CAPRA: Scaling Feedback on Software Architecture Deliverables with a Multi-Agent LLM System
Pith reviewed 2026-06-26 20:09 UTC · model grok-4.3
The pith
CAPRA uses multiple LLM agents plus fuzzy evidence matching to generate reliable feedback on student software architecture reports.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CAPRA coordinates specialized agents with a Python microservice for multi-modal extraction and applies Evidence Anchoring via normalized Levenshtein fuzzy matching together with a ConsistencyManager that cross-verifies and deduplicates findings, allowing the system to produce template-compliant feedback while satisfying 88.8 percent of evaluation criteria on ten student reports and achieving kappa 0.582 agreement with human raters.
What carries the argument
The Evidence Anchoring step using fuzzy matching via normalized Levenshtein distance together with the ConsistencyManager agent that cross-verifies, deduplicates, and merges agent findings.
If this is right
- Each report can be processed in slightly over four minutes without manual extraction of text or diagrams.
- Feedback meets 88.8 percent of the eight-criterion taxonomy under strict aggregation.
- Moderate inter-rater agreement (kappa 0.582) is reached with human evaluators on the same reports.
- Template and tone compliance can be enforced while still flagging specific traceability and completeness issues.
Where Pith is reading between the lines
- The same anchoring-plus-consistency pattern could be tested on other document types such as requirements specifications or design documents.
- Processing time and criterion scores might change if the underlying vision model or fuzzy-matching threshold is altered.
- The current eight-criterion taxonomy could be expanded to include additional dimensions such as diagram clarity or notation consistency.
Load-bearing premise
The Evidence Anchoring step and ConsistencyManager will reliably prevent hallucinations and produce educationally accurate feedback on structural completeness and requirements traceability for varied student submissions.
What would settle it
Running the system on a new set of at least 30 architecture reports from a different course or institution and measuring whether the strict two-rater criterion satisfaction rate stays above 80 percent or drops due to missed issues or unsupported claims.
Figures

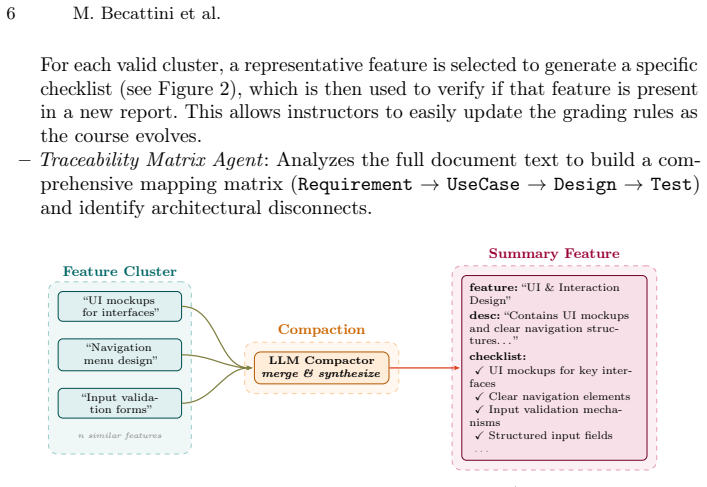
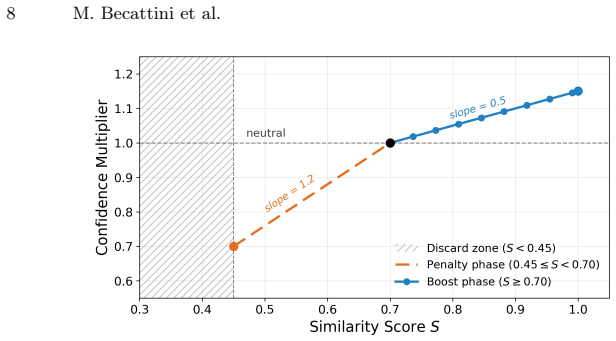
read the original abstract
Automated assessment in software engineering education has advanced significantly for code grading and essay scoring. However, reviewing software architecture deliverables, which requires analyzing structural completeness and requirements traceability, has not yet been fully automated. Applying Large Language Models (LLMs) to this task requires robust architectures to ensure technical feedback is accurate and reliable for students. This paper presents CAPRA (Configurable Architecture Proficiency Report Assessment), a multi-agent LLM system that analyzes software architecture deliverables to generate personalized, template-compliant LaTeX feedback. As a core design choice, CAPRA coordinates multiple specialized agents and employs a Python-based microservice for multi-modal document extraction, utilizing PyMuPDF and vision-enabled LLMs (specifically gpt-4o) to parse text and UML diagrams. To ensure educational reliability and mitigate hallucinations, CAPRA introduces a deterministic Evidence Anchoring step using fuzzy matching via normalized Levenshtein distance, along with a ConsistencyManager agent that cross-verifies, deduplicates, and merges findings. System performance is assessed using a structured eight-criterion binary evaluation taxonomy covering: (i) extraction completeness, (ii) feature validation, (iii) issue grounding and severity detection, (iv) recommendation specificity and traceability, and (v) template and tone compliance. A preliminary empirical evaluation on 10 student reports shows that CAPRA satisfied 88.8% of the evaluated criteria under a strict two-rater aggregation rule, achieved moderate inter-rater agreement with human evaluators (kappa = 0.582), and processed each report in slightly over 4 minutes. While these results support the viability of LLM-supported architectural feedback, human oversight remains essential for subjective assessment dimensions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents CAPRA, a multi-agent LLM system for automated assessment of software architecture deliverables. It coordinates specialized agents with a Python microservice for multi-modal extraction (PyMuPDF and gpt-4o for text and UML diagrams), employs deterministic Evidence Anchoring via normalized Levenshtein fuzzy matching to ground feedback, and uses a ConsistencyManager agent for cross-verification. Feedback is generated as template-compliant LaTeX. A preliminary evaluation on 10 student reports using an eight-criterion taxonomy reports 88.8% criterion satisfaction under strict two-rater aggregation, moderate inter-rater agreement (kappa=0.582), and average processing time slightly over 4 minutes per report. The authors note that human oversight remains necessary for subjective dimensions.
Significance. If the anchoring and consistency mechanisms prove reliable across varied submissions, the work could meaningfully advance scalable, personalized feedback in software engineering education for complex tasks like structural completeness and requirements traceability. Strengths include the explicit design to mitigate hallucinations through deterministic grounding, the structured multi-agent coordination, and the use of a binary taxonomy for evaluation. These elements provide a concrete engineering contribution. The preliminary scale of the evaluation, however, constrains the immediate significance pending further validation.
major comments (2)
- [Methods (Evidence Anchoring)] Methods section (Evidence Anchoring step): The reliability claim rests on normalized Levenshtein fuzzy matching to anchor feedback to source spans and prevent ungrounded judgments. No ablation study, threshold sensitivity analysis, or failure-case examination is reported for paraphrased requirements or non-identical UML descriptions common in student reports. Because the matching is surface-string based, systematic retrieval failures would directly affect downstream severity and traceability outputs and thereby the reported 88.8% success rate.
- [Evaluation] Evaluation section: The performance numbers (88.8% criterion satisfaction, kappa=0.582) derive from only 10 reports. The manuscript does not detail the report selection process, the precise operationalization of each of the eight taxonomy criteria, or the full inter-rater data matrix. These omissions make it difficult to assess whether the moderate agreement and high satisfaction rate generalize or are sensitive to rater subjectivity.
minor comments (1)
- [Abstract] Abstract: The eight-criterion taxonomy is summarized at a high level; a concise enumerated list or reference to a table in the main text would improve immediate readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that greater transparency on the Evidence Anchoring implementation and the evaluation protocol is warranted. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Methods (Evidence Anchoring)] Methods section (Evidence Anchoring step): The reliability claim rests on normalized Levenshtein fuzzy matching to anchor feedback to source spans and prevent ungrounded judgments. No ablation study, threshold sensitivity analysis, or failure-case examination is reported for paraphrased requirements or non-identical UML descriptions common in student reports. Because the matching is surface-string based, systematic retrieval failures would directly affect downstream severity and traceability outputs and thereby the reported 88.8% success rate.
Authors: We accept that the current description is insufficient. The normalized Levenshtein threshold (0.75) was chosen to keep anchoring deterministic and independent of additional LLM calls. In the revised manuscript we will add a dedicated paragraph in the Methods section that (a) reports the threshold selection rationale, (b) presents a post-hoc sensitivity check on the 10 reports showing how criterion satisfaction changes at thresholds 0.65–0.85, and (c) enumerates the observed failure modes (primarily paraphrased functional requirements and diagram labels that differ in wording but not semantics). We will also state explicitly that surface-string matching remains a limitation and that embedding-based retrieval is planned for future versions. These additions will allow readers to assess the robustness of the 88.8 % figure without requiring new experiments at this stage. revision: partial
-
Referee: [Evaluation] Evaluation section: The performance numbers (88.8% criterion satisfaction, kappa=0.582) derive from only 10 reports. The manuscript does not detail the report selection process, the precise operationalization of each of the eight taxonomy criteria, or the full inter-rater data matrix. These omissions make it difficult to assess whether the moderate agreement and high satisfaction rate generalize or are sensitive to rater subjectivity.
Authors: We agree that additional methodological detail is needed. The revised manuscript will include: (1) a description of the report selection process (random sample of 10 consenting submissions from one undergraduate software architecture course), (2) an appendix that gives the exact operational definition and scoring rubric for each of the eight criteria together with one positive and one negative example per criterion, and (3) the complete per-criterion inter-rater agreement table (or at minimum the raw agreement counts underlying the reported kappa). These changes will improve reproducibility while preserving the explicitly preliminary framing of the evaluation. revision: yes
Circularity Check
No significant circularity; metrics from independent human evaluation
full rationale
The paper reports empirical metrics (88.8% criterion satisfaction, kappa=0.582) obtained via external human-rater comparison against a fixed eight-criterion taxonomy. These quantities are not derived from or equivalent to any internal system parameters, fitted values, or self-citations. No equations, predictions, or uniqueness claims reduce to inputs by construction. The Evidence Anchoring mechanism is a design choice whose reliability is externally tested rather than tautological. This is the normal case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Computer Science Education15(2), 83–102 (2005)
Ala-Mutka, K.M.: A survey of automated assessment approaches for programming assignments. Computer Science Education15(2), 83–102 (2005)
2005
-
[2]
Becattini et al
Artifex Software, Inc.: PyMuPDF: Python bindings for MuPDF (2024), https: //pymupdf.readthedocs.io, version 1.24, accessed 2024 18 M. Becattini et al
2024
-
[3]
Becattini, M., Verdecchia, R., Vicario, E.: SALLMA: A software architecture for LLM-based multi-agent systems. In: Proceedings of the IEEE/ACM International Workshop on New Trends in Software Architecture (SATrends). pp. 5–8 (2025). https://doi.org/10.1109/SATrends66715.2025.00006
-
[4]
In: Proceedings of the 17th International Conference on Computer Supported Education, CSEDU 2025
Bouali, N., Gerhold, M., Rehman, T.U., Ahmed, F.: Toward automated UML diagram assessment: Comparing LLM-generated scores with teaching assistants. In: Proceedings of the 17th International Conference on Computer Supported Education, CSEDU 2025. vol. 1, pp. 158–169 (2025). https://doi.org/10.5220/ 0013481900003932
2025
-
[5]
In: Advances in Neural Information Processing Systems 33
Brown, T.B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., et al.: Language models are few-shot learners. In: Advances in Neural Information Processing Systems 33. vol. 33, pp. 1877–1901 (2020)
1901
-
[6]
In: Advances in Knowledge Discovery and Data Mining – PAKDD 2013
Campello, R.J.G.B., Moulavi, D., Sander, J.: Density-based clustering based on hierarchical density estimates. In: Advances in Knowledge Discovery and Data Mining – PAKDD 2013. Lecture Notes in Computer Science, vol. 7819, pp. 160–172. Springer (2013). https://doi.org/10.1007/978-3-642-37456-2_14
-
[7]
In: The Twelfth International Conference on Learning Representations (2024)
Chen, W., Su, Y., Zuo, J., Yang, C., Yuan, C., Chan, C.M., Yu, H., Lu, Y., Hung, Y.H., Qian, C., Qin, Y., Cong, X., Xie, R., Liu, Z., Sun, M., Zhou, J.: AgentVerse: Facilitating multi-agent collaboration and exploring emergent behaviors. In: The Twelfth International Conference on Learning Representations (2024)
2024
-
[8]
Chu, Z., Wang, S., Xie, J., Zhu, T., Yan, Y., Ye, J., Zhong, A., Hu, X., Liang, J., Yu, P.S., Wen, Q.: LLM agents for education: Advances and applications. In: Christodoulopoulos, C., Chakraborty, T., Rose, C., Peng, V. (eds.) Findings of the Association for Computational Linguistics: EMNLP 2025. pp. 13782–13810. Association for Computational Linguistics,...
-
[9]
Educational and Psycho- logical Measurement20(1), 37–46 (1960)
Cohen, J.: A coefficient of agreement for nominal scales. Educational and Psycho- logical Measurement20(1), 37–46 (1960)
1960
-
[10]
Applied Sciences15(10), 5683 (2025)
Emirtekin, E.: Large language model-powered automated assessment: A sys- tematic review. Applied Sciences15(10), 5683 (2025). https://doi.org/10.3390/ app15105683, https://www.mdpi.com/2076-3417/15/10/5683
2025
-
[11]
Guo, T., Chen, X., Wang, Y., Chang, R., Pei, S., Chawla, N.V., Wiest, O., Zhang, X.: Large language model based multi-agents: A survey of progress and challenges. In: Larson, K. (ed.) Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, IJCAI-24. pp. 8048–8057. International Joint Conferences on Artificial Intelligenc...
-
[12]
Review of Educational Research 77(1), 81–112 (2007)
Hattie, J., Timperley, H.: The power of feedback. Review of Educational Research 77(1), 81–112 (2007)
2007
-
[13]
In: The Twelfth International Conference on Learning Representations (2024)
Hong, S., Zhuge, M., Chen, J., Zheng, X., Cheng, Y., Zhang, C., Wang, J., Wang, Z., Yau, S.K.S., Lin, Z., Zhou, L., Ran, C., Xiao, L., Wu, C., Schmidhuber, J.: MetaGPT: Meta programming for a multi-agent collaborative framework. In: The Twelfth International Conference on Learning Representations (2024)
2024
-
[14]
Large Language Models for Software Engineering: A Systematic Literature Review.ACM Trans
Hou, X., Zhao, Y., Liu, Y., Yang, Z., Wang, K., Li, L., Luo, X., Lo, D., Grundy, J., Wang, H.: Large language models for software engineering: A systematic literature review. ACM Transactions on Software Engineering and Methodology33(8), 1–79 (2024). https://doi.org/10.1145/3695988, article 220
-
[15]
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X., Qin, B., Liu, T.: A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Trans. Inf. Syst.43(2), 1–55 (Jan 2025). https://doi.org/10.1145/3703155 CAPRA: Scaling Feedback on Software Architecture Deliverables 19
-
[16]
In: Proceedings of the 10th Koli Calling International Conference on Computing Education Research
Ihantola, P., Ahoniemi, T., Karavirta, V., Seppälä, O.: Review of recent systems for automatic assessment of programming assignments. In: Proceedings of the 10th Koli Calling International Conference on Computing Education Research. pp. 86–93 (2010)
2010
-
[17]
Khasentino, J., Belyaeva, A., Liu, X., Yang, Z., Furlotte, N
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y., Ishii, E., Bang, Y.J., Madotto, A., Fung, P.: Survey of hallucination in natural language generation. ACM Comput. Surv.55(12), 1–38 (Mar 2023). https://doi.org/10.1145/3571730
-
[18]
Learning and Individual Differences103, 102274 (2023)
Kasneci, E., Seßler, K., Küchemann, S., Bannert, M., Dementieva, D., Fischer, F., Gasser, U., Groh, G., Günnemann, S., Hüllermeier, E., Krusche, S., Kutyniok, G., Michaeli, T., Nerdel, C., Pfeffer, J., Poquet, O., Sailer, M., Schmidt, A., Seidel, T., Stadler, M., Weller, J., Kuhn, J., Kasneci, G.: ChatGPT for good? On opportunities and challenges of large...
2023
-
[19]
ACM Trans
Keuning, H., Jeuring, J., Heeren, B.: A systematic literature review of automated feedback generation for programming exercises. ACM Trans. Comput. Educ.19(1), 1–43 (2019)
2019
-
[20]
In: The Twelfth International Conference on Learning Representations (2024)
Kim, S., Shin, J., Cho, Y., Jang, J., Longpre, S., Lee, H., Yun, S., Shin, S., Kim, S., Thorne, J., Seo, M.: Prometheus: Inducing fine-grained evaluation capabil- ity in language models. In: The Twelfth International Conference on Learning Representations (2024)
2024
-
[21]
IEEE Trans
Kitchenham, B.A., Pfleeger, S.L., Pickard, L., Jones, P.W., Hoaglin, D.C., Emam, K.E., Rosenberg, J.: Preliminary guidelines for empirical research in software engineering. IEEE Trans. Softw. Eng.28(8), 721–734 (2002)
2002
-
[22]
In: Proceedings of the 49th ACM Technical Symposium on Computer Science Education
Krusche, S., Seitz, A.: Artemis: An automatic assessment management system for interactive learning. In: Proceedings of the 49th ACM Technical Symposium on Computer Science Education. pp. 284–289 (Feb 2018). https://doi.org/10.1145/ 3159450.3159602
arXiv 2018
-
[23]
Biometrics33(1), 159–174 (1977)
Landis, J.R., Koch, G.G.: The measurement of observer agreement for categorical data. Biometrics33(1), 159–174 (1977)
1977
-
[24]
Soviet Physics Doklady10, 707–710 (1966)
Levenshtein, V.I.: Binary codes capable of correcting deletions, insertions, and reversals. Soviet Physics Doklady10, 707–710 (1966)
1966
-
[25]
In: Advances in Neural Information Processing Systems 36
Li, G., Hammoud, H.A.A.K., Itani, H., Khizbullin, D., Ghanem, B.: CAMEL: Communicative agents for “mind” exploration of large language model society. In: Advances in Neural Information Processing Systems 36. vol. 36 (2023)
2023
-
[26]
: A survey on LLM-based multi-agent systems: workflow, infrastructure, and challenges
Li, X., Wang, S., Zeng, S., Wu, Y., Yang, Y.: A survey on LLM-based multi- agent systems: Workflow, infrastructure, and challenges. Vicinagearth1(1) (2024). https://doi.org/10.1007/s44336-024-00009-2
-
[27]
arXiv preprint arXiv:2512.02498 (2025)
Li, Y., Yang, G., Liu, H., Wang, B., Zhang, C.: dots.ocr: Multilingual document layout parsing in a single vision-language model. arXiv preprint arXiv:2512.02498 (2025)
arXiv 2025
-
[28]
In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (2023)
Liu, Y., Iter, D., Xu, Y., Wang, S., Xu, R., Zhu, C.: G-Eval: NLG evaluation using GPT-4 with better human alignment. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (2023)
2023
-
[29]
IEEE Transactions on Pattern Analysis and Machine Intelligence15(9), 926–932 (1993)
Marzal, A., Vidal, E.: Computation of normalized edit distance and applications. IEEE Transactions on Pattern Analysis and Machine Intelligence15(9), 926–932 (1993). https://doi.org/10.1109/34.232078
-
[30]
Messer, M., Brown, N.C.C., Kolling, M., Shi, M.: Automated grading and feedback tools for programming education: A systematic review. ACM Trans. Comput. Educ. 24(1), 1–43 (2024). https://doi.org/10.1145/3636515
-
[31]
ACM Computing Surveys , year = 2001, volume = 33, number = 1, month =
Navarro, G.: A guided tour to approximate string matching. ACM Comput. Surv. 33(1), 31–88 (Mar 2001). https://doi.org/10.1145/375360.375365 20 M. Becattini et al
-
[32]
https://openai.com/index/hello-gpt-4o/ (2024), accessed: June 2026
OpenAI: Hello GPT-4o. https://openai.com/index/hello-gpt-4o/ (2024), accessed: June 2026
2024
-
[33]
In: Proceedings of the 16th International Conference on Educational Data Mining (2023)
Phung, T., Cambronero, J., Gulwani, S., Kohn, T., Majumdar, R., Singla, A., Soares, G.: Generating high-precision feedback for programming syntax errors using large language models. In: Proceedings of the 16th International Conference on Educational Data Mining (2023)
2023
-
[34]
In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (2024)
Qian, C., Liu, W., Liu, H., Chen, N., Dang, Y., Li, J., Yang, C., Chen, W., Su, Y., Cong, X., Xu, J., Li, D., Liu, Z., Sun, M.: ChatDev: Communicative agents for software development. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (2024)
2024
-
[35]
In: Proceedings of the 44th ACM Technical Symposium on Computer Science Education
Radermacher, A., Walia, G.: Gaps between industry expectations and the abilities of graduates. In: Proceedings of the 44th ACM Technical Symposium on Computer Science Education. pp. 525–530 (2013)
2013
-
[36]
Empirical Software Engineering14(2), 131–164 (2009)
Runeson, P., Höst, M.: Guidelines for conducting and reporting case study research in software engineering. Empirical Software Engineering14(2), 131–164 (2009)
2009
-
[37]
In: Proceedings of the 34th ACM SIGPLAN Conference on Programming Language Design and Implementation
Singh, R., Gulwani, S., Solar-Lezama, A.: Automated feedback generation for introductory programming assignments. In: Proceedings of the 34th ACM SIGPLAN Conference on Programming Language Design and Implementation. pp. 15–26 (2013)
2013
-
[38]
Tenhunen, S., Männistö, T., Luukkainen, M., Ihantola, P.: A systematic literature review of capstone courses in software engineering. Inf. Softw. Technol.159(C), 107191 (Jul 2023). https://doi.org/10.1016/j.infsof.2023.107191
-
[39]
and Spring Contributors: Spring AI: An application framework for AI engineering
VMware, Inc. and Spring Contributors: Spring AI: An application framework for AI engineering. https://spring.io/projects/spring-ai (2024), version 1.0.x. Accessed: February 2026
2024
-
[40]
In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (2024)
Wang, P., Li, L., Chen, L., Cai, Z., Zhu, D., Lin, B., Cao, Y., Kong, L., Liu, Q., Liu, T., Sui, Z.: Large language models are not fair evaluators. In: Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (2024)
2024
-
[41]
In: The Eleventh International Conference on Learning Representations (2023)
Wang, X., Wei, J., Schuurmans, D., Le, Q.V., Chi, E.H., Narang, S., Chowdhery, A., Zhou, D.: Self-consistency improves chain of thought reasoning in language models. In: The Eleventh International Conference on Learning Representations (2023)
2023
-
[42]
arXiv preprint arXiv:2308.08155 (2023)
Wu, Q., Bansal, G., Zhang, J., Wu, Y., Li, B., Zhu, E., Jiang, L., Zhang, X., Zhang, S., Liu, J., Awadallah, A.H., White, R.W., Burger, D., Wang, C.: AutoGen: Enabling next-gen LLM applications via multi-agent conversation. arXiv preprint arXiv:2308.08155 (2023)
Pith/arXiv arXiv 2023
-
[43]
In: Proceedings of the Interna- tional Conference on Research in Adaptive and Convergent Systems
Xie, W., Niu, J., Xue, C.J., Guan, N.: Grade like a human: Rethinking auto- mated assessment with large language models. In: Proceedings of the Interna- tional Conference on Research in Adaptive and Convergent Systems. pp. 1–8. RACS ’25, Association for Computing Machinery, New York, NY, USA (2025). https://doi.org/10.1145/3769002.3769962
-
[44]
IEEE Transactions on Pattern Analysis and Machine Intelligence29(6), 1091–1095 (2007)
Yujian, L., Bo, L.: A normalized levenshtein distance metric. IEEE Transactions on Pattern Analysis and Machine Intelligence29(6), 1091–1095 (2007). https: //doi.org/10.1109/TPAMI.2007.1078
-
[45]
In: Advances in Neural Information Processing Systems 36
Zheng, L., Chiang, W.L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E.P., Zhang, H., Gonzalez, J.E., Stoica, I.: Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. In: Advances in Neural Information Processing Systems 36. vol. 36 (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.