Off-the-Shelf LLMs as Process Scorers: Training-Free Alternative to PRMs for Mathematical Reasoning
Pith reviewed 2026-06-28 15:11 UTC · model grok-4.3
The pith
Off-the-shelf large models can steer small ones through math reasoning by scoring fixed-length chunks without training a reward model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
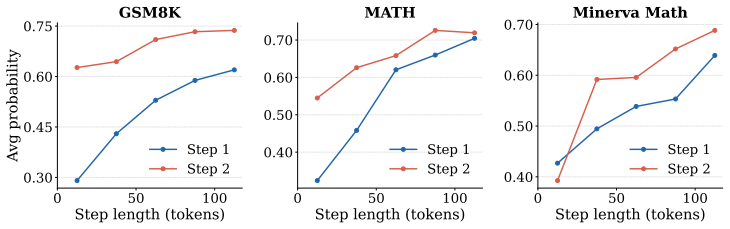
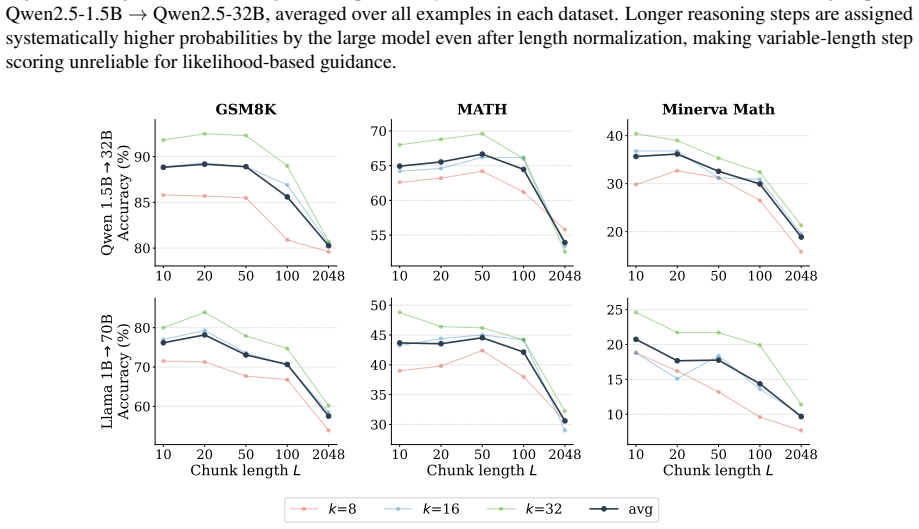
Chunk-Level Guided Generation samples k fixed-length candidate chunks from the small model at each reasoning step and scores them with an off-the-shelf larger model using length-normalized log-probabilities or a contrastive difference that subtracts the small model's own probability; the highest-scoring chunk is appended and the process repeats. This steers generation before errors propagate and yields shorter final traces than process-reward-model search while matching or exceeding its accuracy on GSM8K, MATH, Minerva Math, AMC23, and AIME24 under matched budgets.
What carries the argument
Chunk-Level Guided Generation, which uses fixed-length chunk proposals scored by large-model likelihoods (via Likelihood-Guided Selection or Contrastive-Guided Selection) to select the next segment without any reward-model training.
Load-bearing premise
Large-model likelihoods computed on fixed-length text chunks reliably signal which reasoning step is correct.
What would settle it
A direct comparison in which CGS accuracy falls below majority voting once the large scorer is replaced by a model of similar size to the generator.
Figures

read the original abstract
Selecting the best response from multiple small-model samples using a stronger scorer is a simple inference-time strategy, but fails when the small model has already committed to incorrect reasoning paths. PRM guided search avoids this by scoring candidate continuations during generation, but requires a reward model trained with step-level labels. We propose Chunk-Level Guided Generation, a training-free alternative that uses an off-the-shelf large language model as a process scorer. At each step, a small model samples k fixed-length candidate chunks, while the larger model scores the candidates using likelihoods without generating any text. The selected chunk is committed before the next step, steering generation before errors can propagate. We instantiate this framework with two selection rules: Likelihood-Guided Selection (LGS), which selects the chunk with the highest length-normalized large-model log-probability, and Contrastive-Guided Selection (CGS), which subtracts the small model's log-probability to favor chunks where the large model's preference diverges from the small model's. We show that scoring variable-length reasoning steps with large-model likelihoods is unreliable due to a systematic length bias that persists even after length normalization, and that fixed-length chunks avoid this confound. On GSM8K, MATH, Minerva Math, AMC23, and AIME24 with Qwen2.5-1.5B guided by Qwen2.5-32B and Llama-3.2-1B guided by Llama-3.1-70B, CGS outperforms majority voting by up to 28 pp and, under matched guidance budgets, matches or outperforms Qwen2.5-Math-PRM-72B guided search on most benchmarks without reward-model training. With Qwen2.5-7B guided by Qwen2.5-72B, CGS reaches 81.8% on MATH and 63.6% on Minerva Math at k=16, surpassing majority voting by 4--6 pp. Finally, Chunk-Level Guided Generation produces substantially shorter reasoning traces than PRM guided search.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Chunk-Level Guided Generation, a training-free method that uses an off-the-shelf large LLM to score fixed-length chunks sampled by a smaller model during generation. It introduces Likelihood-Guided Selection (LGS) and Contrastive-Guided Selection (CGS) rules based on length-normalized log-probabilities, claims that variable-length scoring suffers from persistent length bias while fixed-length chunks avoid it, and reports that CGS outperforms majority voting by up to 28 pp and matches or exceeds Qwen2.5-Math-PRM-72B guided search on GSM8K, MATH, Minerva Math, AMC23, and AIME24 without any reward-model training.
Significance. If the performance gains hold under controlled conditions, the work demonstrates a practical inference-time alternative to trained process reward models for mathematical reasoning, reducing reliance on step-level annotations while producing shorter traces than PRM search.
major comments (2)
- The central mechanism claim—that fixed-length chunk log-likelihoods (especially contrastive) reliably signal correct reasoning steps rather than surface fluency or model biases—lacks direct support. All reported gains are aggregate benchmark accuracies; the manuscript provides no chunk-level validation, human annotations of step correctness, or controls that would distinguish process guidance from alternative explanations such as the large model imposing its own generation style.
- The length-bias analysis for variable-length scoring is noted in the abstract, but the claim that fixed-length chunks fully eliminate confounds for process scoring requires additional evidence (e.g., correlation studies or ablations) to be load-bearing for the superiority over majority voting and trained PRMs.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment point by point below, with clarifications on the existing evidence and proposed revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: The central mechanism claim—that fixed-length chunk log-likelihoods (especially contrastive) reliably signal correct reasoning steps rather than surface fluency or model biases—lacks direct support. All reported gains are aggregate benchmark accuracies; the manuscript provides no chunk-level validation, human annotations of step correctness, or controls that would distinguish process guidance from alternative explanations such as the large model imposing its own generation style.
Authors: We agree that direct chunk-level validation (e.g., human annotations of step correctness or explicit controls for style imposition) is not present and would provide stronger mechanistic evidence. The current support is indirect but multifaceted: (1) CGS, which explicitly subtracts the small model's log-probabilities, outperforms both LGS and majority voting by substantial margins, which would not be expected if gains stemmed only from the large model imposing its generation style; (2) the method matches or exceeds a trained 72B PRM under matched budgets on five benchmarks, suggesting the likelihood signals capture process-relevant information; and (3) the length-bias analysis already distinguishes the approach from naive likelihood scoring. Nevertheless, we will add a dedicated limitations subsection discussing alternative explanations and qualitative examples of chunk selections to make these distinctions more explicit. revision: partial
-
Referee: The length-bias analysis for variable-length scoring is noted in the abstract, but the claim that fixed-length chunks fully eliminate confounds for process scoring requires additional evidence (e.g., correlation studies or ablations) to be load-bearing for the superiority over majority voting and trained PRMs.
Authors: The manuscript demonstrates that length bias persists in variable-length scoring even after normalization, motivating the fixed-length design. Fixed-length chunks standardize the unit being scored, thereby removing length as a variable. We acknowledge that additional correlation studies between chunk scores and independent measures of correctness would make this claim more robust and load-bearing. We will incorporate further ablations and correlation analyses in the revised version to directly address this point. revision: yes
Circularity Check
No circularity: empirical method with external benchmark validation
full rationale
The paper proposes Chunk-Level Guided Generation as a training-free inference method that scores fixed-length chunks via off-the-shelf LLM log-likelihoods (LGS: length-normalized large-model log-prob; CGS: contrastive subtraction of small-model log-prob). These rules are defined directly from probability outputs without fitting parameters to target outcomes or redefining quantities in terms of themselves. All reported gains (e.g., +28 pp over majority voting, matching trained PRMs) are measured on external benchmarks (GSM8K, MATH, etc.) against independent baselines; no self-citation chains, uniqueness theorems, or ansatzes from prior author work are invoked as load-bearing. The length-bias observation justifies the fixed-chunk design but does not create a self-referential loop. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Off-the-shelf large language models' likelihoods on fixed-length text chunks can be used to score the quality of reasoning steps.
Reference graph
Works this paper leans on
-
[1]
The Eleventh International Conference on Learning Representations , year =
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author =. The Eleventh International Conference on Learning Representations , year =
-
[2]
arXiv preprint arXiv:2407.21787 , year =
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling , author =. arXiv preprint arXiv:2407.21787 , year =
-
[3]
Charlie Snell and Jaehoon Lee and Kelvin Xu and Aviral Kumar , journal =. Scaling
-
[4]
arXiv preprint arXiv:2305.20050 , year =
Let's Verify Step by Step , author =. arXiv preprint arXiv:2305.20050 , year =
-
[5]
Measuring Mathematical Problem Solving With the
Dan Hendrycks and Collin Burns and Saurav Kadavath and Akul Arora and Steven Basart and Eric Tang and Dawn Song and Jacob Steinhardt , journal =. Measuring Mathematical Problem Solving With the
-
[6]
Math-Shepherd: Verify and Reinforce
Peiyi Wang and Lei Li and Zhihong Sheng and Runxin Xu and Damai Dai and Yifei Li and Deli Chen and Yu Wu and Zhifang Sui , booktitle =. Math-Shepherd: Verify and Reinforce
-
[7]
Shuaijie She and Junxiao Liu and Yifeng Liu and Jiajun Chen and Xin Huang and Shujian Huang , journal =
-
[8]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , year =
Contrastive Decoding: Open-ended Text Generation as Optimization , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , year =
-
[9]
Proceedings of the 40th International Conference on Machine Learning , year =
Fast Inference from Transformers via Speculative Decoding , author =. Proceedings of the 40th International Conference on Machine Learning , year =
-
[10]
arXiv preprint arXiv:2302.01318 , year =
Accelerating Large Language Model Decoding with Speculative Sampling , author =. arXiv preprint arXiv:2302.01318 , year =
-
[11]
arXiv preprint arXiv:2504.12329 , year =
Speculative Thinking: Enhancing Small-Model Reasoning with Large Model Guidance at Inference Time , author =. arXiv preprint arXiv:2504.12329 , year =
-
[12]
arXiv preprint arXiv:2302.09664 , year =
Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation , author =. arXiv preprint arXiv:2302.09664 , year =
-
[13]
Miao Xiong and Zhiyuan Hu and Xinyang Lu and Yifei Li and Jie Fu and Junxian He and Bryan Hooi , journal =. Can
-
[14]
arXiv preprint arXiv:2110.14168 , year =
Training Verifiers to Solve Math Word Problems , author =. arXiv preprint arXiv:2110.14168 , year =
-
[15]
Scalable Best-of-
Zhewei Kang and Xuandong Zhao and Dawn Song , booktitle =. Scalable Best-of-
-
[16]
An Yang and Beichen Zhang and Binyuan Hui and Bofei Gao and Bowen Yu and Chengpeng Li and Dayiheng Liu and Jianhong Tu and Jingren Zhou and Junyang Lin and Keming Lu and Mingfeng Xue and Runji Lin and Tianyu Liu and Xingzhang Ren and Zhenru Zhang , journal =
-
[17]
arXiv preprint arXiv:2211.14275 , year =
Solving Math Word Problems with Process- and Outcome-Based Feedback , author =. arXiv preprint arXiv:2211.14275 , year =
-
[18]
arXiv preprint arXiv:2206.14858 , year =
Solving Quantitative Reasoning Problems with Language Models , author =. arXiv preprint arXiv:2206.14858 , year =
-
[19]
Qwen Team , journal =
-
[20]
arXiv preprint arXiv:2407.21783 , year =
The. arXiv preprint arXiv:2407.21783 , year =
-
[21]
arXiv preprint arXiv:2309.09117 , year =
Contrastive Decoding Improves Reasoning in Large Language Models , author =. arXiv preprint arXiv:2309.09117 , year =
-
[22]
arXiv preprint arXiv:2405.19262 , year =
Weak-to-Strong Search: Align Large Language Models via Searching over Small Language Models , author =. arXiv preprint arXiv:2405.19262 , year =
-
[23]
Muhammad Khalifa and Lajanugen Logeswaran and Moontae Lee and Honglak Lee and Lu Wang , journal =
-
[24]
Haojin Wang and Yike Wang and Shangbin Feng and Hannaneh Hajishirzi and Yulia Tsvetkov , journal =
-
[25]
arXiv preprint arXiv:2604.23623 , year =
Tandem: Riding Together with Large and Small Language Models for Efficient Reasoning , author =. arXiv preprint arXiv:2604.23623 , year =
-
[26]
Mert Cemri and Nived Rajaraman and Rishabh Tiwari and Xiaoxuan Liu and Kurt Keutzer and Ion Stoica and Kannan Ramchandran and Ahmad Beirami and Ziteng Sun , journal =
-
[27]
Reward-Guided Speculative Decoding for Efficient
Baohao Liao and Yuhui Xu and Hanze Dong and Junnan Li and Christof Monz and Silvio Savarese and Doyen Sahoo and Caiming Xiong , journal =. Reward-Guided Speculative Decoding for Efficient
-
[28]
arXiv preprint arXiv:2406.06592 , year =
Improve Mathematical Reasoning in Language Models by Automated Process Supervision , author =. arXiv preprint arXiv:2406.06592 , year =
-
[29]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
-
[30]
arXiv preprint arXiv:2501.07301 , year =
The Lessons of Developing Process Reward Models in Mathematical Reasoning , author =. arXiv preprint arXiv:2501.07301 , year =
-
[32]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[33]
arXiv preprint arXiv:2210.00720 , year=
Complexity-based prompting for multi-step reasoning , author=. arXiv preprint arXiv:2210.00720 , year=
-
[34]
Preferring Shorter Thinking Chains for Improved LLM Reasoning , author=
Don't Overthink it. Preferring Shorter Thinking Chains for Improved LLM Reasoning , author=. arXiv preprint arXiv:2505.17813 , year=
-
[35]
arXiv preprint arXiv:2502.07266 , year=
When more is less: Understanding chain-of-thought length in llms , author=. arXiv preprint arXiv:2502.07266 , year=
-
[36]
arXiv preprint arXiv:2604.10739 , year=
When More Thinking Hurts: Overthinking in LLM Test-Time Compute Scaling , author=. arXiv preprint arXiv:2604.10739 , year=
-
[37]
arXiv preprint arXiv:2510.21049 , year=
Reasoning's Razor: Reasoning Improves Accuracy but Can Hurt Recall at Critical Operating Points in Safety and Hallucination Detection , author=. arXiv preprint arXiv:2510.21049 , year=
-
[38]
arXiv preprint arXiv:2412.01981 , year=
Free process rewards without process labels , author=. arXiv preprint arXiv:2412.01981 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.