Hide to Guide: Learning via Semantic Masking
Pith reviewed 2026-06-30 12:13 UTC · model grok-4.3
The pith
Masking reward-relevant semantic spans in expert traces prevents reward hacking in RLVR.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
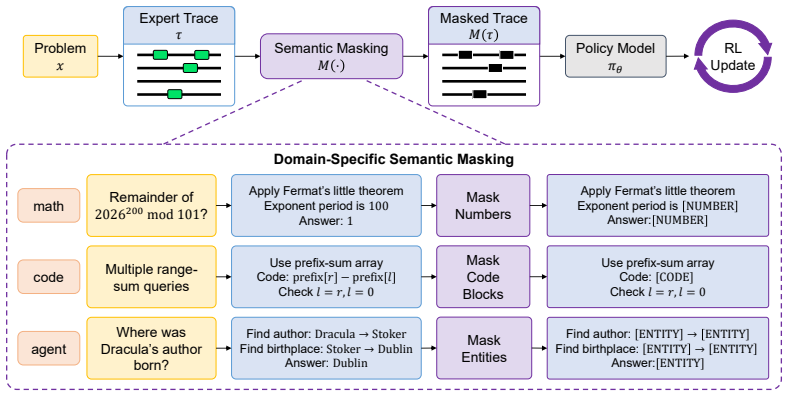
SMEPO masks reward-relevant semantic spans along the critical path to the verifier target while preserving the expert's decomposition, plan, and procedural structure, turning hard problems into a fill-in-the-blank process where the policy follows the route but reconstructs missing content itself.
What carries the argument
Semantic Masked Expert Policy Optimization (SMEPO), a fine-grained semantic masking strategy that hides reward-relevant content in expert traces for guided RLVR.
If this is right
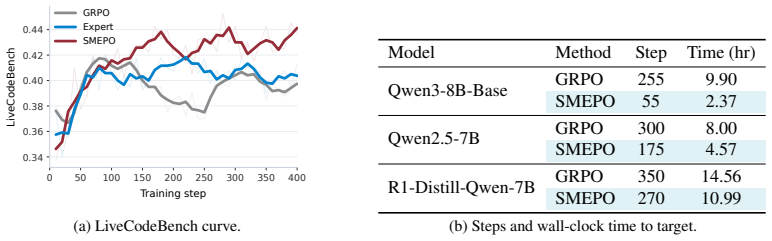
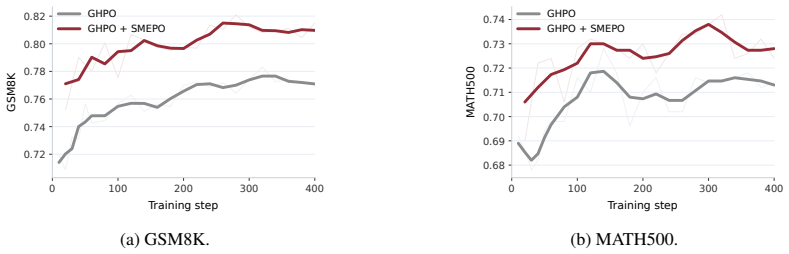
- Accuracy improves by up to 3.2 points over GRPO on diverse domains like math, code, and agentic search.
- Training time reduces by up to 4.2x compared to baselines.
- Requires no changes to the reward function or RL objective.
- The policy learns underlying reasoning and agentic behavior rather than copying traces.
Where Pith is reading between the lines
- Similar masking could be applied to other forms of guidance in machine learning beyond RL.
- Testing on a wider range of tasks might reveal if the method scales to more complex agent behaviors.
- The approach might reduce the need for large amounts of expert data by making each trace more effective for learning.
Load-bearing premise
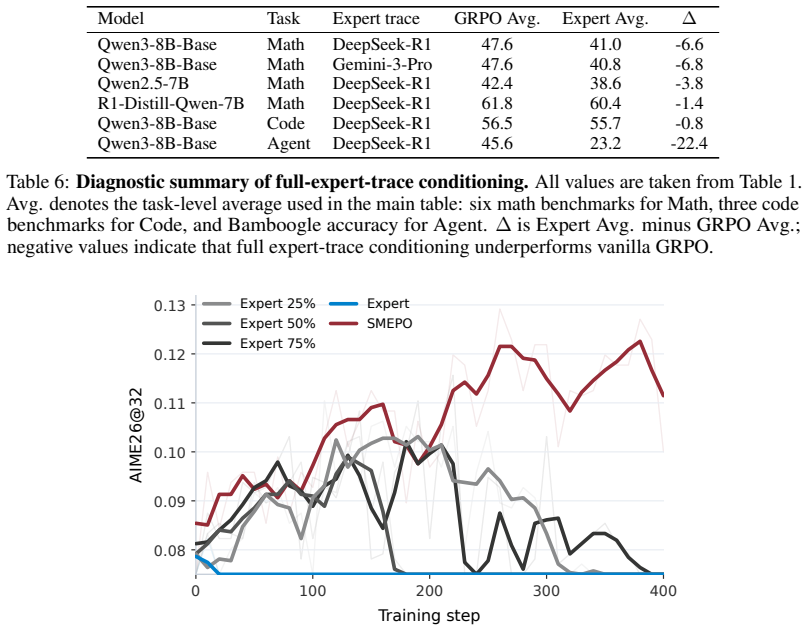
Selectively masking reward-relevant semantic spans still allows the policy to learn the underlying reasoning and behavior instead of reconstructing the masked content through other means.
What would settle it
A test where models trained with SMEPO achieve high rewards but fail to solve similar problems when expert traces are not provided or when masks are removed.
Figures



read the original abstract
Reinforcement learning with verifiable rewards (RLVR) has become a powerful paradigm for improving language models on reasoning-intensive tasks, but its effectiveness is often limited by exploration. For example, models often fail on hard problems, leaving little useful reward signal. External expert traces offer a natural source of guidance, yet they may also expose reward-relevant content along the critical path to the verifier target, such as final answers, intermediate values, executable implementations, or answer-related entities. This content can create an unintended reward hacking channel, allowing the policy to obtain reward by copying the trace rather than learning the underlying reasoning or agentic behavior. Existing guided-RL methods reduce this risk by using partial trajectories, but they mainly control how much expert information is shown heuristically rather than which parts should be hidden. To this end, we propose Semantic Masked Expert Policy Optimization (SMEPO), a fine-grained semantic masking strategy for expert-guided RLVR. Instead of truncating traces coarsely or revealing them unchanged, SMEPO masks reward-relevant semantic spans along the critical path while preserving the expert's decomposition, plan, and procedural structure. This turns hard problems from reasoning from scratch into a fill-in-the-blank process: the policy can follow the expert's problem-solving route, but must still reconstruct the missing values, code, or entities by itself. SMEPO is simple to apply and requires no changes to the reward function or RL objective. Across diverse domains, including math, code, and agentic search, SMEPO improves accuracy by up to 3.2 points over GRPO and reduces training time by up to 4.2x. The code is available at https://github.com/mit-han-lab/SMEPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Semantic Masked Expert Policy Optimization (SMEPO) for RLVR. SMEPO applies fine-grained semantic masking to reward-relevant spans (final answers, code, entities) in expert traces while preserving the expert's decomposition, plan, and procedural structure. This converts hard problems into a fill-in-the-blank task so the policy must reconstruct the masked content rather than copy it. The paper claims SMEPO yields accuracy gains of up to 3.2 points over GRPO and training-time reductions of up to 4.2x across math, code, and agentic-search domains, requires no reward or objective changes, and releases code at https://github.com/mit-han-lab/SMEPO.
Significance. If the reported gains are shown to arise from improved reasoning acquisition rather than pattern completion on preserved structure, SMEPO would supply a lightweight, reward-agnostic way to incorporate expert guidance in RLVR. The public code release is a clear strength for reproducibility.
major comments (2)
- [Abstract] Abstract: the empirical claims (accuracy +3.2, time -4.2x) are stated without any description of experimental setup, statistical significance testing, baseline implementations, or controls for confounding factors such as masking heuristics and data selection. This absence directly undermines evaluation of the central claim.
- [Abstract] Abstract (method and results): no ablation or control is described that pairs the retained expert decomposition with incorrect but plausible masked content. Without such a test it remains unclear whether the observed gains reflect genuine reasoning or reconstruction via domain priors and common solution templates.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and describe the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the empirical claims (accuracy +3.2, time -4.2x) are stated without any description of experimental setup, statistical significance testing, baseline implementations, or controls for confounding factors such as masking heuristics and data selection. This absence directly undermines evaluation of the central claim.
Authors: We agree that the abstract is concise and would benefit from additional context. In the revised version we will expand the abstract to briefly note the evaluation domains (math, code, agentic search), the main baseline (GRPO), and that results are averaged over multiple random seeds with reported statistical significance. Full descriptions of masking heuristics, data selection, and baseline implementations appear in Sections 3 and 4. Abstract length limits preclude exhaustive detail, but the added sentence will improve clarity without altering the central claim. revision: partial
-
Referee: [Abstract] Abstract (method and results): no ablation or control is described that pairs the retained expert decomposition with incorrect but plausible masked content. Without such a test it remains unclear whether the observed gains reflect genuine reasoning or reconstruction via domain priors and common solution templates.
Authors: We acknowledge the value of this specific control. Our existing ablations (Section 5) compare semantic masking against random masking and unmasked traces, showing that structure-preserving semantic masking is necessary for the observed gains. However, we did not include an explicit condition that replaces masked spans with incorrect but plausible content. We will add this experiment in the revision to directly test whether gains derive from reasoning acquisition rather than domain priors or template reconstruction. revision: yes
Circularity Check
No significant circularity; empirical method with no derivation chain
full rationale
The paper proposes SMEPO as a practical semantic masking strategy for expert-guided RLVR, turning hard problems into fill-in-the-blank via selective masking of reward-relevant spans while preserving structure. Claims of up to 3.2-point accuracy gains and 4.2x speedup over GRPO are presented purely as experimental outcomes across math, code, and agentic search domains, with no equations, derivations, or first-principles results shown. No self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations appear in the abstract or description. The approach requires no reward function changes and is supported by code release, making the central contribution self-contained empirical validation rather than a closed theoretical loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models, 2024. URLhttps://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, ...
-
[3]
REINFORCE++: Stabilizing Critic-Free Policy Optimization with Global Advantage Normalization
Jian Hu, Jason Klein Liu, Haotian Xu, and Wei Shen. REINFORCE++: Stabilizing critic-free policy optimization with global advantage normalization, 2025. URL https://arxiv.org/abs/2501.03262
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Reinforcement Learning for Reasoning in Large Language Models with One Training Example
Yiping Wang, Qing Yang, Zhiyuan Zeng, Liliang Ren, Liyuan Liu, Baolin Peng, Hao Cheng, Xuehai He, Kuan Wang, Jianfeng Gao, Weizhu Chen, Shuohang Wang, Simon Shaolei Du, and Yelong Shen. Reinforcement learning for reasoning in large language models with one training example, 2025. URL https://arxiv.org/abs/2504.20571
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding R1-Zero-Like training: A critical perspective, 2025. URL https://arxiv.org/abs/ 2503.20783
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
DeepResearcher: Scaling Deep Research via Reinforcement Learning in Real-world Environments
Yuxiang Zheng, Dayuan Fu, Xiangkun Hu, Xiaojie Cai, Lyumanshan Ye, Pengrui Lu, and Pengfei Liu. DeepResearcher: Scaling deep research via reinforcement learning in real-world environments, 2025. URL https://arxiv.org/abs/2504.03160
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Learn hard problems during RL with reference guided fine-tuning, 2026
Yangzhen Wu, Shanda Li, Zixin Wen, Xin Zhou, Ameet Talwalkar, Yiming Yang, Wenhao Huang, and Tianle Cai. Learn hard problems during RL with reference guided fine-tuning, 2026. URL https: //arxiv.org/abs/2603.01223
-
[9]
GHPO: Adaptive guidance for stable and efficient LLM reinforcement learning,
Ziru Liu, Cheng Gong, Xinyu Fu, Yaofang Liu, Ran Chen, Shoubo Hu, Suiyun Zhang, Rui Liu, Qingfu Zhang, and Dandan Tu. GHPO: Adaptive guidance for stable and efficient LLM reinforcement learning,
- [10]
-
[11]
Trust-region adaptive policy optimization, 2025
Mingyu Su, Jian Guan, Yuxian Gu, Minlie Huang, and Hongning Wang. Trust-region adaptive policy optimization, 2025. URLhttps://arxiv.org/abs/2512.17636. 10
-
[12]
POPE: Learning to reason on hard problems via privileged on-policy exploration, 2026
Yuxiao Qu, Amrith Setlur, Virginia Smith, Ruslan Salakhutdinov, and Aviral Kumar. POPE: Learning to reason on hard problems via privileged on-policy exploration, 2026. URL https://arxiv.org/abs/ 2601.18779
-
[13]
Learning to Reason under Off-Policy Guidance
Jianhao Yan, Yafu Li, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Yu Cheng, and Yue Zhang. Learning to reason under off-policy guidance, 2025. URLhttps://arxiv.org/abs/2504.14945
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Adaptive guidance accelerates reinforcement learning of reasoning models, 2025
Vaskar Nath, Elaine Lau, Anisha Gunjal, Manasi Sharma, Nikhil Baharte, and Sean Hendryx. Adaptive guidance accelerates reinforcement learning of reasoning models, 2025. URL https://arxiv.org/ abs/2506.13923
-
[15]
ReFT: Reasoning with reinforced fine-tuning, 2024
Trung Quoc Luong, Xinbo Zhang, Zhanming Jie, Peng Sun, Xiaoran Jin, and Hang Li. ReFT: Reasoning with reinforced fine-tuning, 2024. URLhttps://arxiv.org/abs/2401.08967
-
[16]
explo- sion/spaCy: v3.7.2: Fixes for APIs and requirements, October 2023
Ines Montani, Matthew Honnibal, Adriane Boyd, Sofie Van Landeghem, and Henning Peters. explo- sion/spaCy: v3.7.2: Fixes for APIs and requirements, October 2023. URL https://doi.org/10.5281/ zenodo.10009823
2023
-
[17]
SaySelf: Teaching LLMs to express confidence with self-reflective rationales
Urchade Zaratiana, Nadi Tomeh, Pierre Holat, and Thierry Charnois. GLiNER: Generalist model for named entity recognition using bidirectional transformer. In Kevin Duh, Helena Gomez, and Steven Bethard, editors,Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (V o...
-
[18]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Qwen Team, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao L...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021. URLhttps://arxiv.org/abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[21]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step, 2023. URL https://arxiv.org/ abs/2305.20050
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
American invitational mathematics examination (AIME) 2025, 2025
Yifan Zhang and Team Math-AI. American invitational mathematics examination (AIME) 2025, 2025. URLhttps://huggingface.co/datasets/math-ai/aime25
2025
-
[23]
American invitational mathematics examination (AIME) 2026, 2026
Yifan Zhang and Team Math-AI. American invitational mathematics examination (AIME) 2026, 2026. URLhttps://huggingface.co/datasets/math-ai/aime26
2026
-
[24]
American mathematics competitions (AMC) 2023, 2023
Yifan Zhang and Team Math-AI. American mathematics competitions (AMC) 2023, 2023. URL https: //huggingface.co/datasets/math-ai/amc23
2023
-
[25]
OlympiadBench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems,
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. OlympiadBench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems,
-
[26]
URLhttps://arxiv.org/abs/2402.14008
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[28]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by ChatGPT really correct? rigorous evaluation of large language models for code generation, 2023. URL https: //arxiv.org/abs/2305.01210
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar- Lezama, Koushik Sen, and Ion Stoica. LiveCodeBench: Holistic and contamination free evaluation of large language models for code, 2024. URLhttps://arxiv.org/abs/2403.07974
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Smith, and Mike Lewis
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A. Smith, and Mike Lewis. Measuring and narrowing the compositionality gap in language models, 2023. URL https://arxiv.org/abs/2210. 03350
2023
-
[31]
Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR), 2021
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR), 2021
2021
-
[32]
Aligning ai with shared human values.Proceedings of the International Conference on Learning Representations (ICLR), 2021
Dan Hendrycks, Collin Burns, Steven Basart, Andrew Critch, Jerry Li, Dawn Song, and Jacob Stein- hardt. Aligning ai with shared human values.Proceedings of the International Conference on Learning Representations (ICLR), 2021
2021
-
[33]
OpenThoughts: Data Recipes for Reasoning Models
Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, Ashima Suvarna, Benjamin Feuer, Liangyu Chen, Zaid Khan, Eric Frankel, Sachin Grover, Caroline Choi, Niklas Muennighoff, Shiye Su, Wanjia Zhao, John Yang, Shreyas Pimpalgaonkar, Kartik Sharma, Charlie Cheng-Jie Ji, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
MiroMind Team, Song Bai, Lidong Bing, Carson Chen, Guanzheng Chen, Yuntao Chen, Zhe Chen, Ziyi Chen, Jifeng Dai, Xuan Dong, Wenhan Dou, Yue Deng, Yunjie Fu, Junqi Ge, Chenxia Han, Tammy Huang, Zhenhang Huang, Jerry Jiao, Shilei Jiang, Tianyu Jiao, Xiaoqi Jian, Lei Lei, Ruilin Li, Gen Luo, Tiantong Li, Xiang Lin, Ziyuan Liu, Zhiqi Li, Jie Ni, Qiang Ren, Pa...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
The language model evaluation harness, 07 2024
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. The languag...
-
[36]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-R1: Training LLMs to reason and leverage search engines with reinforcement learning, 2025. URLhttps://arxiv.org/abs/2503.09516
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Enci Zhang, Xingang Yan, Wei Lin, Tianxiang Zhang, and Qianchun Lu. Learning Like Humans: Advancing LLM reasoning capabilities via adaptive difficulty curriculum learning and expert-guided self-reformulation, 2025. URLhttps://arxiv.org/abs/2505.08364
-
[38]
Concrete Problems in AI Safety
Dario Amodei, Chris Olah, Jacob Steinhardt, Paul Christiano, John Schulman, and Dan Mané. Concrete problems in AI safety, 2016. URLhttps://arxiv.org/abs/1606.06565
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[39]
Tom Everitt, Marcus Hutter, Ramana Kumar, and Victoria Krakovna. Reward tampering problems and solutions in reinforcement learning: A causal influence diagram perspective, 2021. URL https: //arxiv.org/abs/1908.04734. 12
-
[40]
Defining and characteriz- ing reward gaming
Joar Skalse, Nikolaus Howe, Dmitrii Krasheninnikov, and David Krueger. Defining and characteriz- ing reward gaming. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, edi- tors,Advances in Neural Information Processing Systems, volume 35, pages 9460–9471. Curran As- sociates, Inc., 2022. URL https://proceedings.neurips.cc/paper_files/pa...
2022
-
[41]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In Jill Burstein, Christy Doran, and Thamar Solorio, editors,Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, V ol...
-
[42]
MASS: Masked Sequence to Sequence Pre-training for Language Generation
Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and Tie-Yan Liu. MASS: Masked sequence to sequence pre-training for language generation, 2019. URLhttps://arxiv.org/abs/1905.02450
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[43]
BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Veselin Stoyanov, and Luke Zettlemoyer. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault, editors,Proceedings of the 58th Annual Meeti...
2020
-
[44]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67, 2020. URL http://jmlr.org/papers/v21/ 20-074.html
2020
-
[45]
Efficient Training of Language Models to Fill in the Middle
Mohammad Bavarian, Heewoo Jun, Nikolas Tezak, John Schulman, Christine McLeavey, Jerry Tworek, and Mark Chen. Efficient training of language models to fill in the middle, 2022. URLhttps://arxiv. org/abs/2207.14255
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[46]
InCoder: A generative model for code infilling and synthesis,
Daniel Fried, Armen Aghajanyan, Jessy Lin, Sida Wang, Eric Wallace, Freda Shi, Ruiqi Zhong, Wen tau Yih, Luke Zettlemoyer, and Mike Lewis. InCoder: A generative model for code infilling and synthesis,
-
[47]
URLhttps://arxiv.org/abs/2204.05999
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
SantaCoder: don’t reach for the stars!,
Loubna Ben Allal, Raymond Li, Denis Kocetkov, Chenghao Mou, Christopher Akiki, Carlos Munoz Ferran- dis, Niklas Muennighoff, Mayank Mishra, Alex Gu, Manan Dey, Logesh Kumar Umapathi, Carolyn Jane Anderson, Yangtian Zi, Joel Lamy Poirier, Hailey Schoelkopf, Sergey Troshin, Dmitry Abulkhanov, Manuel Romero, Michael Lappert, Francesco De Toni, Bernardo Garcí...
- [49]
-
[50]
Yue Wang, Hung Le, Akhilesh Deepak Gotmare, Nghi D. Q. Bui, Junnan Li, and Steven C. H. Hoi. CodeT5+: Open code large language models for code understanding and generation, 2023. URL https: //arxiv.org/abs/2305.07922
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y . Wu, Y . K. Li, Fuli Luo, Yingfei Xiong, and Wenfeng Liang. DeepSeek-Coder: When the large language model meets programming – the rise of code intelligence, 2024. URL https://arxiv.org/abs/2401.14196
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
DeepSeek-AI, Qihao Zhu, Daya Guo, Zhihong Shao, Dejian Yang, Peiyi Wang, Runxin Xu, Y . Wu, Yukun Li, Huazuo Gao, Shirong Ma, Wangding Zeng, Xiao Bi, Zihui Gu, Hanwei Xu, Damai Dai, Kai Dong, Liyue Zhang, Yishi Piao, Zhibin Gou, Zhenda Xie, Zhewen Hao, Bingxuan Wang, Junxiao Song, Deli Chen, Xin Xie, Kang Guan, Yuxiang You, Aixin Liu, Qiushi Du, Wenjun Ga...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Evaluation of LLMs on syntax-aware code fill-in-the-middle tasks, 2024
Linyuan Gong, Sida Wang, Mostafa Elhoushi, and Alvin Cheung. Evaluation of LLMs on syntax-aware code fill-in-the-middle tasks, 2024. URLhttps://arxiv.org/abs/2403.04814
-
[54]
Structure-aware fill-in-the-middle pretraining for code, 2025
Linyuan Gong, Alvin Cheung, Mostafa Elhoushi, and Sida Wang. Structure-aware fill-in-the-middle pretraining for code, 2025. URLhttps://arxiv.org/abs/2506.00204. 13
-
[55]
Laminar: A scalable asynchronous RL post-training framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. HybridFlow: A flexible and efficient RLHF framework. InProceedings of the Twentieth European Conference on Computer Systems, EuroSys ’25, page 1279–1297. ACM, March 2025. doi: 10.1145/3689031.3696075. URLhttp://dx.doi.org/10.1145/3689031.3696...
-
[56]
collected
So, we need to find k such that 4k + 3 = 2001. Solving for k: 4k + 3 = 2001 4k = 1998 k = 499.5 Since k must be an integer, we need to adjust our approach. The rollout repeats this failed pattern, repeatedly forcing even targets such as 2000 into a rule that applies to inputs of the form4n+ 1. SMEPO Output The masked trace removes the concrete numbers but...
2001
-
[57]
- For \( n = 4k + 3 \), \( f(n) = 8k + 2 \)
**Odd Numbers**: - For \( n = 4k + 1 \), \( f(n) = 4k + 3 \). - For \( n = 4k + 3 \), \( f(n) = 8k + 2 \). 24
-
[58]
Then \( f(n) = 2^k \cdot f(m) \)
**Even Numbers**: - If \( n \) is even, express \( n \) as \( 2^k \cdot m \) where \( m \) is odd. Then \( f(n) = 2^k \cdot f(m) \). **Application to \( n = 1000 \)**: - Decompose \( 1000 = 2^3 \cdot 125 \). - \( 125 \) is odd and of the form \( 4k + 1 \) (\( 125 = 4 \cdot 31 + 1 \)), so \( f(125) = 4 \cdot 31 + 3 = 127 \). - Therefore, \( f(1000) = 2^3 \...
2000
-
[59]
### Step 1: Understand the function properties - The first property \( f(f(n)) = 2n \) tells us that applying the function twice doubles the input
\( f(4n + 1) = 4n + 3 \) Let’s proceed step by step. ### Step 1: Understand the function properties - The first property \( f(f(n)) = 2n \) tells us that applying the function twice doubles the input. - The second property \( f(4n + 1) = 4n + 3 \) gives us the value of the function for numbers of the form \( 4n + 1 \). 25 ### Step 2: Find a pattern or a w...
2000
-
[60]
Here, \( 125 \) is odd and can be written as \( 125 = 4 \cdot 31 + 1 \)
**Identify the form of \( n \):** - \( 1000 \) is an even number, and we can express it as \( 1000 = 2^3 \cdot 125 \). Here, \( 125 \) is odd and can be written as \( 125 = 4 \cdot 31 + 1 \)
-
[61]
**Use the given conditions:** - Since \( 125 = 4 \cdot 31 + 1 \), we have \( f(125) = 4 \cdot 31 + 3 = 127 \)
-
[62]
inputs": [
**Determine \( f(1000) \):** - First, derive the scaling property. From \( f(f(n)) = 2n \), applying the same identity to \( f(n) \) gives \( f(f(f(n))) = 2f(n) \). Since \( f(f(n)) = 2n \), the left-hand side is also \( f(2n) \). Hence \( f(2n) = 2f(n) \), and by induction \( f(2^k \cdot m) = 2^k \cdot f(m) \). - Since \( 1000 = 2^3 \cdot 125 \), we get ...
-
[67]
**Find Minimum Cost**: Iterate through all (dx, dy) pairs to find the minimum number of chains, which corresponds to the minimum cost. ### Solution Code ‘‘\‘python n = int(input()) points = [tuple(map(int, input().split())) for _ in range(n)] if n == 1: print(1) exit() points_set = set(points) diff_set = set() 29 for i in range(n): x_i, y_i = points[i] fo...
-
[70]
**Generate Differences**: For each pair of distinct points, the differences (dx, dy) are computed and stored in a set to avoid duplicates
-
[72]
**Find Minimum**: The minimum number of chains across all (dx, dy) pairs is determined and printed as the result. Masked Expert Hint To solve this problem, we need to determine the minimum total cost required to collect all balls in a 2D plane by optimally choosing two integers p and q (not both zero). The cost is minimized by arranging the balls into the...
-
[73]
**Input Handling**: Read the number of balls and their coordinates
-
[74]
**Special Case for Single Ball**: If there is only one ball, the cost is always 1
-
[75]
**Generate Differences**: Compute all possible (dx, dy) pairs from the differences between every pair of distinct points
-
[76]
A chain starts at a point if the previous point (by subtracting dx and dy) is not present
**Determine Chains**: For each (dx, dy) pair, calculate the number of chains required. A chain starts at a point if the previous point (by subtracting dx and dy) is not present
-
[77]
### Solution Code ‘‘\‘python [CODE] ‘‘\‘ ### Explanation
**Find Minimum Cost**: Iterate through all (dx, dy) pairs to find the minimum number of chains, which corresponds to the minimum cost. ### Solution Code ‘‘\‘python [CODE] ‘‘\‘ ### Explanation
-
[78]
**Input Handling**: The code reads the number of balls and their coordinates, storing them in a list and a set for quick lookups
-
[79]
**Special Case Handling**: If there’s only one ball, the cost is directly output as 1
-
[80]
**Generate Differences**: For each pair of distinct points, the differences (dx, dy) are computed and stored in a set to avoid duplicates. 30
-
[81]
The count of such starting points gives the number of chains
**Chain Calculation**: For each (dx, dy) pair, the code checks each point to see if it can start a new chain by verifying if the previous point (x-dx, y-dy) exists in the set of points. The count of such starting points gives the number of chains
-
[82]
__main__
**Find Minimum**: The minimum number of chains across all (dx, dy) pairs is determined and printed as the result. Expert Output ‘‘\‘python n = int(input()) points = [tuple(map(int, input().split())) for _ in range(n)] if n == 1: print(1) exit() points_set = set(points) diff_set = set() for i in range(n): x_i, y_i = points[i] for j in range(n): if i != j: ...
2015
-
[83]
to New York City
Identify the Amtrak train derailment incident in 2015 involving a train from Washington, D.C. to New York City
2015
-
[84]
Find the list of eight victims killed in that incident
-
[85]
Determine which of those victims was an American social entrepreneur
-
[86]
<search> Find information about the 2015 Amtrak train derailment from Washington, D.C
Find the age of that individual at the time of the incident First, I’ll search for information about the 2015 Amtrak derailment to identify the victims. <search> Find information about the 2015 Amtrak train derailment from Washington, D.C. to New York City, including the list of victims killed in the incident. </search> Round 2: From the list of victims, ...
2015
-
[87]
Identify the [ENTITY] train derailment incident in [ENTITY] involving a train from [ENTITY], [ENTITY] to [ENTITY]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.