Improving Sparse-View 3DGS Generalization via Flat Minima Optimization
Pith reviewed 2026-07-02 14:11 UTC · model grok-4.3
The pith
Adapting flat minima optimization to 3D Gaussian Splatting improves generalization from sparse input views without architectural changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
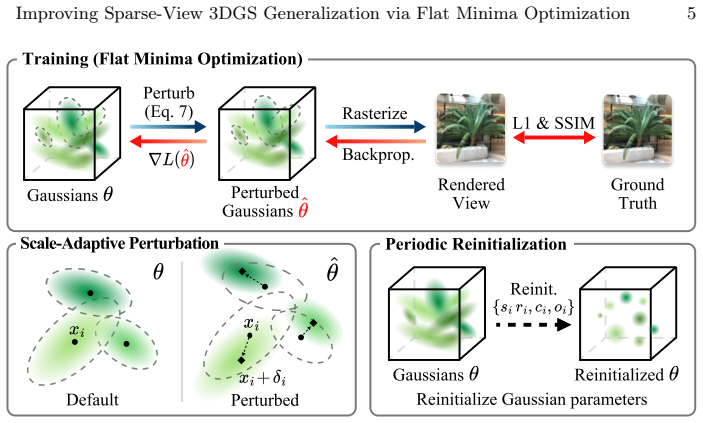
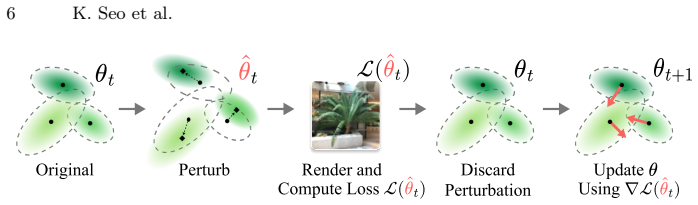
Viewing Gaussian parameters as weights, the method applies flat-minima principles by injecting controlled perturbations that respect each Gaussian's anisotropic shape and the stage of training; periodic reinitialization of non-positional parameters for short windows further stabilizes the search for flat regions, yielding solutions that generalize better to novel views while retaining fine detail.
What carries the argument
Controlled Gaussian perturbations scaled by anisotropy and training progress, together with periodic reinitialization of non-positional parameters.
If this is right
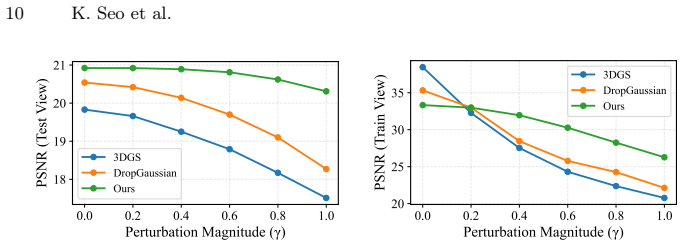
- Reconstructions exhibit higher PSNR, SSIM, and lower LPIPS on held-out views from LLFF and Mip-NeRF360 under sparse supervision.
- Output images are sharper and exhibit fewer floating artifacts when rendered from novel viewpoints.
- The same 3DGS pipeline can be used without redesigning the representation or the renderer.
- Training still finishes at comparable speed because the added operations are lightweight and periodic.
Where Pith is reading between the lines
- The same perturbation schedule might transfer to other explicit scene representations that suffer from sparse-view overfitting.
- If the flat-minima effect scales with scene complexity, the method could reduce the number of required input images for large outdoor environments.
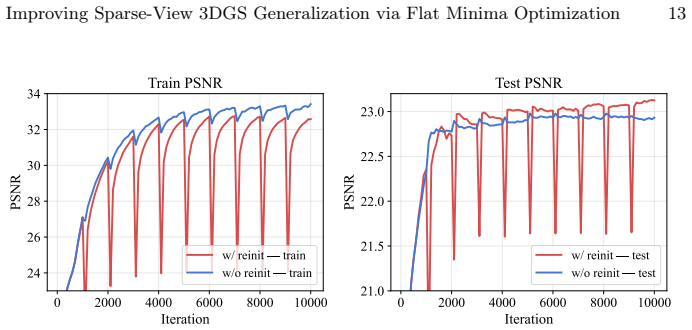
- Periodic reinitialization might interact with the densification heuristic in 3DGS; testing whether it alters the final Gaussian count would clarify the mechanism.
Load-bearing premise
That perturbations chosen according to each Gaussian's shape and training stage, plus short reinitialization windows, will locate flatter minima that reduce overfitting to the sparse training views.
What would settle it
An ablation that disables the anisotropy-aware perturbations and reinitialization on the same LLFF or Mip-NeRF360 sparse-view splits and measures whether novel-view PSNR, SSIM, and LPIPS remain unchanged or worsen.
Figures

read the original abstract
Recent advances in neural rendering have established 3D Gaussian Splatting (3DGS) as a highly efficient representation for novel view synthesis, enabling fast training and real-time rendering with strong fidelity. However, when supervision is limited to sparse input views, 3DGS tends to overfit to the observed images and generalize poorly to unseen viewpoints. We address this challenge from the perspective of flat minima (FM) optimization, which seeks solutions that remain stable under small parameter perturbations. Viewing Gaussian parameters as trainable weights, we adapt FM principles to the geometric and dynamic nature of 3DGS with a lightweight training framework. Our method regularizes optimization with controlled Gaussian perturbations that account for each Gaussian's anisotropy and the training progress, preserving fine details while improving robustness to sparse-view overfitting. To further stabilize this flat minima optimization process, we introduce periodic reinitialization, which temporarily returns non-positional parameters to their initial states for a short window. Together, these techniques integrate seamlessly into existing 3DGS pipelines without architectural changes. Experiments on LLFF and Mip-NeRF360 datasets demonstrate improved quantitative metrics and perceptual quality under sparse-view supervision, producing reconstructions that are sharper, more stable, and better generalized to novel viewpoints.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that adapting flat-minima optimization to 3D Gaussian Splatting via anisotropy-aware controlled perturbations of Gaussian parameters (accounting for training progress) plus periodic reinitialization of non-positional parameters yields improved robustness to sparse-view overfitting. The resulting solutions are said to generalize better to novel views while preserving fine details, with no architectural changes to 3DGS required. Experiments on LLFF and Mip-NeRF360 under sparse supervision are reported to show gains in quantitative metrics and perceptual quality.
Significance. If the central mechanism is shown to produce demonstrably flatter minima and the gains are attributable to that property rather than generic regularization, the work would supply a lightweight, plug-in regularization strategy for a widely used representation. This could be practically useful in low-data novel-view synthesis settings.
major comments (2)
- [Abstract] Abstract: the central claim attributes improved sparse-view generalization to flat-minima optimization, yet the abstract (and the provided manuscript excerpt) contains no indication that flatness was measured (e.g., via sharpness metrics, Hessian trace, or loss under parameter perturbations) or that the obtained solutions are flatter than standard 3DGS training. Without this link, metric improvements on LLFF/Mip-NeRF360 could arise from any form of regularization.
- [Abstract] Abstract: the description of the perturbation schedule and reinitialization window is given at a high level only; no equations, pseudocode, or hyper-parameter values are supplied, preventing assessment of whether the method is parameter-free or how the anisotropy and progress terms are defined.
minor comments (1)
- [Abstract] Abstract: baseline methods, exact sparsity levels, quantitative tables, error bars, and statistical significance are not mentioned, making it impossible to judge the magnitude or reliability of the reported gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point-by-point below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim attributes improved sparse-view generalization to flat-minima optimization, yet the abstract (and the provided manuscript excerpt) contains no indication that flatness was measured (e.g., via sharpness metrics, Hessian trace, or loss under parameter perturbations) or that the obtained solutions are flatter than standard 3DGS training. Without this link, metric improvements on LLFF/Mip-NeRF360 could arise from any form of regularization.
Authors: We agree that the abstract does not report explicit flatness measurements and that this weakens the direct attribution to flat minima. In the revised manuscript we will add quantitative analysis (e.g., sharpness metrics and approximate Hessian trace) comparing the loss landscape of our method against standard 3DGS training on the same sparse-view setups. These results will be placed in the experiments or analysis section and referenced from the abstract to establish that the observed gains are linked to flatter minima rather than generic regularization. revision: yes
-
Referee: [Abstract] Abstract: the description of the perturbation schedule and reinitialization window is given at a high level only; no equations, pseudocode, or hyper-parameter values are supplied, preventing assessment of whether the method is parameter-free or how the anisotropy and progress terms are defined.
Authors: The full manuscript contains the mathematical definitions of the anisotropy-aware perturbation (including the anisotropy and training-progress factors), the periodic reinitialization schedule, and the complete hyper-parameter table in Section 3 and the supplementary material. To make the abstract more self-contained we will revise it to include the key equations for the perturbation term and a brief reference to the reinitialization window, while ensuring the methods section already supplies pseudocode and all numerical values. revision: partial
Circularity Check
No circularity: empirical adaptation of known flat-minima principles verified on external benchmarks
full rationale
The paper describes a lightweight training framework that adapts established flat-minima optimization ideas to 3DGS using controlled perturbations (anisotropy- and progress-aware) plus periodic reinitialization. These are presented as regularization techniques integrated into existing pipelines, with claims resting on quantitative and perceptual improvements measured on LLFF and Mip-NeRF360 under sparse-view conditions. No equations, self-citations, or fitted quantities are shown that reduce the reported gains to a definition or input by construction. The derivation chain is therefore self-contained: the method is an engineering adaptation whose validity is assessed against independent dataset metrics rather than tautological re-labeling of its own components.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Barron, J.T., Mildenhall, B., Verbin, D., Srinivasan, P.P., Hedman, P.: Mip- nerf 360: Unbounded anti-aliased neural radiance fields. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5470–5479 (2022)
2022
-
[2]
In: International Conference on Artificial Intelligence and Statistics
Bisla, D., Wang, J., Choromanska, A.: Low-pass filtering sgd for recovering flat optima in the deep learning optimization landscape. In: International Conference on Artificial Intelligence and Statistics. pp. 8299–8339. PMLR (2022)
2022
-
[3]
Advances in Neural Information Processing Systems38, 115939–115968 (2026)
Chen, K., Zhong, Y., Li, Z., Lin, J., Chen, Y., Qin, M., Wang, H.: Quantifying and alleviating co-adaptation in sparse-view 3d gaussian splatting. Advances in Neural Information Processing Systems38, 115939–115968 (2026)
2026
-
[4]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition
Chung, J., Oh, J., Lee, K.M.: Depth-regularized optimization for 3d gaussian splat- ting in few-shot images. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. pp. 811–820 (2024)
2024
-
[5]
In: International Conference on Machine Learning
Dinh, L., Pascanu, R., Bengio, S., Bengio, Y.: Sharp minima can generalize for deep nets. In: International Conference on Machine Learning. pp. 1019–1028. PMLR (2017)
2017
-
[6]
Sharpness-Aware Minimization for Efficiently Improving Generalization
Foret, P., Kleiner, A., Mobahi, H., Neyshabur, B.: Sharpness-aware minimization for efficiently improving generalization. arXiv preprint arXiv:2010.01412 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[7]
In: Proceed- ings of the Computer Vision and Pattern Recognition Conference
Guédon, A., Ichikawa, T., Yamashita, K., Nishino, K.: Matcha gaussians: Atlas of charts for high-quality geometry and photorealism from sparse views. In: Proceed- ings of the Computer Vision and Pattern Recognition Conference. pp. 6001–6011 (2025)
2025
-
[8]
arXiv preprint arXiv:2508.04968 (2025)
Guo, Z., Wang, P., Chen, Z., Kong, X., Lyu, Y., Gao, G., Han, L.: Ugod: Uncertainty-guided differentiable opacity and soft dropout for enhanced sparse- view 3dgs. arXiv preprint arXiv:2508.04968 (2025)
-
[9]
Neural computation9(1), 1–42 (1997)
Hochreiter, S., Schmidhuber, J.: Flat minima. Neural computation9(1), 1–42 (1997)
1997
-
[10]
Advances in Neural Information Processing Systems37, 110412–110435 (2024)
Hyung, J., Hong, S., Hwang, S., Lee, J., Choo, J., Kim, J.H.: Effective rank anal- ysis and regularization for enhanced 3d gaussian splatting. Advances in Neural Information Processing Systems37, 110412–110435 (2024)
2024
-
[11]
ACM Transactions on Graphics (TOG)44(6), 1–16 (2025)
Jiang, L., Mao, Y., Xu, L., Lu, T., Ren, K., Jin, Y., Xu, X., Yu, M., Pang, J., Zhao, F., et al.: Anysplat: Feed-forward 3d gaussian splatting from unconstrained views. ACM Transactions on Graphics (TOG)44(6), 1–16 (2025)
2025
-
[12]
ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G., et al.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139–1 (2023)
2023
-
[13]
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
Keskar, N.S., Mudigere, D., Nocedal, J., Smelyanskiy, M., Tang, P.T.P.: On large- batch training for deep learning: Generalization gap and sharp minima. arXiv preprint arXiv:1609.04836 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[14]
Advances in Neural Information Processing Systems37, 80965–80986 (2024) 16 K
Kheradmand, S., Rebain, D., Sharma, G., Sun, W., Tseng, Y.C., Isack, H., Kar, A., Tagliasacchi, A., Yi, K.M.: 3d gaussian splatting as markov chain monte carlo. Advances in Neural Information Processing Systems37, 80965–80986 (2024) 16 K. Seo et al
2024
-
[15]
ACM Transactions on Graphics (ToG)36(4), 1–13 (2017)
Knapitsch, A., Park, J., Zhou, Q.Y., Koltun, V.: Tanks and temples: Benchmarking large-scale scene reconstruction. ACM Transactions on Graphics (ToG)36(4), 1–13 (2017)
2017
-
[16]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, J., Zhang, J., Bai, X., Zheng, J., Ning, X., Zhou, J., Gu, L.: Dngaussian: Opti- mizing sparse-view 3d gaussian radiance fields with global-local depth normaliza- tion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 20775–20785 (2024)
2024
-
[17]
arXiv preprint arXiv:2404.00357 (2024)
Li, T., Tao, Q., Yan, W., Lei, Z., Wu, Y., Fang, K., He, M., Huang, X.: Revisiting random weight perturbation for efficiently improving generalization. arXiv preprint arXiv:2404.00357 (2024)
-
[18]
arXiv preprint arXiv:2211.11489 (2022)
Li, T., Yan, W., Lei, Z., Wu, Y., Fang, K., Yang, M., Huang, X.: Efficient gen- eralization improvement guided by random weight perturbation. arXiv preprint arXiv:2211.11489 (2022)
-
[19]
ACM Transactions on Graphics (ToG)38(4), 1–14 (2019)
Mildenhall, B., Srinivasan, P.P., Ortiz-Cayon, R., Kalantari, N.K., Ramamoorthi, R., Ng, R., Kar, A.: Local light field fusion: Practical view synthesis with pre- scriptive sampling guidelines. ACM Transactions on Graphics (ToG)38(4), 1–14 (2019)
2019
-
[20]
Commu- nications of the ACM65(1), 99–106 (2021)
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Commu- nications of the ACM65(1), 99–106 (2021)
2021
-
[21]
In: Proceedings of the computer vision and pattern recog- nition conference
Park, H., Ryu, G., Kim, W.: Dropgaussian: Structural regularization for sparse- view gaussian splatting. In: Proceedings of the computer vision and pattern recog- nition conference. pp. 21600–21609 (2025)
2025
-
[22]
In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers
Patle, G., Girgaonkar, N., Somraj, N., Soundararajan, R.: Ad-gs: Alternating den- sification for sparse-input 3d gaussian splatting. In: Proceedings of the SIGGRAPH Asia 2025 Conference Papers. pp. 1–11 (2025)
2025
-
[23]
Advances in Neural Information Processing Systems37, 97328–97352 (2024)
Peng, R., Xu, W., Tang, L., Liao, L., Jiao, J., Wang, R.: Structure consistent gaussian splatting with matching prior for few-shot novel view synthesis. Advances in Neural Information Processing Systems37, 97328–97352 (2024)
2024
-
[24]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Schonberger, J.L., Frahm, J.M.: Structure-from-motion revisited. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4104–4113 (2016)
2016
-
[25]
Song, M., Lin, X., Zhang, D., Li, H., Li, X., Du, B., Qi, L.: D2gs: Depth-and-density guided gaussian splatting for stable and accurate sparse-view reconstruction. arXiv preprint arXiv:2510.08566 (2025)
-
[26]
IEEE transactions on image processing 13(4), 600–612 (2004)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. IEEE transactions on image processing 13(4), 600–612 (2004)
2004
-
[27]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wu, J.Z., Zhang, Y., Turki, H., Ren, X., Gao, J., Shou, M.Z., Fidler, S., Gojcic, Z., Ling, H.: Difix3d+: Improving 3d reconstructions with single-step diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 26024–26035 (2025)
2025
-
[28]
In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference
Wu, J., Li, R., Zhu, Y., Guo, R., Sun, J., Zhang, Y.: Sparse2dgs: Geometry- prioritized gaussian splatting for surface reconstruction from sparse views. In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference. pp. 11307– 11316 (2025)
2025
-
[29]
In: 2025 Interna- tional Conference on 3D Vision (3DV)
Xiong, H., Muttukuru, S., Xiao, H., Upadhyay, R., Chari, P., Zhao, Y., Kadambi, A.: Sparsegs: sparse view synthesis using 3d gaussian splatting. In: 2025 Interna- tional Conference on 3D Vision (3DV). pp. 1032–1041. IEEE (2025) Improving Sparse-View 3DGS Generalization via Flat Minima Optimization 17
2025
-
[30]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xu, Y., Wang, L., Chen, M., Ao, S., Li, L., Guo, Y.: Dropoutgs: Dropping out gaussians for better sparse-view rendering. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 701–710 (2025)
2025
-
[31]
In: European conference on computer vision
Zhang, J., Li, J., Yu, X., Huang, L., Gu, L., Zheng, J., Bai, X.: Cor-gs: sparse-view 3d gaussian splatting via co-regularization. In: European conference on computer vision. pp. 335–352. Springer (2024)
2024
-
[32]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 586–595 (2018)
2018
-
[33]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhao, C., Wang, X., Zhang, T., Javed, S., Salzmann, M.: Self-ensembling gaussian splatting for few-shot novel view synthesis. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4940–4950 (2025)
2025
-
[34]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zheng, Y., Jiang, Z., He, S., Sun, Y., Dong, J., Zhang, H., Du, Y.: Nexusgs: Sparse view synthesis with epipolar depth priors in 3d gaussian splatting. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 26800–26809 (2025)
2025
-
[35]
Zhong, Y., Li, Z., Chen, D.Z., Hong, L., Xu, D.: Taming video diffusion prior with scene-groundingguidancefor3dgaussiansplattingfromsparseinputs.In:Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6133–6143 (2025)
2025
-
[36]
In: European conference on computer vision
Zhu, Z., Fan, Z., Jiang, Y., Wang, Z.: Fsgs: Real-time few-shot view synthesis using gaussian splatting. In: European conference on computer vision. pp. 145–
-
[37]
Seo et al
Springer (2024) 18 K. Seo et al. A Appendix A.1 Additional Benchmark Results We evaluate our method on additional real-world outdoor, synthetic, and object- centric benchmarks, including NeO 360 dataset for outdoor settings with limited viewpoint coverage. T able 5:Additional benchmark results. Dataset Method PSNR SSIM LPIPS Tanks & Temples 12-view 3DGS13...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.