Evidential Reasoning Advances Interpretable Real-World Disease Screening
Pith reviewed 2026-06-30 20:51 UTC · model grok-4.3
The pith
EviScreen retrieves region-level evidence from historical cases in dual knowledge banks to raise specificity at clinical recall while supplying built-in interpretability via contrastive abnormality maps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
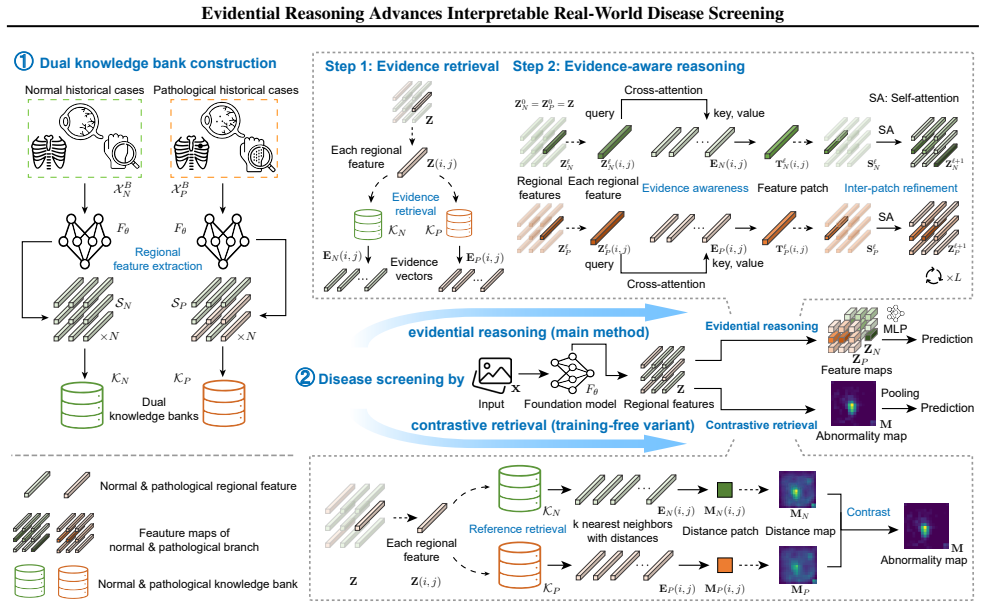
EviScreen is an evidential reasoning framework that leverages region-level evidence retrieved from dual knowledge banks of historical cases, applies an evidence-aware reasoning module that combines current and retrieved information for predictions, and derives abnormality maps through contrastive retrieval to deliver retrospection and localization interpretability, achieving higher specificity at clinical-level recall on established real-world screening benchmarks.
What carries the argument
Dual knowledge banks with contrastive retrieval that supply region-level historical evidence and generate abnormality maps for direct interpretability.
If this is right
- Screening models reach higher specificity without dropping below clinical recall thresholds on real-world data.
- Interpretability arises directly from retrieved regional evidence and contrastive abnormality maps rather than post-hoc saliency.
- Predictions explicitly incorporate both current image features and supporting evidence from past cases.
- Localization of abnormalities improves through the contrastive retrieval step without separate explanation modules.
Where Pith is reading between the lines
- The retrieval approach could be tested on longitudinal patient records to see whether evidence from prior visits further reduces false positives.
- If the retrieved regions align with how radiologists reason, the method might support hybrid human-AI review processes in screening programs.
- Similar dual-bank structures might apply to other diagnostic tasks where historical case comparison is already part of clinical practice.
Load-bearing premise
The dual knowledge banks and contrastive retrieval mechanism actually supply causally relevant evidence rather than spurious correlations that happen to improve metrics on the chosen benchmarks.
What would settle it
Performance gains disappear on the same benchmarks when the knowledge banks contain randomly selected or mismatched historical cases instead of curated ones.
Figures








read the original abstract
Disease screening is critical for early detection and timely intervention in clinical practice. However, most current screening models for medical images suffer from limited interpretability and suboptimal performance. They often lack effective mechanisms to reference historical cases or provide transparent reasoning pathways. To address these challenges, we introduce EviScreen, an evidential reasoning framework for disease screening that leverages region-level evidence from historical cases. The proposed EviScreen offers retrospection interpretability through regional evidence retrieved from dual knowledge banks. Using this evidential mechanism, the subsequent evidence-aware reasoning module makes predictions using both the current case and evidence from historical cases, thereby enhancing disease screening performance. Furthermore, rather than relying on post-hoc saliency maps, EviScreen enhances localization interpretability by leveraging abnormality maps derived from contrastive retrieval. Our method achieves superior performance on our carefully established benchmarks for real-world disease screening, yielding notably higher specificity at clinical-level recall. Code is publicly available at https://github.com/DopamineLcy/EviScreen.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces EviScreen, an evidential reasoning framework for disease screening from medical images. It retrieves region-level evidence from historical cases stored in dual knowledge banks, employs contrastive retrieval to generate abnormality maps for localization interpretability, and uses an evidence-aware reasoning module that combines the current case with retrieved evidence to make predictions. The central claim is that this yields superior performance, specifically higher specificity at clinical-level recall, on custom benchmarks for real-world disease screening, while providing retrospection interpretability beyond post-hoc saliency maps. Code is released publicly.
Significance. If the evidential mechanism supplies causally relevant evidence without leakage or benchmark-specific artifacts, the framework could advance interpretable medical imaging by grounding predictions in historical cases rather than opaque feature attributions. Public code availability is a clear strength supporting reproducibility. However, the significance cannot be fully assessed given the absence of methods details, data splits, ablation studies, or statistical validation in the provided manuscript text.
major comments (1)
- [Abstract] Abstract: The claim that the method yields 'notably higher specificity at clinical-level recall' on 'carefully established benchmarks' is load-bearing for the central performance contribution, yet no information is supplied on benchmark construction, case selection criteria, or controls for leakage between knowledge banks and test cases; this creates moderate risk that reported gains are tied to dataset curation rather than the evidential reasoning mechanism.
minor comments (1)
- [Abstract] Abstract: Terms such as 'dual knowledge banks' and 'contrastive retrieval' are introduced without brief definitions or references, reducing immediate clarity for readers outside the immediate subfield.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to address concerns about the abstract's performance claims. We respond point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the method yields 'notably higher specificity at clinical-level recall' on 'carefully established benchmarks' is load-bearing for the central performance contribution, yet no information is supplied on benchmark construction, case selection criteria, or controls for leakage between knowledge banks and test cases; this creates moderate risk that reported gains are tied to dataset curation rather than the evidential reasoning mechanism.
Authors: We agree the abstract is concise and omits these details. The full manuscript (Section 4.1) describes benchmark construction from multi-center real-world screening data, case selection criteria based on clinical protocols, and leakage controls via temporal and patient-level disjoint splits between knowledge banks and test cases. Ablations (Section 5.3) and statistical tests isolate the evidential mechanism's contribution. We will revise the abstract to briefly reference these elements for clarity. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces an empirical ML framework (EviScreen) whose central claims consist of performance improvements on author-established benchmarks and interpretability via retrieved evidence. No equations, derivations, or first-principles results are referenced in the abstract or reader summary. Consequently there is no derivation chain that could reduce to self-definition, fitted inputs renamed as predictions, or self-citation load-bearing steps. The work is self-contained as an empirical contribution; any concerns about benchmark construction fall under external validity rather than internal circularity of a derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chattopadhay, A., Sarkar, A., Howlader, P., and Balasubra- manian, V . N. Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks. In 2018 IEEE winter conference on applications of computer vision (WACV), pp. 839–847. IEEE,
2018
-
[2]
MIMIC-CXR-JPG, a large publicly available database of labeled chest radiographs
Johnson, A. E., Pollard, T. J., Greenbaum, N. R., Lun- gren, M. P., Deng, C.-y., Peng, Y ., Lu, Z., Mark, R. G., Berkowitz, S. J., and Horng, S. Mimic-cxr-jpg, a large publicly available database of labeled chest radiographs. arXiv preprint arXiv:1901.07042, 2019a. Johnson, J., Douze, M., and J´egou, H. Billion-scale similar- ity search with gpus.IEEE Tra...
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[3]
BenchReAD: A systematic benchmark for retinal anomaly detection
Lian, C., Zhou, H.-Y ., Hu, Z., and Qin, J. BenchReAD: A systematic benchmark for retinal anomaly detection . InMedical Image Computing and Computer Assisted Intervention – MICCAI 2025, volume LNCS 15961, pp. 35 –
2025
-
[4]
Decoupled Weight Decay Regularization
Loshchilov, I. and Hutter, F. Decoupled weight decay regu- larization.arXiv preprint arXiv:1711.05101,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
doi: 10.1371/journal.pdig.0000454. URL https://doi. org/10.1371/journal.pdig.0000454. Oquab, M., Darcet, T., Moutakanni, T., V o, H., Szafraniec, M., Khalidov, V ., Fernandez, P., Haziza, D., Massa, F., El- Nouby, A., et al. Dinov2: Learning robust visual features without supervision.Transactions on Machine Learning Research Journal, pp. 1–31,
-
[6]
doi: https://doi.org/10.1016/j.image.2024.117151
ISSN 0923-5965. doi: https://doi.org/10.1016/j.image.2024.117151. URL https://www.sciencedirect.com/ science/article/pii/S0923596524000523. Yan, S., Yu, Z., Primiero, C., Vico-Alonso, C., Wang, Z., Yang, L., Tschandl, P., Hu, M., Ju, L., Tan, G., et al. A multimodal vision foundation model for clinical derma- tology.Nature Medicine, pp. 1–12,
-
[7]
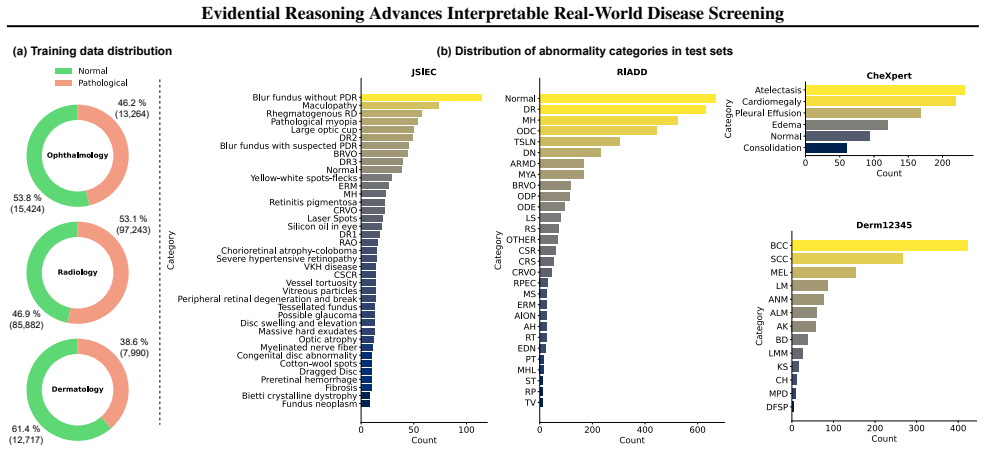
and BRSET (Nakayama et al., 2024). We categorize samples based on abnormality presence: cases without detected abnormalities are classified as normal, while those exhibiting any abnormality are classified as pathological. To simulate real-world disease screening scenarios, we employ two external datasets: JSIEC (Cen et al.,
2024
-
[8]
benign” are treated as “normal
evaluation set as our test dataset, chosen for its board-certified radiologist annotations ensuring label reliability. Following the original CheXpert recommendations, our evaluation focuses on five primary pathological categories: atelectasis, cardiomegaly, consolidation, edema, and pleural effusion. A.3. Dermatology The dermatology benchmark incorporate...
2018
-
[9]
as our test set for evaluation. B. More Comprehensive Implementation Details Our code is implemented using PyTorch 2.4.1 (Paszke et al., 2019). All experiments are carried out with Nvidia GeForce RTX 3090 GPUs. We employ state-of-the-art foundation models for each modality: RETFound-Dinov2 (Zhou et al.,
2019
-
[10]
The foundation models chosen as regional feature extractors are based on ViT-L (Dosovitskiy et al., 2020; Vaswani et al., 2017), which consists of 24 transformer blocks
for dermoscopic images. The foundation models chosen as regional feature extractors are based on ViT-L (Dosovitskiy et al., 2020; Vaswani et al., 2017), which consists of 24 transformer blocks. Features in the layers of 7 and 17 are selected and aggregated by adaptive average pooling to generate desired regional features. RETFound-Dinov2 (Zhou et al.,
2020
-
[11]
The dimension of evidence vectors is 1,024. Following previous related work (Roth et al., 2022; Lian et al., 2025), no data augmentation is applied to avoid including new abnormality or losing original abnormality in the images. During the construction and usage of dual knowledge banks, Faiss 1.8.0 (Johnson et al., 2019b) is adopted for the nearest neighb...
2022
-
[12]
is adopted as the default optimizer, with a weight decay of 0.05, β1 of 0.9, and β2 of 0.95. We employ a “warm-up” strategy by linearly increasing the learning rate (selected based on validation performance from 1.25e-4, 2e-4, and 2.5e-4) to the desired value and then decreasing it using a cosine decay schedule. Batch size is 32 for CFP and dermoscopic im...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.