When Is a Columnar Scan Bandwidth-Bound? A Decode-Throughput Law and Its Cross-Hardware Validation
Pith reviewed 2026-06-26 09:47 UTC · model grok-4.3
The pith
A decoder's value throughput stays constant across bit widths, so the bandwidth fraction a columnar scan achieves follows a one-parameter law.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A decoder's value throughput T_dec is essentially independent of bit-width b because it is set by the decode layout and strategy rather than the number of bits per value. Consequently the achieved bandwidth fraction obeys f = min(1, T_dec * b / (8*beta)) with the compute-to-bandwidth ridge at b* = 8*beta/T_dec. Fitting one T_dec per strategy reproduces measured fractions with median error 0.027 on x86/AVX2 and 0.003 on Apple M4/NEON.
What carries the argument
The decode-throughput law f = min(1, T_dec * b / (8*beta)) that converts a constant per-strategy decode rate into a predicted bandwidth fraction.
If this is right
- Scans become bandwidth-bound only above a predictable bit-width ridge that depends on the machine's bandwidth beta.
- The same fitted T_dec predicts bandwidth usage on a second machine once its bandwidth is inserted into the law.
- Higher-T_dec hand-tuned decoders push the bandwidth-bound regime to narrower bit widths.
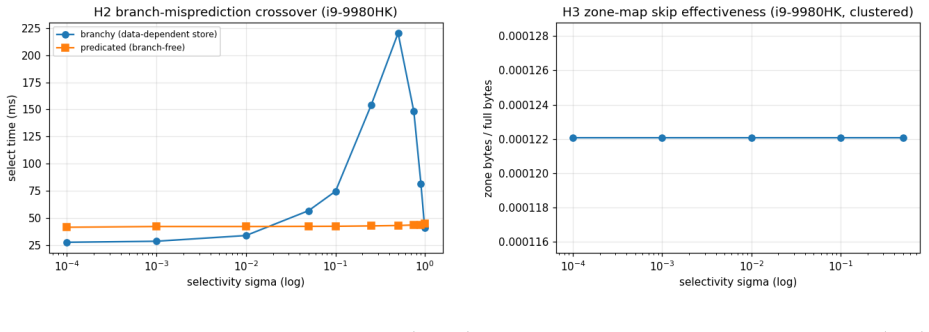
- Branch-free predicate evaluation outperforms branchy code only inside a mid-selectivity band set by the sigma(1-sigma) misprediction curve.
- Zone-map skipping helps according to data clustering rather than selectivity alone.
Where Pith is reading between the lines
- The law could guide automatic choice of encoding width to reach the bandwidth roofline on a given machine.
- Once T_dec is high enough that the ridge falls below the narrowest practical bit width, further decode-speed improvements yield little bandwidth gain.
- The independence of T_dec from b may fail on architectures where instruction throughput scales with bit width, providing a clear test on additional hardware.
Load-bearing premise
That a decoder's throughput measured on one set of bit widths remains constant when bit width changes.
What would settle it
Measure the value decode rate T_dec at bit widths from 1 to 32 bits under fixed encoding and selectivity and test whether the rates differ by more than a few percent.
Figures

read the original abstract
A columnar scan that decompresses, filters, and aggregates should be limited only by memory bandwidth (the roofline floor T >= BytesRead/beta), yet real kernels are often compute-bound and leave bandwidth idle. We give a predictive answer to when a scan is bandwidth-bound. Across encodings, predicate selectivities, and two very different machines, a decoder's value throughput T_dec (values decoded per second) is essentially independent of bit-width b: it is set by the decode layout/strategy, not by how many bits each value occupies. Hence the achieved bandwidth fraction obeys a one-parameter law, f = min(1, T_dec * b / (8*beta)), with the compute-to-bandwidth ridge at b* = 8*beta/T_dec. Fitting one T_dec per strategy reproduces measured bandwidth fractions with median error 0.027 on x86/AVX2 and 0.003 on a held-out Apple M4/NEON machine, and the ridge b* shifts correctly with each machine's bandwidth. Inserting FastLanes' reported decode throughput into the law reproduces its "decode is free at three bits" headline as the large-T_dec limit, unifying our portable decoder and hand-tuned state of the art in one curve. We add two crossovers, validated on both machines: branch-free predicate evaluation beats branchy in a mid-selectivity band (the sigma(1-sigma) misprediction parabola), and zone-map skipping is clustering-gated rather than selectivity-gated. We release the micro-benchmark, the correctness oracle, and a one-command reproduction. This is a baseline and a model, not a faster kernel: our portable C decoders reach ~2 values/cycle, far below hand-tuned SOTA, and the law holds precisely because it is parameterized by the measured T_dec.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript derives a decode-throughput law stating that a decoder's value throughput T_dec (values/s) is independent of bit-width b and set by the decode layout/strategy. This yields the achieved bandwidth fraction f = min(1, T_dec * b / (8*beta)) with the compute-to-bandwidth ridge at b* = 8*beta/T_dec. Fitting one T_dec per strategy reproduces measured f across encodings, predicate selectivities, and two dissimilar machines (x86/AVX2 and held-out Apple M4/NEON) with median errors 0.027 and 0.003; the ridge shifts correctly with each machine's beta. The law unifies the portable decoder results with FastLanes' "decode is free at three bits" headline. Two additional validated crossovers are presented: branch-free predicate evaluation outperforms branchy in a mid-selectivity band, and zone-map skipping is clustering-gated. The micro-benchmark, correctness oracle, and one-command reproduction script are released.
Significance. If the central independence of T_dec from b holds, the result supplies a simple, portable, one-parameter-per-strategy predictive model for when columnar scans are bandwidth-bound rather than compute-bound. Credit is due for the direct cross-hardware validation on dissimilar ISAs, the low median errors, the unification with prior SOTA, and the public release of the benchmark and reproduction artifacts, all of which make the law falsifiable and reusable for database performance modeling.
minor comments (1)
- [Abstract] Abstract: does not report error bars or uncertainty on the fitted T_dec values themselves, nor the precise number of encodings tested.
Simulated Author's Rebuttal
We thank the referee for the detailed and positive review. The recommendation to accept is appreciated, and we are pleased that the cross-hardware validation, low median errors, unification with prior work, and artifact release were viewed favorably.
Circularity Check
No significant circularity detected
full rationale
The paper posits that T_dec is independent of b (set by decode layout/strategy) and derives the one-parameter law f = min(1, T_dec * b / (8*beta)) from that premise. T_dec is obtained by fitting one value per strategy; the resulting model is then shown to reproduce measured f across bit-widths, selectivities, and a held-out machine with low median error. This constitutes an empirical validation of the independence assumption rather than a reduction of the law to a tautology or to quantities defined only by the same fit. No step equates a claimed prediction to its own inputs by construction, no self-citation chain is load-bearing, and the cross-machine results supply an external check. The derivation is therefore self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- T_dec per decode strategy
axioms (2)
- domain assumption Decoder value throughput T_dec is independent of bit-width b and set only by decode layout/strategy
- standard math Machine bandwidth beta is an independent, measurable constant for each platform
Reference graph
Works this paper leans on
-
[1]
The FastLanes compression layout: Decoding 100 billion integers per second with scalar code
Azim Afroozeh and Peter Boncz. The FastLanes compression layout: Decoding 100 billion integers per second with scalar code. Proceedings of the VLDB Endowment, 16 0 (9): 0 2132--2144, 2023
2023
-
[2]
Boncz, Marcin Zukowski, and Niels Nes
Peter A. Boncz, Marcin Zukowski, and Niels Nes. MonetDB/X100 : Hyper-pipelining query execution. In CIDR, pages 225--237, 2005
2005
-
[3]
Everything you always wanted to know about compiled and vectorized queries but were afraid to ask
Timo Kersten, Viktor Leis, Alfons Kemper, Thomas Neumann, Andrew Pavlo, and Peter Boncz. Everything you always wanted to know about compiled and vectorized queries but were afraid to ask. Proceedings of the VLDB Endowment, 11 0 (13): 0 2209--2222, 2018
2018
-
[4]
BtrBlocks : Efficient columnar compression for data lakes
Maximilian Kuschewski, David Sauerwein, Adnan Alhomssi, and Viktor Leis. BtrBlocks : Efficient columnar compression for data lakes. Proceedings of the ACM on Management of Data, 1 0 (2): 0 1--26, 2023
2023
-
[5]
Boncz, Thomas Neumann, and Alfons Kemper
Harald Lang, Tobias M \"u hlbauer, Florian Funke, Peter A. Boncz, Thomas Neumann, and Alfons Kemper. Data blocks: Hybrid OLTP and OLAP on compressed storage using both vectorization and compilation. In SIGMOD, pages 311--326, 2016
2016
-
[6]
Boncz, and Martin L
Stefan Manegold, Peter A. Boncz, and Martin L. Kersten. Generic database cost models for hierarchical memory systems. In VLDB, pages 191--202, 2002
2002
-
[7]
McCalpin
John D. McCalpin. Memory bandwidth and machine balance in current high performance computers. IEEE TCCA Newsletter, pages 19--25, 1995
1995
-
[8]
Orestis Polychroniou and Kenneth A. Ross. Efficient lightweight compression alongside fast scans. In DaMoN, pages 1--6, 2015
2015
-
[9]
Orestis Polychroniou, Arun Raghavan, and Kenneth A. Ross. Rethinking SIMD vectorization for in-memory databases. In SIGMOD, pages 1493--1508, 2015
2015
-
[10]
Roofline: an insightful visual performance model for multicore architectures
Samuel Williams, Andrew Waterman, and David Patterson. Roofline: an insightful visual performance model for multicore architectures. In Communications of the ACM, volume 52, pages 65--76. ACM, 2009
2009
-
[11]
An empirical evaluation of columnar storage formats
Xinyu Zeng, Yulong Hui, Jiahong Shen, Andrew Pavlo, Wes McKinney, and Huanchen Zhang. An empirical evaluation of columnar storage formats. Proceedings of the VLDB Endowment, 17 0 (2): 0 148--161, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.