Granuscore: A Reference-Free Measure of Granularity for Text Analysis and Question Answering
Pith reviewed 2026-06-29 18:30 UTC · model grok-4.3
The pith
Granuscore measures linguistic granularity from structural properties of hierarchical embedding spaces without any reference texts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
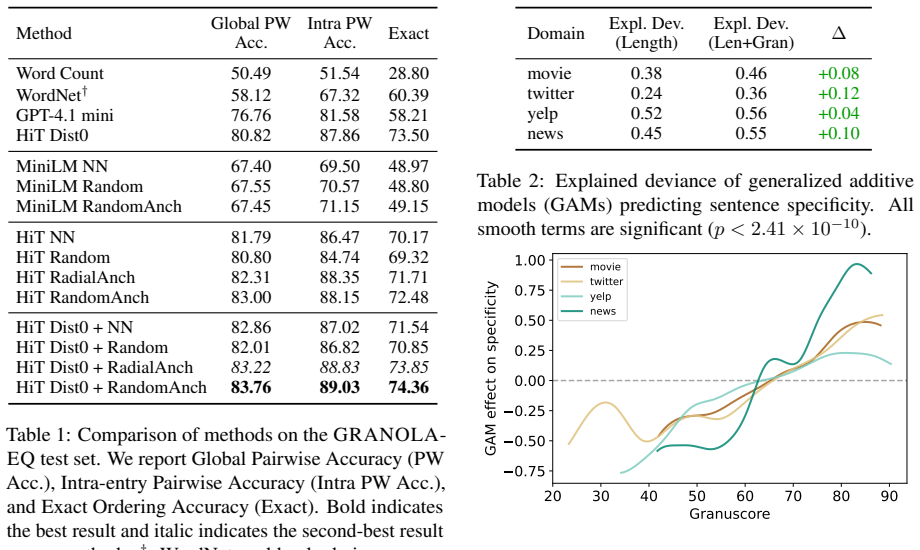
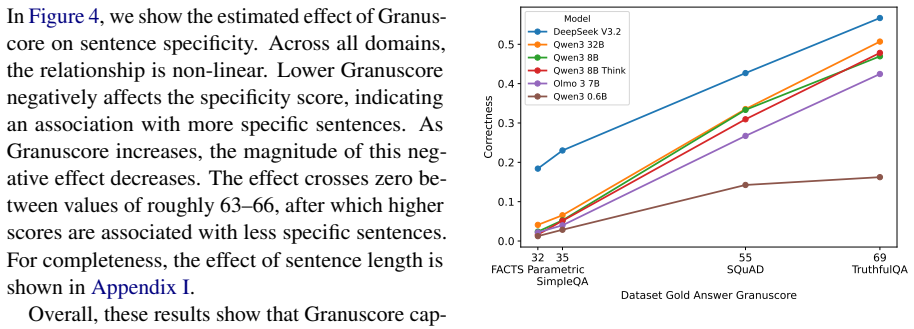
Granuscore is a reference-free measure of granularity that leverages structural properties of a hierarchical embedding space. It reliably recovers hierarchical orderings on the Granola-EQ dataset and captures expected differences in granularity across discourse contexts. Across domains, Granuscore explains non-linear variation in sentence specificity beyond sentence length. Applied to four question-answering benchmarks, the measure analyzes granularity for questions, gold answers, and model outputs across response outcomes, revealing consistent differences in model behavior and supplying a principled lens for characterizing QA dataset difficulty.
What carries the argument
Granuscore, computed directly from the structural arrangement of points inside a hierarchical embedding space to assign a granularity value to text.
If this is right
- Granuscore recovers hierarchical orderings on the Granola-EQ dataset.
- It captures expected differences in granularity across discourse contexts.
- It explains non-linear variation in sentence specificity beyond sentence length.
- It reveals consistent differences in model behavior on four QA benchmarks.
- It supplies a lens for characterizing the difficulty of QA datasets.
Where Pith is reading between the lines
- Granuscore could be applied to conversational systems to detect when generated answers are too broad or too narrow for the query.
- The same embedding-based approach might be extended to measure granularity drift across successive turns in a dialogue.
- Datasets for training language models could be filtered or balanced using Granuscore to control the range of detail levels present.
- The method suggests granularity information is already latent in existing embedding geometries and does not require new labeled data collection.
Load-bearing premise
The structural properties of a hierarchical embedding space line up directly with the linguistic idea of granularity without needing outside references or human ratings for confirmation.
What would settle it
A controlled test set of texts whose granularity levels have been established independently by multiple human raters in which Granuscore fails to recover the correct ordering or fails to separate discourse contexts as predicted.
Figures






read the original abstract
Natural language conveys information at varying levels of granularity, from fine-grained references to broad descriptions. While granularity is fundamental to human communication, existing measures mostly capture surface detail or sentence specificity. We introduce Granuscore, a reference-free measure of granularity that leverages structural properties of a hierarchical embedding space. Granuscore reliably recovers hierarchical orderings on the Granola-EQ dataset and captures expected differences in granularity across discourse contexts. Across domains, we further show that Granuscore explains non-linear variation in sentence specificity beyond sentence length. Finally, we apply Granuscore to four question-answering benchmarks and analyze how granularity differs for questions, gold answers, and model outputs across response outcomes. The analysis reveals consistent differences in model behavior and provides a principled lens for characterizing the difficulty of QA datasets. Together, the results position Granuscore as a scalable, broadly applicable tool for analyzing granularity in text.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Granuscore, a reference-free measure of granularity derived from structural properties of a hierarchical embedding space. It claims that Granuscore reliably recovers hierarchical orderings on the Granola-EQ dataset, captures expected differences across discourse contexts, explains non-linear variation in sentence specificity beyond length, and reveals consistent differences in model behavior across questions, gold answers, and outputs on four QA benchmarks.
Significance. If the embedding-to-granularity mapping is substantiated, Granuscore would offer a scalable reference-free tool for discourse analysis and QA evaluation. The reference-free design and application to multiple benchmarks are potential strengths, though no machine-checked proofs, reproducible code releases, or parameter-free derivations are described.
major comments (3)
- [abstract and §3] The central claim that structural properties of the hierarchical embedding space encode linguistic granularity (abstract and §3) lacks any reported correlation with human granularity judgments or external validation; without this, recovery of orderings on Granola-EQ may reflect embedding artifacts rather than the intended construct.
- [§3 (Methods)] The method for inducing the hierarchical embedding space and the specific structural metrics used (e.g., distances, nesting) are not specified in sufficient detail to evaluate whether the measure is truly reference-free or whether any fitted components introduce circularity with the target variable.
- [§5] In the QA benchmark analysis (§5), the reported differences in granularity across response outcomes are presented without controls for sentence length or lexical overlap, undermining the claim that Granuscore provides explanatory power beyond surface features.
minor comments (2)
- [§3] Notation for the embedding hierarchy and granularity score should be defined explicitly with an equation in §3 to improve reproducibility.
- [§4] The Granola-EQ dataset construction and any preprocessing steps are referenced but not described; a brief appendix table would clarify the evaluation setup.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, indicating where we will revise the manuscript to improve clarity, detail, and validation.
read point-by-point responses
-
Referee: [abstract and §3] The central claim that structural properties of the hierarchical embedding space encode linguistic granularity (abstract and §3) lacks any reported correlation with human granularity judgments or external validation; without this, recovery of orderings on Granola-EQ may reflect embedding artifacts rather than the intended construct.
Authors: The Granola-EQ dataset provides a controlled testbed with known hierarchical orderings, and Granuscore's recovery of these orderings, combined with its capture of expected discourse-context differences and non-linear specificity variation beyond length, offers evidence that the measure aligns with the intended construct rather than pure artifacts. We acknowledge that an explicit correlation with fresh human granularity judgments is not reported in the current version. In the revision we will add such a correlation on a held-out subset to further substantiate the claim. revision: yes
-
Referee: [§3 (Methods)] The method for inducing the hierarchical embedding space and the specific structural metrics used (e.g., distances, nesting) are not specified in sufficient detail to evaluate whether the measure is truly reference-free or whether any fitted components introduce circularity with the target variable.
Authors: We agree that additional methodological detail is needed for full evaluation and reproducibility. The current description in §3 is insufficiently precise on the induction procedure and the exact structural metrics. In the revised manuscript we will expand this section to specify the full induction process, the precise metrics (distances and nesting), and an explicit argument that no fitted components create circularity with granularity, preserving the reference-free character of the measure. revision: yes
-
Referee: [§5] In the QA benchmark analysis (§5), the reported differences in granularity across response outcomes are presented without controls for sentence length or lexical overlap, undermining the claim that Granuscore provides explanatory power beyond surface features.
Authors: The sentence-specificity experiments already demonstrate that Granuscore explains non-linear variation beyond sentence length. For the QA-benchmark results in §5, however, we did not include parallel controls for length or lexical overlap. We will add these controls in the revision to isolate granularity effects from surface features and thereby strengthen the explanatory claim. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract defines Granuscore via structural properties of a hierarchical embedding space and reports its empirical performance on Granola-EQ and QA benchmarks. No equations, fitted parameters, self-citations, or ansatzes are shown that would make any claimed prediction or ordering equivalent to the input data or measure by construction. The derivation chain is presented as an independent proposal whose validity rests on external dataset behavior rather than tautological reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ta- ble 12 reports pairwise accuracy on the GRANOLA- EQ test split while varying the anchor set size
We analyze the effect of the number of reference an- chors when using the Random Anchor method. Ta- ble 12 reports pairwise accuracy on the GRANOLA- EQ test split while varying the anchor set size. Performance remains largely stable across dif- ferent anchor sizes, indicating that the method is not highly sensitive to this parameter. The best performance ...
2019
-
[2]
We retain only responses that terminate before the token limit, ensuring all evaluated outputs are complete and not truncated
We instruct the model to produce answers of at most five sentences. We retain only responses that terminate before the token limit, ensuring all evaluated outputs are complete and not truncated. Models are instructed to produce answers of at most five sentences using the following prompt: User Prompt: Answer Generation Answer the following query in at mos...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.