Mining Architectural Quality Under Agentic AI Adoption: A Causal Study of Java Repositories
Pith reviewed 2026-06-27 06:03 UTC · model grok-4.3
The pith
Agentic AI adoption increases code volume without increasing architectural smell counts, causing a density decline as a denominator effect.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Adoption of agentic AI produces no statistically significant change in total architectural smell counts (+1.1%, p=0.82) but drives a 12.8% increase in lines of code (p=0.003), yielding a 6.7% decline in smell density (p=0.004) that is attributable to the denominator rather than fewer smells per unit of code.
What carries the argument
Staggered difference-in-differences estimator with Borusyak imputation applied to monthly architectural smell density measurements from Arcan, after propensity score matching of treated and control repositories.
If this is right
- Density-based architectural metrics require explicit decomposition into numerator and denominator effects when treatments alter code volume.
- Raw smell counts and size metrics should be reported separately in causal evaluations of AI coding tools.
- The pattern holds across per-type smell estimates and multiple robustness checks including wild cluster bootstrap and Lee bounds.
- Pre-trends are consistent with parallel trends assumption in the matched sample.
Where Pith is reading between the lines
- Similar effects may appear in other programming languages or with different AI tools if they encourage code expansion.
- Future studies could track individual developer productivity alongside architecture to see if the size growth reflects added features or duplication.
- The result implies that AI-assisted development might scale systems faster than it introduces architectural debt in the short term.
Load-bearing premise
Repositories are correctly classified as having adopted agentic AI based on configuration files and commit trailers, and propensity matching sufficiently balances unobserved confounders for the causal estimator.
What would settle it
Finding a treated repository where lines of code do not increase after adoption but total smells rise significantly would contradict the denominator-effect explanation.
Figures

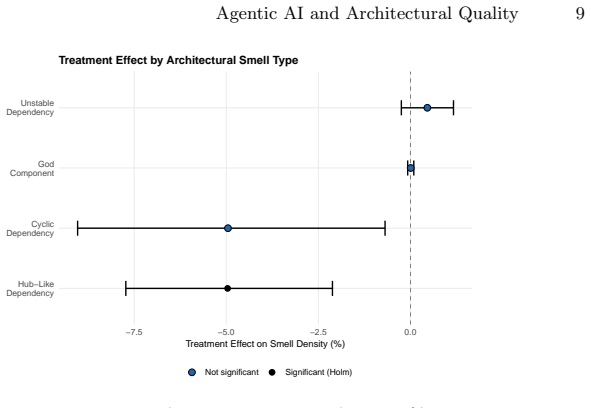
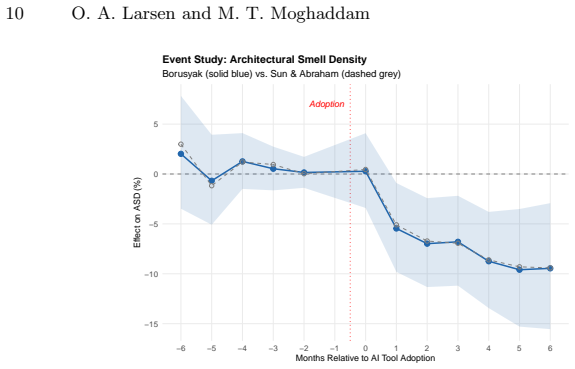

read the original abstract
AI coding tools are now used by a majority of developers, and agentic use of these tools has popularized the practice colloquially called "vibe coding". Yet causal evidence on their effect on software architecture is scarce. Prior causal work has measured code-level outcomes (complexity, static analysis warnings); whether such degradation propagates to architecture-level outcomes remains unknown. We mine 151 open-source Java repositories, 74 with detectable agentic AI adoption (identified via configuration files and Co-Authored-By commit trailers) and 77 propensity-matched controls, across a 13-month per-repository window yielding 1,811 monthly Arcan snapshots. We estimate the causal effect of adoption on architectural smell density (ASD) with a staggered difference-in-differences design and the Borusyak imputation estimator, applying a causal design recently used for code-level metrics to the architecture level. Total smell counts are essentially unchanged (+1.1%, p = 0.82) while lines of code grow +12.8% (p = 0.003); the resulting 6.7% ASD decline (p = 0.004) is therefore a denominator effect rather than an architectural improvement. Per-type estimates and robustness checks (wild cluster bootstrap, Lee bounds, stale-observation sensitivity) corroborate the pattern; pre-trends are flat (Wald p = 0.90), consistent with parallel trends. Density-normalized outcomes can mislead when treatment affects system size: raw counts and explicit decomposition are required for causal mining studies of AI tool adoption. The complete replication package, including the curated 151-repository monthly panel, is publicly available.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a causal analysis of agentic AI adoption on architectural smell density in 151 Java repositories using staggered difference-in-differences and the Borusyak imputation estimator. Treated units (74 repositories) are identified via configuration files and Co-Authored-By trailers, propensity-matched to controls. The main result is that smell counts are stable (+1.1%, p=0.82) while LOC increases (+12.8%, p=0.003), yielding a 6.7% ASD reduction (p=0.004) attributed to the denominator effect. Multiple robustness checks and a public replication package are provided.
Significance. Should the identification assumptions hold, the findings highlight a methodological point for causal mining studies: density metrics can produce misleading conclusions when the intervention affects system size. The work extends prior code-level analyses to architecture and supplies reproducible data, which strengthens its contribution to empirical software engineering.
major comments (1)
- [§3 (Identification Strategy)] The detection of agentic AI adoption via configuration files and Co-Authored-By commit trailers is central to assigning treatment status for the staggered DiD. The manuscript provides no validation, sensitivity analysis to alternative proxies, or discussion of potential false positives (e.g., config files present without active use). This is load-bearing for the claim that the observed patterns are caused by adoption rather than selection or measurement error, as differential misclassification would bias the Borusyak estimates and the parallel trends test.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the identification strategy. The concern about validation of treatment assignment is well-taken and directly relevant to the credibility of the staggered DiD estimates. We respond point-by-point below and commit to revisions that add the requested validation and sensitivity checks.
read point-by-point responses
-
Referee: [§3 (Identification Strategy)] The detection of agentic AI adoption via configuration files and Co-Authored-By commit trailers is central to assigning treatment status for the staggered DiD. The manuscript provides no validation, sensitivity analysis to alternative proxies, or discussion of potential false positives (e.g., config files present without active use). This is load-bearing for the claim that the observed patterns are caused by adoption rather than selection or measurement error, as differential misclassification would bias the Borusyak estimates and the parallel trends test.
Authors: We agree that explicit validation of the treatment proxy is necessary given its central role. The current manuscript relies on two observable signals (presence of agentic configuration files such as .cursor or .windsurf and Co-Authored-By trailers) that have been used in prior mining studies of AI tool adoption, but we did not report sample-level validation or alternative definitions. In the revision we will add: (1) a new subsection in §3 reporting manual inspection of a random sample of 20 treated repositories to confirm active use (via commit messages, PR descriptions, and configuration contents); (2) sensitivity analyses re-estimating the main models under stricter proxies (e.g., requiring both signals or at least three Co-Authored-By trailers) and under a looser proxy (config file only); and (3) explicit discussion of the direction and magnitude of potential misclassification bias, including how it would affect the Borusyak imputation estimator and the parallel-trends test. These additions will be supported by updated tables in the robustness section. We believe this directly mitigates the referee's concern without altering the core findings. revision: yes
Circularity Check
Empirical causal study with standard DiD estimator; no load-bearing circularity in derivation
full rationale
The paper applies a staggered difference-in-differences design with the Borusyak imputation estimator to a mined panel of 151 Java repositories. Treatment classification relies on observable proxies (configuration files and Co-Authored-By trailers), and outcomes (smell counts, LOC, ASD) are computed directly from Arcan snapshots. The central claim—that ASD decline is a denominator effect—is an arithmetic decomposition of the estimated treatment effects on raw counts versus size, not a self-referential equation or fitted parameter renamed as prediction. The mention of a 'causal design recently used for code-level metrics' is a methodological reference rather than a load-bearing self-citation that justifies the result. No self-definitional loops, ansatz smuggling, or uniqueness theorems appear. The analysis is self-contained against external benchmarks (public replication package) and receives a minimal score only for possible minor self-citation of the method.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The parallel trends assumption holds between treated and control repositories in the absence of treatment.
Reference graph
Works this paper leans on
-
[1]
Agarwal, S., He, H., Vasilescu, B.: AI IDEs or autonomous agents? Measuring the impact of coding agents on software development (2026), accepted at MSR 2026
2026
-
[2]
Journal of Econometrics1(1), 49–59 (1973).https://doi.org/10
Aigner, D.J.: Regression with a binary independent variable subject to errors of observation. Journal of Econometrics1(1), 49–59 (1973).https://doi.org/10. 1016/0304-4076(73)90005-5
1973
-
[3]
In: Software Architecture: ECSA 2025 Tracks and Workshops
Amasanti, G., Jahi´ c, J.: The impact of AI-generated solutions on software archi- tecture and productivity: Results from a survey study. In: Software Architecture: ECSA 2025 Tracks and Workshops. Lecture Notes in Computer Science, vol. 15982, pp. 89–104. Springer (2025).https://doi.org/10.1007/978-3-032-04403-7_10 Agentic AI and Architectural Quality 15
-
[4]
Software tool (2025)
Anthropic: Claude Code: An agentic coding tool. Software tool (2025)
2025
-
[5]
Software tool (2024)
Anysphere: Cursor: The AI code editor. Software tool (2024)
2024
-
[6]
In: Proceedings of the IEEE International Conference on Software Architecture Workshops (ICSAW)
Arcelli Fontana, F., Pigazzini, I., Roveda, R., Tamburri, D.A., Zanoni, M., Di Nitto, E.: Arcan: A Tool for Architectural Smells Detection. In: Proceedings of the IEEE International Conference on Software Architecture Workshops (ICSAW). pp. 282– 285 (2017).https://doi.org/10.1109/ICSAW.2017.16
-
[7]
Pharmaceutical Statistics10(2), 150–161 (2011).https://doi.org/10.1002/pst
Austin, P.C.: Optimal caliper widths for propensity-score matching when estimat- ing differences in means and differences in proportions in observational studies. Pharmaceutical Statistics10(2), 150–161 (2011).https://doi.org/10.1002/pst. 433
work page doi:10.1002/pst 2011
-
[8]
Addison- Wesley, 4th edn
Bass, L., Clements, P., Kazman, R.: Software Architecture in Practice. Addison- Wesley, 4th edn. (2021)
2021
-
[9]
Review of Economic Studies91(6), 3253–3285 (2024).https: //doi.org/10.1093/restud/rdae007
Borusyak, K., Jaravel, X., Spiess, J.: Revisiting event-study designs: Robust and efficient estimation. Review of Economic Studies91(6), 3253–3285 (2024).https: //doi.org/10.1093/restud/rdae007
-
[10]
The Review of Economics and Statistics90(3), 414–427 (2008).https://doi.org/10.1162/rest.90.3.414
Cameron, A.C., Gelbach, J.B., Miller, D.L.: Bootstrap-based improvements for inference with clustered errors. The Review of Economics and Statistics90(3), 414–427 (2008).https://doi.org/10.1162/rest.90.3.414
-
[11]
Cotroneo, D., Improta, C., Liguori, P.: Human-written vs. AI-generated code: A large-scale study of defects, vulnerabilities, and complexity. In: Proceedings of IS- SRE. pp. 252–263 (2025).https://doi.org/10.1109/ISSRE66568.2025.00035
-
[12]
American Economic Review110(9), 2964–2996 (2020).https://doi.org/10.1257/aer.20181169
de Chaisemartin, C., d’Haultfœuille, X.: Two-way fixed effects estimators with heterogeneous treatment effects. American Economic Review110(9), 2964–2996 (2020).https://doi.org/10.1257/aer.20181169
-
[13]
Software Quality Journal 33(4), 33 (2025).https://doi.org/10.1007/s11219-025-09730-7
Esposito, M., Robredo, M., Arcelli Fontana, F., Lenarduzzi, V.: On the correlation between architectural smells and static analysis warnings. Software Quality Journal 33(4), 33 (2025).https://doi.org/10.1007/s11219-025-09730-7
-
[14]
In: Proceedings of ICSE-SEIP (2026), arXiv:2510.00328, to appear
Fawzy, A., Tahir, A., Blincoe, K.: Vibe coding in practice: Motivations, challenges, and a future outlook—a grey literature review. In: Proceedings of ICSE-SEIP (2026), arXiv:2510.00328, to appear
arXiv 2026
-
[15]
In: Proceedings of the International Conference on the Qual- ity of Software Architectures (QoSA)
Garcia, J., Popescu, D., Edwards, G., Medvidovic, N.: Toward a catalogue of archi- tectural bad smells. In: Proceedings of the International Conference on the Qual- ity of Software Architectures (QoSA). pp. 146–162 (2009).https://doi.org/10. 1007/978-3-642-02351-4_10
2009
-
[16]
Software tool (2025)
GitHub: GitHub Copilot: Your AI pair programmer. Software tool (2025)
2025
-
[17]
Journal of Systems and Software217, 112170 (2024).https://doi.org/10.1016/j.jss.2024.112170
Gnoyke, P., Schulze, S., Kr¨ uger, J.: Evolution patterns of software-architecture smells: An empirical study of intra- and inter-version smells. Journal of Systems and Software217, 112170 (2024).https://doi.org/10.1016/j.jss.2024.112170
-
[18]
Goodman-Bacon, A.: Difference-in-differences with variation in treatment timing. Journal of Econometrics225(2), 254–277 (2021).https://doi.org/10.1016/j. jeconom.2021.03.014
work page doi:10.1016/j 2021
-
[19]
Journal of Systems and Software61(2), 105–119 (2002)
van Gurp, J., Bosch, J.: Design erosion: Problems and causes. Journal of Systems and Software61(2), 105–119 (2002)
2002
-
[20]
He, H., Miller, C., Agarwal, S., K¨ astner, C., Vasilescu, B.: Speed at the cost of quality: How Cursor AI increases short-term velocity and long-term complexity in open-source projects (2025), accepted at MSR 2026
2025
-
[21]
In- formation and Software Technology47(10), 643–656 (2005)
Hochstein, L., Lindvall, M.: Combating architectural degeneration: A survey. In- formation and Software Technology47(10), 643–656 (2005)
2005
-
[22]
Jiang, S., Nam, D.: Beyond the prompt: An empirical study of Cursor Rules. In: Proceedings of the 23rd International Conference on Mining Software Repositories (MSR) (2026), arXiv:2512.18925, to appear 16 O. A. Larsen and M. T. Moghaddam
arXiv 2026
-
[23]
Journal of Systems and Software 225, 112382 (2025).https://doi.org/10.1016/j.jss.2025.112382
Jolak, R., Karlsson, S., Dobslaw, F.: An empirical investigation of the impact of architectural smells on software maintainability. Journal of Systems and Software 225, 112382 (2025).https://doi.org/10.1016/j.jss.2025.112382
-
[24]
Empiri- cal Software Engineering21(5), 2035–2071 (2016).https://doi.org/10.1007/ s10664-015-9393-5
Kalliamvakou, E., Gousios, G., Blincoe, K., Singer, L., German, D.M., Damian, D.: An in-depth study of the promises and perils of mining GitHub. Empiri- cal Software Engineering21(5), 2035–2071 (2016).https://doi.org/10.1007/ s10664-015-9393-5
2035
-
[25]
X (formerly Twitter) (February 2025),https://x
Karpathy, A.: Vibe coding. X (formerly Twitter) (February 2025),https://x. com/karpathy/status/1886192184808149383
arXiv 2025
-
[26]
Review of Economic Studies76(3), 1071–1102 (2009).https: //doi.org/10.1111/j.1467-937X.2009.00536.x
Lee, D.S.: Training, wages, and sample selection: Estimating sharp bounds on treatment effects. Review of Economic Studies76(3), 1071–1102 (2009).https: //doi.org/10.1111/j.1467-937X.2009.00536.x
-
[27]
John Wiley & Sons (2006)
Lippert, M., Roock, S.: Refactoring in Large Software Projects: Performing Com- plex Restructurings Successfully. John Wiley & Sons (2006)
2006
-
[28]
Prentice Hall (2003)
Martin, R.C.: Agile Software Development: Principles, Patterns, and Practices. Prentice Hall (2003)
2003
-
[29]
ACM SIGSOFT Software Engineering Notes17(4), 40–52 (1992)
Perry, D.E., Wolf, A.L.: Foundations for the study of software architecture. ACM SIGSOFT Software Engineering Notes17(4), 40–52 (1992)
1992
-
[30]
Rosenbaum, P.R., Rubin, D.B.: Constructing a control group using multivariate matched sampling methods that incorporate the propensity score. The Ameri- can Statistician39(1), 33–38 (1985).https://doi.org/10.1080/00031305.1985. 10479383
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1080/00031305.1985 1985
-
[31]
Biometrics36(2), 293–298 (1980).https://doi.org/10.2307/2529981
Rubin, D.B.: Bias reduction using Mahalanobis-metric matching. Biometrics36(2), 293–298 (1980).https://doi.org/10.2307/2529981
-
[32]
Sas, D., Avgeriou, P.: An architectural technical debt index based on machine learn- ing and architectural smells. IEEE Transactions on Software Engineering49(8), 4169–4195 (2023).https://doi.org/10.1109/TSE.2023.3286179
-
[33]
Empirical Software Engineering27, 86 (2022)
Sas, D., Avgeriou, P., Uyumaz, U.: On the evolution and impact of architectural smells—an industrial case study. Empirical Software Engineering27, 86 (2022)
2022
-
[34]
Schmid, L., Hey, T., Armbruster, M., Corallo, S., Fuchß, D., Keim, J., Liu, H., Koziolek, A.: Software architecture meets LLMs: A systematic literature review (2025)
2025
-
[35]
Online survey (2024)
Stack Overflow: Stack overflow developer survey 2024. Online survey (2024)
2024
-
[36]
Statistical Science25(1), 1–21 (2010).https://doi.org/10.1214/09-STS313
Stuart, E.A.: Matching methods for causal inference: A review and a look forward. Statistical Science25(1), 1–21 (2010).https://doi.org/10.1214/09-STS313
-
[37]
Journal of Econometrics225(2), 175–199 (2021)
Sun, L., Abraham, S.: Estimating dynamic treatment effects in event studies with heterogeneous treatment effects. Journal of Econometrics225(2), 175–199 (2021). https://doi.org/10.1016/j.jeconom.2020.09.006
-
[38]
In: Proceedings of the 19th European Conference on Software Architecture (ECSA)
Tessa, C., Bochicchio, M., Arcelli Fontana, F.: Exploring architectural smells detec- tion through LLMs. In: Proceedings of the 19th European Conference on Software Architecture (ECSA). Lecture Notes in Computer Science, vol. 15929, pp. 90–98. Springer (2025).https://doi.org/10.1007/978-3-032-02138-0_6
-
[39]
Waseem, M., Ahmad, A., Kemell, K.K., Rasku, J., Lahti, S., M¨ akel¨ a, K., Abra- hamsson, P.: Vibe coding in practice: Flow, technical debt, and guidelines for sustainable use (2025)
2025
-
[40]
Cana- dian Journal of Economics56(3), 839–858 (2023).https://doi.org/10.1111/ caje.12661
Webb, M.D.: Reworking wild bootstrap-based inference for clustered errors. Cana- dian Journal of Economics56(3), 839–858 (2023).https://doi.org/10.1111/ caje.12661
2023
-
[41]
Yeti¸ stiren, B.,¨Ozsoy, I., Ayerdem, M., T¨ uz¨ un, E.: Evaluating the code quality of AI-assisted code generation tools: An empirical study on GitHub Copilot, Amazon CodeWhisperer, and ChatGPT (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.