Bridging Handheld and Teleoperated Supervision for Contact-Rich Manipulation via State-Gated Experts
Pith reviewed 2026-06-26 05:28 UTC · model grok-4.3
The pith
State-gated mixture of experts routes between handheld and targeted teleop data to raise contact-rich manipulation success by up to 36.7%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
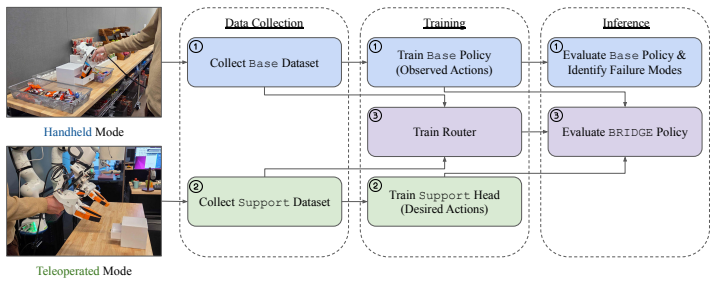
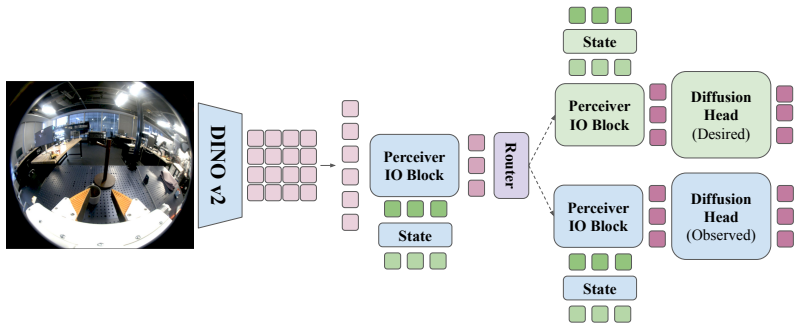
Rather than teleoperating entire tasks, partial teleoperated demonstrations collected only for segments where base handheld policies fail can be combined with handheld data through BRIDGE, a mixture of diffusion policy experts that routes between specialist task-phase heads conditioned on the current robot state. This enables task-phase specific use of desired actions during contact-sensitive segments and improves success rates over handheld-only baselines by up to 36.7% across three contact-rich manipulation tasks.
What carries the argument
BRIDGE (Bi-modal Routing for Imitation Data via Gated Experts): a mixture of diffusion policy experts whose heads are selected by a router conditioned on robot state.
If this is right
- Handheld trajectories supply valid supervision only in tolerant free-space phases.
- Teleoperated desired actions are required selectively in contact-sensitive phases to avoid large unsafe forces.
- Naive mixing of the two data types produces worse policies than handheld data alone.
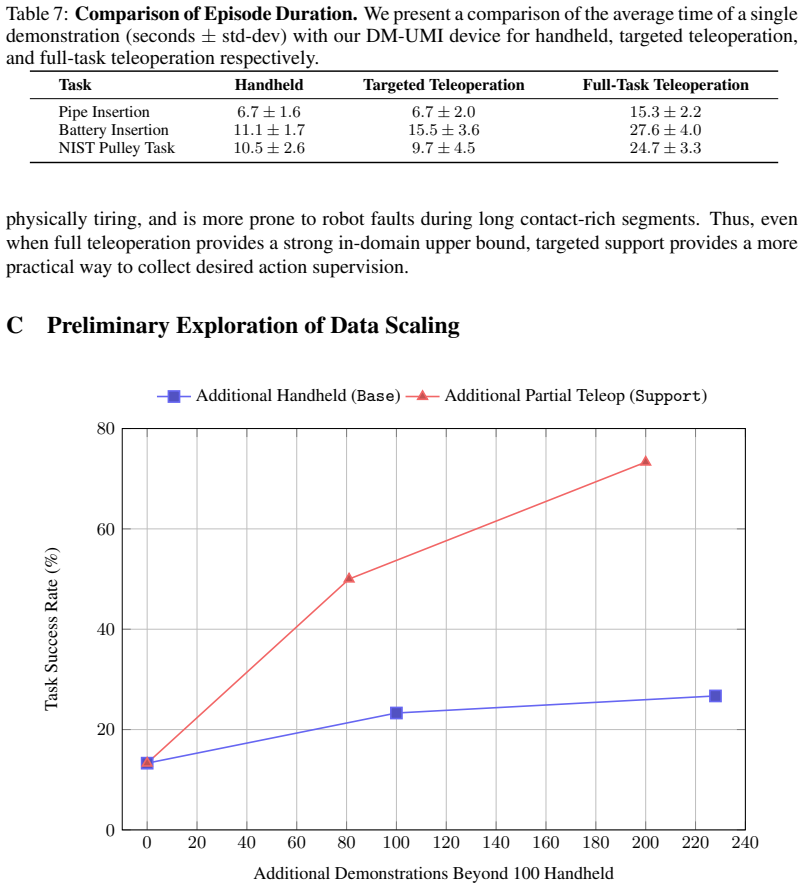
- Targeted collection of partial teleop demonstrations for failure segments yields an efficient hybrid dataset.
- State-conditioned routing permits correct expert selection without manual phase annotation.
Where Pith is reading between the lines
- The same routing logic could be tested on tasks that require more than two data sources or additional sensing modalities.
- If state observability varies across robots or environments, the method would need auxiliary inputs to maintain phase detection.
- The approach implies that imitation datasets can be assembled adaptively rather than collected uniformly.
Load-bearing premise
Robot state alone is sufficient to detect task phases and route to the correct expert without explicit phase labels or additional sensing.
What would settle it
On a new contact-rich task, measure whether state-based routing selects the wrong expert on a measurable fraction of trials and whether the resulting success rate falls to or below the handheld-only baseline.
Figures







read the original abstract
Handheld data collection systems, such as the Universal Manipulation Interface (UMI), enable scalable data collection across diverse environments but only capture observed actions rather than the desired actions executed by a robot controller. In contrast, teleoperation captures desired actions directly, but is prohibitively time-consuming to collect. We revisit this trade-off through the lens of action validity across task phases. We observe that handheld trajectories provide valid supervision in tolerant, free-space phases, but lack dynamic feasibility in contact-sensitive phases, where tracking observed trajectories at high stiffness produces large, unsafe contact forces. We study the interaction between these two supervision types for contact-rich manipulation and find that training policies that combine handheld data with a small number of targeted teleoperated demonstrations provide an efficient hybrid strategy. Specifically, rather than teleoperating the entire task, we only collect partial teleoperated demonstrations for task segments where base handheld policies fail. However, naively mixing handheld and teleoperated phase-specific data yields worse performance than training on handheld data alone. To address this mismatch between observed and desired supervision, we propose Bi-modal Routing for Imitation Data via Gated Experts (BRIDGE), a mixture of diffusion policy experts that routes between specialist task phase heads conditioned on the current robot state. Notably, our approach enables task-phase specific use of desired actions during contact sensitive segments and improves success rates over handheld-only baselines by up to 36.7% across three contact-rich manipulation tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes BRIDGE (Bi-modal Routing for Imitation Data via Gated Experts), a mixture-of-experts diffusion policy that routes between handheld-observed-action experts and teleoperated-desired-action experts conditioned solely on robot state. It claims that handheld data suffices for free-space phases but produces unsafe forces in contact phases, that naive mixing of the two data types degrades performance below handheld-only baselines, and that state-gated routing enables targeted use of teleop data to achieve up to 36.7% higher success rates across three contact-rich manipulation tasks.
Significance. If the empirical results and the state-only gating assumption hold under rigorous testing, the work would be significant for scalable imitation learning in robotics: it offers a practical hybrid data-collection strategy that reduces the need for full-task teleoperation while mitigating the dynamic infeasibility of observed actions during contact. The explicit contrast between observed and desired actions and the negative result for naive mixing are useful contributions.
major comments (2)
- [Abstract] Abstract: the central empirical claim (up to 36.7% success-rate improvement) is presented without any reported trial counts, statistical tests, baseline definitions, or failure-mode analysis, rendering it impossible to determine whether the data support the claim that BRIDGE outperforms both handheld-only and naive-mixing policies.
- [Abstract] Abstract and method description: the performance gain is load-bearing on the BRIDGE router correctly disambiguating task phases from robot state alone (without phase labels or additional sensing). No independent verification of gating accuracy, confusion-matrix analysis, or handling of ambiguous states is described, despite the paper noting that naive mixing hurts performance; this leaves open the possibility that observed gains arise from other factors.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our submission. We address each major comment below and commit to revisions that improve the clarity and rigor of the empirical claims and method validation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim (up to 36.7% success-rate improvement) is presented without any reported trial counts, statistical tests, baseline definitions, or failure-mode analysis, rendering it impossible to determine whether the data support the claim that BRIDGE outperforms both handheld-only and naive-mixing policies.
Authors: We agree that the abstract would be strengthened by including these details. In the revised version we will specify the evaluation protocol (20 trials per task per method, averaged over 3 seeds), explicitly name the baselines (handheld-only diffusion policy and naive mixing of all data), and note that failure-mode analysis (unsafe contact forces under handheld supervision) appears in Section 4.2. This makes the 36.7% figure traceable to the reported experiments without altering the numerical result. revision: yes
-
Referee: [Abstract] Abstract and method description: the performance gain is load-bearing on the BRIDGE router correctly disambiguating task phases from robot state alone (without phase labels or additional sensing). No independent verification of gating accuracy, confusion-matrix analysis, or handling of ambiguous states is described, despite the paper noting that naive mixing hurts performance; this leaves open the possibility that observed gains arise from other factors.
Authors: We acknowledge the value of an explicit gating analysis. The current manuscript shows that naive mixing degrades performance relative to handheld-only (Table 2) and provides qualitative routing visualizations, but does not report quantitative router accuracy against phase labels. In revision we will add an appendix with (i) router accuracy computed against contact-force-derived phase labels, (ii) a confusion matrix across the three tasks, and (iii) discussion of ambiguous states (e.g., near-contact transitions). This will directly address whether the observed gains are attributable to correct state-gated routing. revision: yes
Circularity Check
No circularity: purely empirical method with no derivations or self-referential claims
full rationale
The paper describes an empirical approach (BRIDGE: mixture of diffusion policy experts routed by robot state) for hybrid supervision in contact-rich tasks. No equations, derivations, fitted parameters renamed as predictions, or uniqueness theorems appear in the provided text. The central claim is an observed success-rate improvement (up to 36.7%) over baselines, which is externally falsifiable via experiments and does not reduce to any input by construction. Self-citations, if present, are not load-bearing for any mathematical result. This matches the default expectation for non-circular empirical ML papers.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Handheld trajectories provide valid supervision in tolerant free-space phases but lack dynamic feasibility in contact-sensitive phases
- domain assumption Naively mixing handheld and teleoperated phase-specific data yields worse performance than training on handheld data alone
Reference graph
Works this paper leans on
-
[1]
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song. Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots.arXiv preprint arXiv:2402.10329, 2024
Pith/arXiv arXiv 2024
-
[2]
P. Wu, Y . Shentu, Z. Yi, X. Lin, and P. Abbeel. Gello: A general, low-cost, and intuitive teleoperation framework for robot manipulators.arXiv preprint arXiv:2309.13037, 2023
arXiv 2023
-
[3]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
Pith/arXiv arXiv 2023
-
[4]
Assembly performance metrics and test methods.https://www.nist.gov/el/intelligent-systems-division-73500/ robotic-grasping-and-manipulation-assembly/assembly, 2026
National Institute of Standards and Technology. Assembly performance metrics and test methods.https://www.nist.gov/el/intelligent-systems-division-73500/ robotic-grasping-and-manipulation-assembly/assembly, 2026. Accessed: 2026- 05-19
2026
-
[5]
O. X.-E. Collaboration. Open x-embodiment: Robotic learning datasets and rt-x models.arXiv preprint arXiv:2310.08864, 2023
Pith/arXiv arXiv 2023
-
[6]
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, Y . Zhu, C. Finn, S. Levine, and P. Liang. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
Pith/arXiv arXiv 2024
-
[7]
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
Pith/arXiv arXiv 2024
-
[8]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al. Pi0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[9]
L. Wang, X. Chen, J. Zhao, and K. He. Scaling proprioceptive-visual learning with hetero- geneous pre-trained transformers. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[10]
Doshi, H
R. Doshi, H. Walke, O. Mees, S. Dasari, and S. Levine. Scaling cross-embodied learning: One policy for manipulation, navigation, locomotion and aviation. InConference on Robot Learning (CoRL), 2024
2024
-
[11]
L. Y . Chen, C. Xu, K. Dharmarajan, R. Cheng, K. Keutzer, M. Tomizuka, Q. Vuong, and K. Goldberg. Mirage: Cross-embodiment zero-shot policy transfer with cross-painting. In Robotics: Science and Systems (RSS), 2024
2024
-
[12]
Z. Fu, Q. Zhao, Q. Wu, G. Wetzstein, and C. Finn. HumanPlus: Humanoid shadowing and imitation from humans. InConference on Robot Learning (CoRL), 2024
2024
-
[13]
Torne, A
M. Torne, A. Simeonov, Z. Li, A. Chan, T. Chen, A. Gupta, and P. Agrawal. Reconciling re- ality through simulation: A real-to-sim-to-real approach for robust manipulation. InRobotics: Science and Systems (RSS), 2024
2024
-
[14]
Mandlekar, S
A. Mandlekar, S. Nasiriany, B. Wen, I. Akinola, Y . Narang, L. Fan, Y . Zhu, and D. Fox. Mimicgen: A data generation system for scalable robot learning using human demonstrations. InConference on Robot Learning (CoRL), 2023
2023
-
[15]
Mandlekar, D
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Mart´ın-Mart´ın. What matters in learning from offline human demonstrations for robot manipulation. InConference on Robot Learning (CoRL), 2021. 9
2021
-
[16]
S. Ross, G. Gordon, and D. Bagnell. A reduction of imitation learning and structured predic- tion to no-regret online learning. InInternational Conference on Artificial Intelligence and Statistics (AISTATS), 2011
2011
-
[17]
Kelly, C
M. Kelly, C. Sidrane, K. Driggs-Campbell, and M. J. Kochenderfer. Hg-dagger: Interactive imitation learning with human experts.IEEE International Conference on Robotics and Au- tomation (ICRA), 2019
2019
-
[18]
Hoque, A
R. Hoque, A. Balakrishna, E. Novoseller, A. Wilcox, D. S. Brown, and K. Goldberg. ThriftyDAgger: Budget-aware novelty and risk gating for interactive imitation learning. In Conference on Robot Learning (CoRL), 2021
2021
-
[19]
Spencer, S
J. Spencer, S. Choudhury, M. Barnes, M. Schmittle, M. Chiang, P. Ramadge, and S. Srinivasa. Learning from interventions: Human-robot interaction as both explicit and implicit feedback. InRobotics: Science and Systems (RSS), 2020
2020
-
[20]
A. Mandlekar, D. Xu, R. Mart ´ın-Mart´ın, Y . Zhu, L. Fei-Fei, and S. Savarese. Human-in-the- loop imitation learning using remote teleoperation.arXiv preprint arXiv:2012.06733, 2020
arXiv 2012
-
[21]
H. Liu, S. Nasiriany, L. Zhang, Z. Bao, and Y . Zhu. Robot learning on the job: Human-in- the-loop autonomy and learning during deployment. InRobotics: Science and Systems (RSS), 2023
2023
-
[22]
T. Silver, K. Allen, J. Tenenbaum, and L. Kaelbling. Residual policy learning.arXiv preprint arXiv:1812.06298, 2018
Pith/arXiv arXiv 2018
-
[23]
Johannink, S
T. Johannink, S. Bahl, A. Nair, J. Luo, A. Kumar, M. Loskyll, J. A. Ojea, E. Solowjow, and S. Levine. Residual reinforcement learning for robot control. InIEEE International Conference on Robotics and Automation (ICRA), 2019
2019
-
[24]
X. Xu, Y . Hou, C. Xin, Z. Liu, and S. Song. Compliant residual DAgger: Improving real-world contact-rich manipulation with human corrections.arXiv preprint arXiv:2506.16685, 2025
arXiv 2025
-
[25]
Y . Huang, N. Ma, W. Zhao, Z. Liu, J. Sun, Q. Wang, and Y . Chen. Force-aware residual dagger via trajectory editing for precision insertion with impedance control, 2026. URLhttps: //arxiv.org/abs/2603.04038
Pith/arXiv arXiv 2026
-
[26]
N. Shazeer, A. Mirhoseini, K. Maziarz, A. Davis, Q. Le, G. Hinton, and J. Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer, 2017. URLhttps:// arxiv.org/abs/1701.06538
Pith/arXiv arXiv 2017
-
[27]
C. Hao, X. Zhai, Y . Liu, and H. Soh. Abstracting robot manipulation skills via mixture-of- experts diffusion policies, 2026. URLhttps://arxiv.org/abs/2601.21251
arXiv 2026
-
[28]
K. Guo, H. Liu, Y . Sun, R. Zhao, J. Zhou, and J. Ma. Moe-act: Scaling multi-task bimanual manipulation with sparse language-conditioned mixture-of-experts transformers, 2026. URL https://arxiv.org/abs/2603.15265
arXiv 2026
-
[29]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[30]
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haz- iza, F. Massa, A. El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023
Pith/arXiv arXiv 2023
-
[31]
A. Jaegle, S. Borgeaud, J.-B. Alayrac, C. Doersch, C. Ionescu, D. Ding, S. Koppula, D. Zoran, A. Brock, E. Shelhamer, et al. Perceiver io: A general architecture for structured inputs & outputs.arXiv preprint arXiv:2107.14795, 2021. 10 A Implementation Details We present the training, pre-processing, model, and optimization details for our baselines and m...
Pith/arXiv arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.