Look Before You Zoom: Adaptive Routing for the Resolution-Context Trade-off in Visual RAG
Pith reviewed 2026-06-26 12:52 UTC · model grok-4.3
The pith
ViRGo routes visual queries to global perception or retrieval methods by estimating object scale from VLM localization heads to resolve the resolution-context trade-off.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
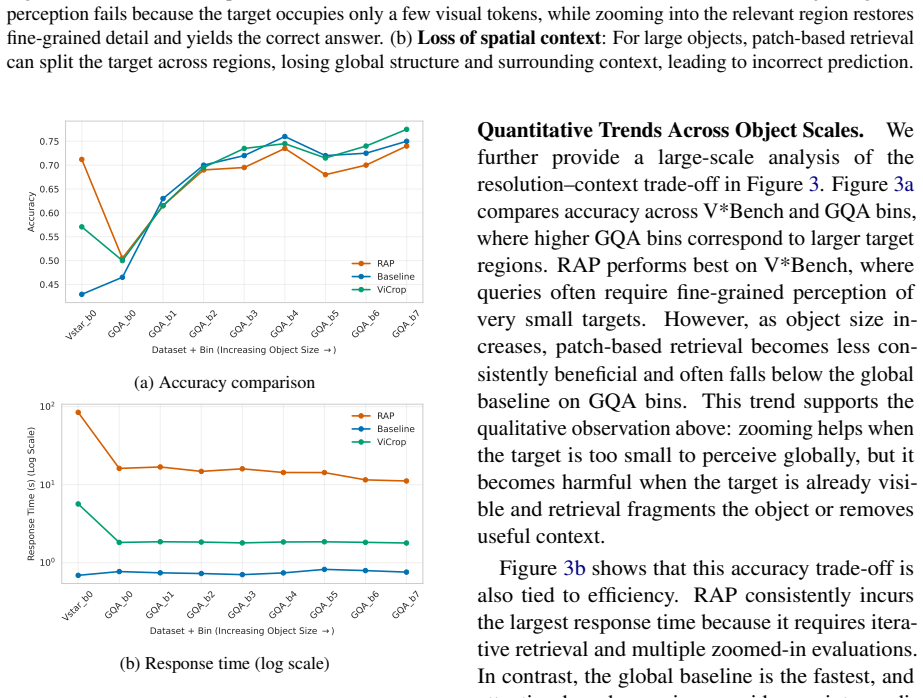
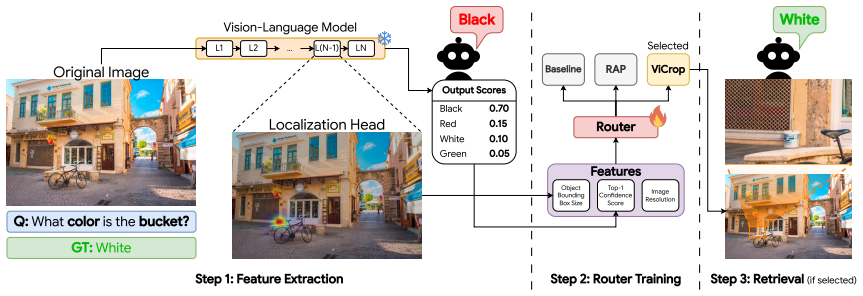
ViRGo (Visual Retrieval or Global Perception) is a lightweight framework that formulates visual retrieval as an adaptive routing problem. It estimates object scale from the VLM's intrinsic localization heads during the initial forward pass and combines it with semantic token confidence to select between global perception, patch-based retrieval, and attention-based retrieval with minimal additional computation. Experiments across multiple VQA benchmarks and object-size groups show that ViRGo matches patch retrieval on small details, leverages attention-based retrieval for larger objects, and reduces inference time by routing to the global baseline when zooming is unnecessary.
What carries the argument
ViRGo routing mechanism that estimates object scale from VLM localization heads and semantic token confidence to select among global perception, patch-based retrieval, and attention-based retrieval.
If this is right
- ViRGo matches patch retrieval accuracy on small objects while preserving context for larger ones.
- It improves performance on larger objects by selecting attention-based retrieval when appropriate.
- It reduces inference time by routing to the global baseline when retrieval is unnecessary.
- The method improves the accuracy-efficiency trade-off across VQA benchmarks and multiple object-size groups.
Where Pith is reading between the lines
- The same early scale estimate might be reused to adjust other VLM behaviors such as token allocation or attention masking.
- If localization heads prove reliable across model families, routing could become a default preprocessing step rather than a separate module.
- Testing the routing logic on video or multi-image inputs would check whether the scale-based decision generalizes beyond single-image VQA.
Load-bearing premise
Object scale can be reliably estimated from the VLM's intrinsic localization heads during the initial forward pass and combined with semantic token confidence to select the optimal retrieval strategy without introducing new errors.
What would settle it
An experiment in which scale estimates from the localization heads are replaced by random or incorrect values and ViRGo accuracy falls below the best fixed strategy on the same benchmarks.
Figures



read the original abstract
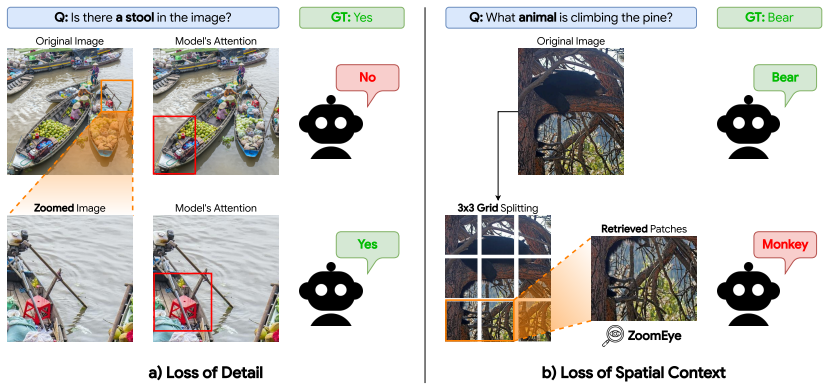
Vision-Language Models (VLMs) struggle as query-relevant objects become smaller. To address this, recent training-free approaches dynamically retrieve and zoom into local image regions. However, we show that indiscriminately applying retrieval ignores a critical vulnerability: the resolution-context trade-off. Patch-based zooming recovers details for small targets, but can split large objects and destroy global spatial context; attention-based retrieval better preserves large objects, but remains less reliable on tiny details; and global perception is often fastest when retrieval is unnecessary. Motivated by these failure modes, we introduce ViRGo (Visual Retrieval or Global Perception), a lightweight framework that formulates visual retrieval as an adaptive routing problem. ViRGo estimates object scale from the VLM's intrinsic localization heads during the initial forward pass and combines it with semantic token confidence to select between global perception, patch-based retrieval, and attention-based retrieval with minimal additional computation. Experiments across multiple VQA benchmarks and object-size groups show that ViRGo improves the accuracy-efficiency trade-off: it matches patch retrieval on small details, leverages attention-based retrieval for larger objects, and reduces inference time by routing to the global baseline when zooming is unnecessary.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ViRGo, a lightweight adaptive routing framework for visual retrieval in VQA tasks. It estimates object scale from a VLM's intrinsic localization heads in the initial forward pass, combines this with semantic token confidence, and routes to one of three strategies—global perception, patch-based retrieval, or attention-based retrieval—to balance the resolution-context trade-off without substantial extra computation. Experiments on multiple VQA benchmarks grouped by object size are claimed to show improved accuracy-efficiency compared to fixed baselines.
Significance. If the routing decisions prove reliable, the framework could meaningfully improve inference efficiency for VLMs on tasks with varying object scales by avoiding unnecessary retrieval while preserving accuracy on both small and large targets. The approach is training-free and leverages existing model components, which is a practical strength if the scale estimator is shown to be sufficiently accurate.
major comments (2)
- [Abstract and method description] The central claim depends on reliable object-scale estimation from the VLM's localization heads during the initial pass, yet the manuscript provides no correlation analysis, ablation, or error metrics comparing these estimates to ground-truth object sizes on the evaluated VQA sets. Without this, it is unclear whether the reported gains arise from adaptive routing or from the three fixed baselines themselves.
- [Abstract] The abstract states that ViRGo 'matches patch retrieval on small details' and 'leverages attention-based retrieval for larger objects' but supplies no quantitative accuracy numbers, baseline comparisons, or inference-time reductions broken down by object-size group. This absence prevents verification of the accuracy-efficiency trade-off improvement.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We agree that strengthening the empirical validation of the scale estimator and providing more explicit quantitative breakdowns will improve the manuscript. We address each point below and will incorporate revisions.
read point-by-point responses
-
Referee: [Abstract and method description] The central claim depends on reliable object-scale estimation from the VLM's localization heads during the initial pass, yet the manuscript provides no correlation analysis, ablation, or error metrics comparing these estimates to ground-truth object sizes on the evaluated VQA sets. Without this, it is unclear whether the reported gains arise from adaptive routing or from the three fixed baselines themselves.
Authors: We agree that explicit validation of the scale estimator is needed to substantiate the routing decisions. In the revised manuscript we will add a dedicated analysis section (including Pearson correlation coefficients, mean absolute error against ground-truth bounding boxes on the VQA benchmarks, and an ablation removing the scale estimate) to demonstrate that the estimator is sufficiently reliable and that performance gains are attributable to adaptive routing rather than the fixed baselines alone. revision: yes
-
Referee: [Abstract] The abstract states that ViRGo 'matches patch retrieval on small details' and 'leverages attention-based retrieval for larger objects' but supplies no quantitative accuracy numbers, baseline comparisons, or inference-time reductions broken down by object-size group. This absence prevents verification of the accuracy-efficiency trade-off improvement.
Authors: The current abstract is intentionally concise. The full paper already reports per-group accuracy and latency results (Tables 2–4 and Figure 3) across small/medium/large object strata on the evaluated benchmarks. To directly address the concern we will revise the abstract to include one or two key quantitative deltas (e.g., “+2.1% accuracy on small objects vs. patch baseline while matching its latency; −18% latency on large objects vs. attention baseline”) and ensure the object-size stratification is highlighted in the abstract itself. revision: yes
Circularity Check
No circularity: adaptive routing framework is self-contained
full rationale
The paper introduces ViRGo as a new framework that estimates object scale from existing VLM localization heads during the initial forward pass and routes among global, patch, and attention strategies based on that estimate plus token confidence. No equations, derivations, or self-citations appear in the provided text that reduce the claimed accuracy-efficiency improvement to a fitted parameter, self-definition, or prior author result by construction. The central claim rests on empirical experiments across VQA benchmarks rather than any algebraic identity or renamed input quantity, rendering the derivation chain independent and non-circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[9]
arXiv preprint arXiv:2503.01222 , year=
Retrieval-augmented perception: High-resolution image perception meets visual rag , author=. arXiv preprint arXiv:2503.01222 , year=
-
[10]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Your large vision-language model only needs a few attention heads for visual grounding , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[11]
arXiv preprint arXiv:2511.20460 , year=
Look Where It Matters: Training-Free Ultra-HR Remote Sensing VQA via Adaptive Zoom Search , author=. arXiv preprint arXiv:2511.20460 , year=
-
[12]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Adaptive-rag: Learning to adapt retrieval-augmented large language models through question complexity , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[13]
arXiv preprint arXiv:2512.09487 , year=
RouteRAG: Efficient Retrieval-Augmented Generation from Text and Graph via Reinforcement Learning , author=. arXiv preprint arXiv:2512.09487 , year=
-
[14]
arXiv preprint arXiv:2306.15195 , year=
Shikra: Unleashing multimodal llm's referential dialogue magic , author=. arXiv preprint arXiv:2306.15195 , year=
-
[15]
arXiv preprint arXiv:2502.17422 , year=
Mllms know where to look: Training-free perception of small visual details with multimodal llms , author=. arXiv preprint arXiv:2502.17422 , year=
-
[16]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Gqa: A new dataset for real-world visual reasoning and compositional question answering , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[17]
arXiv preprint arXiv:2312.14135 , year=
V*: Guided Visual Search as a Core Mechanism in Multimodal LLMs , author=. arXiv preprint arXiv:2312.14135 , year=
-
[18]
arXiv preprint arXiv:2411.16044 , year=
ZoomEye: Enhancing Multimodal LLMs with Human-Like Zooming Capabilities through Tree-Based Image Exploration , author=. arXiv preprint arXiv:2411.16044 , year=
-
[19]
arXiv preprint arXiv:2402.07384 , year=
Exploring perceptual limitation of multimodal large language models , author=. arXiv preprint arXiv:2402.07384 , year=
-
[20]
, author=
Contextual guidance of eye movements and attention in real-world scenes: the role of global features in object search. , author=. Psychological review , volume=. 2006 , publisher=
2006
-
[21]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[22]
LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , url=
Liu, Haotian and Li, Chunyuan and Li, Yuheng and Li, Bo and Zhang, Yuanhan and Shen, Sheng and Lee, Yong Jae , month=. LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , url=
-
[23]
Improved Baselines with Visual Instruction Tuning , author=
-
[24]
Visual Instruction Tuning , author=
-
[25]
European Conference on Computer Vision , pages=
Vary: Scaling up the vision vocabulary for large vision-language model , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[26]
arXiv preprint arXiv:2403.05525 , year=
Deepseek-vl: towards real-world vision-language understanding , author=. arXiv preprint arXiv:2403.05525 , year=
-
[27]
IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
Mini-Gemini: Mining the Potential of Multi-Modality Vision Language Models , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , year=
-
[28]
ArXiv , year=
ConvLLaVA: Hierarchical Backbones as Visual Encoder for Large Multimodal Models , author=. ArXiv , year=
-
[29]
2023 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
Segment Anything , author=. 2023 IEEE/CVF International Conference on Computer Vision (ICCV) , year=
2023
-
[30]
2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
A ConvNet for the 2020s , author=. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2022
-
[31]
2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
WebQA: Multihop and Multimodal QA , author=. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2022
-
[32]
2017 IEEE International Conference on Computer Vision (ICCV) , year=
Automatic Spatially-Aware Fashion Concept Discovery , author=. 2017 IEEE International Conference on Computer Vision (ICCV) , year=
2017
-
[33]
ArXiv , year=
MMed-RAG: Versatile Multimodal RAG System for Medical Vision Language Models , author=. ArXiv , year=
-
[34]
ArXiv , year=
VisRAG: Vision-based Retrieval-augmented Generation on Multi-modality Documents , author=. ArXiv , year=
-
[35]
2024 , eprint=
LLaVA-OneVision: Easy Visual Task Transfer , author=. 2024 , eprint=
2024
-
[36]
ArXiv , year=
Dragonfly: Multi-Resolution Zoom Supercharges Large Visual-Language Model , author=. ArXiv , year=
-
[37]
ArXiv , year=
Beyond LLaVA-HD: Diving into High-Resolution Large Multimodal Models , author=. ArXiv , year=
-
[38]
ArXiv , year=
Divide, Conquer and Combine: A Training-Free Framework for High-Resolution Image Perception in Multimodal Large Language Models , author=. ArXiv , year=
-
[39]
2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
V*: Guided Visual Search as a Core Mechanism in Multimodal LLMs , author=. 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
2024
-
[40]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[41]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Towards vqa models that can read , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.