 2025. 3
work page 2025
-
[63]
Adapting text-to-image generation with feature difference instruction for generic image restoration
Chao Wang, Hehe Fan, Huichen Yang, Sarvnaz Karimi, Lina Yao, and Yi Yang. Adapting text-to-image generation with feature difference instruction for generic image restoration. In2025 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 23539–23550, 2025. 3
work page 2025
-
[64]
Scaling down text encoders of text-to-image diffusion mod- els, 2025
Lifu Wang, Daqing Liu, Xinchen Liu, and Xiaodong He. Scaling down text encoders of text-to-image diffusion mod- els, 2025. 1
work page 2025
-
[65]
Unified reward model for multimodal understanding and generation, 2025
Yibin Wang, Yuhang Zang, Hao Li, Cheng Jin, and Jiaqi Wang. Unified reward model for multimodal understanding and generation, 2025. 1
work page 2025
-
[66]
Designdiffusion: High- quality text-to-design image generation with diffusion mod- els, 2025
Zhendong Wang, Jianmin Bao, Shuyang Gu, Dong Chen, Wengang Zhou, and Houqiang Li. Designdiffusion: High- quality text-to-design image generation with diffusion mod- els, 2025. 1
work page 2025
-
[67]
Dump: Automated distribution-level curricu- lum learning for rl-based llm post-training, 2025
Zhenting Wang, Guofeng Cui, Yu-Jhe Li, Kun Wan, and Wentian Zhao. Dump: Automated distribution-level curricu- lum learning for rl-based llm post-training, 2025. 3
work page 2025
-
[68]
Rob Wass and Clinton Golding. Sharpening a tool for teach- ing: the zone of proximal development.Teaching in Higher Education, 19(6):671–684, 2014. 3
work page 2014
-
[69]
Enze Xie, Junsong Chen, Yuyang Zhao, Jincheng Yu, Ligeng Zhu, Chengyue Wu, Yujun Lin, Zhekai Zhang, Muyang Li, Junyu Chen, Han Cai, Bingchen Liu, Daquan Zhou, and Song Han. Sana 1.5: Efficient scaling of training-time and inference-time compute in linear diffusion transformer,
-
[70]
Logic-rl: Unleashing llm reasoning with rule- based reinforcement learning, 2025
Tian Xie, Zitian Gao, Qingnan Ren, Haoming Luo, Yuqian Hong, Bryan Dai, Joey Zhou, Kai Qiu, Zhirong Wu, and Chong Luo. Logic-rl: Unleashing llm reasoning with rule- based reinforcement learning, 2025. 3
work page 2025
-
[71]
Focus- n-fix: Region-aware fine-tuning for text-to-image genera- tion, 2025
Xiaoying Xing, Avinab Saha, Junfeng He, Susan Hao, Paul Vicol, Moonkyung Ryu, Gang Li, Sahil Singla, Sarah Young, Yinxiao Li, Feng Yang, and Deepak Ramachandran. Focus- n-fix: Region-aware fine-tuning for text-to-image genera- tion, 2025. 3
work page 2025
-
[72]
Imagere- ward: Learning and evaluating human preferences for text- to-image generation, 2023
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagere- ward: Learning and evaluating human preferences for text- to-image generation, 2023. 1
work page 2023
-
[73]
The perfect blend: Redefining rlhf with mixture of judges, 2024
Tengyu Xu, Eryk Helenowski, Karthik Abinav Sankarara- man, Di Jin, Kaiyan Peng, Eric Han, Shaoliang Nie, Chen Zhu, Hejia Zhang, Wenxuan Zhou, Zhouhao Zeng, Yun He, Karishma Mandyam, Arya Talabzadeh, Madian Khabsa, Gabriel Cohen, Yuandong Tian, Hao Ma, Sinong Wang, and Han Fang. The perfect blend: Redefining rlhf with mixture of judges, 2024. 1
work page 2024
-
[74]
Scaling autoregressive models for content-rich text-to-image generation, 2022
Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gun- jan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yin- fei Yang, Burcu Karagol Ayan, Ben Hutchinson, Wei Han, Zarana Parekh, Xin Li, Han Zhang, Jason Baldridge, and Yonghui Wu. Scaling autoregressive models for content-rich text-to-image generation, 2022. 3
work page 2022
-
[75]
Learning to sample effective and diverse prompts for text-to-image generation, 2025
Taeyoung Yun, Dinghuai Zhang, Jinkyoo Park, and Ling Pan. Learning to sample effective and diverse prompts for text-to-image generation, 2025. 3 Curriculum Group Policy Optimization: Adaptive Sampling for Unleashing the Potential of Text-to-Image Generation Supplementary Material
work page 2025
-
[76]
To derive the analytical solution for the optimization problem in Eq
Derivation of the Category Calibration For- mula In this section, we present the detailed derivation process for our category calibration. To derive the analytical solution for the optimization problem in Eq. (6), we first expand the KL divergence term. The original problem is: max q cX i=1 log(qi)−λ·KL(v∥q), s.t.∀q i ≥0, cX i=1 qi = 1. (9) The KL diverge...
-
[77]
Further Details on the Experimental Setup Our CGPO framework builds upon the Flow-GRPO archi- tecture. The configuration uses a sampling timestepT= 10 during training andT= 40for evaluation, with an image group sizeG= 24, noise levela= 0.8, and image reso- lution 256. The KL ratio is set to 0.004 (0.04 for the fast variant). LoRA parameters are configured...
-
[78]
increasing reward with decreasing variance
Extended Experimental Results 8.1. Multiple Rewards Experimental For a controlled comparison, the reproduced 8-GPU Flow- GRPO uses the same batch size, rollout configuration, re- ward model, and training steps as CGPO, with the train- ing framework being the only difference. Following the evaluation protocol of Flow-GRPO, we train three separate models us...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.