LUNA: Learning Universal 3D Human Animation Beyond Skinning
Pith reviewed 2026-07-01 05:18 UTC · model grok-4.3
The pith
LUNA maps 2D controls directly to 3D Gaussian human deformations without linear blend skinning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
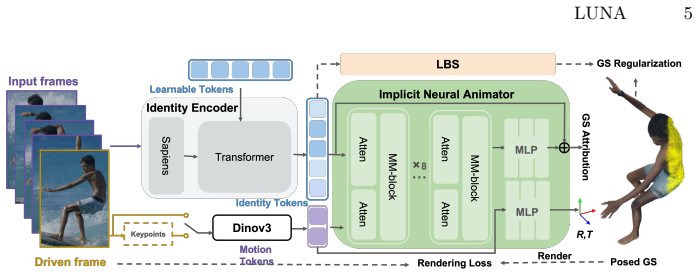
LUNA is the first end-to-end 3D animatable model supporting implicit 2D driving by directly mapping multiple 2D controls to 3D Gaussian deformations via a transformer motion regressor that disentangles global rigid motion from fine-grained local dynamics, trained with hybrid supervision that distills soft priors from an LBS teacher on limited fitted data plus large in-the-wild videos.
What carries the argument
Transformer-based motion regressor that disentangles global rigid motion from local dynamics, paired with hybrid LBS-teacher distillation and a loss supporting both fitted and unlabeled video data.
If this is right
- LUNA reaches visual fidelity competitive with LBS-based methods.
- It produces realistic human motion with zero-shot cross-identity generalization.
- It handles diverse 2D driving modalities including sketches and unseen characters.
- Training scales to large unlabeled video collections beyond limited fitted datasets.
Where Pith is reading between the lines
- The LBS-free design may extend naturally to clothing and hair dynamics that parametric models handle poorly.
- Implicit 2D driving could support real-time avatar control from casual smartphone video.
- The hybrid supervision pattern may apply to other 3D reconstruction tasks that mix synthetic and in-the-wild data.
Load-bearing premise
Hybrid supervision from an LBS teacher plus a loss usable on both fitted data and unlabeled videos suffices to resolve 2D-to-3D lifting ambiguity and scale beyond fitted datasets.
What would settle it
Failure to produce coherent deformations on a set of in-the-wild 2D driving videos where traditional LBS fitting is known to be ambiguous would falsify the central claim.
Figures








read the original abstract
Creating photorealistic, animatable 3D human avatars from monocular images still largely depends on Linear Blend Skinning (LBS) and parametric body models, which constrain expressivity and often introduce artifacts due to imperfect fitting. We propose LUNA, an LBS-free universal neural animation model that directly maps multiple 2D controls like images, keypoints, sketches, and unseen characters into 3D Gaussian deformations, bypassing explicit body fitting. At its core, a transformer-based motion regressor disentangles global rigid motion from fine-grained local dynamics to capture both coherent movement and subtle non-rigid effects. To resolve the inherent ambiguity of 2D-to-3D lifting while scaling beyond fitted datasets, we introduce hybrid supervision that distills soft structural priors from an LBS teacher and a loss that supports training on both limited fitted data and large in-the-wild unlabeled videos. Extensive experiments show LUNA achieves competitive visual fidelity compared to LBS-based approaches, while delivering realistic human motion and zero-shot cross-identity generalization across diverse driving modalities. To the best of our knowledge, LUNA is the first end-to-end 3D animatable model that supports implicit 2D driving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LUNA, an LBS-free universal neural animation model that directly maps multiple 2D controls (images, keypoints, sketches, unseen characters) to 3D Gaussian deformations via a transformer-based motion regressor that disentangles global rigid motion from local dynamics. Hybrid supervision distills soft structural priors from an LBS teacher while supporting training on limited fitted data and large in-the-wild unlabeled videos to resolve 2D-to-3D ambiguity. The manuscript reports competitive visual fidelity to LBS-based methods, realistic motion, zero-shot cross-identity generalization across driving modalities, and claims to be the first end-to-end 3D animatable model supporting implicit 2D driving.
Significance. If the experimental claims hold with rigorous quantitative validation, this work could meaningfully advance 3D human animation by removing reliance on parametric LBS models, enabling greater expressivity for non-rigid effects and better scaling to in-the-wild data. The hybrid supervision strategy for handling lifting ambiguity represents a practical contribution worth evaluating against existing distillation and self-supervised approaches in the field.
major comments (2)
- Abstract: The claims of 'competitive visual fidelity', 'realistic human motion', and 'zero-shot cross-identity generalization' are asserted without any quantitative metrics, error analysis, ablation studies, or experimental details supplied in the text, preventing assessment of whether the hybrid supervision actually resolves the 2D-to-3D ambiguity or enables the reported scaling.
- Abstract: The assertion that LUNA is 'the first end-to-end 3D animatable model that supports implicit 2D driving' is a strong novelty claim; without the related-work section or explicit comparisons to prior implicit or end-to-end methods, it is impossible to verify whether this holds or if the hybrid supervision is the key differentiator.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to address these points regarding the abstract. We respond to each major comment below, clarifying the support provided in the full manuscript.
read point-by-point responses
-
Referee: Abstract: The claims of 'competitive visual fidelity', 'realistic human motion', and 'zero-shot cross-identity generalization' are asserted without any quantitative metrics, error analysis, ablation studies, or experimental details supplied in the text, preventing assessment of whether the hybrid supervision actually resolves the 2D-to-3D ambiguity or enables the reported scaling.
Authors: The abstract is a high-level summary. The full manuscript contains a dedicated Experiments section (Section 4) with quantitative metrics for visual fidelity and motion quality, error analysis, ablation studies on the hybrid supervision, and evaluation of its role in resolving 2D-to-3D ambiguity and enabling scaling to in-the-wild data. These results are presented with tables, figures, and comparisons. We can revise the abstract to include brief references to Section 4 for improved clarity. revision: partial
-
Referee: Abstract: The assertion that LUNA is 'the first end-to-end 3D animatable model that supports implicit 2D driving' is a strong novelty claim; without the related-work section or explicit comparisons to prior implicit or end-to-end methods, it is impossible to verify whether this holds or if the hybrid supervision is the key differentiator.
Authors: The manuscript includes a Related Work section (Section 2) reviewing LBS-based, implicit, and end-to-end animation methods, along with explicit comparisons in the Experiments section. The novelty claim is qualified as 'to the best of our knowledge' and is supported by positioning LUNA's LBS-free implicit 2D driving capability, with the hybrid supervision detailed in the Method section as a key enabler. No revision is needed as the supporting sections are present. revision: no
Circularity Check
No circularity in derivation chain
full rationale
The abstract and supplied text contain no equations, derivations, predictions, or self-citations that could reduce any claimed result to its inputs by construction. The hybrid supervision (LBS-teacher distillation plus in-the-wild loss) is presented as a methodological choice to address ambiguity, with no fitted-parameter-as-prediction pattern, uniqueness theorem, or ansatz smuggling visible. The central claim of being the first end-to-end implicit-2D-driving model is a novelty assertion, not a derivation. No load-bearing steps exist to analyze, so the paper's description remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022)
Alldieck, T., Zanfir, M., Sminchisescu, C.: Photorealistic monocular 3d reconstruc- tion of humans wearing clothing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2022)
2022
-
[2]
ACM Transactions on Graphics (TOG)40(4), 1–17 (2021)
Bagautdinov, T., Wu, C., Simon, T., Prada, F., Shiratori, T., Wei, S.E., Xu, W., Sheikh, Y., Saragih, J.: Driving-signal aware full-body avatars. ACM Transactions on Graphics (TOG)40(4), 1–17 (2021)
2021
-
[3]
arXiv preprint arXiv:2509.24817 (2025)
Cai, Z., Li, Z., Li, X., Li, B., Wang, Z., Zhang, Z., Xiu, Y.: Up2you: Fast reconstruction of yourself from unconstrained photo collections. arXiv preprint arXiv:2509.24817 (2025)
-
[4]
In: Proceed- ings of the IEEE/CVF international conference on computer vision
Chan, C., Ginosar, S., Zhou, T., Efros, A.A.: Everybody dance now. In: Proceed- ings of the IEEE/CVF international conference on computer vision. pp. 5933–5942 (2019)
2019
-
[5]
In: Proceedings of the Computer Vision and Pattern Recognition Con- ference
Chen, J., Hu, J., Wang, G., Jiang, Z., Zhou, T., Chen, Z., Lv, C.: Taoavatar: Real-time lifelike full-body talking avatars for augmented reality via 3d gaussian splatting. In: Proceedings of the Computer Vision and Pattern Recognition Con- ference. pp. 10723–10734 (2025)
2025
-
[6]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Chen, J., Yi, W., Ma, L., Jia, X., Lu, H.: Gm-nerf: Learning generalizable model-based neural radiance fields from multi-view images. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 20648–20658 (June 2023)
2023
-
[7]
In: ECCV (2022)
Chen, M., Zhang, J., Xu, X., Liu, L., Cai, Y., Feng, J., Yan, S.: Geometry-guided progressive nerf for generalizable and efficient neural human rendering. In: ECCV (2022)
2022
-
[8]
arXiv preprint arXiv:2510.07723 (2025)
Chen, W., Li, P., Zheng, W., Zhao, C., Li, M., Zhu, Y., Dou, Z., Wang, R., Liu, Y.: Synchuman: Synchronizing 2d and 3d generative models for single-view human reconstruction. arXiv preprint arXiv:2510.07723 (2025)
- [9]
-
[10]
arXiv preprint arXiv:2509.14055 (2025)
Cheng, G., Gao, X., Hu, L., Hu, S., Huang, M., Ji, C., Li, J., Meng, D., Qi, J., Qiao, P., et al.: Wan-animate: Unified character animation and replacement with holistic replication. arXiv preprint arXiv:2509.14055 (2025)
-
[11]
In: CVPR (2023)
Du, Y., Kips, R., Pumarola, A., Starke, S., Thabet, A., Sanakoyeu, A.: Avatars grow legs: Generating smooth human motion from sparse tracking inputs with diffusion model. In: CVPR (2023)
2023
-
[12]
In: ICML (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: ICML (2024)
2024
-
[13]
Ferguson, A., Osman, A.A.A., Bescos, B., Stoll, C., Twigg, C., Lassner, C., Otte, D., Vignola, E., Prada, F., Bogo, F., Santesteban, I., Romero, J., Zarate, J., Lee, J., Park, J., Yang, J., Doublestein, J., Venkateshan, K., Kitani, K., Kavan, L., Farra, M.D., Hu, M., Cioffi, M., Fabris, M., Ranieri, M., Modarres, M., Kadlecek, P., Khirodkar, R., Abdrashit...
-
[14]
In: LUNA 17 ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition
Guo, C., Jiang, T., Chen, X., Song, J., Hilliges, O.: Vid2avatar: 3d avatar re- construction from videos in the wild via self-supervised scene decomposition. In: LUNA 17 ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition. pp. 12858–12868 (2023)
2023
-
[15]
In: European conference on computer vision (ECCV) (2024)
Guo, C., Jiang, T., Kaufmann, M., Zheng, C., Valentin, J., Song, J., Hilliges, O.: Reloo: Reconstructing humans dressed in loose garments from monocular video in the wild. In: European conference on computer vision (ECCV) (2024)
2024
-
[16]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Guo, C., Li, J., Kant, Y., Sheikh, Y., Saito, S., Cao, C.: Vid2avatar-pro: Authentic avatar from videos in the wild via universal prior. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 5559–5570 (2025)
2025
-
[17]
ACM Transactions on Graphics40(4) (aug 2021)
Habermann, M., Liu, L., Xu, W., Zollhoefer, M., Pons-Moll, G., Theobalt, C.: Real-time deep dynamic characters. ACM Transactions on Graphics40(4) (aug 2021)
2021
-
[18]
In: Proceedings of the IEEE/CVF international conference on computer vision
He, T., Xu, Y., Saito, S., Soatto, S., Tung, T.: Arch++: Animation-ready clothed human reconstruction revisited. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 11046–11056 (2021)
2021
-
[19]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ho, I., Song, J., Hilliges, O., et al.: Sith: Single-view textured human reconstruction with image-conditioned diffusion. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 538–549 (2024)
2024
-
[20]
LRM: Large Reconstruction Model for Single Image to 3D
Hong, Y., Zhang, K., Gu, J., Bi, S., Zhou, Y., Liu, D., Liu, F., Sunkavalli, K., Bui, T., Tan, H.: Lrm: Large reconstruction model for single image to 3d. arXiv preprint arXiv:2311.04400 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Hu, L.: Animate anyone: Consistent and controllable image-to-video synthesis for character animation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8153–8163 (2024)
2024
-
[22]
In: 2022 International Conference on 3D Vision (3DV) (2022)
Hu,T.,Yu,T.,Zheng,Z.,Zhang,H.,Liu,Y.,Zwicker,M.:Hvtr:Hybridvolumetric- textural rendering for human avatars. In: 2022 International Conference on 3D Vision (3DV) (2022)
2022
-
[23]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Z., Xu, Y., Lassner, C., Li, H., Tung, T.: Arch: Animatable reconstruction of clothed humans. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3093–3102 (2020)
2020
-
[24]
In: ACM SIGGRAPH (2021)
Jiakai, Z., Xinhang, L., Xinyi, Y., Fuqiang, Z., Yanshun, Z., Minye, W., Yingliang, Z., Lan, X., Jingyi, Y.: Editable free-viewpoint video using a layered neural repre- sentation. In: ACM SIGGRAPH (2021)
2021
-
[25]
In: Proceedings of the European conference on computer vision (ECCV) (2022)
Jiang, W., Yi, K.M., Samei, G., Tuzel, O., Ranjan, A.: Neuman: Neural human radiance field from a single video. In: Proceedings of the European conference on computer vision (ECCV) (2022)
2022
- [26]
-
[27]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2019)
Kanazawa, A., Zhang, J.Y., Felsen, P., Malik, J.: Learning 3d human dynamics from video. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (June 2019)
2019
-
[28]
TOG (2023),https://repo- sam.inria.fr/ fungraph/3d-gaussian-splatting/
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. TOG (2023),https://repo- sam.inria.fr/ fungraph/3d-gaussian-splatting/
2023
-
[29]
In: European Conference on Computer Vision
Khirodkar, R., Bagautdinov, T., Martinez, J., Zhaoen, S., James, A., Selednik, P., Anderson, S., Saito, S.: Sapiens: Foundation for human vision models. In: European Conference on Computer Vision. pp. 206–228. Springer (2024)
2024
-
[30]
In: European Conference on Computer Vision (2024) 18 P
Kwon, Y., Fang, B., Lu, Y., Dong, H., Zhang, C., Carrasco, F.V., Mosella-Montoro, A., Xu, J., Takagi, S., Kim, D., Prakash, A., la Torre, F.D.: Generalizable human gaussians for sparse view synthesis. In: European Conference on Computer Vision (2024) 18 P. Li et al
2024
-
[31]
Lei, J., Wang, Y., Pavlakos, G., Liu, L., Daniilidis, K.: Gart: Gaussian articulated template models (2023)
2023
-
[32]
In: ACM SIGGRAPH 2024 Conference Papers (2024)
Li, J., Cao, C., Schwartz, G., Khirodkar, R., Richardt, C., Simon, T., Sheikh, Y., Saito, S.: Uravatar: Universal relightable gaussian codec avatars. In: ACM SIGGRAPH 2024 Conference Papers (2024)
2024
- [33]
-
[34]
Li, P., Zheng, W., Liu, Y., Yu, T., Li, Y., Qi, X., Li, M., Chi, X., Xia, S., Xue, W., et al.: Pshuman: Photorealistic single-view human reconstruction using cross-scale diffusion. arXiv preprint arXiv:2409.10141 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
In: European Conference on Com- puter Vision (ECCV) (2022)
Li, R., Tanke, J., Vo, M., Zollhofer, M., Gall, J., Kanazawa, A., Lassner, C.: Tava: Template-free animatable volumetric actors. In: European Conference on Com- puter Vision (ECCV) (2022)
2022
-
[36]
ACM SIGGRAPH Conference Pro- ceedings (2023)
Li, Z., Zheng, Z., Liu, Y., Zhou, B., Liu, Y.: Posevocab: Learning joint-structured pose embeddings for human avatar modeling. ACM SIGGRAPH Conference Pro- ceedings (2023)
2023
-
[37]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, Z., Zheng, Z., Wang, L., Liu, Y.: Animatable gaussians: Learning pose- dependent gaussian maps for high-fidelity human avatar modeling. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 19711–19722 (2024)
2024
-
[38]
In: CVPR (2024)
Li, Z., Zheng, Z., Wang, L., Liu, Y.: Animatable gaussians: Learning pose- dependent gaussian maps for high-fidelity human avatar modeling. In: CVPR (2024)
2024
-
[39]
ACM Trans
Liu, L., Habermann, M., Rudnev, V., Sarkar, K., Gu, J., Theobalt, C.: Neural actor: Neural free-view synthesis of human actors with pose control. ACM Trans. Graph.(ACM SIGGRAPH Asia) (2021)
2021
-
[40]
In: Proceedings of the IEEE/CVF international conference on computer vision
Liu, W., Piao, Z., Min, J., Luo, W., Ma, L., Gao, S.: Liquid warping gan: A unified framework for human motion imitation, appearance transfer and novel view synthesis. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 5904–5913 (2019)
2019
-
[41]
TOG34(6), 1–16 (2015)
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: Smpl: a skinned multi-person linear model. TOG34(6), 1–16 (2015)
2015
-
[42]
NeurIPS Track on Datasets and Benchmarks (2024)
Martinez, J., Kim, E., Romero, J., Bagautdinov, T., Saito, S., Yu, S.I., Anderson, S., Zollhöfer, M., Wang, T.L., Bai, S., Li, C., Wei, S.E., Joshi, R., Borsos, W., Simon, T., Saragih, J., Theodosis, P., Greene, A., Josyula, A., Maeta, S.M., Jewett, A.I., Venshtain, S., Heilman, C., Chen, Y.T., Fu, S., Elshaer, M.E.A., Du, T., Wu, L., Chen, S.C., Kang, K....
2024
-
[43]
In: ECCV
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: NeRF: Representing scenes as neural radiance fields for view synthesis. In: ECCV. pp. 405–421 (2020)
2020
-
[44]
In: ECCV (2024)
Moon, G., Shiratori, T., Saito, S.: Expressive whole-body 3d gaussian avatar. In: ECCV (2024)
2024
-
[45]
In: CVPR (2024) LUNA 19
Moreau, A., Song, J., Dhamo, H., Shaw, R., Zhou, Y., Pérez-Pellitero, E.: Human gaussian splatting: Real-time rendering of animatable avatars. In: CVPR (2024) LUNA 19
2024
-
[46]
In: International Conference on Computer Vision (2021)
Noguchi, A., Sun, X., Lin, S., Harada, T.: Neural articulated radiance field. In: International Conference on Computer Vision (2021)
2021
-
[47]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Pang,H.,Zhu,H.,Kortylewski,A.,Theobalt,C.,Habermann,M.:Ash:Animatable gaussian splats for efficient and photoreal human rendering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 1165–1175 (June 2024)
2024
-
[48]
In: Proceedings IEEE Conf
Pavlakos, G., Choutas, V., Ghorbani, N., Bolkart, T., Osman, A.A.A., Tzionas, D., Black, M.J.: Expressive body capture: 3D hands, face, and body from a single image. In: Proceedings IEEE Conf. on Computer Vision and Pattern Recognition (CVPR). pp. 10975–10985 (2019)
2019
-
[49]
In: CVPR (2019)
Pavlakos, G., Choutas, V., Ghorbani, N., Bolkart, T., Osman, A.A., Tzionas, D., Black, M.J.: Expressive body capture: 3d hands, face, and body from a single image. In: CVPR (2019)
2019
-
[50]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Peng, S., Dong, J., Wang, Q., Zhang, S., Shuai, Q., Zhou, X., Bao, H.: Animatable neural radiance fields for modeling dynamic human bodies. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 14314–14323 (2021)
2021
-
[51]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Peng, S., Zhang, Y., Xu, Y., Wang, Q., Shuai, Q., Bao, H., Zhou, X.: Neural body: Implicit neural representations with structured latent codes for novel view synthesis of dynamic humans. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9054–9063 (2021)
2021
-
[52]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Qiu, L., Gu, X., Li, P., Zuo, Q., Shen, W., Zhang, J., Qiu, K., Yuan, W., Chen, G., Dong, Z., et al.: Lhm: Large animatable human reconstruction model for single image to 3d in seconds. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 14184–14194 (2025)
2025
-
[53]
arXiv preprint arXiv:2506.13766 (2025)
Qiu, L., Li, P., Zuo, Q., Gu, X., Dong, Y., Yuan, W., Zhu, S., Han, X., Chen, G., Dong, Z.: Pf-lhm: 3d animatable avatar reconstruction from pose-free articulated human images. arXiv preprint arXiv:2506.13766 (2025)
-
[54]
In: CVPR (2025)
Qiu, L., Zhu, S., Zuo, Q., Gu, X., Dong, Y., Zhang, J., Xu, C., Li, Z., Yuan, W., Bo, L., et al.: Anigs: Animatable gaussian avatar from a single image with inconsistent gaussian reconstruction. In: CVPR (2025)
2025
-
[55]
In: ACM SIGGRAPH 2022 Conference Proceedings
Remelli, E., Bagautdinov, T., Saito, S., Wu, C., Simon, T., Wei, S.E., Guo, K., Cao, Z., Prada, F., Saragih, J., et al.: Drivable volumetric avatars using texel-aligned features. In: ACM SIGGRAPH 2022 Conference Proceedings. pp. 1–9 (2022)
2022
-
[56]
In: Proceedings of the IEEE/CVF international conference on computer vision
Saito, S., Huang, Z., Natsume, R., Morishima, S., Kanazawa, A., Li, H.: Pifu: Pixel-aligned implicit function for high-resolution clothed human digitization. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 2304–2314 (2019)
2019
-
[57]
In: CVPR (2024)
Saito, S., Schwartz, G., Simon, T., Li, J., Nam, G.: Relightable gaussian codec avatars. In: CVPR (2024)
2024
-
[58]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Saito, S., Simon, T., Saragih, J., Joo, H.: Pifuhd: Multi-level pixel-aligned im- plicit function for high-resolution 3d human digitization. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 84–93 (2020)
2020
-
[59]
TOG43(6) (2024)
Shao, R., Pang, Y., Zheng, Z., Sun, J., Liu, Y.: Human4dit: 360-degree human video generation with 4d diffusion transformer. TOG43(6) (2024)
2024
-
[60]
In: Computer Vision and Pattern Recognition (CVPR) (2023)
Shen, K., Guo, C., Kaufmann, M., Zarate, J., Valentin, J., Song, J., Hilliges, O.: X- avatar: Expressive human avatars. In: Computer Vision and Pattern Recognition (CVPR) (2023)
2023
-
[61]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., Massa, F., Haziza, D., Wehrstedt, 20 P. Li et al. L., Wang, J., Darcet, T., Moutakanni, T., Sentana, L., Roberts, C., Vedaldi, A., Tolan, J., Brandt, J., Couprie, C., Mairal, J., Jégou, H., Labatut, P., Bojanowski, P.: DINOv3 (...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[62]
In: The Thirteenth International Conference on Learning Rep- resentations (2025)
Song, C., Wu, Z., Su, S.Y., Wandt, B., Sigal, L., Rhodin, H.: Locality sensitive avatars from video. In: The Thirteenth International Conference on Learning Rep- resentations (2025)
2025
-
[63]
In: 3DV (2025)
Tan, J., Xiang, D., Tulsiani, S., Ramanan, D., Yang, G.: Dressrecon: Freeform 4d human reconstruction from monocular video. In: 3DV (2025)
2025
-
[64]
In: European Conference on Computer Vision (ECCV) (2022)
Wang, S., Schwarz, K., Geiger, A., Tang, S.: Arah: Animatable volume rendering of articulated human sdfs. In: European Conference on Computer Vision (ECCV) (2022)
2022
-
[65]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang,T.,Li,L.,Lin,K.,Zhai,Y.,Lin,C.C.,Yang,Z.,Zhang,H.,Liu,Z.,Wang,L.: Disco: Disentangled control for realistic human dance generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9326–9336 (2024)
2024
-
[66]
In: CVPR (2022)
Weng, C.Y., Curless, B., Srinivasan, P.P., Barron, J.T., Kemelmacher-Shlizerman, I.: Humannerf: Free-viewpoint rendering of moving people from monocular video. In: CVPR (2022)
2022
-
[67]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xiu, Y., Yang, J., Cao, X., Tzionas, D., Black, M.J.: Econ: Explicit clothed humans optimized via normal integration. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 512–523 (2023)
2023
-
[68]
In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Xiu, Y., Yang, J., Tzionas, D., Black, M.J.: Icon: Implicit clothed humans obtained from normals. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 13286–13296. IEEE (2022)
2022
-
[69]
In: CVPR (2022)
Xu, T., Fujita, Y., Matsumoto, E.: Surface-aligned neural radiance fields for con- trollable 3d human synthesis. In: CVPR (2022)
2022
-
[70]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Xu, Z., Zhang, J., Liew, J.H., Yan, H., Liu, J.W., Zhang, C., Feng, J., Shou, M.Z.: Magicanimate: Temporally consistent human image animation using diffu- sion model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1481–1490 (2024)
2024
-
[71]
arXiv preprint arXiv:2602.15989 (2026)
Yang, X., Kukreja, D., Pinkus, D., Sagar, A., Fan, T., Park, J., Shin, S., Cao, J., Liu, J., Ugrinovic, N., Feiszli, M., Malik, J., Dollar, P., Kitani, K.: Sam 3d body: Robust full-body human mesh recovery. arXiv preprint arXiv:2602.15989 (2026)
-
[72]
In: Advances in Neural Information Processing Systems (2021)
Yariv, L., Gu, J., Kasten, Y., Lipman, Y.: Volume rendering of neural implicit surfaces. In: Advances in Neural Information Processing Systems (2021)
2021
-
[73]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (June 2021)
Yu, T., Zheng, Z., Guo, K., Liu, P., Dai, Q., Liu, Y.: Function4d: Real-time hu- man volumetric capture from very sparse consumer rgbd sensors. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (June 2021)
2021
-
[74]
In: Proceedings of the Spe- cial Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers
Yu, Z., Li, Z., Bao, H., Yang, C., Zhou, X.: Humanram: Feed-forward human re- construction and animation model using transformers. In: Proceedings of the Spe- cial Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers. pp. 1–13 (2025)
2025
-
[75]
arXiv preprint arXiv:2406.19680 (2024)
Zhang, Y., Gu, J., Wang, L.W., Wang, H., Cheng, J., Zhu, Y., Zou, F.: Mimic- motion: High-quality human motion video generation with confidence-aware pose guidance. arXiv preprint arXiv:2406.19680 (2024)
-
[76]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhao, F., Yang, W., Zhang, J., Lin, P., Zhang, Y., Yu, J., Xu, L.: Humannerf: Efficiently generated human radiance field from sparse inputs. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 7743–7753 (June 2022) LUNA 21
2022
-
[77]
In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhao, J., Zhang, H.: Thin-plate spline motion model for image animation. In: Pro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 3657–3666 (2022)
2022
-
[78]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zheng, R., Li, P., Wang, H., Yu, T.: Learning visibility field for detailed 3d human reconstruction and relighting. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 216–226 (2023)
2023
-
[79]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
Zheng, S., Zhou, B., Shao, R., Liu, B., Zhang, S., Nie, L., Liu, Y.: Gps-gaussian: Generalizable pixel-wise 3d gaussian splatting for real-time human novel view syn- thesis. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
2024
-
[80]
IEEE transactions on pat- tern analysis and machine intelligence44(6), 3170–3184 (2021)
Zheng, Z., Yu, T., Liu, Y., Dai, Q.: Pamir: Parametric model-conditioned implicit representation for image-based human reconstruction. IEEE transactions on pat- tern analysis and machine intelligence44(6), 3170–3184 (2021)
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.