Piper: A Programmable Distributed Training System
Pith reviewed 2026-06-27 11:32 UTC · model grok-4.3
The pith
Piper decouples distributed training strategies from the runtime by transforming a unified global DAG IR with user annotations and directives.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
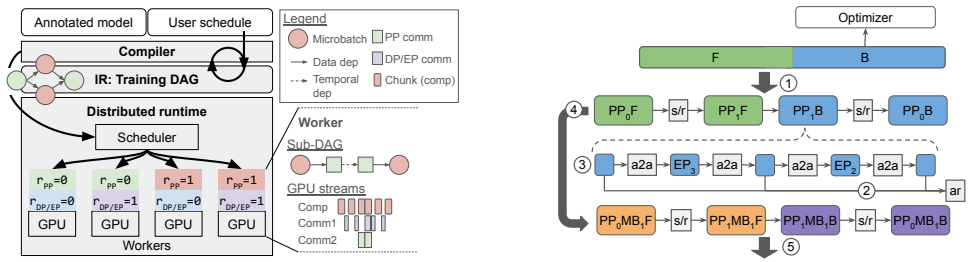
Piper is a user-controllable distributed training system that decouples the strategy from the runtime implementation. Users declare a comprehensive distributed training strategy with a small set of model annotations and scheduling directives. Each directive applies a transformation on Piper's intermediate representation, a unified global training DAG that represents all computation and communication. Using this IR, Piper compiles per-device execution plans and executes them with a distributed runtime agnostic to the strategy.
What carries the argument
The unified global training DAG IR, on which user annotations and scheduling directives apply transformations to produce strategy-specific execution plans while the runtime remains unchanged.
If this is right
- The system maintains performance parity on commonly available strategies such as ZeRO.
- Joint scheduling of compute and communication in composed strategies such as DualPipe produces additional performance and memory efficiency gains.
- New strategies can be integrated by adding transformations to the IR without altering the runtime.
- Compositions of data, pipeline, expert, and memory-saving parallelism become expressible through the same annotation mechanism.
Where Pith is reading between the lines
- Experimenting with novel parallelism combinations becomes feasible without writing new runtime code for each one.
- The IR representation could support automated search over strategy spaces by treating directives as composable operators.
- Similar decoupling might apply to inference or fine-tuning workloads that also combine multiple parallelism forms.
Load-bearing premise
A small set of model annotations and scheduling directives applied as transformations to the unified global training DAG IR is sufficient to express and efficiently schedule arbitrary compositions of data, pipeline, expert, and memory-saving parallelism without strategy-specific runtime changes.
What would settle it
A new parallelism composition that cannot be expressed or scheduled efficiently using only the provided annotations and directives on the DAG IR, requiring direct modifications to the distributed runtime instead.
Figures








read the original abstract
Large-scale model training increasingly relies on composing multiple parallelism strategies, such as data, pipeline, and expert parallelism, together with memory-saving optimizations like ZeRO. Deployed systems for foundation model pretraining often rely on human experts to manually design a high-level parallelism strategy then implement the corresponding low-level execution strategy, making it difficult to adapt the system to new strategies. Meanwhile, many general-purpose frameworks are more flexible but their implementations are still tied to a fixed set of common parallelism strategies, making it challenging to integrate state-of-the-art strategies. We present Piper, a user-controllable distributed training system that decouples the strategy from the runtime implementation. Piper allows users to declare a comprehensive distributed training strategy with a small set of model annotations and scheduling directives. Each directive applies a transformation on Piper's intermediate representation (IR), a unified global training DAG that represents all computation and communication. Using this IR, Piper compiles per-device execution plans and executes them with a distributed runtime agnostic to the strategy. We show that the combined system maintains performance parity on commonly available strategies such as ZeRO, while also enabling additional performance and memory efficiency gains through joint scheduling of compute and communication in composed parallelism strategies such as DeepSeek-V3's DualPipe.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Piper, a user-controllable distributed training system that decouples parallelism strategy from runtime implementation. Users declare strategies via a small set of model annotations and scheduling directives; each directive transforms a unified global training DAG IR representing all computation and communication. Piper then compiles per-device execution plans and runs them on a strategy-agnostic distributed runtime. The abstract claims performance parity with ZeRO and additional gains via joint compute/communication scheduling in composed strategies such as DeepSeek-V3's DualPipe.
Significance. If the central decoupling claim holds and the small annotation set plus DAG transformations can express arbitrary compositions without runtime modifications, the work would meaningfully advance flexibility in large-scale training frameworks, reducing reliance on hand-tuned implementations for new strategies.
major comments (3)
- [Abstract, §3] Abstract and §3 (IR and transformations): the central claim that a fixed small set of annotations and directives suffices for arbitrary compositions (including DualPipe) without strategy-specific runtime changes is not supported by any concrete transformation definitions, IR node types, or derivation of the DualPipe schedule. The manuscript supplies no example showing how DualPipe is encoded as transformations on the global DAG.
- [Abstract] Abstract: the claims of 'performance parity on commonly available strategies such as ZeRO' and 'additional performance and memory efficiency gains' are stated without any quantitative results, error bars, baselines, or experimental setup details, leaving the empirical support for the system unverified.
- [§4] §4 (runtime): the assertion that the distributed runtime remains agnostic to the strategy rests on the IR producing per-device plans, but no evidence is given that the runtime requires no strategy-specific logic when executing the DualPipe schedule or other novel compositions.
minor comments (1)
- [Abstract] The abstract would benefit from a brief mention of the number of annotations/directives in the 'small set' and the size of the IR.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications and indicate revisions to strengthen the presentation of the IR transformations, empirical claims, and runtime design.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (IR and transformations): the central claim that a fixed small set of annotations and directives suffices for arbitrary compositions (including DualPipe) without strategy-specific runtime changes is not supported by any concrete transformation definitions, IR node types, or derivation of the DualPipe schedule. The manuscript supplies no example showing how DualPipe is encoded as transformations on the global DAG.
Authors: We agree that an explicit worked example is needed to substantiate the claim. The revised manuscript will add to §3 a concrete derivation of the DualPipe schedule, specifying the IR node types, the sequence of annotations and directives, and the resulting transformations on the global DAG. This will demonstrate that the small annotation set encodes the composition without requiring changes to the runtime. revision: yes
-
Referee: [Abstract] Abstract: the claims of 'performance parity on commonly available strategies such as ZeRO' and 'additional performance and memory efficiency gains' are stated without any quantitative results, error bars, baselines, or experimental setup details, leaving the empirical support for the system unverified.
Authors: The abstract summarizes the key findings; the supporting quantitative results (including ZeRO parity numbers, DualPipe gains, error bars, baselines, and setup) appear in §5. We will revise the abstract to reference the evaluation section and, space permitting, include one or two representative metrics. revision: partial
-
Referee: [§4] §4 (runtime): the assertion that the distributed runtime remains agnostic to the strategy rests on the IR producing per-device plans, but no evidence is given that the runtime requires no strategy-specific logic when executing the DualPipe schedule or other novel compositions.
Authors: The runtime is intentionally strategy-agnostic because it only interprets the per-device plans emitted by the IR compiler. The revised §4 will add a description of the execution loop together with a reference to the DualPipe example (updated in §3) to show explicitly that no strategy-specific code paths are present. revision: yes
Circularity Check
No circularity; claim rests on implemented system, not derivation
full rationale
The paper is a systems description of Piper, which uses a unified DAG IR, model annotations, and scheduling directives to produce per-device plans. No equations, parameters, or mathematical derivations appear in the abstract or described content. The decoupling claim is justified by the runtime being strategy-agnostic and by empirical parity/gains on ZeRO and DualPipe, not by any step that reduces to its own inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked. This is a standard non-circular implementation claim for a programmable systems paper.
Axiom & Free-Parameter Ledger
invented entities (1)
-
unified global training DAG IR
no independent evidence
Reference graph
Works this paper leans on
-
[1]
DeepSpeed: Extreme-scale model training for every- one.https://www.microsoft.com/en-us/research/blog/deepspeed- extreme-scale-model-training-for-everyone
2025. DeepSpeed: Extreme-scale model training for every- one.https://www.microsoft.com/en-us/research/blog/deepspeed- extreme-scale-model-training-for-everyone
2025
-
[2]
torch.distributed.tensor.https://docs.pytorch.org/docs/stable/ distributed.tensor.html
2025. torch.distributed.tensor.https://docs.pytorch.org/docs/stable/ distributed.tensor.html. Package
2025
-
[3]
Murray, Benoit Steiner, Paul Tucker, Vijay Vasudevan, Pete Warden, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng
Martín Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irv- ing, Michael Isard, Manjunath Kudlur, Josh Levenberg, Rajat Monga, Sherry Moore, Derek G. Murray, Benoit Steiner, Paul Tucker, Vijay Vasudevan, Pete Warden, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. 2016. TensorFlow: a system f...
2016
-
[4]
Jason Ansel, Edward Yang, Horace He, Natalia Gimelshein, Animesh Jain, Michael Voznesensky, Bin Bao, Peter Bell, David Berard, Evgeni Burovski, Geeta Chauhan, Anjali Chourdia, Will Constable, Alban Desmaison, Zachary DeVito, Elias Ellison, Will Feng, Jiong Gong, Michael Gschwind, Brian Hirsh, Sherlock Huang, Kshiteej Kalam- barkar, Laurent Kirsch, Michael...
-
[5]
Paul Barham, Aakanksha Chowdhery, Jeff Dean, Sanjay Ghemawat, Steven Hand, Dan Hurt, Michael Isard, Hyeontaek Lim, Ruom- ing Pang, Sudip Roy, Brennan Saeta, Parker Schuh, Ryan Sepa- ssi, Laurent El Shafey, Chandramohan A. Thekkath, and Yonghui Wu. 2022. Pathways: Asynchronous Distributed Dataflow for ML. arXiv:2203.12533 [cs.DC]https://arxiv.org/abs/2203.12533
arXiv 2022
-
[6]
James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, et al. 2021. Jax: Autograd and xla.Astrophysics Source Code Library(2021), ascl–2111
2021
-
[7]
Ruisheng Cao, Mouxiang Chen, Jiawei Chen, Zeyu Cui, Yunlong Feng, Binyuan Hui, Yuheng Jing, Kaixin Li, Mingze Li, Junyang Lin, Zeyao Ma, Kashun Shum, Xuwu Wang, Jinxi Wei, Jiaxi Yang, Jiajun Zhang, Lei Zhang, Zongmeng Zhang, Wenting Zhao, and Fan Zhou. 2026. Qwen3-Coder-Next Technical Report. arXiv:2603.00729 [cs.CL]https: //arxiv.org/abs/2603.00729
Pith/arXiv arXiv 2026
-
[8]
Li-Wen Chang, Wenlei Bao, Qi Hou, Chengquan Jiang, Ningxin Zheng, Yinmin Zhong, Xuanrun Zhang, Zuquan Song, Chengji Yao, Ziheng Jiang, et al. 2024. Flux: Fast software-based communication overlap on gpus through kernel fusion.arXiv preprint arXiv:2406.06858(2024)
arXiv 2024
-
[9]
Chang Chen, Xiuhong Li, Qianchao Zhu, Jiangfei Duan, Peng Sun, Xingcheng Zhang, and Chao Yang. 2024. Centauri: Enabling efficient scheduling for communication-computation overlap in large model training via communication partitioning. InProceedings of the 29th ACM International Conference on Architectural Support for Program- ming Languages and Operating ...
2024
-
[10]
Hongzheng Chen, Cody Hao Yu, Shuai Zheng, Zhen Zhang, Zhiru Zhang, and Yida Wang. 2024. Slapo: A schedule language for progres- sive optimization of large deep learning model training. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 1095–1111
2024
-
[11]
Yan, Leyuan Wang, Yuwei Hu, Luis Ceze, Carlos Guestrin, and Arvind Krishnamurthy
Tianqi Chen, Thierry Moreau, Ziheng Jiang, Haichen Shen, Eddie Q. Yan, Leyuan Wang, Yuwei Hu, Luis Ceze, Carlos Guestrin, and Arvind Krishnamurthy. 2018. TVM: End-to-End Optimization Stack for Deep Learning.CoRRabs/1802.04799 (2018). arXiv:1802.04799http://arxiv. org/abs/1802.04799
Pith/arXiv arXiv 2018
-
[12]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huaj...
Pith/arXiv arXiv 2025
-
[13]
Megan Frisella, Arvin Oentoro, Xiangyu Gao, Gilbert Bernstein, and Stephanie Wang. 2025. Piper: Towards Flexible Pipeline Parallelism for PyTorch. InProceedings of the 4th Workshop on Practical Adop- tion Challenges of ML for Systems(Seoul, Republic of Korea)(PACMI ’25). Association for Computing Machinery, New York, NY, USA, 1–6. doi:10.1145/3766882.3767187
-
[14]
Ahan Gupta, Zhihao Wang, Neel Dani, Masahiro Tanaka, Olatunji Ruwase, and Minjia Zhang. [n. d.]. AutoSP: Unlocking Long-Context LLM Training Via Compiler-Based Sequence Parallelism. InThe Four- teenth International Conference on Learning Representations
-
[15]
Aaron Harlap, Deepak Narayanan, Amar Phanishayee, Vivek Seshadri, Nikhil Devanur, Greg Ganger, and Phil Gibbons. 2018. PipeDream: Fast and Efficient Pipeline Parallel DNN Training. arXiv:1806.03377 [cs.DC] https://arxiv.org/abs/1806.03377
Pith/arXiv arXiv 2018
-
[16]
Weifang Hu, Langshi Chen, Man Yuan, Youyang Yao, Xiulong Yuan, Li Tian, Yong Li, Wei Lin, Xuanhua Shi, Zhengping Qian, and Jingren Zhou. 2026. Tessera: A Holistic Pipeline Parallelism Framework for Trillion-Parameter Heterogeneous MoE Training. InProceedings of the 20th USENIX Symposium on Operating Systems Design and Imple- mentation (OSDI ’26). To appear. 13
2026
-
[17]
Le, Yonghui Wu, and Zhifeng Chen
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Mia Xu Chen, Dehao Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V. Le, Yonghui Wu, and Zhifeng Chen. 2019.GPipe: efficient training of giant neural networks using pipeline parallelism. Curran Associates Inc., Red Hook, NY, USA
2019
-
[18]
Abhinav Jangda, Jun Huang, Guodong Liu, Amir Hossein Nodehi Sa- bet, Saeed Maleki, Youshan Miao, Madanlal Musuvathi, Todd Mytkow- icz, and Olli Saarikivi. 2022. Breaking the computation and communica- tion abstraction barrier in distributed machine learning workloads. In Proceedings of the 27th ACM International Conference on Architectural Support for Pro...
2022
-
[19]
Zhihao Jia, Matei Zaharia, and Alex Aiken. 2019. Beyond data and model parallelism for deep neural networks.Proceedings of Machine Learning and Systems1 (2019), 1–13
2019
-
[20]
Zhiquan Lai, Shengwei Li, Xudong Tang, Keshi Ge, Weijie Liu, Yabo Duan, Linbo Qiao, and Dongsheng Li. 2023. Merak: An efficient distributed dnn training framework with automated 3d parallelism for giant foundation models.IEEE Transactions on Parallel and Distributed Systems34, 5 (2023), 1466–1478
2023
-
[21]
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. 2020. Gshard: Scaling giant models with conditional computation and automatic sharding.arXiv preprint arXiv:2006.16668 (2020)
Pith/arXiv arXiv 2020
-
[22]
Shen Li, Yanli Zhao, Rohan Varma, Omkar Salpekar, Pieter Noordhuis, Teng Li, Adam Paszke, Jeff Smith, Brian Vaughan, Pritam Damania, and Soumith Chintala. 2020. PyTorch Distributed: Experiences on Accelerating Data Parallel Training. arXiv:2006.15704 [cs.DC]https: //arxiv.org/abs/2006.15704
Pith/arXiv arXiv 2020
-
[23]
Wanchao Liang, Tianyu Liu, Less Wright, Will Constable, Andrew Gu, Chien-Chin Huang, Iris Zhang, Wei Feng, Howard Huang, Junjie Wang, Sanket Purandare, Gokul Nadathur, and Stratos Idreos. 2025. TorchTitan: One-stop PyTorch native solution for production ready LLM pretraining. InThe Thirteenth International Conference on Learn- ing Representations.https://...
2025
-
[24]
Lightning.ai. [n. d.]. Faster PyTorch Training by Reducing Peak Mem- ory (combining backward pass + optimizer step) - Lightning AI — lightning.ai.https://lightning.ai/pages/community/tutorial/faster- pytorch-training-by-reducing-peak-memory/. [Accessed 23-04- 2026]
2026
-
[25]
Zhiqi Lin, Youshan Miao, Quanlu Zhang, Fan Yang, Yi Zhu, Cheng Li, Saeed Maleki, Xu Cao, Ning Shang, Yilei Yang, et al . 2024. {nnScaler}:{Constraint-Guided} Parallelization Plan Generation for Deep Learning Training. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 347–363
2024
-
[26]
Guodong Liu, Youshan Miao, Zhiqi Lin, Xiaoxiang Shi, Saeed Maleki, Fan Yang, Yungang Bao, and Sa Wang. 2024. Aceso: Efficient parallel DNN training through iterative bottleneck alleviation. InProceedings of the Nineteenth European Conference on Computer Systems. 163–181
2024
-
[27]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual Instruction Tuning. InAdvances in Neural Information Pro- cessing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. Curran Associates, Inc., 34892– 34916.https://proceedings.neurips.cc/paper_files/paper/2023/file/ 6dcf277ea32ce3288914faf369fe6...
2023
-
[28]
Xupeng Miao, Yujie Wang, Youhe Jiang, Chunan Shi, Xiaonan Nie, Hailin Zhang, and Bin Cui. 2022. Galvatron: Efficient transformer training over multiple gpus using automatic parallelism.arXiv preprint arXiv:2211.13878(2022)
arXiv 2022
-
[29]
Deepak Narayanan, Amar Phanishayee, Kaiyu Shi, Xie Chen, and Matei Zaharia. 2021. Memory-Efficient Pipeline-Parallel DNN Train- ing. InProceedings of the 38th International Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 139), Marina Meila and Tong Zhang (Eds.). PMLR, 7937–7947.https://proceedings. mlr.press/v139/narayanan21a.html
2021
-
[30]
Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGresley, Mostofa Patwary, Vijay Anand Korthikanti, Dmitri Vain- brand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catanzaro, Amar Phanishayee, and Matei Zaharia. 2021. Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM. arXiv:2104.04473 [cs.CL]https://arxiv.org/abs/2104.04473
arXiv 2021
-
[31]
NVIDIA. [n. d.]. NVIDIA Collective Communications Library (NCCL). https://developer.nvidia.com/nccl
-
[32]
Yi Pan, Yile Gu, Jinbin Luo, Yibo Wu, Ziren Wang, Hongtao Zhang, Ziyi Xu, Shengkai Lin, Baris Kasikci, and Stephanie Wang. 2026. DynaFlow: Transparent and Flexible Intra-Device Parallelism via Programmable Operator Scheduling.Proceedings of Machine Learning and Systems. To appear
2026
-
[33]
Yanghua Peng, Yibo Zhu, Yangrui Chen, Yixin Bao, Bairen Yi, Chang Lan, Chuan Wu, and Chuanxiong Guo. 2019. A generic communication scheduler for distributed DNN training acceleration. InProceedings of the 27th ACM Symposium on Operating Systems Principles. 16–29
2019
-
[34]
Penghui Qi, Xinyi Wan, Guangxing Huang, and Min Lin. 2023. Zero Bubble Pipeline Parallelism.ArXivabs/2401.10241 (2023).https: //api.semanticscholar.org/CorpusID:267060979
arXiv 2023
-
[35]
Penghui Qi, Xinyi Wan, Guangxing Huang, and Min Lin. 2025. DualPipe could be better without the Dual.https://hackmd.io/ @ufotalent/r1lVXsa9Jg. Blog
2025
-
[36]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Su- pervision. InProceedings of the 38th International Conference on Ma- chine Learning (Proceedings of Mac...
2021
-
[37]
Jonathan Ragan-Kelley, Connelly Barnes, Andrew Adams, Sylvain Paris, Frédo Durand, and Saman Amarasinghe. 2013. Halide: a lan- guage and compiler for optimizing parallelism, locality, and recompu- tation in image processing pipelines.SIGPLAN Not.48, 6 (June 2013), 519–530. doi:10.1145/2499370.2462176
-
[38]
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He
-
[39]
arXiv:1910.02054 http://arxiv.org/abs/1910.02054
ZeRO: Memory Optimization Towards Training A Trillion Parameter Models.CoRRabs/1910.02054 (2019). arXiv:1910.02054 http://arxiv.org/abs/1910.02054
Pith/arXiv arXiv 1910
-
[40]
James Reed, Pavel Belevich, Ke Wen, Howard Huang, and Will Con- stable. 2022. PiPPy: Pipeline Parallelism for PyTorch.https://github. com/pytorch/PiPPy
2022
-
[41]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2019. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. CoRRabs/1909.08053 (2019). arXiv:1909.08053http://arxiv.org/abs/ 1909.08053
Pith/arXiv arXiv 2019
-
[42]
Zhenbo Sun, Huanqi Cao, Yuanwei Wang, Guanyu Feng, Shengqi Chen, Haojie Wang, and Wenguang Chen. 2024. Adapipe: Optimizing pipeline parallelism with adaptive recomputation and partitioning. In Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3. 86–100
2024
-
[43]
Masahiro Tanaka, Du Li, Umesh Chand, Ali Zafar, Haiying Shen, and Olatunji Ruwase. 2025. DeepCompile: A Compiler-Driven Approach to Optimizing Distributed Deep Learning Training.arXiv preprint arXiv:2504.09983(2025)
arXiv 2025
-
[44]
Jakub M Tarnawski, Deepak Narayanan, and Amar Phanishayee. 2021. Piper: Multidimensional planner for dnn parallelization.Advances in Neural Information Processing Systems34 (2021), 24829–24840
2021
-
[45]
Colin Unger, Zhihao Jia, Wei Wu, Sina Lin, Mandeep Baines, Carlos Efrain Quintero Narvaez, Vinay Ramakrishnaiah, Nirmal Prajapati, Pat 14 McCormick, Jamaludin Mohd-Yusof, et al. 2022. Unity: Accelerating {DNN} training through joint optimization of algebraic transforma- tions and parallelization. In16th USENIX Symposium on Operating Systems Design and Imp...
2022
-
[46]
Minjie Wang, Chien-chin Huang, and Jinyang Li. 2019. Supporting very large models using automatic dataflow graph partitioning. In Proceedings of the Fourteenth EuroSys Conference 2019. 1–17
2019
-
[47]
Shibo Wang, Jinliang Wei, Amit Sabne, Andy Davis, Berkin Ilbeyi, Blake Hechtman, Dehao Chen, Karthik Srinivasa Murthy, Marcello Maggioni, Qiao Zhang, et al . 2022. Overlap communication with dependent computation via decomposition in large deep learning models. InProceedings of the 28th ACM International Conference on Ar- chitectural Support for Programmi...
2022
-
[48]
Yifu Wang, Horace He, Less Wright, Luca Wehrstedt, Tianyu Liu, and Wanchao Liang. 2024. Distributed w/ TorchTi- tan: Introducing Async Tensor Parallelism in PyTorch. https://discuss.pytorch.org/t/distributed-w-torchtitan-introducing- async-tensor-parallelism-in-pytorch/209487. PyTorch Forum Post. Accessed: 2026-04-23
2024
-
[49]
Anxhelo Xhebraj, Sean Lee, Hanfeng Chen, and Vinod Grover. 2025. Scaling deep learning training with MPMD pipeline parallelism.Pro- ceedings of Machine Learning and Systems7 (2025)
2025
-
[50]
Yuanzhong Xu, HyoukJoong Lee, Dehao Chen, Blake Hechtman, Yanping Huang, Rahul Joshi, Maxim Krikun, Dmitry Lepikhin, Andy Ly, Marcello Maggioni, Ruoming Pang, Noam Shazeer, Shibo Wang, Tao Wang, Yonghui Wu, and Zhifeng Chen. 2021. GSPMD: General and Scalable Parallelization for ML Computation Graphs. arXiv:2105.04663 [cs.DC]https://arxiv.org/abs/2105.04663
Pith/arXiv arXiv 2021
-
[51]
Amy Yang, Jingyi Yang, Aya Ibrahim, Xinfeng Xie, Bangsheng Tang, Grigory Sizov, Jongsoo Park, and Jianyu Huang. 2025. Context Paral- lelism for Scalable Million-Token Inference. InProceedings of Machine Learning and Systems, M. Zaharia, G. Joshi, and Y. Lin (Eds.), Vol. 7. MLSys.https://proceedings.mlsys.org/paper_files/paper/2025/file/ 78834433edc3291f4c...
2025
-
[52]
Tailing Yuan, Yuliang Liu, Xucheng Ye, Shenglong Zhang, Jianchao Tan, Bin Chen, Chengru Song, and Di Zhang. 2024. Accelerating the training of large language models using efficient activation remate- rialization and optimal hybrid parallelism. In2024 USENIX Annual Technical Conference (USENIX ATC 24). 545–561
2024
-
[53]
Duzhen Zhang, Yahan Yu, Jiahua Dong, Chenxing Li, Dan Su, Chenhui Chu, and Dong Yu. 2024. MM-LLMs: Recent Advances in MultiModal Large Language Models. InFindings of the Association for Computa- tional Linguistics: ACL 2024, Lun-Wei Ku, Andre Martins, and Vivek Srikumar (Eds.). Association for Computational Linguistics, Bangkok, Thailand, 12401–12430. doi...
-
[54]
Zili Zhang, Yinmin Zhong, Yimin Jiang, Hanpeng Hu, Jianjian Sun, Zheng Ge, Yibo Zhu, Daxin Jiang, and Xin Jin. 2025. DistTrain: Ad- dressing Model and Data Heterogeneity with Disaggregated Training for Multimodal Large Language Models. InProceedings of the ACM SIGCOMM 2025 Conference(São Francisco Convent, Coimbra, Por- tugal)(SIGCOMM ’25). Association fo...
-
[55]
Chenggang Zhao, Shangyan Zhou, Liyue Zhang, Chengqi Deng, Zhean Xu, Yuxuan Liu, Kuai Yu, Jiashi Li, and Liang Zhao. 2025. DeepEP: an efficient expert-parallel communication library.https://github.com/ deepseek-ai/DeepEP
2025
-
[56]
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, Alban Desmaison, Can Balioglu, Pritam Damania, Bernard Nguyen, Geeta Chauhan, Yuchen Hao, Ajit Mathews, and Shen Li. 2023. Py- Torch FSDP: Experiences on Scaling Fully Sharded Data Parallel. arXiv:2304.11277 [cs.DC]https://arxiv...
Pith/arXiv arXiv 2023
-
[57]
Lianmin Zheng, Zhuohan Li, Hao Zhang, Yonghao Zhuang, Zhifeng Chen, Yanping Huang, Yida Wang, Yuanzhong Xu, Danyang Zhuo, Eric P Xing, et al. 2022. Alpa: Automating inter-and {Intra-Operator} parallelism for distributed deep learning. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). 559–578
2022
-
[58]
Zhanda Zhu, Christina Giannoula, Muralidhar Andoorveedu, Qidong Su, Karttikeya Mangalam, Bojian Zheng, and Gennady Pekhimenko
-
[59]
InProceedings of the Twentieth European Conference on Computer Systems
Mist: Efficient Distributed Training of Large Language Mod- els via Memory-Parallelism Co-Optimization. InProceedings of the Twentieth European Conference on Computer Systems. 1298–1316. 15
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.