HYDRA-X: Native Unified Multimodal Models with Holistic Visual Tokenizers
Pith reviewed 2026-06-27 06:59 UTC · model grok-4.3
The pith
HYDRA-X unifies image and video tokenization inside one Vision Transformer for multimodal models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
HYDRA-X demonstrates that a native ViT can serve as a holistic visual tokenizer unifying image and video by using frame-level causal temporal attention, hierarchical temporal compression, and a lightweight decompressor under joint teacher supervision, leading to improved editing consistency when latent-level interactions are used and competitive results across image and video tasks.
What carries the argument
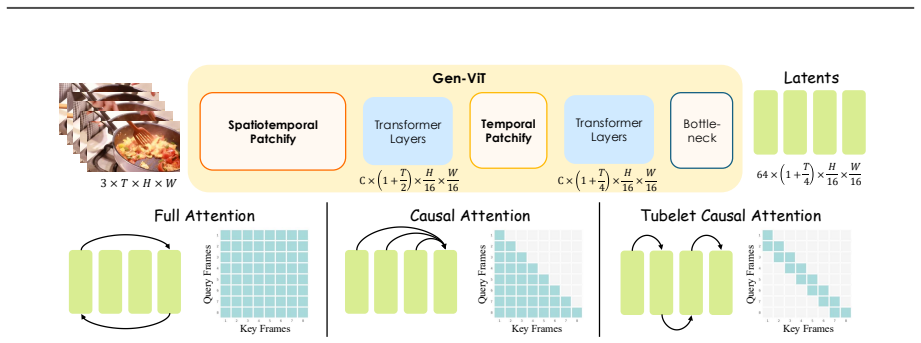
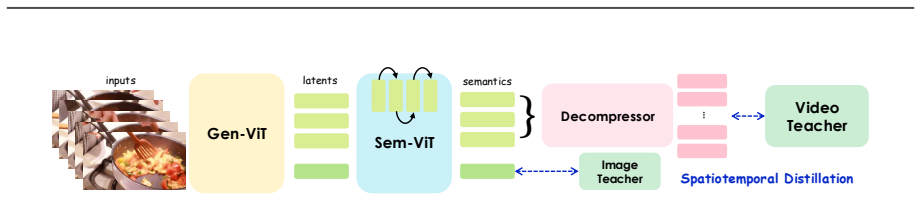
Holistic visual tokenizer: a single ViT with causal temporal attention, hierarchical compression, and joint-supervised decompressor that maps diverse visual inputs to a unified latent space.
If this is right
- Frame-level causal temporal attention suffices for visual reconstruction while full spatiotemporal attention degrades it.
- Hierarchical temporal compression substantially outperforms single-step alternatives.
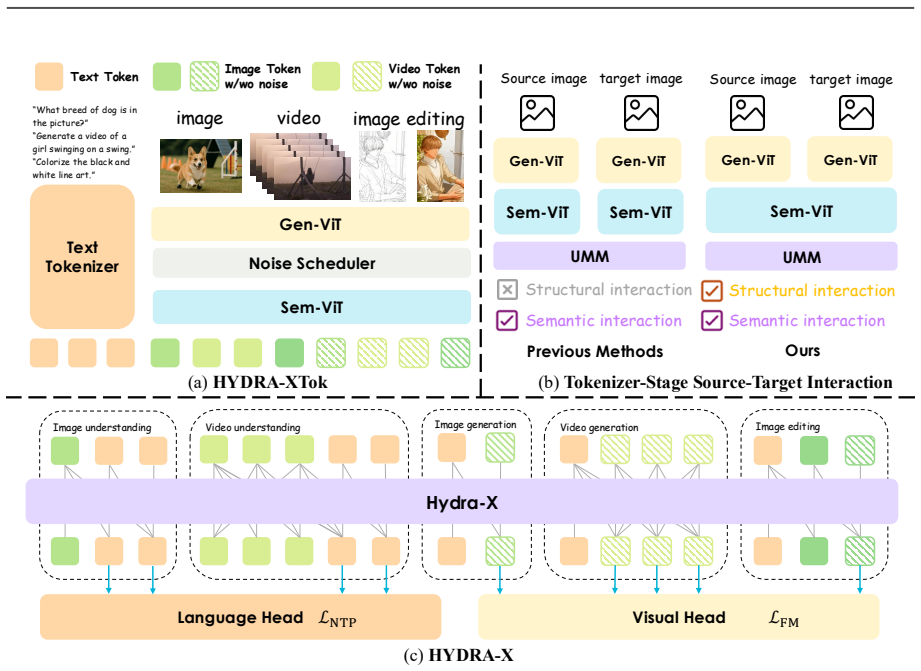
- Source-target interaction at the latent level inside the tokenizer improves editing consistency and accelerates convergence.
- HYDRA-X achieves strong performance across image and video understanding and generation tasks at 7B scale.
Where Pith is reading between the lines
- If the joint supervision approach holds, similar decompressor designs could extend to other multimodal combinations like text and audio without major conflicts.
- Testing the tokenizer on longer video sequences would reveal if the hierarchical compression scales effectively beyond current lengths.
- The latent-level editing improvement suggests that future UMMs might benefit from tighter integration between tokenizer and generation modules.
Load-bearing premise
Joint image-video teacher supervision via the lightweight decompressor embeds complementary semantic structures in the compact latent space without conflicts.
What would settle it
A direct comparison showing that the decompressor-trained latent space leads to measurable conflicts, such as reduced performance on video-specific tasks when image semantics dominate or vice versa, would falsify the unification claim.
Figures








read the original abstract
Holistic visual tokenizers are fundamental to unified multimodal models (UMMs) as they map diverse visual inputs into a unified representation space. In this paper, we present HYDRA-X, the first UMM that unifies image and video tokenization within a single Vision Transformer (ViT). Our design is driven by two core challenges: efficiently injecting spatiotemporal reconstruction capability into a native ViT, and embedding image- and video-level semantic awareness into the latent space. To address the first, comprehensive ablations reveal two key findings: (1) frame-level causal temporal attention suffices for visual reconstruction, whereas full spatiotemporal attention degrades it; and (2) hierarchical temporal compression substantially outperforms single-step alternatives. To tackle the second, we propose a lightweight decompressor that upsamples temporally compressed features under joint image-video teacher supervision, thereby enforcing complementary semantic structures within the compact latent space. Building on this holistic tokenizer, we further propose a principled improvement of the editing pipeline: source-target interaction should occur at the latent level inside the tokenizer rather than at the semantic level inside the LLM, substantially improving editing consistency and accelerating convergence. Instantiated at the 7B dense model, HYDRA-X achieves strong performance across image and video understanding and generation tasks, paving the way for future unified-tokenizer UMMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents HYDRA-X as the first unified multimodal model (UMM) that unifies image and video tokenization inside a single Vision Transformer (ViT). It reports ablation findings that frame-level causal temporal attention suffices for reconstruction while full spatiotemporal attention degrades it, and that hierarchical temporal compression outperforms single-step alternatives. A lightweight decompressor is proposed to upsample compressed features under joint image-video teacher supervision to embed complementary semantics. The work also advocates performing source-target interaction at the latent level inside the tokenizer rather than inside the LLM for editing, and claims strong performance on image/video understanding and generation at the 7B scale.
Significance. If the empirical results and ablations hold, the work could be significant for simplifying UMM design by demonstrating that a native ViT can serve as a holistic spatiotemporal tokenizer, with the editing-pipeline change potentially improving consistency. The reported ablation outcomes on causal attention and hierarchical compression would be useful contributions to tokenizer architecture.
major comments (2)
- [Abstract] Abstract: the claim that the 7B model 'achieves strong performance across image and video understanding and generation tasks' is presented with no metrics, baselines, datasets, error bars, or quantitative comparisons, which is load-bearing for validating the central tokenizer and decompressor design.
- [Abstract] Abstract (paragraph on the decompressor design): the premise that joint image-video teacher supervision will embed complementary semantic structures in the compact latent space without conflicts is asserted but receives no supporting analysis, ablation, or result, which is load-bearing for the semantic-awareness claim.
minor comments (1)
- [Abstract] Abstract: the phrase 'native ViT' is used without a precise definition of what architectural modifications preserve 'nativeness' while adding causal temporal attention and the decompressor.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that the claims require more explicit quantitative grounding and will revise the abstract accordingly while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the 7B model 'achieves strong performance across image and video understanding and generation tasks' is presented with no metrics, baselines, datasets, error bars, or quantitative comparisons, which is load-bearing for validating the central tokenizer and decompressor design.
Authors: We agree the abstract statement is insufficiently supported as written. The full paper contains tables with metrics, baselines, and datasets for both understanding and generation tasks at the 7B scale. In revision we will replace the generic claim with a concise summary of the strongest quantitative results (including specific metrics and comparisons) to make the abstract self-contained. revision: yes
-
Referee: [Abstract] Abstract (paragraph on the decompressor design): the premise that joint image-video teacher supervision will embed complementary semantic structures in the compact latent space without conflicts is asserted but receives no supporting analysis, ablation, or result, which is load-bearing for the semantic-awareness claim.
Authors: We acknowledge that the abstract asserts the benefit of joint supervision without direct evidence. The manuscript body reports ablations on the decompressor and joint training; however, these are not referenced in the abstract. We will revise the abstract to either cite the relevant experimental findings or qualify the claim, ensuring the semantic-awareness motivation is evidence-based. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents HYDRA-X as an empirical architecture whose core claims (unified image-video tokenization in a single ViT, causal temporal attention sufficiency, hierarchical compression benefits, and latent-level editing) rest on ablations and downstream task performance rather than any closed derivation. No equations, fitted parameters renamed as predictions, or self-citation chains are described that would reduce the results to inputs by construction. The decompressor design is motivated by stated findings but is not shown to be self-definitional or forced by prior author work in a load-bearing way. This is the normal case of a design paper whose validity is externally testable via replication.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2408.11039 , year=
Transfusion: Predict the next token and diffuse images with one multi-modal model , author=. arXiv preprint arXiv:2408.11039 , year=
-
[2]
International conference on machine learning , pages=
Similarity of neural network representations revisited , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[3]
2023 , url=
OpenAI , title=. 2023 , url=
2023
-
[4]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Wang, Limin and Huang, Bingkun and Zhao, Zhiyu and Tong, Zhan and He, Yinan and Wang, Yi and Wang, Yali and Qiao, Yu , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2023 , pages =
2023
-
[5]
OpenAI technical report , year=
Improving Image Generation with Better Captions , author=. OpenAI technical report , year=
-
[6]
arXiv preprint arXiv:2010.11929 , year=
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
Pith/arXiv arXiv 2010
-
[7]
arXiv preprint arXiv:2309.17425 , year=
Data filtering networks , author=. arXiv preprint arXiv:2309.17425 , year=
-
[8]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
An empirical study of training self-supervised vision transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[9]
arXiv preprint arXiv:2106.08254 , year=
Beit: Bert pre-training of image transformers , author=. arXiv preprint arXiv:2106.08254 , year=
-
[10]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Vision transformers for dense prediction , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[11]
arXiv preprint arXiv:1907.10326 , year=
From big to small: Multi-scale local planar guidance for monocular depth estimation , author=. arXiv preprint arXiv:1907.10326 , year=
arXiv 1907
-
[12]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mage: Masked generative encoder to unify representation learning and image synthesis , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[13]
arXiv preprint arXiv:2111.11429 , year=
Benchmarking detection transfer learning with vision transformers , author=. arXiv preprint arXiv:2111.11429 , year=
-
[14]
Proceedings of the IEEE international conference on computer vision , pages=
Mask r-cnn , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[15]
ArXiv , year=
Zero-Shot Text-to-Image Generation , author=. ArXiv , year=
-
[16]
ArXiv , year=
Cosmos World Foundation Model Platform for Physical AI , author=. ArXiv , year=
-
[17]
2024 , eprint=
SANA: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformers , author=. 2024 , eprint=
2024
-
[18]
arXiv preprint arXiv:2504.10483 , year=
Repa-e: Unlocking vae for end-to-end tuning with latent diffusion transformers , author=. arXiv preprint arXiv:2504.10483 , year=
-
[19]
arXiv preprint arXiv:2601.05823 , year=
Boosting Latent Diffusion Models via Disentangled Representation Alignment , author=. arXiv preprint arXiv:2601.05823 , year=
-
[20]
arXiv preprint arXiv:2512.13687 , year=
Towards Scalable Pre-training of Visual Tokenizers for Generation , author=. arXiv preprint arXiv:2512.13687 , year=
-
[21]
arXiv preprint arXiv:2503.20314 , year=
Wan: Open and Advanced Large-Scale Video Generative Models , author=. arXiv preprint arXiv:2503.20314 , year=
-
[22]
arXiv preprint arXiv:2510.11690 , year=
Diffusion transformers with representation autoencoders , author=. arXiv preprint arXiv:2510.11690 , year=
-
[23]
arXiv preprint arXiv:2512.19693 , year=
The Prism Hypothesis: Harmonizing Semantic and Pixel Representations via Unified Autoencoding , author=. arXiv preprint arXiv:2512.19693 , year=
-
[25]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[26]
arXiv preprint arXiv:2307.01952 , year=
Sdxl: Improving latent diffusion models for high-resolution image synthesis , author=. arXiv preprint arXiv:2307.01952 , year=
-
[27]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Scalable diffusion models with transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[28]
Advances in Neural Information Processing Systems , volume=
Autoregressive image generation without vector quantization , author=. Advances in Neural Information Processing Systems , volume=
-
[29]
ArXiv , year=
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation , author=. ArXiv , year=
-
[30]
arXiv preprint arXiv:2509.23951 , year=
Hunyuanimage 3.0 technical report , author=. arXiv preprint arXiv:2509.23951 , year=
-
[31]
arXiv preprint arXiv:2510.15301 , year=
Latent diffusion model without variational autoencoder , author=. arXiv preprint arXiv:2510.15301 , year=
-
[32]
arXiv preprint arXiv:2110.04627 , year=
Vector-quantized image modeling with improved vqgan , author=. arXiv preprint arXiv:2110.04627 , year=
-
[33]
arXiv preprint arXiv:2501.18593 , year=
Diffusion autoencoders are scalable image tokenizers , author=. arXiv preprint arXiv:2501.18593 , year=
-
[34]
generation: Taming optimization dilemma in latent diffusion models , author=
Reconstruction vs. generation: Taming optimization dilemma in latent diffusion models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[35]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Autoregressive image generation using residual quantization , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[36]
Advances in Neural Information Processing Systems , volume=
Omnitokenizer: A joint image-video tokenizer for visual generation , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
arXiv preprint arXiv:2507.08441 , year=
Vision Foundation Models as Effective Visual Tokenizers for Autoregressive Image Generation , author=. arXiv preprint arXiv:2507.08441 , year=
-
[38]
Advances in neural information processing systems , volume=
Visual autoregressive modeling: Scalable image generation via next-scale prediction , author=. Advances in neural information processing systems , volume=
-
[39]
Advances in Neural Information Processing Systems , volume=
An image is worth 32 tokens for reconstruction and generation , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
arXiv preprint arXiv:2507.15856 , year=
Latent Denoising Makes Good Visual Tokenizers , author=. arXiv preprint arXiv:2507.15856 , year=
-
[41]
Advances in neural information processing systems , volume=
Generating diverse high-fidelity images with vq-vae-2 , author=. Advances in neural information processing systems , volume=
-
[42]
Foundations and Trends
An introduction to variational autoencoders , author=. Foundations and Trends. 2019 , publisher=
2019
-
[43]
Image Processing Algorithms and Techniques II , volume=
Residual VQ (vector quantizaton) with state prediction: a new method for image coding , author=. Image Processing Algorithms and Techniques II , volume=. 1991 , organization=
1991
-
[44]
Advances in Neural Information Processing Systems , volume=
Movq: Modulating quantized vectors for high-fidelity image generation , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
arXiv preprint arXiv:2409.04410 , year=
Open-magvit2: An open-source project toward democratizing auto-regressive visual generation , author=. arXiv preprint arXiv:2409.04410 , year=
-
[46]
arXiv preprint arXiv:2310.05737 , year=
Language Model Beats Diffusion--Tokenizer is Key to Visual Generation , author=. arXiv preprint arXiv:2310.05737 , year=
-
[47]
International Conference on Learning Representations , year=
Image and Video Tokenization with Binary Spherical Quantization , author=. International Conference on Learning Representations , year=
-
[48]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Softvq-vae: Efficient 1-dimensional continuous tokenizer , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[49]
arXiv preprint arXiv:2410.01756 , year=
Imagefolder: Autoregressive image generation with folded tokens , author=. arXiv preprint arXiv:2410.01756 , year=
-
[50]
Forty-second International Conference on Machine Learning , year=
Masked autoencoders are effective tokenizers for diffusion models , author=. Forty-second International Conference on Machine Learning , year=
-
[51]
2022 , eprint=
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow , author=. 2022 , eprint=
2022
-
[52]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Diffusion autoencoders: Toward a meaningful and decodable representation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[53]
arXiv preprint arXiv:2405.09818 , year=
Chameleon: Mixed-modal early-fusion foundation models , author=. arXiv preprint arXiv:2405.09818 , year=
-
[54]
2025 , eprint=
Towards Semantic Equivalence of Tokenization in Multimodal LLM , author=. 2025 , eprint=
2025
-
[55]
arXiv preprint arXiv:2309.11499 , year=
Dreamllm: Synergistic multimodal comprehension and creation , author=. arXiv preprint arXiv:2309.11499 , year=
-
[56]
arXiv preprint arXiv:2309.04669 , year=
Unified language-vision pretraining in llm with dynamic discrete visual tokenization , author=. arXiv preprint arXiv:2309.04669 , year=
-
[57]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Janus: Decoupling visual encoding for unified multimodal understanding and generation , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[58]
arXiv preprint , year=
World Model on Million-Length Video and Language with RingAttention , author=. arXiv preprint , year=
-
[60]
arXiv preprint arXiv:2310.01218 , year=
Making llama see and draw with seed tokenizer , author=. arXiv preprint arXiv:2310.01218 , year=
-
[61]
Advances in Neural Information Processing Systems , volume=
Datacomp: In search of the next generation of multimodal datasets , author=. Advances in Neural Information Processing Systems , volume=
-
[62]
arXiv preprint arXiv:2409.18869 , year=
Emu3: Next-token prediction is all you need , author=. arXiv preprint arXiv:2409.18869 , year=
-
[63]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[64]
Proceedings of the IEEE/CVF International Conference on Computer Vision , year=
MetaMorph: Multimodal Understanding and Generation via Instruction Tuning , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , year=
-
[65]
arXiv preprint arXiv:2412.06673 , year=
Illume: Illuminating your llms to see, draw, and self-enhance , author=. arXiv preprint arXiv:2412.06673 , year=
-
[66]
arXiv preprint arXiv:2412.00127 , year=
Orthus: Autoregressive interleaved image-text generation with modality-specific heads , author=. arXiv preprint arXiv:2412.00127 , year=
-
[67]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Synergen-vl: Towards synergistic image understanding and generation with vision experts and token folding , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[68]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Vila: On pre-training for visual language models , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[69]
2023 , eprint=
Unified-IO 2: Scaling Autoregressive Multimodal Models with Vision, Language, Audio, and Action , author=. 2023 , eprint=
2023
-
[70]
2025 , eprint=
LMFusion: Adapting Pretrained Language Models for Multimodal Generation , author=. 2025 , eprint=
2025
-
[71]
arXiv preprint arXiv:2502.05178 , year=
Qlip: Text-aligned visual tokenization unifies auto-regressive multimodal understanding and generation , author=. arXiv preprint arXiv:2502.05178 , year=
-
[72]
arXiv preprint arXiv:2505.23661 , year=
OpenUni: A Simple Baseline for Unified Multimodal Understanding and Generation , author=. arXiv preprint arXiv:2505.23661 , year=
-
[73]
arXiv preprint arXiv:2412.04332 , year=
Liquid: Language models are scalable and unified multi-modal generators , author=. arXiv preprint arXiv:2412.04332 , year=
-
[74]
arXiv preprint arXiv:2502.20321 , year=
Unitok: A unified tokenizer for visual generation and understanding , author=. arXiv preprint arXiv:2502.20321 , year=
-
[76]
arXiv preprint arXiv:2507.23278 , year=
UniLiP: Adapting CLIP for Unified Multimodal Understanding, Generation and Editing , author=. arXiv preprint arXiv:2507.23278 , year=
-
[77]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Generative multimodal models are in-context learners , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[78]
arXiv preprint arXiv:2504.01934 , year=
Illume+: Illuminating unified mllm with dual visual tokenization and diffusion refinement , author=. arXiv preprint arXiv:2504.01934 , year=
-
[79]
arXiv preprint arXiv:2412.01762 , year=
Xq-gan: An open-source image tokenization framework for autoregressive generation , author=. arXiv preprint arXiv:2412.01762 , year=
-
[80]
arXiv preprint arXiv:2309.15505 , year=
Finite scalar quantization: Vq-vae made simple , author=. arXiv preprint arXiv:2309.15505 , year=
-
[81]
arXiv preprint arXiv:2503.08354 , year=
Robust latent matters: Boosting image generation with sampling error synthesis , author=. arXiv preprint arXiv:2503.08354 , year=
-
[82]
Proceedings of the IEEE/CVF International Conference on Computer Vision , year=
Flow to the Mode: Mode-Seeking Diffusion Autoencoders for State-of-the-Art Image Tokenization , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , year=
-
[83]
arXiv preprint arXiv:2505.07538 , year=
Selftok: Discrete Visual Tokens of Autoregression, by Diffusion, and for Reasoning , author=. arXiv preprint arXiv:2505.07538 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.