QMFOL: Benchmarking Large Language Model Reasoning via Quantifiable Monadic First-Order Logic Test Case Generation
Pith reviewed 2026-06-26 17:22 UTC · model grok-4.3
The pith
QMFOL generates monadic first-order logic benchmarks with precise control over reasoning depth, width, and label types to measure LLM deductive performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
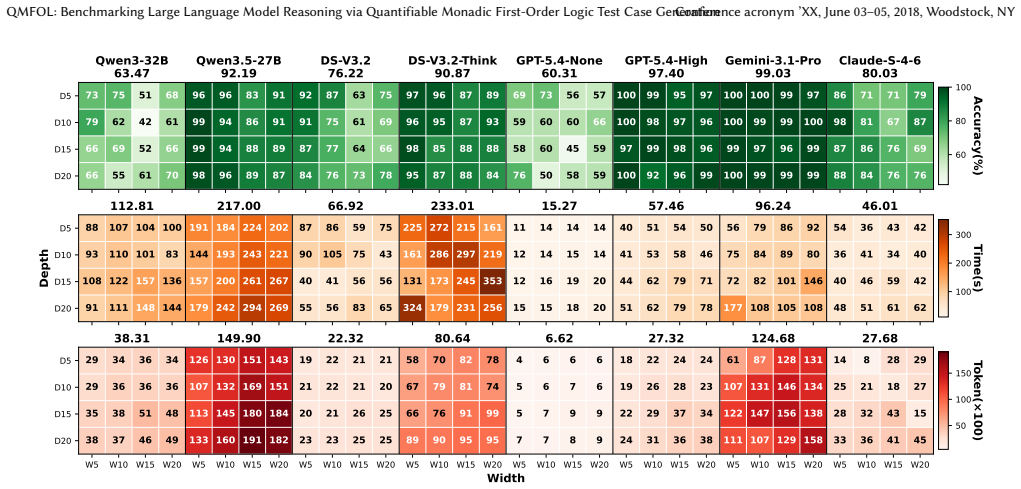
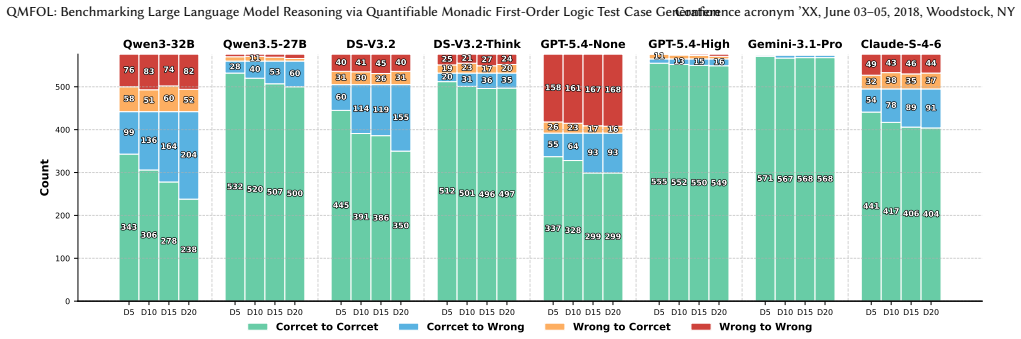
QMFOL constructs formal logical structures in monadic first-order logic using controlled conjunction and disjunction patterns, translates them into natural language via LLMs, and applies round-trip verification with an external prover to guarantee consistency; the resulting QMFOLBench of 2880 instances demonstrates that large reasoning models exhibit declining performance and rising computational cost as logical complexity rises, with better results on true labels than false or unknown and clear sensitivity to semantic wording.
What carries the argument
Formal logical structures built from conjunction and disjunction patterns in monadic first-order logic, translated to natural language and verified by round-trip prover checks, that enforce controllable reasoning depth, width, label types, and distractors.
If this is right
- LLM accuracy on deductive tasks decreases steadily as logical depth and width increase.
- Models achieve higher performance on tasks whose correct label is True than on those labeled False or Unknown.
- Computational cost for solving the tasks grows with added logical complexity.
- Changing the natural-language wording of the same logical structure alters model success rates.
Where Pith is reading between the lines
- Benchmark designers could apply the same pattern-based construction and verification loop to other fragments of logic beyond monadic first-order logic.
- Training pipelines that sample tasks at targeted complexity levels might produce models whose reasoning scales more evenly.
- The verification step points toward hybrid systems that combine language models with symbolic provers for generating reliable evaluation data at scale.
Load-bearing premise
Round-trip verification by an external prover is enough to ensure that the natural-language versions keep exactly the same logical structure and label as the original formal statements.
What would settle it
An independent prover or human logician finding a natural-language instance whose truth value differs from the formal source after the round-trip check passed would show the verification step does not preserve semantics.
Figures



read the original abstract
Large Language Models (LLMs) have made significant progress in reasoning, particularly in deductive reasoning, which is crucial for high-stakes decision-making. As models improve, evaluation benchmarks should evolve to keep pace. However, existing benchmarks lack fine-grained control over logical complexity and struggle to balance semantic diversity with logical consistency. To address these issues, we propose QMFOL, an automated framework for generating monadic first-order logic reasoning tasks with quantifiable and controllable complexity. It constructs formal logical structures using conjunction and disjunction patterns, enabling precise control over reasoning depth, width, label types, and distractors. These structures are then translated into natural language via LLMs, with logical consistency ensured through round-trip verification using an external prover. Based on our framework, we build QMFOLBench, a benchmark comprising 2880 instances with 960 configurations across diverse logical and semantic dimensions. Evaluations on six large reasoning models (LRMs) and two LLMs show that performance degrades and computational overhead increases with rising logical complexity. Models perform better on True-labeled tasks than on False or Unknown ones, and exhibit sensitivity to semantic variation. Overall, QMFOL offers a scalable and reliable approach for constructing deductive reasoning benchmarks with controllable complexity, enabling more precise evaluation of reasoning capabilities in modern language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces QMFOL, a framework that generates monadic first-order logic structures via conjunction/disjunction patterns with explicit control over depth, width, label type, and distractors; translates them to natural language using LLMs; and applies round-trip verification with an external prover to ensure consistency. From this it constructs QMFOLBench (2880 instances, 960 configurations) and reports that six LRMs and two LLMs exhibit degrading performance and rising compute cost with increasing logical complexity, a preference for True labels, and sensitivity to semantic variation.
Significance. If the verification step reliably prevents semantic drift, the approach supplies a scalable route to deductive-reasoning benchmarks whose complexity parameters are inherited from the formal side rather than fitted post hoc. The independent-prover check and the explicit enumeration of 960 configurations constitute concrete strengths that would allow more precise isolation of reasoning failures than existing datasets.
major comments (1)
- [Abstract] Abstract (and the verification procedure described therein): the central reliability claim—that round-trip verification with an external prover guarantees that LLM natural-language translations preserve the original logical structure, label, and complexity—rests on an assumption whose sufficiency is not demonstrated. Monadic FOL rendered in English can introduce scope ambiguities, implicit domain restrictions, or pragmatic implications that a back-translated formal sentence would not necessarily expose, especially once distractors or width/depth parameters alter surface phrasing. Because benchmark labels and complexity metrics are taken directly from the formal side, any undetected mismatch directly undermines the controllability guarantee that underpins the paper’s contribution.
minor comments (1)
- The abstract states performance trends but supplies no quantitative tables, error bars, or exclusion criteria; the full methods and results sections will need to include these to allow readers to judge robustness.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying a key point about the strength of the verification claim. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (and the verification procedure described therein): the central reliability claim—that round-trip verification with an external prover guarantees that LLM natural-language translations preserve the original logical structure, label, and complexity—rests on an assumption whose sufficiency is not demonstrated. Monadic FOL rendered in English can introduce scope ambiguities, implicit domain restrictions, or pragmatic implications that a back-translated formal sentence would not necessarily expose, especially once distractors or width/depth parameters alter surface phrasing. Because benchmark labels and complexity metrics are taken directly from the formal side, any undetected mismatch directly undermines the controllability guarantee that underpins the paper’s contribution.
Authors: We agree that the round-trip verification establishes structural equivalence (the back-translated formula must match the original for the prover to succeed) but does not constitute a complete guarantee against all possible scope ambiguities, domain restrictions, or pragmatic implications that may arise in the natural-language rendering. The check is therefore necessary for preserving the formal label and complexity parameters yet insufficient to rule out every semantic nuance. In the revised manuscript we will (1) qualify the claim in the abstract and methods section to state precisely what the verification guarantees, (2) add an explicit limitations paragraph discussing the referee’s concerns, and (3) report a small-scale human fidelity study on a subset of instances to provide additional evidence. These changes will be reflected in the next version. revision: yes
Circularity Check
No significant circularity; derivation is self-contained via external verification
full rationale
The paper's central contribution is a constructive generation procedure that builds formal monadic FOL structures with explicit parameters for depth/width/label/distractors, translates them via LLM, and applies round-trip verification against an independent external prover. This verification step is external to the generation process and does not reduce any claimed benchmark property back to quantities fitted from the same outputs. No equations, self-citations, or uniqueness theorems are invoked to force the result; the controllability and consistency guarantees are inherited directly from the formal side plus the prover check, making the method self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Monadic first-order logic formulas can be constructed from conjunction and disjunction patterns while preserving decidability and allowing exact control of reasoning depth and width.
- domain assumption Round-trip translation through an LLM followed by prover verification guarantees semantic equivalence between the formal formula and the generated natural-language sentence.
Reference graph
Works this paper leans on
-
[1]
Anthropic. 2026. Introducing Claude Sonnet 4.6. https://www.anthropic.com/ news/claude-sonnet-4-6. Accessed: 2026-3-19
2026
-
[2]
Auer, Christian Bizer, Georgi Kobilarov, Jens Lehmann, Richard Cyganiak, and Zachary G
S. Auer, Christian Bizer, Georgi Kobilarov, Jens Lehmann, Richard Cyganiak, and Zachary G. Ives. 2007. DBpedia: A Nucleus for a Web of Open Data. In ISWC/ASWC. https://api.semanticscholar.org/CorpusID:7278297
2007
-
[3]
Hyeong Kyu Choi, Maxim Khanov, Hongxin Wei, and Yixuan Li. 2025. How Con- taminated Is Your Benchmark? Measuring Dataset Leakage in Large Language Models with Kernel Divergence. InInternational Conference on Machine Learning. https://icml.cc/media/icml-2025/Slides/43619.pdf
2025
-
[4]
Zheng Chu, Jingchang Chen, Qianglong Chen, Weijiang Yu, Haotian Wang, Ming Liu, and Bing Qin. 2024. TimeBench: A Comprehensive Evaluation of Temporal Reasoning Abilities in Large Language Models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Lun-Wei Ku, Andre Martins, and Vivek Srikumar ...
-
[5]
Peter Clark, Oyvind Tafjord, and Kyle Richardson. 2021. Transformers as soft reasoners over language. InProceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence(Yokohama, Yokohama, Japan)(IJCAI’20). Article 537, 9 pages. https://arxiv.org/abs/2002.05867
arXiv 2021
-
[6]
Kolbinger, Hannah Sophie Muti, Zunamys I
Jan Clusmann, Fiona R. Kolbinger, Hannah Sophie Muti, Zunamys I. Carrero, Jan-Niklas Eckardt, Narmin Ghaffari Laleh, Chiara Maria Lavinia Löffler, Sophie- Caroline Schwarzkopf, Michaela Unger, Gregory P. Veldhuizen, Sophia J. Wagner, and Jakob Nikolas Kather. 2023. The future landscape of large language models in medicine.Communications Medicine3, 1 (2023...
-
[7]
DeepSeek-AI, Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenhao Xu, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Erhang Li, Fangqi Zhou, Fangyun Lin, Fucong Dai, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Hanwei Xu, Ha...
Pith/arXiv arXiv 2025
-
[8]
Eva Eigner and Thorsten Händler. 2024. Determinants of LLM-assisted Decision- Making. arXiv:2402.17385 [cs.AI] https://arxiv.org/abs/2402.17385
arXiv 2024
-
[9]
Google. 2026. Gemini 3.1 Pro. https://ai.google.dev/gemini-api/docs/models/ gemini-3.1-pro-preview. Accessed: 2026-3-19
2026
-
[10]
Simeng Han, Hailey Schoelkopf, Yilun Zhao, Zhenting Qi, Martin Riddell, Wenfei Zhou, James Coady, David Peng, Yujie Qiao, Luke Benson, Lucy Sun, Alexander Wardle-Solano, Hannah Szabó, Ekaterina Zubova, Matthew Burtell, Jonathan Fan, Yixin Liu, Brian Wong, Malcolm Sailor, Ansong Ni, Linyong Nan, Jungo Kasai, Tao Yu, Rui Zhang, Alexander Fabbri, Wojciech Ma...
-
[11]
Kaixuan Huang, Jiacheng Guo, Zihao Li, Xiang Ji, Jiawei Ge, Wenzhe Li, Yingqing Guo, Tianle Cai, Hui Yuan, Runzhe Wang, Yue Wu, Ming Yin, Shange Tang, Yangsibo Huang, Chi Jin, Xinyun Chen, Chiyuan Zhang, and Mengdi Wang. 2025. MATH-Perturb: Benchmarking LLMs’ Math Reasoning Abilities against Hard Perturbations.arXiv preprint arXiv:2502.06453(2025). https:...
arXiv 2025
-
[12]
Duygu Sezen Islakoglu and Jan-Christoph Kalo. 2025. ChronoSense: Exploring Temporal Understanding in Large Language Models with Time Intervals of Events. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (Eds.). Ass...
-
[13]
Laura Kovács and Andrei Voronkov. 2013. First-Order Theorem Proving and Vampire. InComputer Aided Verification, Natasha Sharygina and Helmut Veith (Eds.). Springer Berlin Heidelberg, Berlin, Heidelberg, 1–35
2013
-
[14]
Jinqi Lai, Wensheng Gan, Jiayang Wu, Zhenlian Qi, and Philip S. Yu. 2024. Large language models in law: A survey.AI Open5 (2024), 181–196. doi:10.1016/j. aiopen.2024.09.002
work page doi:10.1016/j 2024
-
[15]
Ningke Li, Yuekang Li, Yi Liu, Ling Shi, Kailong Wang, and Haoyu Wang. 2024. Drowzee: Metamorphic Testing for Fact-Conflicting Hallucination Detection in Large Language Models.Proc. ACM Program. Lang.8, OOPSLA2, Article 336 (Oct. 2024), 30 pages. doi:10.1145/3689776
-
[16]
Iman Mirzadeh, Keivan Alizadeh, Hooman Shahrokhi, Oncel Tuzel, Samy Bengio, and Mehrdad Farajtabar. 2024. Gsm-symbolic: Understanding the limitations of mathematical reasoning in large language models.arXiv preprint arXiv:2410.05229 (2024). https://arxiv.org/abs/2410.05229
Pith/arXiv arXiv 2024
-
[17]
Mahmoud Mohammadi, Yipeng Li, Jane Lo, and Wendy Yip. 2025. Evaluation and Benchmarking of LLM Agents: A Survey. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V.2 (KDD ’25). ACM, 6129–6139. doi:10.1145/3711896.3736570
-
[18]
Phuong Minh Nguyen, Tien Huu Dang, and Naoya Inoue. 2025. Non- Interactive Symbolic-Aided Chain-of-Thought for Logical Reasoning. arXiv:2508.12425 [cs.AI] https://arxiv.org/abs/2508.12425
arXiv 2025
-
[19]
OpenAI. 2024. Hello GPT-4o. https://openai.com/index/hello-gpt-4o/. Accessed: 2026-1-3
2024
-
[20]
OpenAI. 2026. Introducing GPT -5.4. https://openai.com/index/introducing-gpt- 5-4/. Accessed: 2026-3-19
2026
-
[21]
Liangming Pan, Alon Albalak, Xinyi Wang, and William Wang. 2023. Logic- LM: Empowering Large Language Models with Symbolic Solvers for Faithful Logical Reasoning. InFindings of the Association for Computational Linguistics: EMNLP 2023, Houda Bouamor, Juan Pino, and Kalika Bali (Eds.). Association for Computational Linguistics, Singapore, 3806–3824. doi:10...
-
[22]
Chengwen Qi, Ren Ma, Bowen Li, He Du, Binyuan Hui, Jinwang Wu, Yuanjun Laili, and Conghui He. 2025. Large Language Models Meet Symbolic Provers for Logical Reasoning Evaluation. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=C25SgeXWjE
2025
-
[23]
QMFOL. 2026. https://doi.org/10.5281/zenodo.19348694
-
[24]
Qwen. 2026. Qwen3.5: Towards Native Multimodal Agents. https://qwen.ai/blog? id=qwen3.5. Accessed: 2026-3-19
2026
-
[25]
Zhyar Rzgar K Rostam, Márta Takács, and Gábor Kertész. 2025. Evaluating Large Language Models: A Review of Metrics and Benchmarks. In2025 IEEE 23rd Jubilee International Symposium on Intelligent Systems and Informatics (SISY). 000233–000240. doi:10.1109/SISY67000.2025.11205366
-
[26]
Soumya Sanyal, Zeyi Liao, and Xiang Ren. 2022. RobustLR: A Diagnostic Benchmark for Evaluating Logical Robustness of Deductive Reasoners. InPro- ceedings of the 2022 Conference on Empirical Methods in Natural Language Pro- cessing, Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang (Eds.). Association for Computational Linguistics, Abu Dhabi, United Arab Emi...
-
[27]
Abulhair Saparov and He He. 2023. Language Models Are Greedy Reasoners: A Systematic Formal Analysis of Chain-of-Thought. InThe Eleventh Interna- tional Conference on Learning Representations. https://openreview.net/forum?id= qFVVBzXxR2V
2023
-
[28]
Abulhair Saparov, Richard Yuanzhe Pang, Vishakh Padmakumar, Nitish Joshi, Seyed Mehran Kazemi, Najoung Kim, and He He. 2023. Testing Conference acronym ’XX, June 03–05, 2018, Woodstock, NY Zheng et al. the General Deductive Reasoning Capacity of Large Language Models Us- ing OOD Examples. InAdvances in Neural Information Processing Systems, Vol. 36. 3083–...
2023
-
[29]
Oyvind Tafjord, Bhavana Dalvi, and Peter Clark. 2021. ProofWriter: Generating Implications, Proofs, and Abductive Statements over Natural Language. InFind- ings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli (Eds.). Association for Computa- tional Linguistics, Online, 3621–3634. d...
-
[30]
Jidong Tian, Yitian Li, Wenqing Chen, Liqiang Xiao, Hao He, and Yaohui Jin
-
[31]
Diagnosing the First-Order Logical Reasoning Ability Through
Diagnosing the First-Order Logical Reasoning Ability Through LogicNLI. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen- tau Yih (Eds.). Association for Computational Linguistics, Online and Punta Cana, Dominican Republic, 3738–3747. doi:10.18653/v1/...
-
[32]
Jan Wielemaker, Tom Schrijvers, Markus Triska, and TorbjÖrn Lager. 2012. Swi- prolog.Theory Pract. Log. Program.12, 1–2 (Jan. 2012), 67–96. doi:10.1017/ S1471068411000494
2012
-
[33]
Wikipedia. 2026. Automated theorem proving. https://en.wikipedia.org/wiki/ Automated_theorem_proving. Accessed: 2026-3-19
2026
-
[34]
Pattaraphon Kenny Wongchamcharoen and Paul Glasserman. 2026. Do Large Language Models Understand Chronology?. InProceedings of the AAAI Conference on Artificial Intelligence. https://arxiv.org/abs/2511.14214 Student Abstract
arXiv 2026
-
[35]
Zihao Xu, Junchen Ding, Yiling Lou, Kun Zhang, Dong Gong, and Yuekang Li
-
[36]
https://arxiv.org/abs/2504.12312
Socrates or Smartypants: Testing Logic Reasoning Capabilities of Large Language Models with Logic Programming-based Test Oracles.arXiv preprint arXiv:2504.12312(2025). https://arxiv.org/abs/2504.12312
arXiv 2025
-
[37]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
Pith/arXiv arXiv 2025
-
[38]
Sherry Yang, Ofir Nachum, Yilun Du, Jason Wei, Pieter Abbeel, and Dale Schuur- mans. 2023. Foundation Models for Decision Making: Problems, Methods, and Opportunities. arXiv:2303.04129 [cs.AI] https://arxiv.org/abs/2303.04129
arXiv 2023
-
[39]
Jingqian Zhao, Bingbing Wang, Geng Tu, Yice Zhang, Qianlong Wang, Bin Liang, Jing Li, and Ruifeng Xu. 2025. CoreEval: Automatically Building Contamination- Resilient Datasets with Real-World Knowledge toward Reliable LLM Evaluation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanxiang ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.