Is Capability a Liability? More Capable Language Models Make Worse Forecasts When It Matters Most
Pith reviewed 2026-05-25 06:00 UTC · model grok-4.3
The pith
More capable language models produce worse distributional forecasts on problems with superlinear growth and tail risks of regime change.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
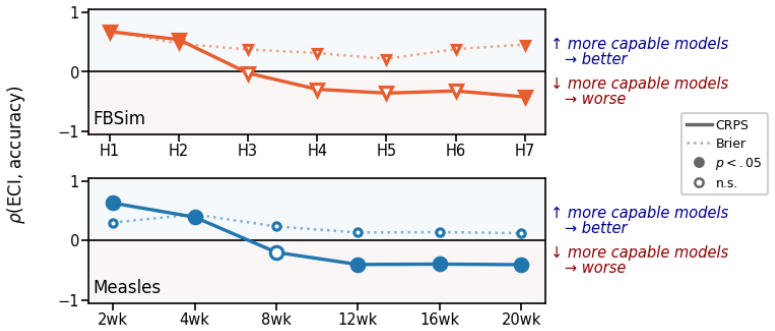
On forecasting problems whose underlying time series exhibit superlinear growth and tail risk of regime change, more capable models produce worse distributional forecasts. The pattern appears on ForecastBench-Sim, synthetic SIR epidemics with a matched linear control, and real-world datasets; a per-quantile decomposition shows the failure concentrates at the upper tail, which more capable models shift upward to track aggressive extrapolations of growth, while the lower tail stays put.
What carries the argument
Per-quantile decomposition of forecast errors, which isolates the upward shift in the upper tail as the source of worse performance in more capable models.
If this is right
- Tail-inclusive scoring reverses the sign of the capability-accuracy relationship on identical outputs relative to single-threshold metrics.
- Both model scale and post-training independently contribute to the inverse scaling, as shown within the Llama-3.1 family.
- Domain knowledge does not reliably improve calibration on these tasks.
- The pattern replicates across synthetic and multiple real-world datasets exhibiting the target structure.
Where Pith is reading between the lines
- Forecasting evaluations for language models should include continuous unbounded metrics as a standard check to surface tail-specific failures.
- The result may apply to other prediction settings that involve rapid growth followed by potential breaks, such as certain financial or supply-chain risks.
- Training methods could be tested for their ability to limit over-extrapolation specifically in the upper quantiles of growth trajectories.
Load-bearing premise
The chosen tasks and datasets are representative of forecasting problems whose underlying time series exhibit superlinear growth and tail risk of regime change.
What would settle it
Finding that more capable models achieve better upper-tail calibration than less capable ones on a new collection of tasks with documented superlinear growth and regime-change risk would falsify the claim.
Figures




read the original abstract
We document inverse scaling in LLMs on forecasting problems whose underlying time series exhibit superlinear growth and tail risk of regime change, a structure common in finance and epidemiology. On these tasks, more capable models produce worse distributional forecasts. The pattern appears on ForecastBench-Sim (FBSim), a contamination-free, simulated-world benchmark we release, in forecasting synthetic SIR epidemics with a matched linear control, and replicates in real-world datasets on COVID-19, measles, housing markets, and hyperinflation. A per-quantile decomposition shows the failure concentrates at the upper tail, which more capable models shift upward to track aggressive extrapolations of growth, while the lower tail stays put. A within-family study of Llama-3.1 shows that both model scale and post-training independently contribute to this effect. Domain knowledge does not reliably rescue calibration. This inverse scaling does not appear on single-threshold metrics common in LLM forecasting benchmarks, reversing the sign of the capability--accuracy relationship on identical outputs. Single-threshold scoring at conventional cutoffs misses the upper-tail cost; tail-inclusive scoring reverses the sign of the capability--accuracy relationship on the same outputs. We recommend that LLM forecasting evaluations use continuous (and unbounded) measures of accuracy alongside bounded binary threshold metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that more capable LLMs produce worse distributional forecasts on problems whose time series exhibit superlinear growth and tail risk of regime change (common in finance and epidemiology). This inverse scaling is documented on the released ForecastBench-Sim (FBSim) benchmark, synthetic SIR epidemics with a matched linear control, and real-world datasets (COVID-19, measles, housing markets, hyperinflation). A per-quantile decomposition localizes the failure to the upper tail; within-family Llama-3.1 results indicate independent contributions from scale and post-training. Single-threshold metrics miss the effect and can reverse the sign of the capability-accuracy relationship.
Significance. If the central empirical pattern holds, the result is significant for LLM evaluation practices in forecasting domains. The release of a contamination-free benchmark and replications on external real-world datasets strengthen reproducibility and external validity. The demonstration that conventional single-threshold scoring can mask upper-tail costs provides a concrete, actionable critique of existing benchmarks.
major comments (3)
- [Abstract and Methods] Abstract and Methods: The abstract states that replications appear across simulated and real datasets but supplies no details on statistical tests, data exclusion rules, error-bar construction, or exact quantile definitions. Without these, the support for the central inverse-scaling claim cannot be verified from the reported information.
- [Results (per-quantile decomposition)] Results (per-quantile decomposition): The decomposition attributes upper-tail shifts to model capability, yet the manuscript reports no sensitivity analyses to FBSim generation parameters (e.g., superlinear trajectory sampling or regime-change probabilities) or to the matched SIR control. This leaves the attribution vulnerable to confounding by data-generation choices.
- [Within-family Llama-3.1 analysis] Within-family Llama-3.1 analysis: The study addresses family-level confounds but does not examine robustness to alternative quantile decompositions or variations in how the target structure is instantiated, which is load-bearing for the claim that the pattern is diagnostic of the described class of forecasting problems rather than specific to the chosen tasks.
minor comments (1)
- [Abstract] The abstract is information-dense; consider separating the description of the per-quantile finding and the metric-reversal result into distinct sentences for readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on statistical transparency and robustness. We address each comment below and have revised the manuscript to incorporate additional details and analyses.
read point-by-point responses
-
Referee: [Abstract and Methods] Abstract and Methods: The abstract states that replications appear across simulated and real datasets but supplies no details on statistical tests, data exclusion rules, error-bar construction, or exact quantile definitions. Without these, the support for the central inverse-scaling claim cannot be verified from the reported information.
Authors: The abstract is intentionally concise. The Methods section specifies bootstrap resampling (1000 iterations) for 95% CIs, inclusion of all series with no exclusions, paired Wilcoxon tests for significance, and quantiles as equal-mass bins of the empirical target distribution. To improve accessibility we have added a brief clause to the abstract on the statistical approach and inserted a summary table of these choices in the Methods. revision: yes
-
Referee: [Results (per-quantile decomposition)] Results (per-quantile decomposition): The decomposition attributes upper-tail shifts to model capability, yet the manuscript reports no sensitivity analyses to FBSim generation parameters (e.g., superlinear trajectory sampling or regime-change probabilities) or to the matched SIR control. This leaves the attribution vulnerable to confounding by data-generation choices.
Authors: The matched linear SIR control already isolates the contribution of superlinear growth and regime change. Nevertheless, we agree that explicit sensitivity checks strengthen attribution. We have added analyses varying the growth exponent (1.1–2.0) and regime-change probability (0.05–0.2) in FBSim; the inverse-scaling pattern and upper-tail localization remain stable. These results appear as a new supplementary figure and table. revision: yes
-
Referee: [Within-family Llama-3.1 analysis] Within-family Llama-3.1 analysis: The study addresses family-level confounds but does not examine robustness to alternative quantile decompositions or variations in how the target structure is instantiated, which is load-bearing for the claim that the pattern is diagnostic of the described class of forecasting problems rather than specific to the chosen tasks.
Authors: The within-family results employ the same decile decomposition used throughout for consistency. To demonstrate that the pattern is not an artifact of the exact instantiation, we have added robustness checks using quintile and vigintile decompositions as well as additional problem variants with altered growth exponents and tail-risk probabilities. These appear in a new subsection of the results. revision: yes
Circularity Check
No circularity: purely empirical observational study with no derivation chain or fitted quantities
full rationale
The paper reports empirical observations of inverse scaling on forecasting tasks using a new benchmark (FBSim), synthetic SIR controls, and real-world datasets. No equations, first-principles derivations, parameter fits, or predictions are described that could reduce to self-definition, fitted inputs renamed as predictions, or self-citation chains. The per-quantile decomposition is a descriptive breakdown of observed outputs rather than a definitional equivalence. Central claims rest on replication across datasets and within-family controls, not on any load-bearing ansatz or uniqueness theorem imported from prior work. This is a standard empirical finding with independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The selected tasks (FBSim, synthetic SIR epidemics with linear control, and listed real-world datasets) represent forecasting problems with superlinear growth and tail risk of regime change common in finance and epidemiology.
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations (ICLR) , year=
ForecastBench: A Dynamic Benchmark of AI Forecasting Capabilities , author=. International Conference on Learning Representations (ICLR) , year=
-
[2]
Advances in Neural Information Processing Systems (NeurIPS) , year=
LLM Processes: Numerical Predictive Distributions Conditioned on Natural Language , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[3]
arXiv preprint arXiv:2402.18563 , year=
Approaching Human-Level Forecasting with Language Models , author=. arXiv preprint arXiv:2402.18563 , year=
-
[4]
and Bastos, Rafael Valdece Sousa and Tetlock, Philip E
Schoenegger, Philipp and Tuminauskaite, Indre and Park, Peter S. and Bastos, Rafael Valdece Sousa and Tetlock, Philip E. , journal=. Wisdom of the Silicon Crowd:
-
[5]
Do Large Language Models Know What They Don't Know?
Nel, Lukas , journal=. Do Large Language Models Know What They Don't Know?
-
[6]
arXiv preprint arXiv:2506.00723 , year=
Pitfalls in Evaluating Language Model Forecasters , author=. arXiv preprint arXiv:2506.00723 , year=
-
[7]
arXiv preprint arXiv:2503.14749 , year=
Uncertainty Distillation: Teaching Language Models to Express Semantic Confidence , author=. arXiv preprint arXiv:2503.14749 , year=
-
[8]
Alur, Rohan and Stadie, Bradly C. and Kang, Daniel and Chen, Ryan and McManus, Matt and Rickert, Michael and Lee, Tyler and Federici, Michael and Zhu, Richard and Fogerty, Dennis and Williamson, Hayley and Lozinski, Nina and Linsky, Aaron and Sekhon, Jasjeet S. , journal=
-
[9]
International Conference on Machine Learning (ICML) , year=
On Calibration of Modern Neural Networks , author=. International Conference on Machine Learning (ICML) , year=
-
[10]
International Conference on Learning Representations (ICLR) , year=
Taming Overconfidence in LLMs: Reward Calibration in RLHF , author=. International Conference on Learning Representations (ICLR) , year=
-
[11]
Empirical Methods in Natural Language Processing (EMNLP) , year=
Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback , author=. Empirical Methods in Natural Language Processing (EMNLP) , year=
-
[12]
International Conference on Machine Learning (ICML) , year=
Linguistic Calibration of Long-Form Generations , author=. International Conference on Machine Learning (ICML) , year=
-
[13]
Conference on Uncertainty in Artificial Intelligence (UAI) , year=
Mitigating Overconfidence in Out-of-Distribution Detection by Capturing Extreme Activations , author=. Conference on Uncertainty in Artificial Intelligence (UAI) , year=
-
[14]
Advances in Neural Information Processing Systems (NeurIPS) , year=
LACIE: Listener-Aware Finetuning for Confidence Calibration in Large Language Models , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[15]
Transactions on Machine Learning Research , year=
Inverse Scaling: When Bigger Isn't Better , author=. Transactions on Machine Learning Research , year=
-
[16]
Journal of the American Statistical Association , volume=
Strictly Proper Scoring Rules, Prediction, and Estimation , author=. Journal of the American Statistical Association , volume=
-
[17]
Journal of Applied Meteorology , volume=
A New Vector Partition of the Probability Score , author=. Journal of Applied Meteorology , volume=
-
[18]
Monthly Weather Review , volume=
Verification of forecasts expressed in terms of probability , author=. Monthly Weather Review , volume=
-
[19]
International Journal of Forecasting , volume=
The M4 Competition: 100,000 time series and 61 forecasting methods , author=. International Journal of Forecasting , volume=
-
[20]
arXiv preprint arXiv:2412.18544 , year=
Consistency Checks for Language Model Forecasters , author=. arXiv preprint arXiv:2412.18544 , year=
-
[21]
Context is Key: A Benchmark for Forecasting with Essential Textual Information , author=. NeurIPS 2024 Workshop , year=
work page 2024
-
[22]
Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks , year=
ProbTS: Benchmarking Point and Distributional Forecasting across Diverse Prediction Horizons , author=. Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks , year=
-
[23]
Comparing Elicitation Techniques for Probability Distributions , author=. Decision Analysis , year=
-
[24]
arXiv preprint arXiv:2404.07452 , year=
RiskLabs: Predicting Financial Risk Using Large Language Model Based on Multi-Sources Data , author=. arXiv preprint arXiv:2404.07452 , year=
-
[25]
Scaling Laws for Neural Language Models
Scaling Laws for Neural Language Models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[26]
Chowdhery, Aakanksha and Narang, Sharan and Devlin, Jacob and Bosma, Maarten and Mishra, Gaurav and Roberts, Adam and Barham, Paul and Chung, Hyung Won and Sutton, Charles and Gehrmann, Sebastian and others , journal=
-
[27]
Wei, Jason and Kim, Najoung and Tay, Yi and Le, Quoc V. , journal=. Inverse Scaling Can Become
-
[28]
Larger and More Instructable Language Models Become Less Reliable , author=. Nature , volume=
-
[29]
Ho, Anson and Denain, Jean-Stanislas and Atanasov, David and Albanie, Samuel and Shah, Rohin , journal=. A Rosetta Stone for
-
[30]
Rein, David and Hou, Betty Li and Stickland, Asa Cooper and Petty, Jackson and Pang, Richard Yuanzhe and Dirani, Julien and Michael, Julian and Bowman, Samuel R. , journal=
-
[31]
MIRAI: Evaluating LLM Agents for Event Forecasting , author=. 2024 , eprint=
work page 2024
-
[32]
Chen, Zhen and others , journal=
-
[33]
Freeciv.org: open source empire-building strategy game , author=. 2026 , howpublished=
work page 2026
- [34]
- [35]
- [36]
- [37]
- [38]
- [39]
-
[40]
arXiv preprint arXiv:2506.21558 , year=
Bench to the Future: A Pastcasting Benchmark for Forecasting Agents , author=. arXiv preprint arXiv:2506.21558 , year=
-
[41]
Mirzadeh, Iman and Alizadeh, Keivan and Shahrokhi, Hooman and Tuzel, Oncel and Bengio, Samy and Farajtabar, Mehrdad , journal=
-
[42]
Qi, Siyuan and Chen, Shuo and Li, Yexin and Kong, Xiangyu and Wang, Junqi and Yang, Bangcheng and Wong, Pring and Zhong, Yifan and Zhang, Xiaoyuan and Zhang, Zhaowei and Liu, Nian and Wang, Wei and Yang, Yaodong and Zhu, Song-Chun , booktitle=
-
[43]
arXiv preprint arXiv:2206.15474 , year=
Forecasting Future World Events with Neural Networks , author=. arXiv preprint arXiv:2206.15474 , year=
-
[44]
Expert Political Judgment: How Good Is It? How Can We Know? , author=
-
[45]
Towards Understanding Sycophancy in Language Models
Towards Understanding Sycophancy in Language Models , author=. arXiv preprint arXiv:2310.13548 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
TruthfulQA: Measuring How Models Mimic Human Falsehoods
TruthfulQA: Measuring How Models Mimic Human Falsehoods , author=. arXiv preprint arXiv:2109.07958 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Discovering Language Model Behaviors with Model-Written Evaluations
Discovering Language Model Behaviors with Model-Written Evaluations , author=. arXiv preprint arXiv:2212.09251 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Benchmark scores are well correlated, even across domains , author=. 2026 , url=
work page 2026
-
[49]
Weather and Forecasting , volume=
Decomposition of the continuous ranked probability score for ensemble prediction systems , author=. Weather and Forecasting , volume=. 2000 , publisher=
work page 2000
-
[50]
Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume=
Probabilistic forecasts, calibration and sharpness , author=. Journal of the Royal Statistical Society: Series B (Statistical Methodology) , volume=
-
[51]
Advances in Neural Information Processing Systems , volume=
Are Emergent Abilities of Large Language Models a Mirage? , author=. Advances in Neural Information Processing Systems , volume=
-
[52]
Transactions on Machine Learning Research , year=
Chronos: Learning the Language of Time Series , author=. Transactions on Machine Learning Research , year=
-
[53]
Advances in Neural Information Processing Systems , volume=
Large Language Models Are Zero-Shot Time Series Forecasters , author=. Advances in Neural Information Processing Systems , volume=
-
[54]
Gaussian Processes for Machine Learning , author=. 2006 , publisher=
work page 2006
- [55]
- [56]
-
[57]
OpenAI o3 and o4-mini System Card , author=. 2025 , howpublished=
work page 2025
- [58]
- [59]
-
[60]
The Llama 3 Herd of Models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
DeepSeek-V3 Technical Report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-R1 Technical Report , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
Qwen3 Technical Report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [64]
-
[65]
Journal of the American Statistical Association , volume=
Making and evaluating point forecasts , author=. Journal of the American Statistical Association , volume=. 2011 , publisher=
work page 2011
-
[66]
Van Panhuis, Willem and Cross, Anne and Burke, Donald , year=. Counts of Measles reported in
-
[67]
International Journal of Forecasting , volume=
On single point forecasts for fat-tailed variables , author=. International Journal of Forecasting , volume=. 2022 , publisher=
work page 2022
-
[68]
International Journal of Forecasting , volume=
False dichotomy alert: Improving subjective-probability estimates vs.\ raising awareness of systemic risk , author=. International Journal of Forecasting , volume=. 2022 , publisher=
work page 2022
-
[69]
Nature Computational Science , volume=
Advancing real-time infectious disease forecasting using large language models , author=. Nature Computational Science , volume=. 2025 , publisher=
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.