Knowledge Distillation for Low-Resource Open-source Text-to-SQL Model
Pith reviewed 2026-05-25 00:39 UTC · model grok-4.3
The pith
A task-specific knowledge base of schema details, abbreviations, business logic and query patterns improves Text-to-SQL results for large language models when labeled data is scarce.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Injecting a constructed task-specific knowledge base into synthetic data generation and inference enables large language models to produce more accurate, generalizable, and robust Text-to-SQL translations, especially when high-quality annotated pairs are limited.
What carries the argument
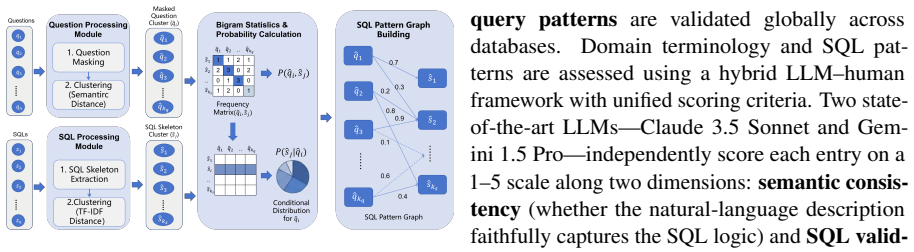
The task-specific knowledge base that encodes schema semantics, abbreviations, business logic, and query patterns; it supplies the content for generating grounded synthetic training examples and for retrieval at inference time.
If this is right
- Synthetic training data becomes more aligned with actual database constraints and business rules.
- Inference gains from on-the-fly retrieval of the same knowledge elements used in training.
- Gains appear for both open-source and closed-source models and are largest in domain-specific low-resource regimes.
- Generalization, robustness to schema variations, and adaptability to new domains all increase.
Where Pith is reading between the lines
- The same knowledge-base construction step could be reused to create evaluation sets that better reflect real deployment conditions.
- Explicit knowledge injection may complement continued scaling of model size when labeled data remains the bottleneck.
- The approach suggests a route to portable domain adaptation without retraining the entire model from scratch.
Load-bearing premise
A reliable task-specific knowledge base can be built and the synthetic examples it produces will be diverse enough and semantically aligned enough to improve model behavior over existing synthesis techniques.
What would settle it
On a held-out domain-specific database, training with the synthetic data produced by the knowledge base yields no improvement or a drop in execution accuracy relative to standard synthesis baselines.
Figures



read the original abstract
Text-to-SQL converts natural language questions into executable SQL queries, enabling non-technical users to access relational databases for analytics and intelligent data services. In real-world scenarios, performance is often constrained by low-resource settings, where high-quality annotated \texttt{<question, SQL>} pairs are scarce, particularly for domain-specific databases. Additional challenges include opaque schema definitions, abbreviations, and implicit business logic that are not explicitly encoded in the schema. Existing data synthesis and prompting techniques improve coverage but often fail to produce task-specific, semantically grounded examples aligned with database constraints. To address these challenges, we propose a knowledge-aware Text-to-SQL framework that constructs task-specific knowledge base including schema semantics, abbreviations, business logic, and query patterns, and injects them into both training and inference. This framework generates diverse, contextually grounded synthetic training data and enhances inference through targeted knowledge retrieval. Experiments on seven benchmarks, covering both general and domain-specific datasets, demonstrate that our approach substantially improves the performance of open-source and closed-source large language models in Text-to-SQL tasks, especially in low-resource domain-specific settings, enhancing generalization, robustness, and adaptability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a knowledge-aware Text-to-SQL framework that constructs a task-specific knowledge base including schema semantics, abbreviations, business logic, and query patterns. This knowledge is injected into both training (via generation of diverse, contextually grounded synthetic data) and inference (via targeted knowledge retrieval). The authors claim that experiments on seven benchmarks demonstrate that the approach substantially improves performance of open-source and closed-source LLMs on Text-to-SQL tasks, especially in low-resource domain-specific settings, while enhancing generalization, robustness, and adaptability.
Significance. If the claimed improvements are substantiated by detailed experiments, the framework could provide a useful method for addressing data scarcity and schema opacity in domain-specific Text-to-SQL by producing more semantically grounded synthetic examples than prior synthesis techniques. This would represent a practical advance for low-resource settings. The current text, however, supplies no quantitative evidence, baselines, ablations, or analysis, preventing any assessment of whether the result holds.
major comments (1)
- [Abstract] Abstract: the assertion that 'Experiments on seven benchmarks... demonstrate that our approach substantially improves the performance' supplies no quantitative results, baselines, ablation details, or error analysis. The central claim therefore cannot be evaluated from the manuscript.
minor comments (1)
- [Title and Abstract] Title and Abstract: the title highlights 'Knowledge Distillation' while the abstract describes a knowledge-base construction and injection approach without any reference to distillation; the relationship between the two should be clarified.
Simulated Author's Rebuttal
We thank the referee for their review. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that 'Experiments on seven benchmarks... demonstrate that our approach substantially improves the performance' supplies no quantitative results, baselines, ablation details, or error analysis. The central claim therefore cannot be evaluated from the manuscript.
Authors: We agree that the abstract would benefit from quantitative results to allow immediate evaluation of the claims. In the revised version we will add specific performance deltas (e.g., exact accuracy gains on the seven benchmarks versus the strongest baselines), a brief note on the ablation studies, and mention of the low-resource domain-specific improvements. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical framework for constructing task-specific knowledge bases and generating synthetic training data for Text-to-SQL in low-resource settings, validated through experiments on seven benchmarks. No equations, derivations, fitted parameters, or first-principles predictions appear in the abstract or are indicated as load-bearing in the provided context. Claims rest on experimental improvements rather than any self-definitional reductions, fitted inputs renamed as predictions, or self-citation chains. The method is presented as a proposed approach with independent empirical support, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
DeepSeek-Coder: When the Large Language Model Meets Programming -- The Rise of Code Intelligence
Question generation from SQL queries im- proves neural semantic parsing. InProceedings of the 2018 Conference on Empirical Methods in Natu- ral Language Processing, Brussels, Belgium, Octo- ber 31 - November 4, 2018, pages 1597–1607. Asso- ciation for Computational Linguistics. Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Towards complex text-to-sql in cross-domain database with intermediate representation. InPro- ceedings of the 57th Conference of the Association for Computational Linguistics, pages 4524–4535. Yiqun Hu, Yiyun Zhao, Jiarong Jiang, Wuwei Lan, Henghui Zhu, Anuj Chauhan, Alexander Hanbo Li, Lin Pan, Jun Wang, Chung-Wei Hang, Sheng Zhang, Jiang Guo, and et al....
work page 2023
-
[3]
Qwen2.5-Coder Technical Report
Qwen2.5-coder technical report.CoRR, abs/2409.12186. Alice Johnson and Bob Lee. 2023. Sciencebenchmark: A diverse query set for interdisciplinary text-to-sql evaluation.Journal of Artificial Intelligence Re- search, 81:123–145. George Katsogiannis-Meimarakis and Georgia Koutrika. 2023. A survey on deep learning approaches for text-to-sql.VLDB J., 32(4):90...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
InProceedings of the 29th International Conference on Computational Linguistics, pages 1593–1603
Addressing limitations of encoder-decoder based approach to text-to-sql. InProceedings of the 29th International Conference on Computational Linguistics, pages 1593–1603. Mohammadreza Pourreza and Davood Rafiei
-
[5]
Mohammadreza Pourreza, Ruoxi Sun, Hailong Li, Lesly Miculicich, Tomas Pfister, and Sercan O Arik
Din-sql: Decomposed in-context learning of text-to-sql with self-correction.Preprint, arXiv:2304.11015. Mohammadreza Pourreza, Ruoxi Sun, Hailong Li, Lesly Miculicich, Tomas Pfister, and Sercan O Arik
-
[6]
Sql-gen: Bridging the dialect gap for text- to-sql via synthetic data and model merging.arXiv preprint arXiv:2408.12733. Mohammadreza Pourreza, Shayan Talaei, Ruoxi Sun, Xingchen Wan, Hailong Li, Azalia Mirhoseini, Amin Saberi, Sercan Arik, and 1 others. 2025. Reasoning- SQL: Reinforcement learning with SQL tailored partial rewards for reasoning-enhanced ...
-
[7]
Dbpal: A fully pluggable NL2SQL train- ing pipeline. InProceedings of the 2020 Interna- tional Conference on Management of Data, SIGMOD Conference 2020, online conference [Portland, OR, USA], June 14-19, 2020, pages 2347–2361. ACM. Kun Wu, Lijie Wang, Zhenghua Li, Ao Zhang, Xinyan Xiao, Hua Wu, Min Zhang, and Haifeng Wang. 2021. Data augmentation with hie...
-
[8]
Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning
Seq2sql: Generating structured queries from natural language using reinforcement learning. CoRR, abs/1709.00103. 12 A Experiment Setup Benchmarks.We utilized three distinct benchmark sets to assess our proposed method. (1)Standard Benchmarks:We use the BIRD dataset (Li et al., 2023c) (BIRD-dev split, 1,534 examples) and Spider (Yu et al., 2018b) (Spider-d...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[9]
to evaluate performance in specialized domains. EHRSQL consists of 1,008 clinical queries, while ScienceBenchmark includes 299 queries across disciplines such as policy, astronomy, and oncology. Baselines.We compare our approach with a diverse set of models and enhancement strategies. ForICL- based baselines, we evaluate Knowledge-Enhanced In-Context Lear...
work page 2023
-
[10]
If the column name contains special characters such as spaces, please use`to enclose it
-
[11]
Exactly select the columns that the user wants to select, and do not select other unnesssary columns
-
[12]
Once you need to subquery, please use CTE that starts with the WITH keyword to wrap the subquery and give it a name
-
[13]
The final Answer Query **must** be wrapped in Markdown format using triple backticks and the`sql`tag
-
[14]
You must reason step by step using a compositional approach. Your reasoning process should follow a **minimal set of steps** selected from a predefined library of 10 reasoning components (listed below). 8### Reasoning Components (Choose From):
-
[15]
Constraint Extraction
-
[16]
Aggregation & Grouping Reasoning
-
[17]
Alias & Expression Handling
-
[18]
Column Count for Data Generation Methods
Nested/Subquery Reasoning 19### DATABASE SCHEMA 20$ { D AT A B AS E _S C H EM A } 21### DOMAIN KNOWLEDGE 22${DOMAIN_KG} 23### RELEVANT QA PAIRS 24${QA_PAIRS} 25### QUESTION 26${USER_ QUESTION } 27Please think step by step: D Prompt for inference prompt 16 Table 6: Token and Time Costs vs. Column Count for Data Generation Methods. Category #A VG.Columns To...
work page 1914
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.