Dual-Agent Framework for Cross-Model Verified Translation of Natural-Language Protocols into Robotic Laboratory Platform
Pith reviewed 2026-06-26 17:18 UTC · model grok-4.3
The pith
A parser agent plus a heterogeneous LLM validator converts natural-language microplate protocols into executable robotic commands via a self-correction loop.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The dual-agent architecture with rule-based deterministic mapping and cross-model LLM validation produces accurate, executable control sequences for microplate experiments directly from natural-language input, enabling autonomous execution on a robotic laboratory platform without manual intervention.
What carries the argument
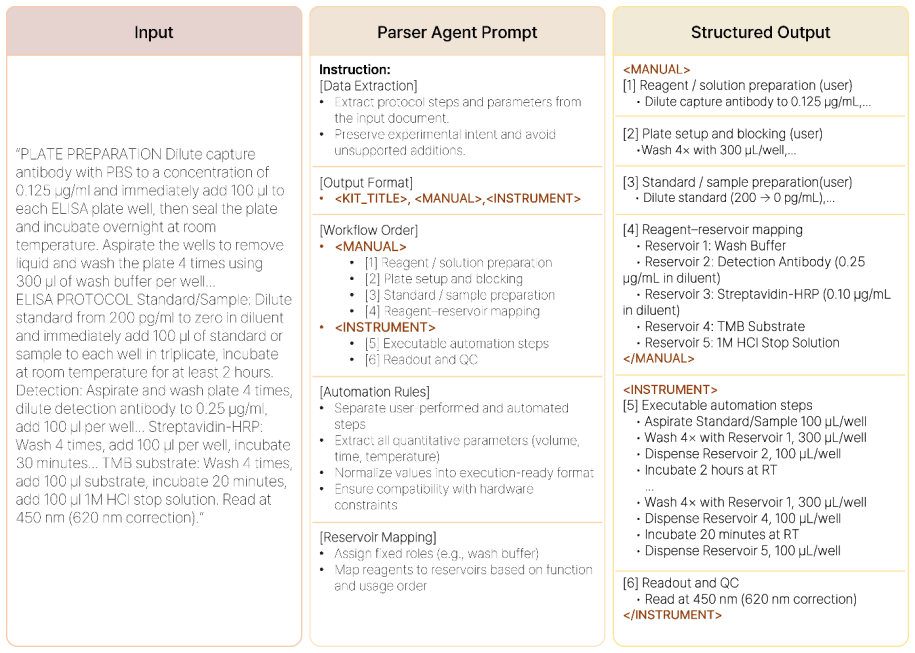
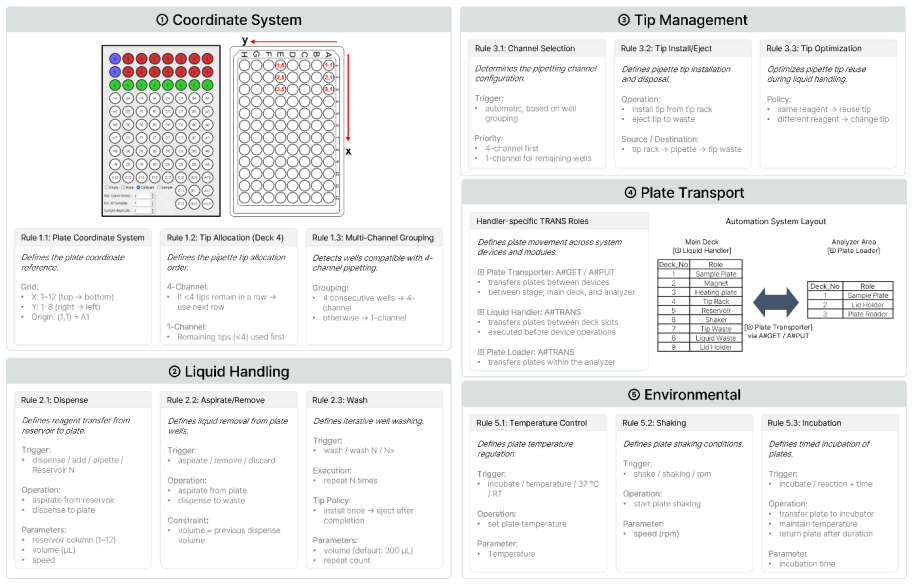
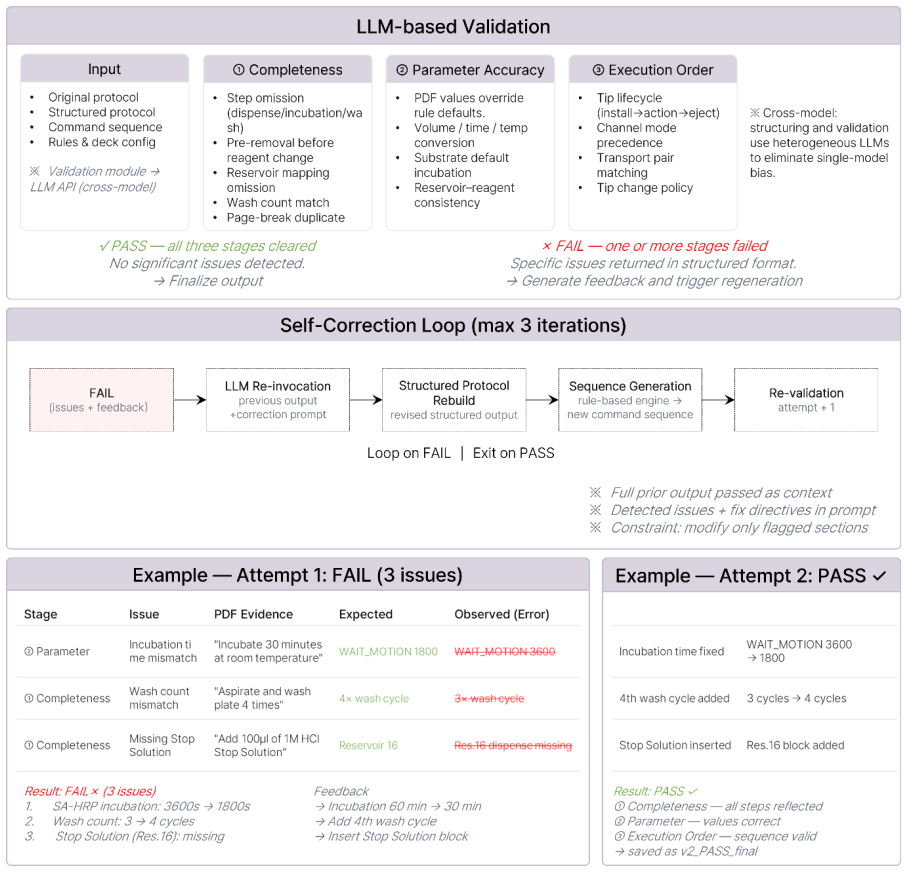
Parser Agent that formalizes natural-language protocols into structured representations, combined with a rule-based mapping engine that embeds robotic platform constraints and a heterogeneous LLM Validation Agent that triggers a structured self-correction loop.
If this is right
- Translation accuracy improves when the validator model differs from the parser model.
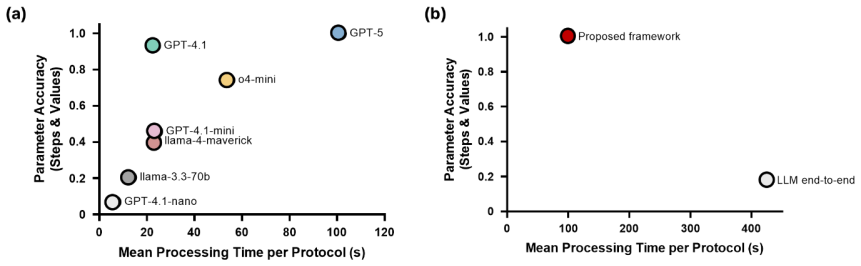
- Rule-based mapping outperforms direct LLM end-to-end mapping in both accuracy and latency for microplate well assignments.
- The framework supports autonomous execution of replicate placement, parallel dispensing, and sample-reagent combinations on physical hardware.
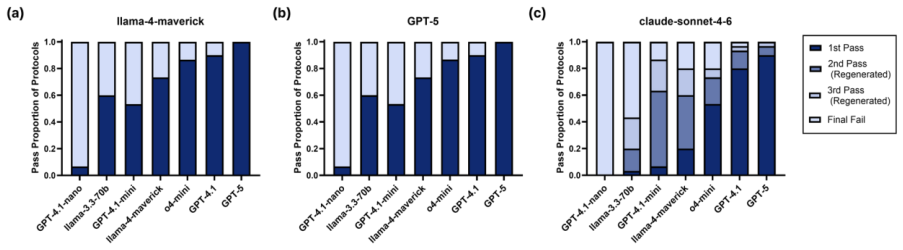
- Cross-model verification raises pass rates on randomly selected ELISA protocols.
Where Pith is reading between the lines
- The same structure could be applied to other liquid-handling platforms if their constraint rules are encoded in the mapping engine.
- If the validation loop is made fully autonomous, the system could iterate until a passing protocol is reached without human review.
- Extending the parser to handle conditional or branching protocols would require only additions to the structured representation.
Load-bearing premise
The rule-based mapping engine can always translate the structured protocol into device commands without losing information or requiring manual fixes.
What would settle it
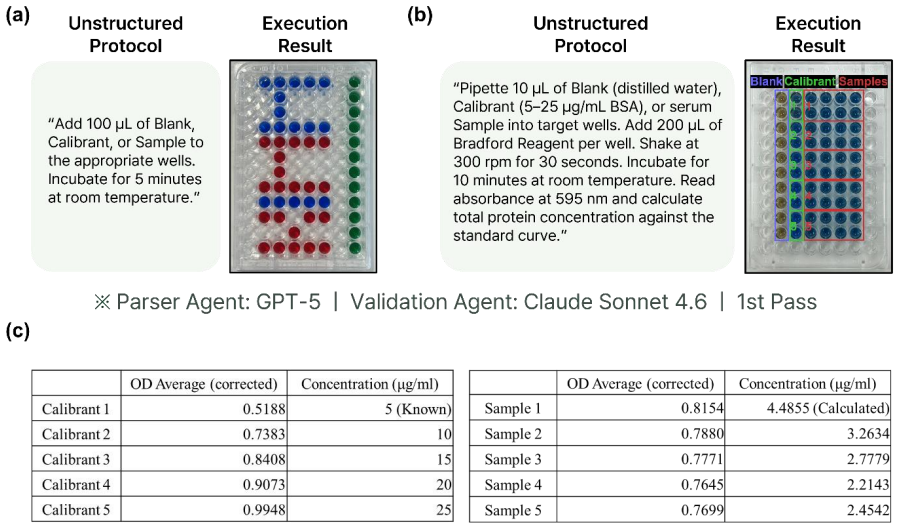
Run the Bradford assay demonstration again after deliberately introducing an ambiguous or incomplete natural-language protocol and observe whether the validation loop produces a correct executable sequence or fails with an uncorrectable error.
Figures


read the original abstract
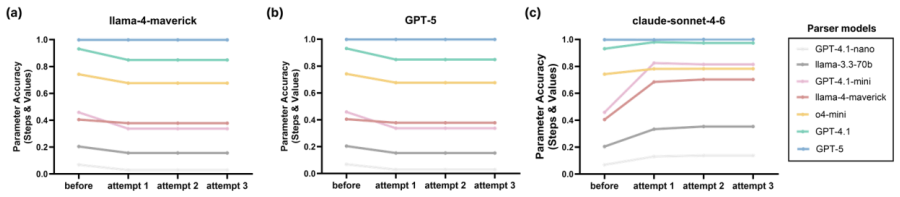
Biological experiment protocols are written in natural language, whereas automation systems rely on predefined control commands, creating a semantic gap that limits autonomous execution. Microplate-based automatic experiments are particularly challenging due to the need to simultaneously control well mapping, sample-reagent combinations, replicate placement, and parallel dispensing. This study proposes an agent-based protocol translation framework that converts natural-language microplate-based protocols into executable control commands for a robotic laboratory platform. A Parser Agent formalizes the natural-language protocol into a structured representation, and a rule-based mapping engine deterministically incorporates the operational constraints of the robotic laboratory platform to generate device-level control commands. A heterogeneous LLM Validation Agent verifies completeness, parameter accuracy, and execution order, and triggers a self-correction loop with structured feedback when errors are detected. A sweep involving 7 Parsers and 3 Validators on randomly selected ELISA protocols evaluates how model scale and Validator type affect translation accuracy and pass rates under cross-model verification. The accuracy-latency trade-off is further verified by comparing the rule-based mapping of the proposed framework with LLM end-to-end direct mapping. Finally, Bradford assay-based protein quantification using a microplate was demonstrated on a robotic laboratory platform, validating end-to-end autonomous execution from natural-language protocols to real-world experiments. The proposed framework provides a flexible approach to narrowing the semantic gap between natural-language protocols and microplate-based self-driving laboratories.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a dual-agent framework for translating natural-language microplate-based biological protocols into executable control commands for robotic laboratory platforms. It consists of a Parser Agent that formalizes the input into a structured representation, a rule-based mapping engine that converts this into device-level commands while incorporating platform constraints such as well mapping and parallel dispensing, and a heterogeneous LLM Validation Agent that checks completeness, parameter accuracy, and execution order before triggering a self-correction loop. The work reports a sweep across 7 parsers and 3 validators on randomly selected ELISA protocols to evaluate effects on translation accuracy and pass rates under cross-model verification, compares the rule-based approach to LLM end-to-end mapping on accuracy-latency trade-offs, and demonstrates end-to-end execution via a Bradford assay-based protein quantification on a real robotic microplate platform.
Significance. If the results hold, the framework could meaningfully narrow the semantic gap between natural-language protocols and automated lab systems, supporting more autonomous self-driving laboratories. The real-world Bradford assay demonstration provides tangible evidence of end-to-end execution from NL input to physical experiment, which is a clear strength. The cross-model verification sweep and explicit comparison to direct LLM mapping also add value by addressing model-scale effects and trade-offs. These elements distinguish the work from purely simulation-based protocol translation studies.
major comments (2)
- [Abstract] Abstract (framework description paragraph): The central claim that the rule-based mapping engine 'deterministically incorporates the operational constraints of the robotic laboratory platform to generate device-level control commands' without information loss or manual overrides is load-bearing for the entire pipeline, yet no rule specification, pseudocode, edge-case handling (e.g., replicate placement or parallel dispensing conflicts), or systematic validation of this determinism is provided. This leaves open whether the Validation Agent can detect mapping failures that occur before its input is formed.
- [Evaluation] Evaluation section (sweep description): The abstract states that a sweep across 7 parsers and 3 validators was performed and that accuracy and pass rates were measured, but supplies no quantitative accuracy numbers, error analysis, baseline comparisons, or statistical significance tests. Without these data it is impossible to assess whether the reported effects of model scale and validator type actually support the framework's superiority claims.
minor comments (2)
- [Abstract] The abstract would be strengthened by including at least one key quantitative result (e.g., highest pass rate or accuracy delta versus direct LLM mapping) to allow readers to gauge the magnitude of the reported improvements.
- [Methods] Notation for the structured representation produced by the Parser Agent and the exact feedback format used in the self-correction loop should be defined explicitly in the methods section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for clarification and strengthening of the presentation. We address each major comment point-by-point below, indicating where revisions will be made to the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (framework description paragraph): The central claim that the rule-based mapping engine 'deterministically incorporates the operational constraints of the robotic laboratory platform to generate device-level control commands' without information loss or manual overrides is load-bearing for the entire pipeline, yet no rule specification, pseudocode, edge-case handling (e.g., replicate placement or parallel dispensing conflicts), or systematic validation of this determinism is provided. This leaves open whether the Validation Agent can detect mapping failures that occur before its input is formed.
Authors: We agree that the current manuscript provides insufficient detail on the rule-based mapping engine to fully substantiate the determinism claim. In the revised version, we will add a new subsection in the Methods section with explicit rule specifications, pseudocode for the mapping process (including well mapping, replicate placement, and parallel dispensing logic), and discussion of edge-case handling. We will also clarify the interface between the mapping engine and the Validation Agent, noting that the latter operates on the output of the mapping step and can flag inconsistencies even if the mapping itself is rule-driven. revision: yes
-
Referee: [Evaluation] Evaluation section (sweep description): The abstract states that a sweep across 7 parsers and 3 validators was performed and that accuracy and pass rates were measured, but supplies no quantitative accuracy numbers, error analysis, baseline comparisons, or statistical significance tests. Without these data it is impossible to assess whether the reported effects of model scale and validator type actually support the framework's superiority claims.
Authors: The evaluation section reports results from the sweep on ELISA protocols and the accuracy-latency comparison to direct LLM mapping, but we acknowledge that the presentation lacks sufficient quantitative detail, error breakdowns, explicit baselines, and statistical tests to allow full assessment. In the revision, we will expand this section with tables containing the specific accuracy and pass-rate numbers for each parser-validator combination, an error analysis categorized by failure type, direct numerical comparisons to the LLM end-to-end baseline, and appropriate statistical significance tests (e.g., paired t-tests or McNemar's test) with p-values. revision: yes
Circularity Check
No circularity; framework claims rest on independent components and empirical evaluation
full rationale
The paper presents a descriptive framework using LLM agents and an asserted rule-based mapping engine with no equations, fitted parameters, or mathematical derivations. Claims about deterministic lossless mapping are stated as design properties of the engine rather than derived from the results being measured. No self-citations are load-bearing for the core assertions, and the evaluation (accuracy sweeps and Bradford assay demo) is presented as external testing rather than reducing to the inputs by construction. This matches the default case of a self-contained non-circular description.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models can detect and correct errors in structured protocol translations when given appropriate feedback prompts
Reference graph
Works this paper leans on
-
[1]
Ahn, M., Brohan, A., Brown, N., Chebotar, Y ., Cortes, O., David, B., Finn, C., Fu, C., Gopalakrishnan, K., Hausman, K., et al. (2022). Do as I can, not as I say: Grounding language in robotic affordances. In Proceedings of the 6th Conference on Robot Learning (CoRL). arXiv preprint arXiv:2204.01691. Ananthanarayanan, V ., & Thies, W. (2010). Biocoder: A ...
Pith/arXiv arXiv 2022
-
[2]
AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors
https://doi.org/10.1186/1754-1611-4-13 Bates, M., Berliner, A. J., Lachoff, J., Jaschke, P. R., & Groban, E. S. (2017). Wet lab accelerator: A web -based application democratizing laboratory automation for synthetic biology. ACS Synthetic Biology, 6(1), 167 –171. https://doi.org/10.1021/acssynbio.6b00108 Boiko, D. A., MacKnight, R., Kline, B., & Gomes, G....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1186/1754-1611-4-13 2017
-
[3]
LAB-Bench: Measuring Capabilities of Language Models for Biology Research
https://doi.org/10.1038/s41467-020-20383-x Laurent, J. M., Janizek, J. D., Ruzo, M., Hinks, M. M., Hammerling, M. J., Narayanan, S., Ponnapati, M., White, A. D., & Rodriques, S. G. (2024). LAB -Bench: Measuring capabilities of language models for biology research. arXiv preprint arXiv:2407.10362. Liang, J., Huang, W., Xia, F., Xu, P., Hausman, K., Ichter,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41467-020-20383-x 2024
-
[4]
https://doi.org/10.1038/s44387-025-00057-z Qian, C., Liu, W., Liu, H., Chen, N., Dang, Y ., Li, J., Yang, C., Chen, W., Su, Y ., Cong, X., Xu, J., Li, D., Liu, Z., & Sun, M. (2024). ChatDev: Communicative agents for software development. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V ol. 1, pp. 15174–15186). ...
-
[5]
https://doi.org/10.1038/s41467-025-61209-y Soldatova, L. N., Nadis, D., King, R. D., Basu, P. S., Haddi, E., Baumlé, V ., Saunders, N. J., Marwan, W., & Rudkin, B. B. (2014). EXACT2: The semantics of biomedical protocols. BMC Bioinformatics, 15(Suppl 14), S5. https://doi.org/10.1186/1471-2105-15-S14-S5 Song, T., Luo, M., Zhang, X., Chen, L., Huang, Y ., C...
-
[6]
Large language models used as Parser and Validator agents. Seven models were evaluated as Parser Agents (GPT-5, GPT-4.1, o4-mini, GPT-4.1-mini, GPT-4.1-nano, Llama-4-Maverick, Llama-3.3-70B) and three as Validator Agents (Claude Sonnet 4.6 (default), GPT -5, Llama-4-Maverick). All model versions and release dates are as of 2026-05-22. Model Role in study ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.