Improving Collaborative Storytelling with a Multi-Agent Framework Based on Large Language Models
Pith reviewed 2026-06-29 07:34 UTC · model grok-4.3
The pith
An iterative writer-editor loop between two LLMs raises the perceived quality of generated stories over successive refinement steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In a simulation study with multiple LLMs, the iterative Writer-Editor process in which one model generates stories and another provides evaluative feedback produces consistent gains in perceived story quality across successive loops, indicating that a limited number of refinement steps can yield high-quality narratives for interactive storytelling with children.
What carries the argument
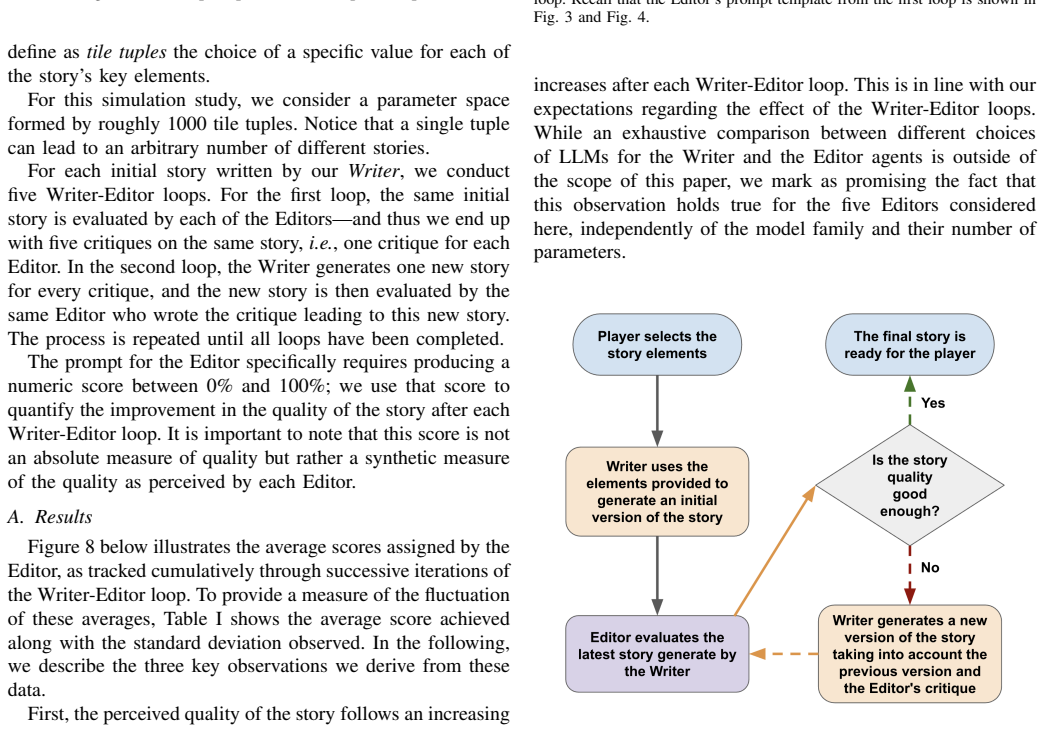
The Writer-Editor iterative interaction, in which one LLM generates a story and a second LLM evaluates it and returns targeted feedback for the next generation round.
If this is right
- Only a small number of refinement loops is required to reach high-quality story outputs.
- The same iterative mechanism can support co-creation between AI and children in a non-digital, physical play setting.
- Multi-agent LLM systems can be applied to ludic co-creation tasks beyond adult digital interfaces.
Where Pith is reading between the lines
- The framework could be adapted to other creative tasks such as generating dialogue or simple illustrations for the same age group.
- If the simulation results hold, the approach might reduce the need for large numbers of human editors in early-stage story development.
- Testing transfer to real children would also reveal whether the feedback language produced by the editor LLM is age-appropriate without further tuning.
Load-bearing premise
Quality gains measured when LLMs critique other LLMs will appear when the same system interacts directly with children using a physical board game.
What would settle it
A controlled test in which children play the board game with the framework and rate the final stories no higher than the initial unrefined versions.
Figures







read the original abstract
The topic of Co-creation, i.e., AI agents interacting with humans to generate outputs (e.g., art), has gained significant attention recently. However, most studies focus on adult-human interactions in a digital setting. This paper explores a novel ludic co-creation scenario involving children and Large Language Models (LLMs) interacting through a physical board game to create written stories. Our goal is to develop a multi-agent framework capable of producing high-quality narratives suitable for young players. At the core of our approach is an iterative Writer-Editor process in which one LLM generates stories while another evaluates them and provides feedback for refinement. Through a simulation study involving multiple LLMs, we show that this iterative interaction consistently improves the perceived quality of generated stories across successive loops. The results indicate that a small number of refinement steps may be sufficient to achieve high-quality outputs in interactive storytelling systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a multi-agent LLM framework for co-creative storytelling in which children and AI interact via a physical board game. The central technical contribution is an iterative Writer-Editor loop in which one LLM generates narrative text and a second LLM evaluates it and supplies feedback for refinement. A simulation study in which both roles are instantiated by LLMs is reported to show consistent gains in perceived story quality across successive iterations, with the conclusion that only a small number of refinement steps are needed to reach high-quality outputs suitable for young players.
Significance. If the iterative refinement mechanism were shown to transfer beyond LLM-LLM simulation, the work would address an under-explored niche of tangible, child-centered co-creation. The simulation itself supplies an existence proof that closed-loop LLM feedback can measurably improve surface-level story metrics, but the absence of any human-subject data or physical-interface testing leaves the claimed suitability for the target population unestablished.
major comments (2)
- [Abstract / Evaluation] Abstract and evaluation section: the central claim that the framework produces "high-quality narratives suitable for young players" rests entirely on an LLM-LLM simulation whose quality metric, number of iterations, statistical controls, and inter-rater reliability are not reported. Because the target population (children) and interaction modality (physical board game) are never instantiated, the observed quality gains do not yet support the application claim.
- [Evaluation] The manuscript provides no ablation or baseline comparison (e.g., single-pass generation versus the iterative loop, or different LLM pairings) that would isolate the contribution of the Writer-Editor mechanism from generic LLM prompting effects.
minor comments (2)
- [Method] Notation for the multi-agent roles and the precise feedback prompt templates should be formalized (e.g., as pseudocode or a diagram) to allow replication.
- [Simulation setup] The paper should explicitly state whether the simulation used the same model family for writer and editor or distinct models, as this choice affects the interpretation of the quality gains.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. Our work presents a simulation-based evaluation of the Writer-Editor framework as an existence proof for iterative refinement in LLM-driven storytelling. We address each point below and note revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation section: the central claim that the framework produces "high-quality narratives suitable for young players" rests entirely on an LLM-LLM simulation whose quality metric, number of iterations, statistical controls, and inter-rater reliability are not reported. Because the target population (children) and interaction modality (physical board game) are never instantiated, the observed quality gains do not yet support the application claim.
Authors: We agree the abstract phrasing is too strong and will revise it to emphasize that results are from an LLM simulation study demonstrating iterative quality gains, with the child/board-game application positioned as future work. The evaluation section reports LLM-based scoring on coherence, engagement and appropriateness, with improvements observed across 1-5 iterations on multiple prompts; we will add explicit reporting of iteration counts, averaging across LLM instances as statistical control, and note that inter-rater reliability does not apply to the automated judge. No human data or physical testing is present, which we will explicitly list as a limitation rather than claiming direct suitability. revision: partial
-
Referee: [Evaluation] The manuscript provides no ablation or baseline comparison (e.g., single-pass generation versus the iterative loop, or different LLM pairings) that would isolate the contribution of the Writer-Editor mechanism from generic LLM prompting effects.
Authors: The reported results already include a direct before/after comparison showing consistent quality score increases from the initial generation through successive editor feedback loops. This isolates the effect of the iterative mechanism relative to single-pass output. We did not test alternative LLM pairings or further ablations owing to resource limits, but the core demonstration remains the measurable improvement from the closed-loop process itself. revision: no
- Absence of any human-subject evaluation with children or physical board-game testing, which cannot be addressed without new experiments outside the current simulation study.
Circularity Check
No circularity: empirical simulation result stands independent of inputs
full rationale
The paper advances a multi-agent Writer-Editor framework and supports its central claim solely via an empirical simulation study in which LLMs play both roles and quality is assessed across refinement loops. No equations, fitted parameters, derivations, or self-citations appear in the load-bearing steps. The reported quality improvement is presented as an observed outcome of the simulation rather than a quantity that reduces to its own definition or to a prior self-citation chain. The absence of any mathematical or definitional reduction means the result is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Discrete-time methods for the analysis of event histories,
P. D. Allison, “Discrete-time methods for the analysis of event histories,” inSociological Methods and Research, S. Leinhardt, Ed. Jossey-Bass, 1982, pp. 61–98
1982
-
[2]
Story designer: towards a mixed- initiative tool to create narrative structures,
A. Alvarez, J. Font, and J. Togelius, “Story designer: towards a mixed- initiative tool to create narrative structures,” inProceedings of the 17th International Conference on the Foundations of Digital Games, 2022, pp. 1–9
2022
-
[3]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Y . Bai, A. Jones, K. Ndousse, A. Askell, A. Chen, N. DasSarma, D. Drain, S. Fort, D. Ganguli, T. Henighanet al., “Training a helpful and harmless assistant with reinforcement learning from human feedback,”arXiv preprint arXiv:2204.05862, 2022. [Online]. Available: https://arxiv.org/abs/2204.05862
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Constitutional ai: Harmlessness from ai feedback,
Y . Bai, S. Kadavath, S. Kundu, A. Askell, J. Kernion, A. Jones, A. Chen, A. Goldie, A. Mirhoseini, C. McKinnon, and et al., “Constitutional ai: Harmlessness from ai feedback,”Preprint, arXiv, no. arXiv:1909.08073, 2022
-
[5]
Deep reinforcement learning from human preferences,
P. F. Christiano, J. Leike, T. Brown, M. Martic, S. Legg, and D. Amodei, “Deep reinforcement learning from human preferences,” no. 30, 2017
2017
-
[6]
Pace: Improving prompt with actor-critic editing for large language model,
Y . Dong, K. Luo, X. Jiang, Z. Jin, and G. L. Key, “Pace: Improving prompt with actor-critic editing for large language model,”Preprint, arXiv, no. 2308.10088v2, 2024
-
[7]
A. Dubey, A. Jauhri, A. Pandey, A. Kadianet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024. [Online]. Available: https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Gemma 2: Improving Open Language Models at a Practical Size
G. T. et al., “Gemma 2: Improving open language models at a practical size,” 2024. [Online]. Available: https://arxiv.org/abs/2408.00118
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Large language models and games: A survey and roadmap,
R. Gallotta, G. Todd, M. Zammit1, S. Earle, A. Liapis, J. Togelius, and G. N. Yannakakis, “Large language models and games: A survey and roadmap,”Preprint, arXiv, no. 2402.18659v4, 2023
-
[10]
Automatic story generation: State of the art and recent trends,
B. D. Herrera-Gonz ´alez, A. Gelbukh, and H. Calvo, “Automatic story generation: State of the art and recent trends,” inAdvances in Com- putational Intelligence, L. Mart ´ınez-Villase˜nor, O. Herrera-Alc ´antara, H. Ponce, and F. A. Castro-Espinoza, Eds. Cham: Springer International Publishing, 2020, pp. 81–91
2020
-
[11]
Self-evolved reward learning for llms,
C. Huang, Z. Fan, L. Wang, F. Yang, P. Zhao, Z. Lin, Q. Lin, D. Zhang, S. Rajmohan, and Q. Zhang, “Self-evolved reward learning for llms,” Preprint, arXiv, no. 2308.00418v1, 2024
-
[13]
Large Language Models Can Self-Improve
[Online]. Available: https://arxiv.org/abs/2210.11610
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
L. Huang, W. Yu, W. Ma, W. Zhong, Z. Feng, H. Wang, Q. Chen, W. Peng, X. Feng, and B. Qin, “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions,” Preprint, arXiv, no. 2311.05232, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. de las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier et al., “Mistral 7b,”arXiv preprint arXiv:2310.06825, 2023. [Online]. Available: https://arxiv.org/abs/2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
An evaluation of state-of-the-art large language models for sarcasm detection,
J.Zhou, “An evaluation of state-of-the-art large language models for sarcasm detection,”Preprint, arXiv, no. 2402.03706, 2023
-
[17]
Openassistant conversations: Democratizing large language model alignment,
A. K ¨opf, Y . Kilcher, D. von R ¨utte, S. Anagnostidis, Z. R. Tam, K. Stevens, A. Barhoum, D. Nguyen, O. Stanley, R. Nagyfiet al., “Openassistant conversations: Democratizing large language model alignment,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 36, 2024
2024
-
[18]
Training Language Models to Self-Correct via Reinforcement Learning
A. Kumar, V . Zhuang, R. Agarwal, Y . Su, J. D. Co-Reyes, A. Singh, K. Baumli, S. Iqbal, C. Bishop, R. Roelofset al., “Training language models to self-correct via reinforcement learning,” arXiv preprint arXiv:2409.12917, 2024. [Online]. Available: https: //arxiv.org/abs/2409.12917
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
RLAIF vs. RLHF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
H. Lee, S. Phatale, H. Mansoor, T. Mesnard, J. Ferret, K. Lu, C. Bishop, E. Hall, V . Carbune, A. Rastogiet al., “RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback,”arXiv preprint arXiv:2309.00267, 2023. [Online]. Available: https://arxiv.org/abs/2309.00267
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Evaluating creativity in computational co-creative systems,
M. L. Maher, K. Grace, P. Karimi, and N. Davis, “Evaluating creativity in computational co-creative systems,” inProceedings of the Ninth International Conference on Computational Creativity, ICCC 2018, Salamanca, Spain, June 25-29, 2018, F. Pachet, A. Jordanous, and C. Le ´on, Eds. Association for Computational Creativity (ACC), 2018, pp. 104–111. [Online...
2018
-
[21]
The strengthened ped- agogical curriculum, framework and content,
Ministry of Children and Education, Denmark, “The strengthened ped- agogical curriculum, framework and content,” 2020
2020
-
[22]
Ollama, “Ollama,” https://ollama.com/, 2024, [Online; Accessed: 17- Mar-2026]
2024
-
[23]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray et al., “Training language models to follow instructions with human feedback,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 35, 2022, pp. 27 730–27 744. [Online]. Available: https://proceedings.neurips.cc/paper files/paper/ 2022...
2022
-
[24]
Language model self-improvement by reinforcement learning contemplation,
J.-C. Pang, P. Wang, K. Li, X.-H. Chen, J. Xu, Z. Zhang, and Y . Yu, “Language model self-improvement by reinforcement learning contemplation,”arXiv preprint arXiv:2305.14483, 2023. [Online]. Available: https://arxiv.org/abs/2305.14483
-
[25]
B. Peng, C. Li, P. He, M. Galley, and J. Gao, “Instruction tuning with gpt-4,”arXiv preprint arXiv:2304.03277, 2023. [Online]. Available: https://arxiv.org/abs/2304.03277
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Regression analysis of grouped survival data with applications to breast cancer data,
R. L. Prentice and L. A. Gloeckler, “Regression analysis of grouped survival data with applications to breast cancer data,”Biometrics, vol. 34, pp. 57–67, 1978
1978
-
[28]
Proximal Policy Optimization Algorithms
[Online]. Available: https://arxiv.org/abs/1707.06347
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Shaker, J
N. Shaker, J. Togelius, and M. J. Nelson,Procedural Content Gen- eration in Games, 1st ed., ser. Computational Synthesis and Creative Systems. Cham, Switzerland: Springer Cham, 2016, published: 18 October 2016. Hardcover ISBN: 978-3-319-42714-0, Softcover ISBN: 978-3-319-82643-1
2016
-
[30]
Learning to summarize with human feedback,
N. Stiennon, L. Ouyang, J. Wu, D. Ziegler, R. Lowe, C. V oss, A. Radford, D. Amodei, and P. F. Christiano, “Learning to summarize with human feedback,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 33, 2020, pp. 3008–
2020
-
[31]
Available: https://proceedings.neurips.cc/paper/2020/ file/1f89885d1d9800737a5d9f0ad6297f22-Paper.pdf
[Online]. Available: https://proceedings.neurips.cc/paper/2020/ file/1f89885d1d9800737a5d9f0ad6297f22-Paper.pdf
2020
-
[32]
MarioGPT: Open-Ended Text2Level Generation through Large Language Models,
S. Sudhakaran, M. Gonz ´alez-Duque, M. Freiberger, C. Glanois, E. Na- jarro, and S. Risi, “MarioGPT: Open-Ended Text2Level Generation through Large Language Models,” inProceedings of the 37th Confer- ence on Neural Information Processing Systems (NeurIPS 2023), 2023, presented at NeurIPS 2023
2023
-
[33]
Principle-driven self-alignment of language models from scratch with minimal human supervision,
Z. Sun, Y . Shen, Q. Zhou, H. Zhang, Z. Chen, D. Cox, Y . Yang, and C. Gan, “Principle-driven self-alignment of language models from scratch with minimal human supervision,” inAdvances in Neural Infor- mation Processing Systems (NeurIPS), vol. 36, 2024
2024
-
[34]
Evaluating quality of gaming narratives co- created with ai,
A. Valdivia and P. Burelli, “Evaluating quality of gaming narratives co- created with ai,” in2025 IEEE Conference on Games (CoG), 2025, pp. 1–4
2025
-
[35]
Self-preference bias in LLM-as- a-judge,
K. Wataoka, T. Takahashi, and R. Ri, “Self-preference bias in LLM-as- a-judge,” 2025. [Online]. Available: https://openreview.net/forum?id= Ns8zGZ0lmM
2025
-
[36]
WizardLM: Empowering large pre-trained language models to follow complex instructions
C. Xu, Q. Sun, K. Zheng, X. Geng, P. Zhao, J. Feng, C. Tao, and D. Jiang, “WizardLM: Empowering Large Language Models to Follow Complex Instructions,”arXiv preprint arXiv:2304.12244, 2023. [Online]. Available: https://arxiv.org/abs/2304.12244
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Dynamic difficulty adjustment for maximized engagement in digital games,
Y . Xueet al., “Dynamic difficulty adjustment for maximized engagement in digital games,” inWWW ’17 Companion: Proceedings of the 26th International Conference on World Wide Web Companion, 2017, pp. 465–467. [Online]. Available: https://doi.org/10.1145/3041021.3054170
-
[38]
What makes a good story and how can we measure it? a comprehensive survey of story evaluation,
D. Yang and Q. Jin, “What makes a good story and how can we measure it? a comprehensive survey of story evaluation,”Preprint, arXiv, no. 2408.14622, 2024
-
[39]
Mixed-initiative co- creativity,
G. N. Yannakakis, A. Liapis, and C. Alexopoulos, “Mixed-initiative co- creativity,” inProceedings of the 9th International Conference on the Foundations of Digital Games, Fort Lauderdale, 2014, pp. 1–8
2014
-
[40]
Fine-Tuning Language Models from Human Preferences
D. M. Ziegler, N. Stiennon, J. Wu, T. Brown, A. Radford, D. Amodei, P. F. Christiano, and G. Irving, “Fine-tuning language models from human preferences,”Preprint, arXiv, no. arXiv:1909.08593, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.