A Set-Theoretic Approach to Detecting Logic Bugs in DBMS Inner Join Optimizations
Pith reviewed 2026-06-26 06:24 UTC · model grok-4.3
The pith
Set intersection rules rewrite inner joins to detect logic bugs in DBMS optimizers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
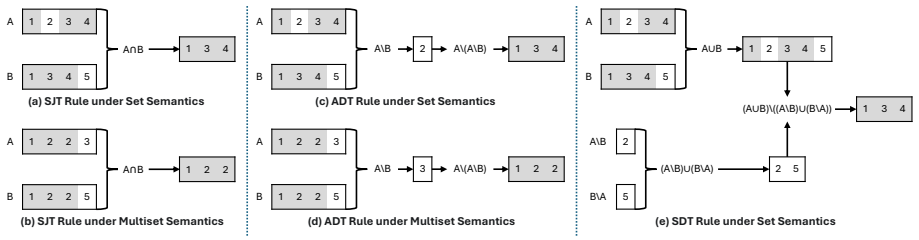
Three semantics-preserving transformation rules derived from set intersection—symmetric join transformation, asymmetric difference transformation, and symmetric difference transformation—rewrite any valid inner join query into an equivalent form; JoinEquiv uses these rewrites as an oracle to expose logical inconsistencies by comparing results of the original and transformed queries.
What carries the argument
JoinEquiv, which applies the three intersection-derived rewrite rules to generate equivalent queries and compare their results for detecting inner join optimization bugs.
If this is right
- DBMSs can be tested for join logic bugs without requiring an external ground-truth result.
- The technique identified 29 previously unknown issues across MySQL, TiDB, DuckDB, and Percona.
- 27 of the 29 issues received official confirmation from the respective vendors.
- The detected inconsistencies point to flaws in both the optimizer and the executor components.
Where Pith is reading between the lines
- The same intersection-based rewriting could be adapted to test other relational operators such as outer joins or set operations.
- Integration of these rules into automated regression suites would allow ongoing verification after optimizer changes.
- The approach supplies a practical way to check whether claimed query equivalences in research papers hold in actual systems.
Load-bearing premise
The three transformation rules always produce queries whose result sets are identical to those of the original inner join queries.
What would settle it
A single valid inner join query for which one of the three rules produces a result set different from the original in a reference implementation known to be correct would falsify the approach.
Figures


read the original abstract
The query optimizer is a fundamental component of database management systems that determines the most efficient execution strategy for a given query by evaluating alternative query plans. Among its tasks, join optimization plays a central role, as the order of joins in multi-table queries can significantly affect execution performance. However, due to the inherent complexity of join optimization, logical bugs are inevitable and often difficult to detect. While existing fuzzing tools have shown notable success in uncovering crash- and performance-related errors, effectively identifying logical bugs -- cases in which the system produces incorrect query results -- remains largely unresolved. In this paper, we propose a metamorphic testing approach to detect DBMS bugs related to INNER JOIN optimization through the lens of set theory. For each testing case, equivalent queries are generated based on a basic set operation -- intersection -- and three semantics-preserving transformation rules, i.e., symmetric join transformation, asymmetric difference transformation, and symmetric difference transformation, are introduced. These rules rewrite a simple NATURAL/INNER JOIN query into a more complex, yet semantically equivalent, form. We implement this design in JoinEquiv, which serves as a testing oracle to systematically uncover logical inconsistencies in DBMS query processing by comparing the results of original and transformed queries. Using JoinEquiv, we uncovered 29 previously unknown issues in mainstream DBMSs (MySQL, TiDB, DuckDB, and Percona), and 27 of them were officially confirmed. JoinEquiv reveals deep logical flaws in DBMS optimizers and executors, underscoring its value in enhancing DBMS robustness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces JoinEquiv, a metamorphic testing approach for detecting logic bugs in DBMS INNER JOIN optimizations. It uses three transformation rules derived from set intersection (symmetric join transformation, asymmetric difference transformation, and symmetric difference transformation) to rewrite simple NATURAL/INNER JOIN queries into more complex but purportedly equivalent forms, then compares execution results across original and rewritten queries to identify inconsistencies. The authors report that JoinEquiv uncovered 29 previously unknown issues in MySQL, TiDB, DuckDB, and Percona, with 27 officially confirmed.
Significance. If the transformations are semantics-preserving under the target DBMS semantics, the approach offers a creative set-theoretic oracle for metamorphic testing of join optimizations, an area where logic bugs are hard to detect. The reported vendor confirmations indicate that the method can surface real issues in production systems. The work does not include machine-checked proofs or reproducible artifacts that would strengthen the claims.
major comments (2)
- [Section on transformation rules (derived from set intersection)] The section deriving the three semantics-preserving transformation rules: The rules are justified solely via set intersection in pure set theory, with the claim that they always produce identical result sets for any valid INNER JOIN. No formal equivalence proof, case analysis, or validation is supplied for SQL multiset (bag) semantics (duplicate preservation) or three-valued logic (NULL propagation in join predicates and results). This is load-bearing for the central claim, as any observed discrepancy between original and rewritten queries could arise from the rewrite itself rather than a DBMS bug.
- [Evaluation section] The evaluation/results section reporting the 29 issues: The abstract and results state that 29 issues were uncovered and 27 confirmed, but the manuscript supplies no details on the total number of queries executed, the procedure used to rule out false positives from the oracle, the criteria for distinguishing bugs from other discrepancies, or how confirmations were obtained from vendors. This directly affects the reliability of the empirical contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the manuscript's claims on transformation equivalence and evaluation transparency.
read point-by-point responses
-
Referee: [Section on transformation rules (derived from set intersection)] The section deriving the three semantics-preserving transformation rules: The rules are justified solely via set intersection in pure set theory, with the claim that they always produce identical result sets for any valid INNER JOIN. No formal equivalence proof, case analysis, or validation is supplied for SQL multiset (bag) semantics (duplicate preservation) or three-valued logic (NULL propagation in join predicates and results). This is load-bearing for the central claim, as any observed discrepancy between original and rewritten queries could arise from the rewrite itself rather than a DBMS bug.
Authors: We acknowledge that the manuscript grounds the rules in set intersection without supplying an explicit formal proof or exhaustive case analysis for SQL multiset semantics and three-valued logic. While the transformations target equi-joins on non-null keys where set and bag semantics align for INNER JOIN, we agree this requires strengthening. In revision we will add a dedicated subsection providing a case analysis that covers duplicate preservation, NULL propagation in predicates and results, and equivalence arguments under standard SQL semantics, supported by concrete examples. revision: yes
-
Referee: [Evaluation section] The evaluation/results section reporting the 29 issues: The abstract and results state that 29 issues were uncovered and 27 confirmed, but the manuscript supplies no details on the total number of queries executed, the procedure used to rule out false positives from the oracle, the criteria for distinguishing bugs from other discrepancies, or how confirmations were obtained from vendors. This directly affects the reliability of the empirical contribution.
Authors: We agree that the evaluation section omits key methodological details needed for assessing the empirical results. In the revised manuscript we will expand the evaluation to report the total number of queries generated and executed, the procedure for ruling out false positives (including manual equivalence checks and cross-DBMS validation), the precise criteria used to classify discrepancies as logic bugs, and the timeline and nature of vendor communications that led to the 27 confirmations. revision: yes
Circularity Check
No significant circularity; derivation is self-contained against external oracles
full rationale
The paper derives three rewrite rules from set intersection and uses them as a metamorphic oracle to compare original vs. rewritten INNER JOIN queries executed on real DBMSs. No equations reduce a 'prediction' to a fitted parameter, no load-bearing self-citation chain exists, and the central claim (discrepancies indicate bugs) rests on external execution results rather than internal redefinition. The method is therefore independent of its own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The symmetric join, asymmetric difference, and symmetric difference transformations preserve the semantics of any valid INNER JOIN query.
Reference graph
Works this paper leans on
-
[1]
Relational data-base management systems,
D. D. Chamberlin, “Relational data-base management systems,”ACM Comput. Surv., vol. 8, no. 1, pp. 43–66, 1976
1976
-
[2]
Intel “big data
M. Stonebraker, S. Madden, and P. Dubey, “Intel “big data” science and technology center vision and execution plan,”SIGMOD Rec., vol. 42, no. 1, pp. 44–49, 2013
2013
-
[3]
What goes around comes around... and around
M. Stonebraker and A. Pavlo, “What goes around comes around... and around...”SIGMOD Rec., vol. 53, no. 2, pp. 21–37, 2024
2024
-
[4]
Quantum data management in the NISQ era,
R. Hai, S.-H. Hung, T. Coopmans, T. Littau, and F. Geerts, “Quantum data management in the NISQ era,”Proc. VLDB Endow., vol. 18, no. 6, pp. 1720–1729, 2025
2025
-
[5]
Plan stitch: Harnessing the best of many plans,
B. Ding, S. Das, W. Wu, S. Chaudhuri, and V . Narasayya, “Plan stitch: Harnessing the best of many plans,”Proc. VLDB Endow., vol. 11, no. 10, pp. 1123–1136, 2018
2018
-
[6]
Neo: A learned query optimizer,
R. Marcus, P. Negi, H. Mao, C. Zhang, M. Alizadeh, T. Kraska, O. Papaemmanouil, and N. Tatbul, “Neo: A learned query optimizer,” Proc. VLDB Endow., vol. 12, no. 11, pp. 1705–1718, 2019
2019
-
[7]
Simple adap- tive query processing vs. learned query optimizers: Observations and analysis,
Y . Zhang, Y . Chronis, J. M. Patel, and T. Rekatsinas, “Simple adap- tive query processing vs. learned query optimizers: Observations and analysis,”Proc. VLDB Endow., vol. 16, no. 11, pp. 2962–2975, 2023
2023
-
[8]
Adaptive optimization of very large join queries,
T. Neumann and B. Radke, “Adaptive optimization of very large join queries,” inProceedings of the 2018 International Conference on Management of Data, 2018, pp. 677–692
2018
-
[9]
Spatial query optimization with learning,
X. Zhang and A. Eldawy, “Spatial query optimization with learning,” Proc. VLDB Endow., vol. 17, no. 12, pp. 4245–4248, 2024
2024
-
[10]
Debunking the myth of join ordering: Toward robust SQL analytics,
J. Zhao, K. Su, Y . Yang, X. Yu, P. Koutris, and H. Zhang, “Debunking the myth of join ordering: Toward robust SQL analytics,”Proc. ACM Manag. Data, vol. 3, no. 3, pp. 146:1–146:28, 2025
2025
-
[11]
Robust join processing with diamond hardened joins,
A. Birler, A. Kemper, and T. Neumann, “Robust join processing with diamond hardened joins,”Proc. VLDB Endow., vol. 17, no. 11, pp. 3215– 3228, 2024
2024
-
[12]
Output-optimal algorithms for join-aggregate queries,
X. Hu, “Output-optimal algorithms for join-aggregate queries,”Proc. ACM Manag. Data, vol. 3, no. 2, pp. 104:1–104:27, 2025
2025
-
[13]
Optimizing queries with many-to-many joins,
H. Kalumin and A. Deshpande, “Optimizing queries with many-to-many joins,” in2025 IEEE 41st International Conference on Data Engineering (ICDE), 2025, pp. 3668–3681
2025
-
[14]
Test oracle,
Wikipedia, “Test oracle,” https://en.wikipedia.org/wiki/Test oracle, 2025, accessed: 2025-10-27
2025
-
[15]
Theoretical and empirical studies of program testing,
W. E. Howden, “Theoretical and empirical studies of program testing,” IEEE Trans. Softw. Eng., no. 4, pp. 293–298, 2006
2006
-
[16]
SQLSmith,
A. Seltenreich, “SQLSmith,” https://github.com/anse1/sqlsmith, 2025, accessed: 2025-10-27
2025
-
[17]
American fuzzy lop,
M. Zalewski, “American fuzzy lop,” https://github.com/google/AFL, 2025, accessed: 2025-10-27
2025
-
[18]
Massive stochastic testing of SQL,
D. R. Slutz, “Massive stochastic testing of SQL,” inProceedings of 24rd International Conference on Very Large Data Bases, 1998, pp. 618–622
1998
-
[19]
Testing database engines via pivoted query synthesis,
M. Rigger and Z. Su, “Testing database engines via pivoted query synthesis,” in14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20), 2020, pp. 667–682
2020
-
[20]
Finding bugs in database systems via query partitioning,
——, “Finding bugs in database systems via query partitioning,”Proc. ACM Program. Lang., vol. 4, no. OOPSLA, pp. 211:1–211:30, 2020
2020
-
[21]
THANOS: DBMS bug detection via storage engine rotation based differential testing,
Y . Fu, Z. Wu, Y . Zhang, J. Liang, J. Fu, Y . Jiang, S. Li, and X. Liao, “THANOS: DBMS bug detection via storage engine rotation based differential testing,” in2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE), 2024, pp. 1–12
2024
-
[22]
Detecting optimization bugs in database engines via non-optimizing reference engine construction,
M. Rigger and Z. Su, “Detecting optimization bugs in database engines via non-optimizing reference engine construction,” inProceedings of the 28th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, 2020, pp. 1140–1152
2020
-
[23]
Detecting schema-related logic bugs in relational DBMSs via equiv- alent database construction,
J. Song, W. Dou, Y . Zheng, Y . Gao, Z. Cui, W. Wang, and J. Wei, “Detecting schema-related logic bugs in relational DBMSs via equiv- alent database construction,”Proc. VLDB Endow., vol. 18, no. 7, pp. 2281–2294, 2025
2025
-
[24]
Detecting logic bugs of join optimizations in DBMS,
X. Tang, S. Wu, D. Zhang, F. Li, and G. Chen, “Detecting logic bugs of join optimizations in DBMS,”Proc. ACM Manag. Data, vol. 1, no. 1, pp. 55:1–55:26, 2023
2023
-
[25]
Keep it simple: Testing databases via differential query plans,
J. Ba and M. Rigger, “Keep it simple: Testing databases via differential query plans,”Proc. ACM Manag. Data, vol. 2, no. 3, pp. 188:1–188:26, 2024
2024
-
[26]
PingCAP, “TiDB,” https://pingcap.com/tidb, 2025, accessed: 2025-10- 27
2025
-
[27]
SQLancer,
M. Rigger, “SQLancer,” https://github.com/sqlancer/sqlancer, 2025, ac- cessed: 2025-10-27
2025
-
[28]
A relational model of data for large shared data banks,
E. F. Codd, “A relational model of data for large shared data banks,” Commun. ACM, vol. 13, no. 6, pp. 377–387, 1970
1970
-
[29]
Access path selection in a relational database management system,
P. G. Selinger, M. M. Astrahan, D. D. Chamberlin, R. A. Lorie, and T. G. Price, “Access path selection in a relational database management system,” inProceedings of the 1979 ACM SIGMOD International Conference on Management of Data, 1979, pp. 23–34
1979
-
[30]
The volcano optimizer generator: Exten- sibility and efficient search,
G. Graefe and W. J. McKenna, “The volcano optimizer generator: Exten- sibility and efficient search,” inProceedings of the Ninth International Conference on Data Engineering, 1993, pp. 209–218
1993
-
[31]
An overview of query optimization in relational systems,
S. Chaudhuri, “An overview of query optimization in relational systems,” inProceedings of the Seventeenth ACM SIGACT-SIGMOD-SIGART Symposium on Principles of Database Systems, 1998, pp. 34–43
1998
-
[32]
Query optimization through the looking glass, and what we found running the join order benchmark,
V . Leis, B. Radke, A. Gubichev, A. Mirchev, P. A. Boncz, A. Kemper, and T. Neumann, “Query optimization through the looking glass, and what we found running the join order benchmark,”VLDB J., vol. 27, no. 5, pp. 643–668, 2018
2018
-
[33]
Metamorphic testing: A new approach for generating next test cases,
T. Y . Chen, S.-C. Cheung, and S.-M. Yiu, “Metamorphic testing: A new approach for generating next test cases,”arXiv:2002.12543, 2020
arXiv 2002
-
[34]
Metamorphic testing: A review of challenges and opportunities,
T. Y . Chen, F.-C. Kuo, H. Liu, P.-L. Poon, D. Towey, T. H. Tse, and Z. Q. Zhou, “Metamorphic testing: A review of challenges and opportunities,” ACM Comput. Surv., vol. 51, no. 1, pp. 4:1–4:27, 2018
2018
-
[35]
A survey on metamorphic testing,
S. Segura, G. Fraser, A. B. S ´anchez, and A. R. Cort ´es, “A survey on metamorphic testing,”IEEE Trans. Softw. Eng., vol. 42, no. 9, pp. 805– 824, 2016
2016
-
[36]
Richard Hipp speaks out on SQLite,
M. Winslett and V . Braganholo, “Richard Hipp speaks out on SQLite,” SIGMOD Rec., vol. 48, no. 2, pp. 39–46, 2019
2019
-
[37]
CERT: Finding performance issues in database systems through the lens of cardinality estimation,
J. Ba and M. Rigger, “CERT: Finding performance issues in database systems through the lens of cardinality estimation,” inProceedings of the 46th IEEE/ACM International Conference on Software Engineering, 2024, pp. 133:1–133:13
2024
-
[38]
QAGen: generating query-aware test databases,
C. Binnig, D. Kossmann, E. Lo, and M. T. ¨Ozsu, “QAGen: generating query-aware test databases,” inProceedings of the 2007 ACM SIGMOD International Conference on Management of Data, 2007, pp. 341–352
2007
-
[39]
Flexible database generators,
N. Bruno and S. Chaudhuri, “Flexible database generators,” inProceed- ings of the 31st International Conference on Very Large Data Bases, 2005, pp. 1097–1107
2005
-
[40]
Quickly generating billion-record synthetic databases,
J. Gray, P. Sundaresan, S. Englert, K. Baclawski, and P. J. Weinberger, “Quickly generating billion-record synthetic databases,” inProceedings of the 1994 ACM SIGMOD International Conference on Management of Data, 1994, pp. 243–252
1994
-
[41]
Simple and realistic data gener- ation,
K. Houkjær, K. Torp, and R. Wind, “Simple and realistic data gener- ation,” inProceedings of the 32nd International Conference on Very Large Data Bases, 2006, pp. 1243–1246
2006
-
[42]
Query- aware test generation using a relational constraint solver,
S. A. Khalek, B. Elkarablieh, Y . O. Laleye, and S. Khurshid, “Query- aware test generation using a relational constraint solver,” in2008 23rd IEEE/ACM International Conference on Automated Software Engineer- ing, 2008, pp. 238–247
2008
-
[43]
A genetic approach for random testing of database systems,
H. Bati, L. Giakoumakis, S. Herbert, and A. Surna, “A genetic approach for random testing of database systems,” inProceedings of the 33rd International Conference on Very Large Data Bases, 2007, pp. 1243– 1251
2007
-
[44]
Generating queries with cardinality constraints for DBMS testing,
N. Bruno, S. Chaudhuri, and D. Thomas, “Generating queries with cardinality constraints for DBMS testing,”IEEE Trans. Knowl. Data Eng., vol. 18, no. 12, pp. 1721–1725, 2006
2006
-
[45]
Apollo: Automatic detection and diagnosis of performance regressions in database systems,
J. Jung, H. Hu, J. Arulraj, T. Kim, and W. Kang, “Apollo: Automatic detection and diagnosis of performance regressions in database systems,” Proc. VLDB Endow., vol. 13, no. 1, pp. 57–70, 2019
2019
-
[46]
Generating targeted queries for database testing,
C. Mishra, N. Koudas, and C. Zuzarte, “Generating targeted queries for database testing,” inProceedings of the 2008 ACM SIGMOD International Conference on Management of Data, 2008, pp. 499–510
2008
-
[47]
Generating thousand benchmark queries in seconds,
M. Poess and J. M. Stephens Jr, “Generating thousand benchmark queries in seconds,” inProceedings of the 30th International Conference on Very Large Data Bases, 2004, pp. 1045–1053
2004
-
[48]
QRelX: generating meaningful queries that provide cardinality assurance,
M. Vartak, V . Raghavan, and E. A. Rundensteiner, “QRelX: generating meaningful queries that provide cardinality assurance,” inProceedings of the 2010 ACM SIGMOD International Conference on Management of data, 2010, pp. 1215–1218
2010
-
[49]
Testing the accuracy of query optimizers,
Z. Gu, M. A. Soliman, and F. M. Waas, “Testing the accuracy of query optimizers,” inProceedings of the Fifth International Workshop on Testing Database Systems, 2012, pp. 1–6
2012
-
[50]
Automated SQL query generation for systematic testing of database engines,
S. Abdul Khalek and S. Khurshid, “Automated SQL query generation for systematic testing of database engines,” inProceedings of the 25th IEEE/ACM International Conference on Automated Software Engineer- ing, 2010, pp. 329–332
2010
-
[51]
A framework for testing DBMS features,
E. Lo, C. Binnig, D. Kossmann, M. Tamer ¨Ozsu, and W.-K. Hon, “A framework for testing DBMS features,”VLDB J., vol. 19, no. 2, pp. 203–230, 2010
2010
-
[52]
Snowtrail: Testing with production queries on a cloud database,
J. Yan, Q. Jin, S. Jain, S. D. Viglas, and A. Lee, “Snowtrail: Testing with production queries on a cloud database,” inProceedings of the Workshop on Testing Database Systems, 2018, pp. 1–6
2018
-
[53]
SQUIRREL: Testing database management systems with language validity and cov- erage feedback,
R. Zhong, Y . Chen, H. Hu, H. Zhang, W. Lee, and D. Wu, “SQUIRREL: Testing database management systems with language validity and cov- erage feedback,” inProceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security, 2020, pp. 955–970
2020
-
[54]
REDQUEEN: Fuzzing with input-to-state correspondence,
C. Aschermann, S. Schumilo, T. Blazytko, R. Gawlik, and T. Holz, “REDQUEEN: Fuzzing with input-to-state correspondence,” in26th Annual Network and Distributed System Security Symposium (NDSS), 2019, pp. 1–15
2019
-
[55]
EnFuzz: Ensemble fuzzing with seed synchronization among diverse fuzzers,
Y . Chen, Y . Jiang, F. Ma, J. Liang, M. Wang, C. Zhou, X. Jiao, and Z. Su, “EnFuzz: Ensemble fuzzing with seed synchronization among diverse fuzzers,” in28th USENIX Security Symposium (USENIX Security 19), 2019, pp. 1967–1983
2019
-
[56]
DeepFuzzer: Accelerated deep greybox fuzzing,
J. Liang, Y . Jiang, M. Wang, X. Jiao, Y . Chen, H. Song, and K.-K. R. Choo, “DeepFuzzer: Accelerated deep greybox fuzzing,”IEEE Trans. Dependable Secur. Comput., vol. 18, no. 6, pp. 2675–2688, 2019
2019
-
[57]
PATA: Fuzzing with path aware taint analysis,
J. Liang, M. Wang, C. Zhou, Z. Wu, Y . Jiang, J. Liu, Z. Liu, and J. Sun, “PATA: Fuzzing with path aware taint analysis,” in2022 IEEE Symposium on Security and Privacy (SP), 2022, pp. 1–17
2022
-
[58]
RIFF: Reduced instruction footprint for Coverage-Guided fuzzing,
M. Wang, J. Liang, C. Zhou, Y . Jiang, R. Wang, C. Sun, and J. Sun, “RIFF: Reduced instruction footprint for Coverage-Guided fuzzing,” in 2021 USENIX Annual Technical Conference (USENIX ATC 21), 2021, pp. 147–159
2021
-
[59]
Industry practice of coverage-guided enterprise-level DBMS fuzzing,
M. Wang, Z. Wu, X. Xu, J. Liang, C. Zhou, H. Zhang, and Y . Jiang, “Industry practice of coverage-guided enterprise-level DBMS fuzzing,” in2021 IEEE/ACM 43rd International Conference on Software Engi- neering: Software Engineering in Practice (ICSE-SEIP), 2021, pp. 328– 337
2021
-
[60]
Unicorn: detect runtime errors in time-series databases with hybrid input synthesis,
Z. Wu, J. Liang, M. Wang, C. Zhou, and Y . Jiang, “Unicorn: detect runtime errors in time-series databases with hybrid input synthesis,” in Proceedings of the 31st ACM SIGSOFT International Symposium on Software Testing and Analysis, 2022, pp. 251–262
2022
-
[61]
QSYM: A practical concolic execution engine tailored for hybrid fuzzing,
I. Yun, S. Lee, M. Xu, Y . Jang, and T. Kim, “QSYM: A practical concolic execution engine tailored for hybrid fuzzing,” in27th USENIX Security Symposium (USENIX Security 18), 2018, pp. 745–761
2018
-
[62]
Sequence-oriented DBMS fuzzing,
J. Liang, Y . Chen, Z. Wu, J. Fu, M. Wang, Y . Jiang, X. Huang, T. Chen, J. Wang, and J. Li, “Sequence-oriented DBMS fuzzing,” in2023 IEEE 39th International Conference on Data Engineering (ICDE), 2023, pp. 668–681
2023
-
[63]
Griffin : Grammar-free DBMS fuzzing,
J. Fu, J. Liang, Z. Wu, M. Wang, and Y . Jiang, “Griffin : Grammar-free DBMS fuzzing,” inProceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering, 2022, pp. 49:1–49:12
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.