AtomMem: Building Simple and Effective Memory System for LLM Agents via Atomic Facts
Pith reviewed 2026-06-26 17:49 UTC · model grok-4.3
The pith
AtomMem extracts atomic facts to create stable long-term memory for LLM agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
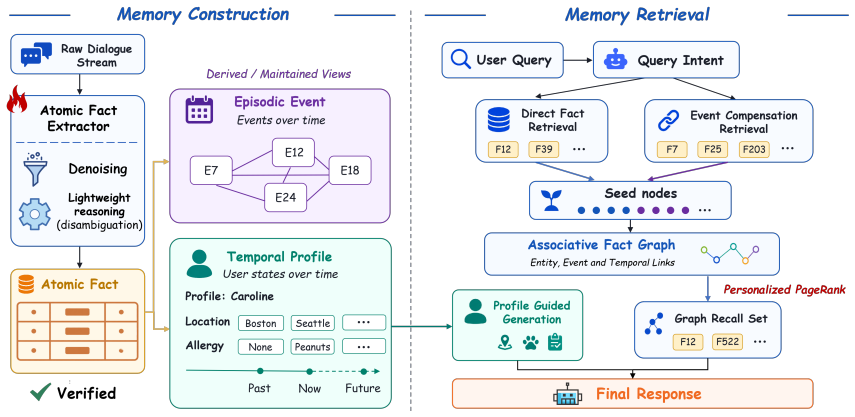
AtomMem introduces a Fact Executor that selectively extracts high-value atomic facts from long-form interactions to serve as efficient memory representations. It organizes these facts into hierarchical event structures and temporal profiles for coherent contexts and evolving user attributes, activating an associative memory graph during retrieval.
What carries the argument
The Fact Executor, which selectively extracts high-value atomic facts from long-form interactions to enable value-dense and stable memory storage.
If this is right
- Allows LLM agents to accumulate and reuse information over multiple sessions without context window limits.
- Organizes memories hierarchically to capture episodic contexts and track user attributes over time.
- Uses an associative memory graph to connect fragmented memories during retrieval.
- Achieves state-of-the-art performance on reasoning tasks in the LoCoMo benchmark.
Where Pith is reading between the lines
- This approach could lower the computational cost of maintaining long-term agent memory compared to full conversation logs.
- The method might generalize to other sequential data processing tasks beyond LLM agents.
- Testing on additional benchmarks could reveal if the hierarchical organization provides advantages in specific domains like personal assistance.
Load-bearing premise
The Fact Executor can reliably and selectively extract high-value atomic facts from long-form interactions in a manner that is both value-dense and free of the instability seen in unconstrained memory updates.
What would settle it
A direct comparison where the Fact Executor is replaced with random or full-context storage, showing whether performance on LoCoMo drops significantly.
Figures








read the original abstract
Large language models (LLMs) demonstrate strong reasoning and generation abilities, but their fixed context windows limit long-term information accumulation and reuse across multi-session interactions. Existing memory-augmented systems often construct memory in a coarse and unstable manner, relying on inefficient memory representations or unstable unconstrained updates. To address these challenges, we propose AtomMem, a long-term memory system designed for value-dense storage and stable memory evolution. AtomMem introduces a Fact Executor, which selectively extracts high value atomic facts from long form interactions to serve as highly efficient memory representations. Subsequently, AtomMem organizes these facts into hierarchical event structures and temporal profiles, capturing coherent episodic contexts and tracking dynamically evolving user attributes over time. During retrieval, the system activates an associative memory graph to connect fragmented memories. Experiments on the LoCoMo benchmark confirm that AtomMem achieves state-of-the-art performance across various reasoning tasks, offering a scalable and economically viable solution for deploying intelligent personalized agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AtomMem, a long-term memory system for LLM agents. It introduces a Fact Executor to selectively extract high-value atomic facts from long-form interactions as efficient memory representations, organizes these into hierarchical event structures and temporal profiles for episodic context and user attribute tracking, and employs an associative memory graph for retrieval. The central claim is that experiments on the LoCoMo benchmark demonstrate state-of-the-art performance across reasoning tasks, providing a scalable solution for personalized agents.
Significance. If the SOTA results on LoCoMo are substantiated with proper controls, AtomMem could offer a practical advance in stable, value-dense memory for multi-session LLM agents, addressing fixed context limits. The atomic-fact approach and hierarchical organization represent a targeted design choice worth evaluating against existing memory-augmented systems.
major comments (2)
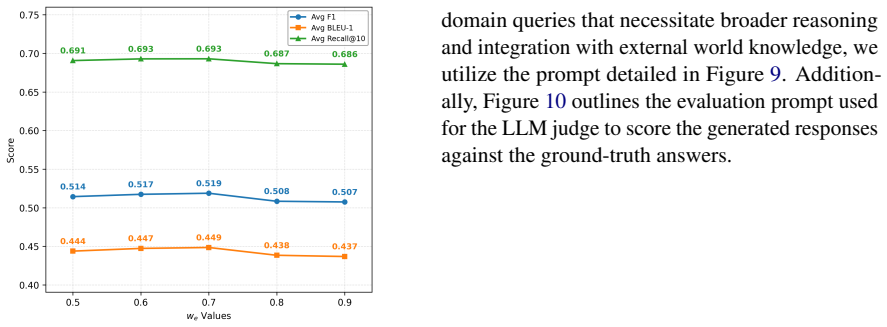
- [Abstract / Experiments] Abstract and Experiments section: The claim that AtomMem achieves state-of-the-art performance on the LoCoMo benchmark supplies no baselines, metrics, error bars, ablation studies, or method details, so the central experimental result cannot be evaluated from the manuscript.
- [§3] §3 (Fact Executor description): The Fact Executor is asserted to reliably and selectively extract high-value atomic facts in a manner free of instability seen in unconstrained updates, but the manuscript provides no mechanism details, selection criteria, or empirical validation of this stability property, which is load-bearing for both the design and the SOTA claim.
minor comments (1)
- [Abstract] Abstract: 'long form interactions' and 'high value atomic facts' should be hyphenated for consistency with technical writing.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: The claim that AtomMem achieves state-of-the-art performance on the LoCoMo benchmark supplies no baselines, metrics, error bars, ablation studies, or method details, so the central experimental result cannot be evaluated from the manuscript.
Authors: We agree that the current manuscript does not supply baselines, metrics, error bars, ablation studies, or sufficient method details to allow evaluation of the SOTA claim on LoCoMo. This is a substantive gap. In revision we will expand the Experiments section with full baseline comparisons, all metrics reported with error bars, ablation studies, and complete method descriptions; the abstract will be updated to summarize these additions accurately. revision: yes
-
Referee: [§3] §3 (Fact Executor description): The Fact Executor is asserted to reliably and selectively extract high-value atomic facts in a manner free of instability seen in unconstrained updates, but the manuscript provides no mechanism details, selection criteria, or empirical validation of this stability property, which is load-bearing for both the design and the SOTA claim.
Authors: We acknowledge that §3 currently offers only a high-level description and lacks explicit mechanism details, selection criteria, and empirical validation of stability. These elements are indeed central. We will revise §3 to include a precise account of the Fact Executor’s operation, the criteria used to identify high-value atomic facts, and supporting empirical analyses demonstrating improved stability relative to unconstrained updates. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an engineering system (AtomMem with Fact Executor, hierarchical structures, and associative graph) validated by benchmark experiments on LoCoMo. No equations, derivations, fitted parameters, or first-principles claims appear in the provided text. Central performance claims rest on external empirical evaluation rather than any self-referential reduction or self-citation chain. This is the expected outcome for a non-derivational systems paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2024. https://openreview.net/forum?id=hSyW5go0v8 Self- RAG : Learning to retrieve, generate, and critique through self-reflection . In The Twelfth International Conference on Learning Representations
2024
-
[3]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. 2025. https://doi.org/10.48550/arXiv.2504.19413 Mem0: Building production-ready AI agents with scalable long-term memory . Preprint, arXiv:2504.19413
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.19413 2025
-
[4]
Jizhan Fang, Xinle Deng, Haoming Xu, Ziyan Jiang, Yuqi Tang, Ziwen Xu, Shumin Deng, Yunzhi Yao, Mengru Wang, Shuofei Qiao, Huajun Chen, and Ningyu Zhang. 2026. https://openreview.net/forum?id=dyJ0GWpjJB LightMem : Lightweight and efficient memory-augmented generation . In The Fourteenth International Conference on Learning Representations
2026
-
[5]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang. 2023. https://doi.org/10.48550/arXiv.2312.10997 Retrieval-augmented generation for large language models: A survey . Preprint, arXiv:2312.10997
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.10997 2023
-
[6]
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. 2020. https://proceedings.mlr.press/v119/guu20a.html Retrieval augmented language model pre-training . In Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 3929--3938. PMLR
2020
-
[9]
u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K \"u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \"a schel, Sebastian Riedel, and Douwe Kiela. 2020. https://proceedings.neurips.cc/paper/2020/hash/6b493230205f780e1bc26945df7481e5-Abstract.html Retrieval-augmented generation for knowledge-intensive NLP ...
2020
-
[10]
Lei Liu, Xiaoyan Yang, Yue Shen, Binbin Hu, Zhiqiang Zhang, Jinjie Gu, and Guannan Zhang. 2023. https://doi.org/10.48550/arXiv.2311.08719 Think-in-memory: Recalling and post-thinking enable LLM s with long-term memory . Preprint, arXiv:2311.08719
-
[11]
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. https://doi.org/10.1162/tacl_a_00638 Lost in the middle: How language models use long contexts . Transactions of the Association for Computational Linguistics, 12:157--173
-
[12]
Shuochen Liu, Junyi Zhu, Long Shu, Junda Lin, Yuhao Chen, Haotian Zhang, Chao Zhang, Derong Xu, Jia Li, Bo Tang, Zhiyu Li, Feiyu Xiong, Enhong Chen, and Tong Xu. 2026. https://doi.org/10.48550/arXiv.2603.23231 PERMA : Benchmarking personalized memory agents via event-driven preference and realistic task environments . Preprint, arXiv:2603.23231
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2603.23231 2026
-
[14]
Ali Modarressi, Ayyoob Imani, Mohsen Fayyaz, and Hinrich Sch \"u tze. 2023. https://doi.org/10.48550/arXiv.2305.14322 RET-LLM : Towards a general read-write memory for large language models . Preprint, arXiv:2305.14322
-
[15]
Rodrigo Nogueira and Kyunghyun Cho. 2019. https://doi.org/10.48550/arXiv.1901.04085 Passage re-ranking with BERT . Preprint, arXiv:1901.04085
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1901.04085 2019
-
[17]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. 2023. https://doi.org/10.48550/arXiv.2310.08560 MemGPT : Towards LLM s as operating systems . Preprint, arXiv:2310.08560
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.08560 2023
-
[21]
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. 2025. https://doi.org/10.48550/arXiv.2410.10813 LongMemEval : Benchmarking chat assistants on long-term interactive memory . In The Thirteenth International Conference on Learning Representations
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.10813 2025
-
[22]
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, and 1 others. 2023. https://doi.org/10.48550/arXiv.2309.07864 The rise and potential of large language model based agents: A survey . Preprint, arXiv:2309.07864
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.07864 2023
-
[23]
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2024. https://doi.org/10.48550/arXiv.2309.17453 Efficient streaming language models with attention sinks . In The Twelfth International Conference on Learning Representations
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.17453 2024
-
[24]
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. 2025. https://doi.org/10.48550/arXiv.2502.12110 A-MEM : Agentic memory for LLM agents . In Advances in Neural Information Processing Systems
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.12110 2025
-
[25]
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. 2023. https://doi.org/10.48550/arXiv.2305.10250 MemoryBank : Enhancing large language models with long-term memory . Preprint, arXiv:2305.10250
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.10250 2023
-
[26]
Zijian Zhou, Ao Qu, Zhaoxuan Wu, Sunghwan Kim, Alok Prakash, Daniela Rus, Jinhua Zhao, Bryan Kian Hsiang Low, and Paul Pu Liang. 2025. https://doi.org/10.48550/arXiv.2506.15841 MEM1 : Learning to synergize memory and reasoning for efficient long-horizon agents . Preprint, arXiv:2506.15841
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.15841 2025
-
[27]
Xu, Wujiang and Liang, Zujie and Mei, Kai and Gao, Hang and Tan, Juntao and Zhang, Yongfeng , booktitle =. 2025 , url =. 2502.12110 , archivePrefix =
Pith/arXiv arXiv 2025
-
[28]
Mem0: Building Production-Ready
Chhikara, Prateek and Khant, Dev and Aryan, Saket and Singh, Taranjeet and Yadav, Deshraj , year =. Mem0: Building Production-Ready. 2504.19413 , archivePrefix =
-
[29]
Think-in-Memory: Recalling and Post-thinking Enable
Liu, Lei and Yang, Xiaoyan and Shen, Yue and Hu, Binbin and Zhang, Zhiqiang and Gu, Jinjie and Zhang, Guannan , year =. Think-in-Memory: Recalling and Post-thinking Enable. 2311.08719 , archivePrefix =
-
[30]
Zhong, Wanjun and Guo, Lianghong and Gao, Qiqi and Ye, He and Wang, Yanlin , year =. 2305.10250 , archivePrefix =
-
[31]
2023 , eprint =
Modarressi, Ali and Imani, Ayyoob and Fayyaz, Mohsen and Sch. 2023 , eprint =
2023
-
[32]
Hu, Chenxu and Fu, Jie and Du, Chenzhuang and Luo, Simian and Zhao, Junbo and Zhao, Hang , year =. 2306.03901 , archivePrefix =
-
[33]
Kang, Jiazheng and Ji, Mingming and Zhao, Zhe and Bai, Ting , booktitle =. Memory. 2025 , address =. doi:10.18653/v1/2025.emnlp-main.1318 , url =
-
[34]
and Stoica, Ion and Gonzalez, Joseph E
Packer, Charles and Wooders, Sarah and Lin, Kevin and Fang, Vivian and Patil, Shishir G. and Stoica, Ion and Gonzalez, Joseph E. , year =. 2310.08560 , archivePrefix =
-
[35]
Evaluating Very Long-Term Conversational Memory of LLM Agents
Maharana, Adyasha and Lee, Dong-Ho and Tulyakov, Sergey and Bansal, Mohit and Barbieri, Francesco and Fang, Yuwei , booktitle =. Evaluating Very Long-Term Conversational Memory of. 2024 , address =. doi:10.18653/v1/2024.acl-long.747 , url =
-
[36]
2023 , eprint =. doi:10.48550/arXiv.2303.08774 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2023
-
[37]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
Bubeck, S. Sparks of Artificial General Intelligence: Early Experiments with. 2023 , eprint =. doi:10.48550/arXiv.2303.12712 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.12712 2023
-
[38]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, Hugo and Martin, Louis and Stone, Kevin and Albert, Peter and Almahairi, Amjad and Babaei, Yasmine and Bashlykov, Nikolay and Batra, Soumya and Bhargava, Prajjwal and Bhosale, Shruti and others , year =. doi:10.48550/arXiv.2307.09288 , url =. 2307.09288 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.09288
-
[39]
Transactions of the Association for Computational Linguistics , volume =
Lost in the Middle: How Language Models Use Long Contexts , author =. Transactions of the Association for Computational Linguistics , volume =. 2024 , doi =
2024
-
[40]
The Twelfth International Conference on Learning Representations , year =
Efficient Streaming Language Models with Attention Sinks , author =. The Twelfth International Conference on Learning Representations , year =. 2309.17453 , archivePrefix =
-
[41]
Retrieval-Augmented Generation for Knowledge-Intensive
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems , volume =. 2020 , url =
2020
-
[42]
Proceedings of the 37th International Conference on Machine Learning , pages =
Retrieval Augmented Language Model Pre-Training , author =. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , volume =
2020
-
[43]
2023 , eprint =
Retrieval-Augmented Generation for Large Language Models: A Survey , author =. 2023 , eprint =
2023
-
[44]
Nogueira, Rodrigo and Cho, Kyunghyun , year =. Passage Re-ranking with. 1901.04085 , archivePrefix =
Pith/arXiv arXiv 1901
-
[45]
Active Retrieval Augmented Generation
Active Retrieval Augmented Generation , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , month = dec, pages =. 2023 , address =. doi:10.18653/v1/2023.emnlp-main.495 , url =
-
[46]
Asai, Akari and Wu, Zeqiu and Wang, Yizhong and Sil, Avirup and Hajishirzi, Hannaneh , booktitle =. Self-. 2024 , url =
2024
-
[47]
Generative Agents: Interactive Simulacra of Human Behavior , author =. Proceedings of the 36th Annual. 2023 , publisher =. doi:10.1145/3586183.3606763 , url =
-
[48]
2023 , eprint =
The Rise and Potential of Large Language Model Based Agents: A Survey , author =. 2023 , eprint =
2023
-
[49]
In Prospect and Retrospect: Reflective Memory Management for Long-term Personalized Dialogue Agents
In Prospect and Retrospect: Reflective Memory Management for Long-term Personalized Dialogue Agents , author =. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , month = jul, pages =. 2025 , address =. doi:10.18653/v1/2025.acl-long.413 , url =
-
[50]
2025 , eprint =
Zep: A Temporal Knowledge Graph Architecture for Agent Memory , author =. 2025 , eprint =
2025
-
[51]
Yan, Sikuan and Yang, Xiufeng and Huang, Zuchao and Nie, Ercong and Ding, Zifeng and Li, Zonggen and Ma, Xiaowen and Bi, Jinhe and Kersting, Kristian and Pan, Jeff Z. and Sch. Memory-. 2025 , eprint =
2025
-
[52]
Zhou, Zijian and Qu, Ao and Wu, Zhaoxuan and Kim, Sunghwan and Prakash, Alok and Rus, Daniela and Zhao, Jinhua and Low, Bryan Kian Hsiang and Liang, Paul Pu , year =. 2506.15841 , archivePrefix =
-
[53]
Wu, Di and Wang, Hongwei and Yu, Wenhao and Zhang, Yuwei and Chang, Kai-Wei and Yu, Dong , booktitle =. 2025 , url =. 2410.10813 , archivePrefix =
Pith/arXiv arXiv 2025
-
[54]
Know Me, Respond to Me: Benchmarking
Jiang, Bowen and Hao, Zhuoqun and Cho, Young Min and Li, Bryan and Yuan, Yuan and Chen, Sihao and Ungar, Lyle and Taylor, Camillo Jose and Roth, Dan , booktitle =. Know Me, Respond to Me: Benchmarking. 2025 , url =. 2504.14225 , archivePrefix =
arXiv 2025
-
[55]
Liu, Shuochen and Zhu, Junyi and Shu, Long and Lin, Junda and Chen, Yuhao and Zhang, Haotian and Zhang, Chao and Xu, Derong and Li, Jia and Tang, Bo and Li, Zhiyu and Xiong, Feiyu and Chen, Enhong and Xu, Tong , year =. 2603.23231 , archivePrefix =
-
[56]
2026 , eprint =
From Recall to Forgetting: Benchmarking Long-Term Memory for Personalized Agents , author =. 2026 , eprint =
2026
-
[57]
2026 , url =
Fang, Jizhan and Deng, Xinle and Xu, Haoming and Jiang, Ziyan and Tang, Yuqi and Xu, Ziwen and Deng, Shumin and Yao, Yunzhi and Wang, Mengru and Qiao, Shuofei and Chen, Huajun and Zhang, Ningyu , booktitle =. 2026 , url =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.