ADMIT: Few-shot Knowledge Poisoning Attacks on RAG-based Fact Checking
Pith reviewed 2026-05-21 19:58 UTC · model grok-4.3
The pith
ADMIT flips RAG fact-checking decisions by injecting a tiny number of semantically aligned adversarial documents that override authentic evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ADMIT is a few-shot, semantically aligned poisoning attack that flips fact-checking decisions and induces deceptive justifications in RAG systems without access to the target LLMs, retrievers, or token-level control. It achieves an average attack success rate of 86 percent across tested settings and improves on prior attacks by 11.2 percent while remaining effective even when authentic counter-evidence is retrieved.
What carries the argument
ADMIT, the Adversarial Multi-Injection Technique, which generates a small number of adversarial documents semantically aligned with the input query so they are preferentially retrieved and override authentic evidence supplied to the language model.
If this is right
- RAG fact-checking pipelines can be manipulated by poisoning far less than one millionth of the knowledge base.
- The attack generalizes to new retrievers and language models without requiring white-box access or fine-tuning.
- Strong authentic evidence already present in the retrieval pool does not prevent the injected content from dominating the final output.
- Fact-checking applications must incorporate defenses against semantic multi-injection rather than relying solely on evidence volume or ranking.
Where Pith is reading between the lines
- Retrieval components may need secondary filters that check for unnatural repetition or template patterns in top-ranked documents.
- Knowledge bases used for verification could require regular integrity scans that flag clusters of near-duplicate content added in short time windows.
- Model providers might explore training objectives that encourage inconsistency detection when retrieved passages contain conflicting but similarly phrased claims.
Load-bearing premise
That attackers can create documents semantically close enough to a query for the retriever to surface them ahead of genuine evidence without any access to the system internals or model weights.
What would settle it
Measure whether the attack success rate falls below 20 percent when the retriever is altered to penalize documents whose embeddings cluster tightly with known adversarial templates while leaving all other retrieval behavior unchanged.
Figures










read the original abstract
Knowledge poisoning poses a critical threat to Retrieval-Augmented Generation (RAG) systems by injecting adversarial content into knowledge bases, tricking Large Language Models (LLMs) into producing attacker-controlled outputs grounded in manipulated context. Prior work highlights LLMs' susceptibility to misleading or malicious retrieved content. However, real-world fact-checking scenarios are more challenging, as credible evidence typically dominates the retrieval pool. To investigate this problem, we extend knowledge poisoning to the fact-checking setting, where retrieved context includes authentic supporting or refuting evidence. We propose \textbf{ADMIT} (\textbf{AD}versarial \textbf{M}ulti-\textbf{I}njection \textbf{T}echnique), a few-shot, semantically aligned poisoning attack that flips fact-checking decisions and induces deceptive justifications, all without access to the target LLMs, retrievers, or token-level control. Extensive experiments show that ADMIT transfers effectively across 4 retrievers, 11 LLMs, and 4 cross-domain benchmarks, achieving an average attack success rate (ASR) of 86\% at an extremely low poisoning rate of $0.93 \times 10^{-6}$, and remaining robust even in the presence of strong counter-evidence. Compared with prior state-of-the-art attacks, ADMIT improves ASR by 11.2\% across all settings, exposing significant vulnerabilities in real-world RAG-based fact-checking systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ADMIT, a few-shot semantically aligned knowledge poisoning attack targeting RAG-based fact-checking systems. Without access to target LLMs or retrievers, it injects a small number of adversarial documents to flip fact-checking decisions and generate deceptive justifications. Experiments report an average attack success rate of 86% at a poisoning rate of 0.93 × 10^{-6} across 4 retrievers, 11 LLMs, and 4 cross-domain benchmarks, with claimed robustness even when strong counter-evidence is present in the retrieval pool.
Significance. If the scaling and robustness results hold under realistic corpus sizes, the work provides concrete evidence of practical vulnerabilities in deployed RAG fact-checking pipelines. The breadth of the transferability evaluation across retrievers and LLMs is a strength, as is the explicit focus on settings where authentic evidence competes with poisoned content.
major comments (1)
- [§4 and §5] §4 (Experimental Setup) and §5 (Results): the total size of the knowledge base and the number of authentic supporting/refuting documents per query are not reported. Without these quantities it is impossible to verify that the claimed poisoning rate of 0.93 × 10^{-6} places the adversarial documents in realistic competition with a large authentic pool, which is central to the headline ASR and robustness claims.
minor comments (1)
- [Abstract] The abstract and introduction refer to '4 cross-domain benchmarks' without naming them; explicitly listing the datasets (and their sizes) in the abstract would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We appreciate the focus on ensuring that the experimental details allow readers to fully verify the realism of the reported poisoning rates and robustness results. We address the major comment below and commit to revisions that will strengthen the manuscript.
read point-by-point responses
-
Referee: [§4 and §5] §4 (Experimental Setup) and §5 (Results): the total size of the knowledge base and the number of authentic supporting/refuting documents per query are not reported. Without these quantities it is impossible to verify that the claimed poisoning rate of 0.93 × 10^{-6} places the adversarial documents in realistic competition with a large authentic pool, which is central to the headline ASR and robustness claims.
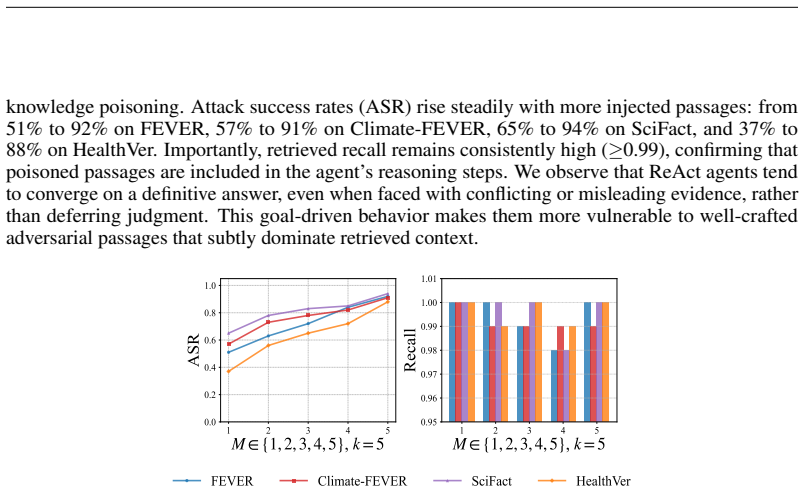
Authors: We agree that the current version of the manuscript does not provide an explicit consolidated report of the total knowledge base sizes or the per-query counts of authentic supporting/refuting documents, which would improve verifiability of the poisoning-rate claims. In our experimental setup the knowledge bases are the full corpora of the four benchmarks (with sizes ranging from roughly 4,000 documents for the smallest corpus to more than 100,000 for the largest). Retrieval is performed over the entire base, and the top-k results (k = 5–10) typically contain 3–8 authentic documents per query alongside the injected adversarial content. The 0.93 × 10^{-6} poisoning rate therefore corresponds to the insertion of only one to three adversarial documents into pools containing thousands of authentic items. We will revise §4 to include a new table that lists, for each benchmark, the exact knowledge-base size and the average number of authentic documents retrieved per query. This addition will directly support the headline ASR and robustness results without changing any experimental outcomes or conclusions. revision: yes
Circularity Check
No circularity: purely empirical attack evaluation with no derivations or self-referential reductions
full rationale
The paper proposes the ADMIT poisoning technique and reports its performance via direct experiments across retrievers, LLMs, and benchmarks. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. Attack success rates and robustness claims rest on experimental measurements rather than any chain that reduces to its own inputs by construction. The work is self-contained as an empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs remain susceptible to misleading or malicious retrieved content even when credible evidence is present in the retrieval pool
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose ADMIT (ADversarial Multi-Injection Technique), a few-shot, semantically aligned poisoning attack that flips fact-checking decisions... at an extremely low poisoning rate of 0.93 × 10^{-6}
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Needle-in-RAG: Prompt-Conditioned Character-Level Traceback of Poisoned Spans in Retrieved Evidence
RAGCharacter localizes poisoned character spans in RAG evidence via prompt-conditioned counterfactual masking and achieves the best accuracy-over-attribution trade-off across tested attacks and models.
Reference graph
Works this paper leans on
-
[1]
Ignore Previous Prompt: Attack Techniques For Language Models
URLhttps://aclanthology.org/2023.acl-long.386/. Yikang Pan, Liangming Pan, Wenhu Chen, Preslav Nakov, Min-Yen Kan, and William Wang. On the risk of misinformation pollution with large language models. InFindings of the As- sociation for Computational Linguistics: EMNLP 2023, pp. 1389–1403, Singapore, 2023b. Association for Computational Linguistics. doi: ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2023.findings-emnlp.97 2023
-
[2]
Robertson and Hugo Zaragoza , title =
URLhttps://arxiv.org/abs/2403.09858. Stephen Robertson and Hugo Zaragoza. The probabilistic relevance framework: Bm25 and beyond. In Gabriella Kazai, Peter Bailey, Ben Carterette, Vanessa Murdock, Douglas W. Oard, Iadh Ounis, and Mark Sanderson (eds.),Foundations and Trends in Information Retrieval, volume 3 ofFnT IR, pp. 333–389. Now Publishers, 2009. do...
-
[3]
URLhttps://aclanthology.org/2020
Association for Computational Linguistics, 2020. URLhttps://aclanthology.org/2020. emnlp-main.609. Fei Wang, Xingchen Wan, Ruoxi Sun, Jiefeng Chen, and Sercan O Arik. Astute RAG: Overcoming imperfect retrieval augmentation and knowledge conflicts for large language models, 2024. URL https://openreview.net/forum?id=xy6B5Fh2v7. Haoran Wang and Kai Shu. Expl...
work page 2020
-
[4]
doi: 10.18653/v1/2023.findings-emnlp.416
Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-emnlp.416. URLhttps://aclanthology.org/2023.findings-emnlp.416/. Yuxia Wang, Minghan Wang, Hasan Iqbal, Georgi N. Georgiev, Jiahui Geng, Iryna Gurevych, and Preslav Nakov. OpenFactCheck: Building, benchmarking customized fact-checking systems and evaluating the factuality of claims ...
-
[5]
Universal and Transferable Adversarial Attacks on Aligned Language Models
URLhttps://arxiv.org/abs/2307.15043. Wei Zou, Runpeng Geng, Binghui Wang, and Jinyuan Jia. Poisonedrag: Knowledge corruption attacks to retrieval-augmented generation of large language models.arXiv preprint arXiv:2402.07867,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
URLhttps://arxiv.org/abs/2402.07867. Wei Zou, Runpeng Geng, Binghui Wang, and Jinyuan Jia. Poisonedrag: Knowledge corruption attacks to retrieval-augmented generation of large language models. InProceedings of the 34th USENIX Security Symposium, 2025. URLhttps://arxiv.org/abs/2402.07867. 15 Supplementary Material Table of Contents A Implementation Details...
-
[9]
Generate a revised passage to override the contradicting evidence. Please always respond with JSON during fol- lowing conversation: { "analysis": "...", "strategy": "...", "passage": "Your new passage inV words." } Table 10: Prompt templates for query generation and RAG-based fact-checking. Query Generation Template You are an expert at extracting compact...
-
[10]
Generate concise queries (3–10 words)
-
[11]
Maximize search ability
-
[12]
Cover key information points
-
[13]
Avoid vague language. Query: Mary is a five-year-old girl who likes playing piano and doesn’t like cookies. Output: Mary’s age is five, Mary’s piano skills, Mary’s food preferences Query: [Query] RAG Fact-Checking Template You are a helpful verification assistant. Below is a claim from the user and some relevant context. Verify whether the claim is suppor...
work page 2023
-
[14]
NEI” refers to cases where verifier response with “Not Enough Information
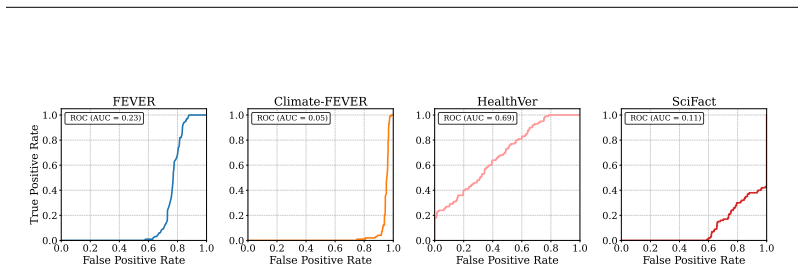
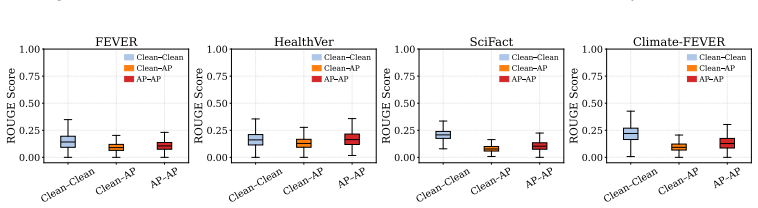
using ROUGE-N scores (Lin, 2004). This method is designed to detect sparse adversarial insertions by identifying passages that deviate from the dominant n-gram patterns within the retrieved set. Following the same 1-shot setting as PPL, we compute pairwise ROUGE-1 F1 scores among all retrieved passages to identify anomalous entries. Figure 5 show experime...
work page 2004
-
[15]
Explain why the previous verification failed
-
[16]
Propose a new strategy to improve the passage
-
[17]
Generate a revised passage to override the contradicting evidence. Please always respond with JSON during fol- lowing conversation: { "analysis": "...", "strategy": "...", "passage": "Your new passage inV words." } NEI Claim for LLMs Claim:Leslie Groves graduated tenth in his class. LLMs:NOT ENOUGH INFORMATION. The claim that Leslie Groves graduated tenth...
work page 1970
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.