Revisiting Neural Processes via Fourier Transform and Volterra Series
Pith reviewed 2026-06-28 17:09 UTC · model grok-4.3
The pith
Translation-equivariant neural processes decompose into convolutions via Volterra series and gain linear scaling through set Fourier convolutions on irregular points.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Continuous translation-equivariant operators equal sums of higher-order convolutions under the Volterra expansion, which admits approximation by first-order convolutions. Set Fourier convolutions supply a frequency-domain parameterization that acts on irregularly sampled points, yields approximately global receptive fields, and grows linearly with the number of observations. These elements underpin SFConvCNPs, which stack SFConv blocks with nonlinearities, and SFVConvCNPs, which incorporate the Volterra form; both show competitive results on synthetic and real datasets.
What carries the argument
Set Fourier convolutions (SFConvs), a frequency-domain parameterization that operates directly on irregularly sampled points to deliver approximately global receptive fields with linear scaling in the number of observations.
If this is right
- SFConvCNPs and SFVConvCNPs produce conditional neural processes that respect translation equivariance with improved interpretability.
- The models scale linearly rather than quadratically with the number of observations.
- Operations apply directly to irregular point sets without requiring dense uniform grids.
- First-order convolution approximations suffice for effective performance in the tested regimes.
- Analytical transparency follows from the explicit Volterra decomposition into convolution sums.
Where Pith is reading between the lines
- The Volterra characterization may extend to designing models with other continuous symmetries such as rotations or scalings.
- SFConvs could combine with existing Fourier feature methods to address higher-dimensional or spatiotemporal functional regression.
- Linear scaling may support deployment in large-scale monitoring systems where observation counts exceed current attention limits.
- Higher-order terms in the Volterra expansion could be selectively retained for tasks where first-order approximations prove insufficient.
Load-bearing premise
The Volterra series expansion accurately represents the function class of translation-equivariant neural process architectures, and first-order convolution approximations combined with frequency-domain operations can be stacked with nonlinearities while retaining symmetry and downstream performance.
What would settle it
On a benchmark requiring translation equivariance, such as shifted time-series forecasting or spatially translated sensor regression, if SFConvCNP or SFVConvCNP achieves lower predictive log-likelihood than quadratic attention-based neural processes at matched parameter count, the efficiency and approximation claims would be falsified.
Figures

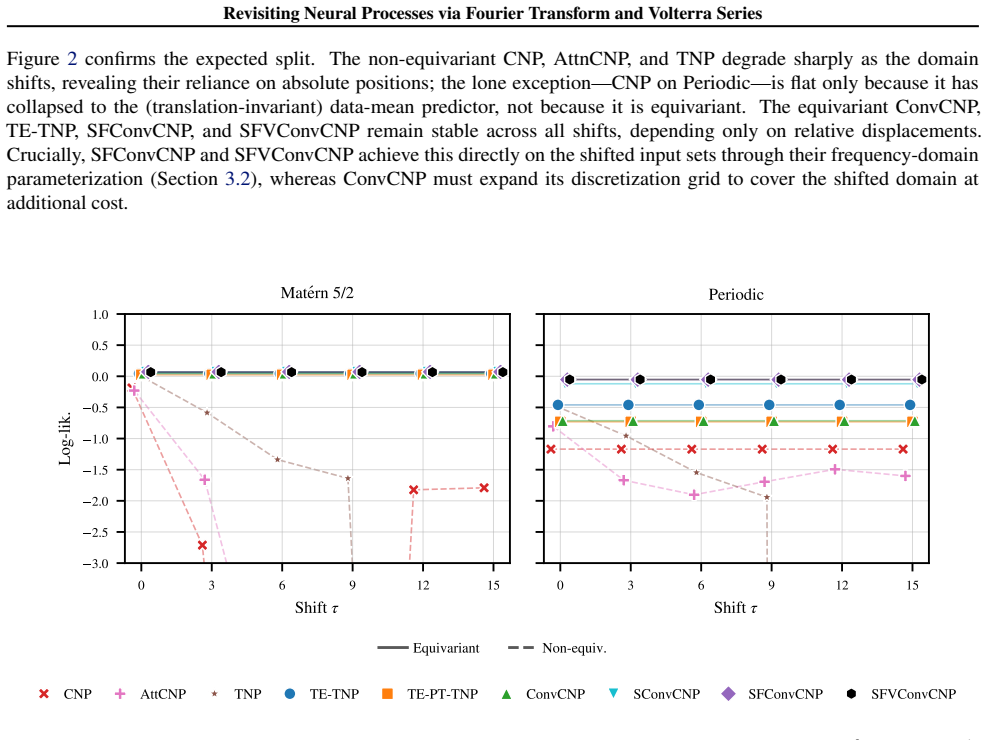
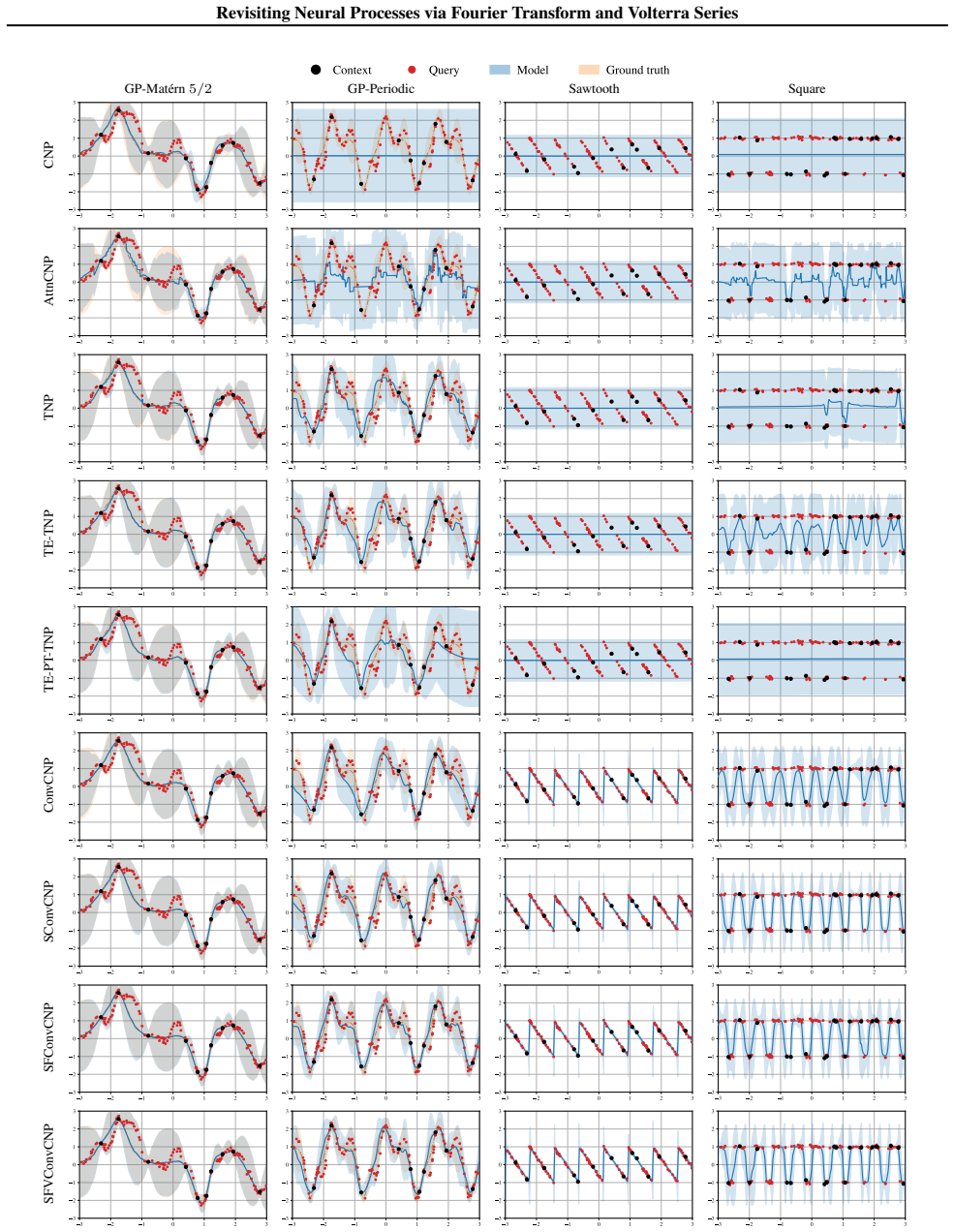
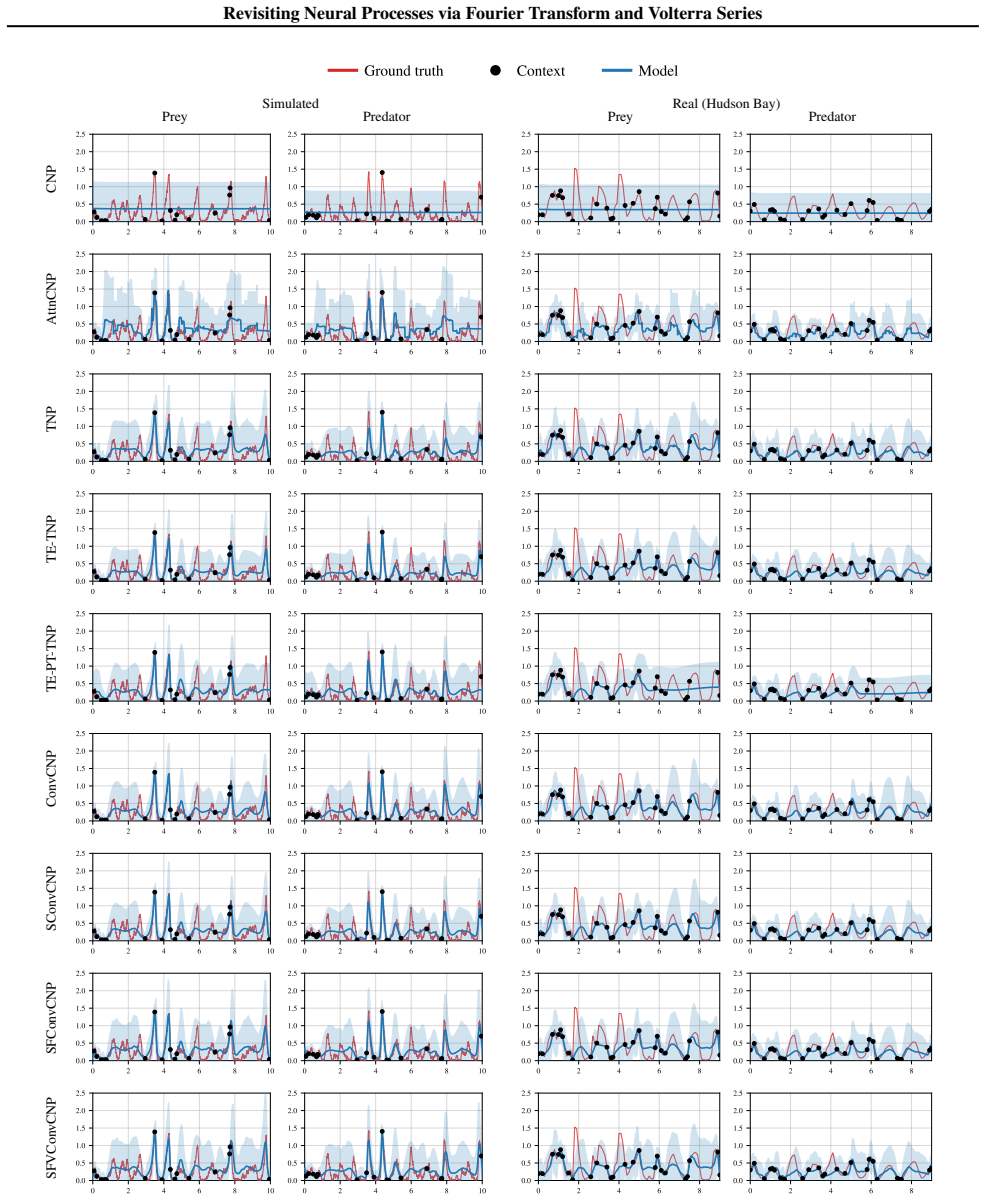

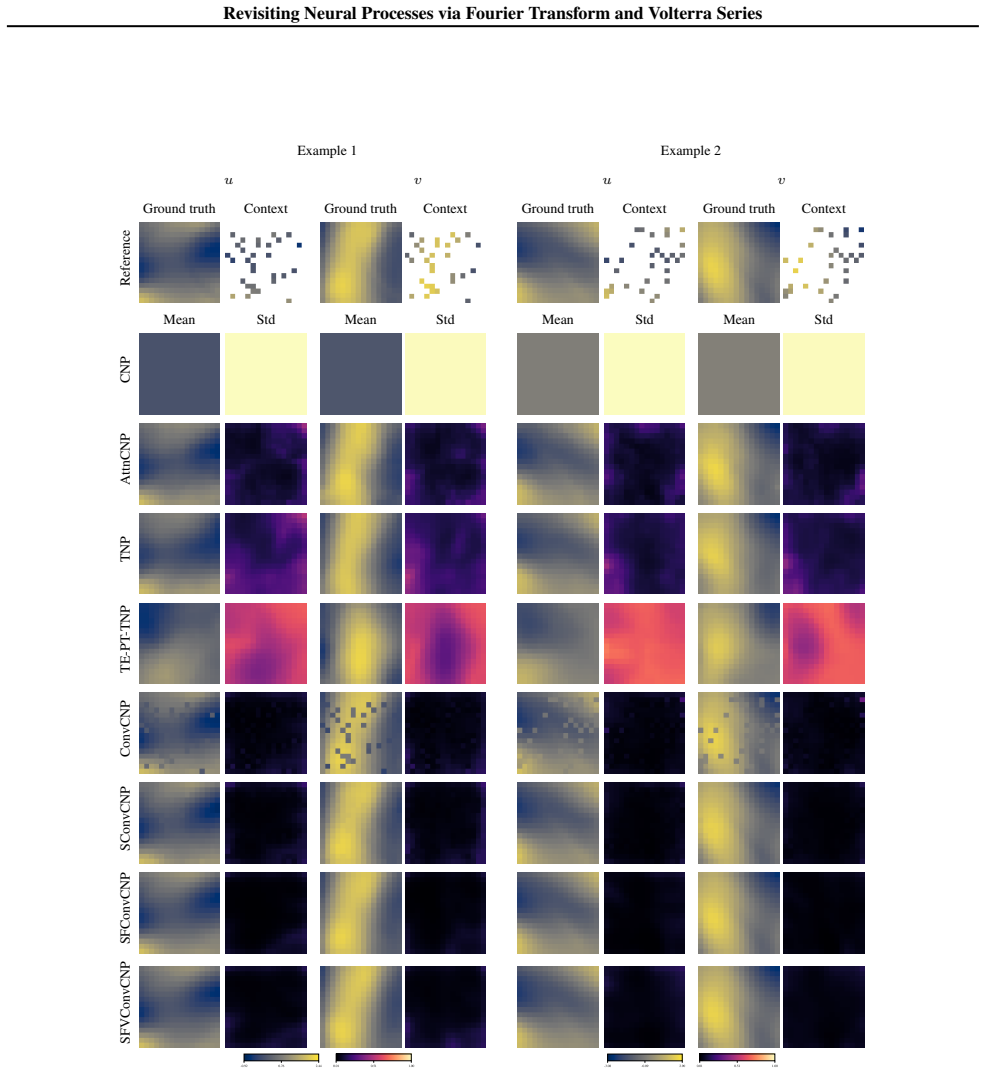

read the original abstract
Modeling unknown latent functions from finite, irregularly sampled measurements is a recurring challenge across science and engineering. Neural processes (NPs), a family of probabilistic functional models, are promising solutions -- especially when endowed with domain-specific symmetries like translation equivariance, which improve sample efficiency and generalization. Yet existing translation-equivariant NPs face two limitations: (i) they stack generic components with non-linearities, obscuring the induced function class and limiting interpretability; and (ii) convolutional designs rely on kernels with local receptive fields and require dense uniform input grids, while attention-based methods avoid these issues but scale quadratically with the number of observations. We address both with two contributions. First, using the Volterra expansion, we characterize continuous translation-equivariant operators as sums of higher-order convolutions, yielding analytical transparency while admitting efficient approximation by first-order convolutions. Second, we introduce set Fourier convolutions (SFConvs), a frequency-domain parameterization that operates directly on irregularly sampled points, achieves approximately global receptive fields, and scales linearly in the number of observations. Building on these ideas, we propose two conditional NPs (CNPs): SFConvCNPs, which stack SFConv blocks with non-linearities, and SFVConvCNPs, which integrate the Volterra formulation. Experiments on synthetic and real-world datasets demonstrate our methods' efficacy against state-of-the-art baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to characterize continuous translation-equivariant operators via the Volterra series as sums of higher-order convolutions (admitting a first-order approximation), introduce set Fourier convolutions (SFConvs) that act directly on irregular points with linear scaling and approximately global receptive fields, and derive two conditional neural process variants (SFConvCNPs and SFVConvCNPs) whose efficacy is shown on synthetic and real-world data against baselines.
Significance. If the derivations and experiments hold, the work supplies an interpretable functional characterization together with a scalable frequency-domain construction that directly targets the stated limitations of prior translation-equivariant NPs. The stress-test concern (whether the Volterra expansion exactly matches the realized architectures) does not land as an internal inconsistency; the paper presents the constructions as yielding the CNPs without circularity or unstated discretization assumptions.
minor comments (2)
- [Abstract] Abstract: the efficacy claim would be strengthened by reporting at least one concrete metric (e.g., mean log-likelihood or RMSE with error bars) rather than the generic statement that experiments demonstrate efficacy.
- Notation for the frequency-domain parameterization of SFConvs should be introduced with an explicit equation before its use in the CNP constructions.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation of minor revision. The provided summary accurately captures the manuscript's contributions, and we are pleased that the referee views the derivations and experiments as holding without internal inconsistency.
Circularity Check
No significant circularity
full rationale
The derivation relies on the standard Volterra series expansion and Fourier transforms, both external mathematical frameworks with no dependence on the paper's own fitted quantities or prior self-citations. The characterization of translation-equivariant operators as higher-order convolutions and the SFConv parameterization are presented as direct consequences of these independent tools, without any reduction of predictions to inputs by construction or load-bearing self-references. Experiments serve as downstream validation rather than closing a definitional loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Continuous translation-equivariant operators admit a Volterra expansion as sums of higher-order convolutions that can be approximated by first-order terms.
Reference graph
Works this paper leans on
-
[1]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[2]
Neural networks , volume=
Multilayer feedforward networks are universal approximators , author=. Neural networks , volume=. 1989 , publisher=
1989
-
[3]
Mathematics of control, signals and systems , volume=
Approximation by superpositions of a sigmoidal function , author=. Mathematics of control, signals and systems , volume=. 1989 , publisher=
1989
-
[4]
IEEE transactions on neural networks , volume=
Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its application to dynamical systems , author=. IEEE transactions on neural networks , volume=. 1995 , publisher=
1995
-
[5]
Journal of the American statistical association , volume=
Functional data analysis for sparse longitudinal data , author=. Journal of the American statistical association , volume=. 2005 , publisher=
2005
-
[6]
G3: Genes, Genomes, Genetics , volume=
Field-based high-throughput phenotyping enhances phenomic and genomic predictions for grain yield and plant height across years in maize , author=. G3: Genes, Genomes, Genetics , volume=. 2024 , publisher=
2024
-
[7]
2006 , publisher=
Gaussian processes for machine learning , author=. 2006 , publisher=
2006
-
[8]
International conference on machine learning , pages=
Conditional neural processes , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[9]
Neural processes , author=. arXiv preprint arXiv:1807.01622 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[11]
arXiv preprint arXiv:2209.00517 , year=
The neural process family: Survey, applications and perspectives , author=. arXiv preprint arXiv:2209.00517 , year=
-
[12]
arXiv preprint arXiv:2408.09583 , year=
Convolutional Conditional Neural Processes , author=. arXiv preprint arXiv:2408.09583 , year=
-
[13]
arXiv preprint arXiv:1910.13556 , year=
Convolutional conditional neural processes , author=. arXiv preprint arXiv:1910.13556 , year=
-
[14]
International Conference on Machine Learning , pages=
On the generalization of equivariance and convolution in neural networks to the action of compact groups , author=. International Conference on Machine Learning , pages=. 2018 , organization=
2018
-
[15]
Theory of functionals and of integral and integro-differential equations , author=
-
[16]
IMA Journal of Mathematical Control and Information , volume=
Analytical foundations of Volterra series , author=. IMA Journal of Mathematical Control and Information , volume=. 1984 , publisher=
1984
-
[17]
1993 , publisher=
Nonlinear adaptive filtering: A unified approach , author=. 1993 , publisher=
1993
-
[18]
1994 IEEE International Symposium on Circuits and Systems (ISCAS) , volume=
Multilayer neural network structure as volterra filter , author=. 1994 IEEE International Symposium on Circuits and Systems (ISCAS) , volume=. 1994 , organization=
1994
-
[19]
IEEE Transactions on circuits and systems , volume=
Fading memory and the problem of approximating nonlinear operators with Volterra series , author=. IEEE Transactions on circuits and systems , volume=. 2003 , publisher=
2003
-
[20]
Journal of Machine Learning Research , volume=
Toward understanding convolutional neural networks from volterra convolution perspective , author=. Journal of Machine Learning Research , volume=
-
[21]
Journal of Machine Learning Research , volume=
Volterra neural networks (vnns) , author=. Journal of Machine Learning Research , volume=
-
[22]
Biological cybernetics , volume=
Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position , author=. Biological cybernetics , volume=. 1980 , publisher=
1980
-
[23]
Neural computation , volume=
Backpropagation applied to handwritten zip code recognition , author=. Neural computation , volume=. 1989 , publisher=
1989
-
[24]
Proceedings of the IEEE , volume=
Gradient-based learning applied to document recognition , author=. Proceedings of the IEEE , volume=. 1998 , publisher=
1998
-
[25]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[26]
Medical image computing and computer-assisted intervention--MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18 , pages=
U-net: Convolutional networks for biomedical image segmentation , author=. Medical image computing and computer-assisted intervention--MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18 , pages=. 2015 , organization=
2015
-
[27]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Approximately Equivariant Neural Processes , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[28]
Proceedings of the 41st International Conference on Machine Learning , pages =
Translation Equivariant Transformer Neural Processes , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[29]
arXiv preprint arXiv:2101.03606 , year=
The Gaussian neural process , author=. arXiv preprint arXiv:2101.03606 , year=
-
[30]
Forty-second International Conference on Machine Learning , year=
Gridded Transformer Neural Processes for Spatio-Temporal Data , author=. Forty-second International Conference on Machine Learning , year=
-
[31]
2008 , publisher=
Probability theory: a comprehensive course , author=. 2008 , publisher=
2008
-
[32]
Nature , volume=
End-to-end data-driven weather prediction , author=. Nature , volume=. 2025 , publisher=
2025
-
[33]
Geoscientific Model Development Discussions , volume=
Convolutional conditional neural processes for local climate downscaling , author=. Geoscientific Model Development Discussions , volume=. 2021 , publisher=
2021
-
[34]
arXiv preprint arXiv:2310.19932 , year=
Sim2real for environmental neural processes , author=. arXiv preprint arXiv:2310.19932 , year=
-
[35]
International conference on machine learning , pages=
Equivariant learning of stochastic fields: Gaussian processes and steerable conditional neural processes , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[36]
Generalization capabilities of translationally equivariant neural networks , author =. Phys. Rev. D , volume =. 2021 , month =. doi:10.1103/PhysRevD.104.074504 , url =
-
[37]
Bioinformatics , volume=
An equivariant Bayesian convolutional network predicts recombination hotspots and accurately resolves binding motifs , author=. Bioinformatics , volume=. 2019 , publisher=
2019
-
[38]
International conference on machine learning , pages=
Generalizing convolutional neural networks for equivariance to lie groups on arbitrary continuous data , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[39]
The Eleventh International Conference on Learning Representations , year=
The Lie Derivative for Measuring Learned Equivariance , author=. The Eleventh International Conference on Learning Representations , year=
-
[40]
Advances in Neural Information Processing Systems , volume=
Meta-learning stationary stochastic process prediction with convolutional neural processes , author=. Advances in Neural Information Processing Systems , volume=
-
[41]
arXiv preprint arXiv:2406.06486 , year=
Continuum attention for neural operators , author=. arXiv preprint arXiv:2406.06486 , year=
-
[42]
arXiv preprint arXiv:2207.04179 , year=
Transformer neural processes: Uncertainty-aware meta learning via sequence modeling , author=. arXiv preprint arXiv:2207.04179 , year=
-
[43]
Attentive neural processes , author=. arXiv preprint arXiv:1901.05761 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[44]
arXiv preprint arXiv:2102.08759 , year=
Group equivariant conditional neural processes , author=. arXiv preprint arXiv:2102.08759 , year=
-
[45]
Advances in Neural Information Processing Systems , volume=
Practical equivariances via relational conditional neural processes , author=. Advances in Neural Information Processing Systems , volume=
-
[46]
arXiv preprint arXiv:2203.08775 , year=
Practical conditional neural processes via tractable dependent predictions , author=. arXiv preprint arXiv:2203.08775 , year=
-
[47]
arXiv preprint arXiv:2304.09431 , year=
Martingale Posterior Neural Processes , author=. arXiv preprint arXiv:2304.09431 , year=
-
[48]
Advances in neural information processing systems , volume=
Learning expressive meta-representations with mixture of expert neural processes , author=. Advances in neural information processing systems , volume=
-
[49]
International Conference on Machine Learning , pages=
Robustifying sequential neural processes , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[50]
Advances in Neural Information Processing Systems , volume=
Sequential neural processes , author=. Advances in Neural Information Processing Systems , volume=
-
[51]
Uncertainty in Artificial Intelligence , pages=
Adaptive conditional quantile neural processes , author=. Uncertainty in Artificial Intelligence , pages=. 2023 , organization=
2023
-
[52]
arXiv preprint arXiv:2307.05431 , year=
Geometric Neural Diffusion Processes , author=. arXiv preprint arXiv:2307.05431 , year=
-
[53]
International Conference on Machine Learning , pages=
Doubly stochastic variational inference for neural processes with hierarchical latent variables , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[54]
The Eleventh International Conference on Learning Representations , year=
Bridge the Inference Gaps of Neural Processes via Expectation Maximization , author=. The Eleventh International Conference on Learning Representations , year=
-
[55]
Advances in Neural Information Processing Systems , volume=
The functional neural process , author=. Advances in Neural Information Processing Systems , volume=
-
[56]
Advances in Neural Information Processing Systems , volume=
Deep stochastic processes via functional markov transition operators , author=. Advances in Neural Information Processing Systems , volume=
-
[57]
International Conference on Artificial Intelligence and Statistics , pages=
Bayesian Convolutional Deep Sets with Task-Dependent Stationary Prior , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2023 , organization=
2023
-
[58]
arXiv preprint arXiv:2303.14468 , year=
Autoregressive conditional neural processes , author=. arXiv preprint arXiv:2303.14468 , year=
-
[59]
Advances in neural information processing systems , volume=
Bootstrapping neural processes , author=. Advances in neural information processing systems , volume=
-
[60]
arXiv preprint arXiv:2204.05449 , year=
Neural processes with stochastic attention: Paying more attention to the context dataset , author=. arXiv preprint arXiv:2204.05449 , year=
-
[61]
arXiv preprint arXiv:2102.02611 , year=
Ckconv: Continuous kernel convolution for sequential data , author=. arXiv preprint arXiv:2102.02611 , year=
-
[62]
Romero and Albert Gu and Efstratios Gavves and Erik J Bekkers and Jakub Mikolaj Tomczak and Mark Hoogendoorn and Jan-jakob Sonke , booktitle=
David M Knigge and David W. Romero and Albert Gu and Efstratios Gavves and Erik J Bekkers and Jakub Mikolaj Tomczak and Mark Hoogendoorn and Jan-jakob Sonke , booktitle=. Modelling Long Range Dependencies in \ N\ D: From Task-Specific to a General Purpose. 2023 , url=
2023
-
[63]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Large kernel matters--improve semantic segmentation by global convolutional network , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[64]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Non-local neural networks , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[65]
Advances in neural information processing systems , volume=
Stand-alone self-attention in vision models , author=. Advances in neural information processing systems , volume=
-
[66]
European conference on computer vision , pages=
Axial-deeplab: Stand-alone axial-attention for panoptic segmentation , author=. European conference on computer vision , pages=. 2020 , organization=
2020
-
[67]
arXiv preprint arXiv:2211.08458 , year=
Latent bottlenecked attentive neural processes , author=. arXiv preprint arXiv:2211.08458 , year=
-
[68]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Scaling up your kernels to 31x31: Revisiting large kernel design in cnns , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[69]
Journal of the Optical Society of America A , volume=
Relations between the statistics of natural images and the response properties of cortical cells , author=. Journal of the Optical Society of America A , volume=. 1987 , publisher=
1987
-
[70]
Advances in neural information processing systems , volume=
Scale mixtures of Gaussians and the statistics of natural images , author=. Advances in neural information processing systems , volume=
-
[71]
Advances in neural information processing systems , volume=
Statistics of natural images: Scaling in the woods , author=. Advances in neural information processing systems , volume=
-
[72]
Fourier Neural Operator for Parametric Partial Differential Equations
Fourier neural operator for parametric partial differential equations , author=. arXiv preprint arXiv:2010.08895 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[73]
Advances in Neural Information Processing Systems , volume=
Spectral convolutional conditional neural processes , author=. Advances in Neural Information Processing Systems , volume=
-
[74]
2024 , url=
Kun Chen and Peng Ye and Hao Chen and kang chen and Tao Han and Wanli Ouyang and Tao Chen and LEI BAI , booktitle=. 2024 , url=
2024
-
[75]
Advances in neural information processing systems , volume=
Pytorch: An imperative style, high-performance deep learning library , author=. Advances in neural information processing systems , volume=
-
[76]
Advances in neural information processing systems , volume=
Incorporating second-order functional knowledge for better option pricing , author=. Advances in neural information processing systems , volume=
-
[77]
Proceedings of the 27th international conference on machine learning (ICML-10) , pages=
Rectified linear units improve restricted boltzmann machines , author=. Proceedings of the 27th international conference on machine learning (ICML-10) , pages=
-
[78]
Advances in neural information processing systems , volume=
Gpytorch: Blackbox matrix-matrix gaussian process inference with gpu acceleration , author=. Advances in neural information processing systems , volume=
-
[79]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[80]
Network: computation in neural systems , volume=
Probable networks and plausible predictions-a review of practical Bayesian methods for supervised neural networks , author=. Network: computation in neural systems , volume=. 1995 , publisher=
1995
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.