Algebraic Priors for Approximately Equivariant Networks
Pith reviewed 2026-05-22 00:03 UTC · model grok-4.3
The pith
For an equivariant encoder over a finite group, the latent space must almost surely contain one copy of its regular representation for each linearly independent data orbit.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For an equivariant encoder over a finite group, the latent space must almost surely contain one copy of its regular representation for each linearly independent data orbit. The authors leverage this fact by imposing the regular representation as an inductive bias through an auxiliary loss that adds no learnable parameters. Extensive evaluations show the resulting models match or outperform specialized equivariant networks, including some designed for infinite groups, while an ablation confirms the regular representation outperforms trivial and defining representation baselines.
What carries the argument
The regular representation of the finite group, imposed as an auxiliary loss on the latent space to enforce the required algebraic structure without adding parameters.
If this is right
- The auxiliary loss provides a parameter-free way to inject finite-group symmetry into existing networks.
- The same loss can be used during training to encourage approximate equivariance.
- The approach applies empirically even when the underlying group is infinite.
- Regular representation consistently outperforms both trivial and defining representations in ablation tests.
Where Pith is reading between the lines
- The method could reduce the engineering effort needed to build symmetry-aware models for new data domains.
- When orbits are known to be dependent, a modified loss or representation choice might still be derived from the same representation-theoretic starting point.
- The auxiliary loss might be combined with other regularizers to handle groups that are only partially known or approximate.
Load-bearing premise
The encoder is exactly equivariant or trained toward equivariance, and the data orbits are treated as linearly independent.
What would settle it
Train an exactly equivariant encoder on a dataset whose orbits are linearly dependent and check whether the latent space still contains one copy of the regular representation per orbit.
Figures






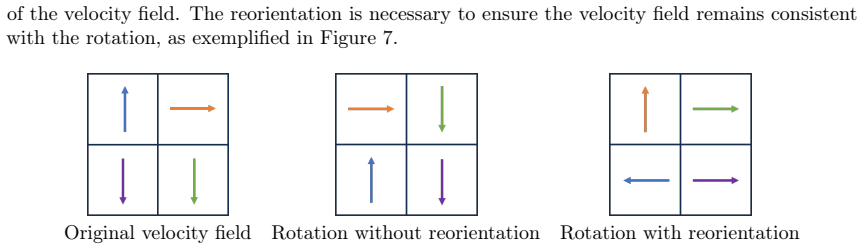
read the original abstract
Equivariant neural networks incorporate symmetries through group actions, embedding them as an inductive bias to improve performance. Existing methods learn an equivariant action on the latent space, or design architectures that are equivariant by construction. These approaches often deliver strong empirical results but can involve architecture-specific constraints, large parameter counts, and high computational cost. We challenge the paradigm of complex equivariant architectures with a parameter-free approach grounded in group representation theory. We prove that for an equivariant encoder over a finite group, the latent space must almost surely contain one copy of its regular representation for each linearly independent data orbit, which we explore with a number of empirical studies. Leveraging this foundational algebraic insight, we impose the group's regular representation as an inductive bias via an auxiliary loss, adding no learnable parameters. Our extensive evaluation shows that this method matches or outperforms specialized models in several cases, even those for infinite groups. We further validate our choice of the regular representation through an ablation study, showing it consistently outperforms defining and trivial group representation baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a parameter-free approach to approximately equivariant networks based on group representation theory. The central claim is that an equivariant encoder over a finite group must almost surely include one copy of the regular representation in its latent space for each linearly independent data orbit. The authors derive an auxiliary loss from this insight to enforce the regular representation as an inductive bias and validate the method through empirical studies on various tasks, showing competitive or superior performance compared to specialized equivariant architectures, along with an ablation confirming the choice of regular representation.
Significance. If the theoretical result is correct, this work offers a significant simplification for building symmetry-aware models by avoiding the need for custom architectures or extra parameters. The empirical evidence that this simple prior can match or exceed more elaborate methods, including for infinite groups, highlights its potential impact. The inclusion of a proof grounded in representation theory and a dedicated ablation study are strengths that enhance the paper's contribution to the field of equivariant machine learning.
major comments (2)
- The proof that the latent space contains the regular representation assumes exact equivariance and linearly independent orbits. Given that the method is applied to approximately equivariant networks, a discussion or bound on how deviations from exact equivariance affect the presence of the regular representation would be necessary to fully support the central claim.
- While the ablation study shows the regular representation outperforms trivial and defining representations, the manuscript should report variance across multiple runs or statistical tests to confirm that the observed improvements are significant and not due to random variation.
minor comments (2)
- The phrase 'a number of empirical studies' is vague; specifying the number and types of experiments would improve the summary.
- Ensure that all figures and tables are clearly labeled and referenced in the text for better readability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and positive recommendation for minor revision. We address each major comment below.
read point-by-point responses
-
Referee: The proof that the latent space contains the regular representation assumes exact equivariance and linearly independent orbits. Given that the method is applied to approximately equivariant networks, a discussion or bound on how deviations from exact equivariance affect the presence of the regular representation would be necessary to fully support the central claim.
Authors: The theoretical result establishes that exact equivariance implies the presence of the regular representation in the latent space. For the approximately equivariant setting, our approach uses an auxiliary loss to impose this as a soft prior. We will add a new subsection discussing the robustness to approximate equivariance, noting that the representation theory result provides a strong inductive bias even when equivariance is not exact, as supported by our empirical results on tasks where perfect equivariance is not achieved. While a rigorous bound on the deviation is challenging without additional assumptions, we will provide a qualitative analysis based on the stability of representations under small perturbations. revision: partial
-
Referee: While the ablation study shows the regular representation outperforms trivial and defining representations, the manuscript should report variance across multiple runs or statistical tests to confirm that the observed improvements are significant and not due to random variation.
Authors: We agree that this would strengthen the paper. We will update the ablation study and main results to include standard deviations computed over multiple random seeds and add statistical significance tests (such as Wilcoxon signed-rank tests) where appropriate. revision: yes
Circularity Check
Core algebraic claim follows from standard representation theory; no load-bearing circularity
full rationale
The paper's central result—that an equivariant encoder's latent space must almost surely contain one copy of the regular representation per linearly independent data orbit—is presented as a direct consequence of standard facts from finite group representation theory applied to the definition of equivariance. The auxiliary loss is then introduced as a parameter-free way to impose this structure. No step reduces a prediction or uniqueness claim to a fitted input, self-citation chain, or ansatz smuggled from prior work by the same authors. The derivation remains self-contained against external benchmarks in representation theory, yielding only a minor self-citation score of 2 with no impact on the independence of the main claim.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard facts from the representation theory of finite groups, including the structure of the regular representation and its decomposition properties.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We prove that for an equivariant encoder over a finite group, the latent space must almost surely contain one copy of its regular representation for each linearly independent data orbit
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Hugo Caselles-Dupré, Michael Garcia-Ortiz, and David Filliat. Symmetry-based disentangled representation learning requires interaction with environments, 2019.arXiv:1904.00243
-
[2]
Taco S. Cohen and Max Welling. Steerable CNNs, 2016.arXiv:1612.08498
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
The MNIST database of handwritten digit images for machine learning research
Li Deng. The MNIST database of handwritten digit images for machine learning research. IEEE Signal Processing Magazine, 29(6):141–142, 2012
work page 2012
-
[4]
Equivariant neural rendering, 2020.arXiv:2006.07630
Emilien Dupont, Miguel Angel Bautista, Alex Colburn, Aditya Sankar, Carlos Guestrin, Josh Susskind, and Qi Shan. Equivariant neural rendering, 2020.arXiv:2006.07630
-
[5]
Residual pathway priors for soft equivariance constraints
Marc Finzi, Gregory Benton, and Andrew G Wilson. Residual pathway priors for soft equivariance constraints. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pages 30037–30049. Curran Associates, Inc., 2021. URL: https://proceedings.neurips.cc/ paper_files/p...
work page 2021
-
[6]
Universal eigenvarieties, triangu line Galois representations, and p-adic Lang- lands functoriality
William Fulton and Joe Harris. Representation Theory. Springer New York, 2004. doi: 10.1007/978-1-4612-0979-9. 10
-
[7]
Yacov Hel-Or and Patrick C Teo. Canonical decomposition of steerable functions.Journal of Mathematical Imaging and Vision, 9:83–95, 1998
work page 1998
-
[8]
Towards a Definition of Disentangled Representations
Irina Higgins, David Amos, David Pfau, Sébastien Racanière, Loïc Matthey, Danilo Rezende, and Alexander Lerchner. Towards a definition of disentangled representations, 2018.arXiv: 1812.02230
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[9]
PhiFlow: A differentiable PDE solving framework for deep learning via physical simulations
Philipp Holl, Vladlen Koltun, Kiwon Um, and Nils Thuerey. PhiFlow: A differentiable PDE solving framework for deep learning via physical simulations. InNeurIPS workshop, volume 2, 2020
work page 2020
-
[10]
Turbulence, coherent structures, dynamical systems and symmetry
Philip Holmes. Turbulence, coherent structures, dynamical systems and symmetry. Cambridge University Press, 2012
work page 2012
-
[11]
Cambridge University Press, 2001.doi:10.1017/cbo9780511814532
Gordon James and Martin Liebeck.Representations and Characters of Groups. Cambridge University Press, 2001.doi:10.1017/cbo9780511814532
-
[12]
Learning group actions on latent representations
Yinzhu Jin, Aman Shrivastava, and Tom Fletcher. Learning group actions on latent representations. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL: https://openreview.net/forum?id=HGNTcy4eEp
work page 2024
-
[13]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization, 2017. URL: https://arxiv.org/abs/1412.6980, arXiv:1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[14]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. 2009. URL: https://api.semanticscholar.org/CorpusID:18268744
work page 2009
-
[15]
MIT Press, Cambridge, MA, USA, 1998
Yann LeCun and Yoshua Bengio.Convolutional networks for images, speech, and time series, page 255–258. MIT Press, Cambridge, MA, USA, 1998
work page 1998
-
[16]
Nimish Magre and Nicholas Brown. Typography-MNIST (TMNIST): an MNIST-style image dataset to categorize glyphs and font-styles, 2022.arXiv:2202.08112
-
[17]
Robin Quessard, Thomas Barrett, and William Clements. Learning disentangled representations and group structure of dynamical environments.Advances in Neural Information Processing Systems, 33:19727–19737, 2020.arXiv:2002.06991
-
[18]
Christopher Shorten and Taghi M. Khoshgoftaar. A survey on image data augmentation for deep learning. Journal of Big Data, 6:60, 2019. doi:10.1186/s40537-019-0197-0
-
[19]
A probabilistic approach to learning the degree of equivariance in steerable CNNs
Lars Veefkind and Gabriele Cesa. A probabilistic approach to learning the degree of equivariance in steerable CNNs. In41st International Conference on Machine Learning (ICML 2024), 2024. URL: https://openreview.net/forum?id=49vHLSxjzy, arXiv:2406.03946
-
[20]
Equivariant Q learning in spatial action spaces
Dian Wang, Robin Walters, Xupeng Zhu, and Robert Platt. Equivariant Q learning in spatial action spaces. In 5th Annual Conference on Robot Learning, 2021. URL: https://openreview.net/forum?id=IScz42A3iCI
work page 2021
-
[21]
Approximately equivariant networks for imperfectly symmetric dynamics
Rui Wang, Robin Walters, and Rose Yu. Approximately equivariant networks for imperfectly symmetric dynamics. InInternational Conference on Machine Learning, pages 23078–23091. PMLR, 2022. arXiv:2201.11969
-
[22]
Self-supervised learning disentangled group representation as feature
Tan Wang, Zhongqi Yue, Jianqiang Huang, Qianru Sun, and Hanwang Zhang. Self-supervised learning disentangled group representation as feature. Advances in Neural Information Processing Systems, 34:18225–18240, 2021.arXiv:2110.15255
-
[23]
Disentangled representation learning, 2024
Xin Wang, Hong Chen, Si’ao Tang, Zihao Wu, and Wenwu Zhu. Disentangled representation learning, 2024. arXiv:2211.11695
-
[24]
General E(2)-Equivariant Steerable CNNs
Maurice Weiler and Gabriele Cesa. General E(2)-Equivariant Steerable CNNs. InConference on Neural Information Processing Systems (NeurIPS), 2019. arXiv:1911.08251. 11
-
[25]
Jiancheng Yang, Rui Shi, Donglai Wei, Zequan Liu, Lin Zhao, Bilian Ke, Hanspeter Pfister, and Bingbing Ni. Medmnist v2 - a large-scale lightweight benchmark for 2d and 3d biomedical image classification.Scientific Data, 10(1), January 2023.doi:10.1038/s41597-022-01721-8
-
[26]
Tao Yang, Xuanchi Ren, Yuwang Wang, Wenjun Zeng, and Nanning Zheng. Towards building a group-based unsupervised representation disentanglement framework, 2022.arXiv:2102.10303. 12 A Code The code to run all the experiments in this paper is available at the following location: • https://github.com/rick-ali/parameter-free-approximate-equivariance In the REA...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.