Right in the Right Way: LM Training with Verifiable Rewards and Human Demonstrations
Pith reviewed 2026-07-02 15:12 UTC · model grok-4.3
The pith
An adversarial discriminator trained on human demonstrations augments RLVR to improve non-verifiable output qualities like style while preserving verifiable accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A generator policy is trained by RL to maximize both a verifiable task reward and an adversarial reward from a discriminator that is trained to separate human demonstrations from model generations; the discriminator acts as a learned proxy for the human output distribution and supplies gradient signal on subjective properties such as style, structure, and diversity.
What carries the argument
Adversarial generator-discriminator framework in which the discriminator provides a learned proxy reward for human-like output properties alongside the verifiable task reward.
If this is right
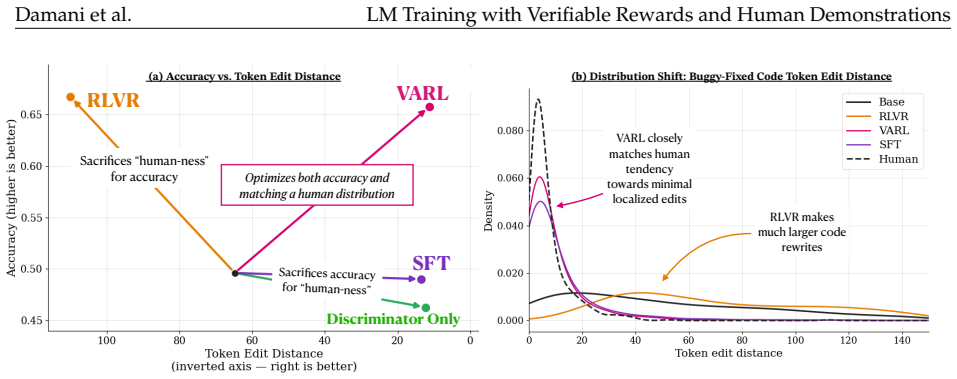
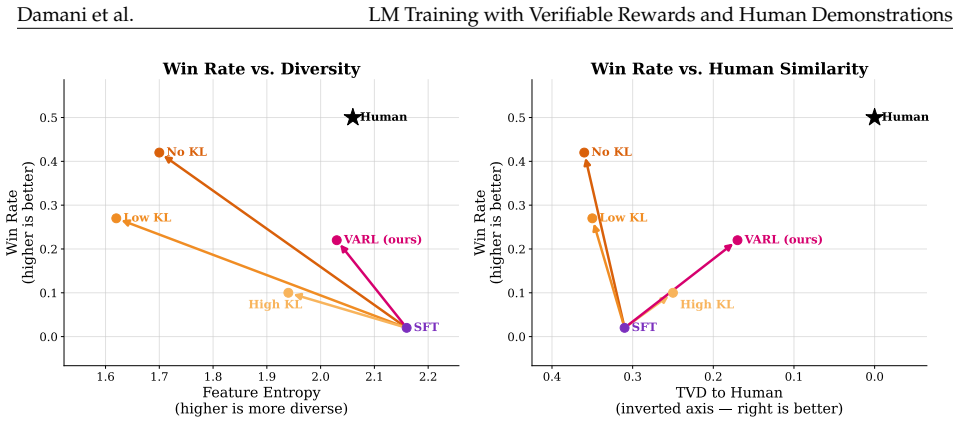
- Bug-fixing solutions exhibit significantly lower edit distance to human references while matching end-task performance.
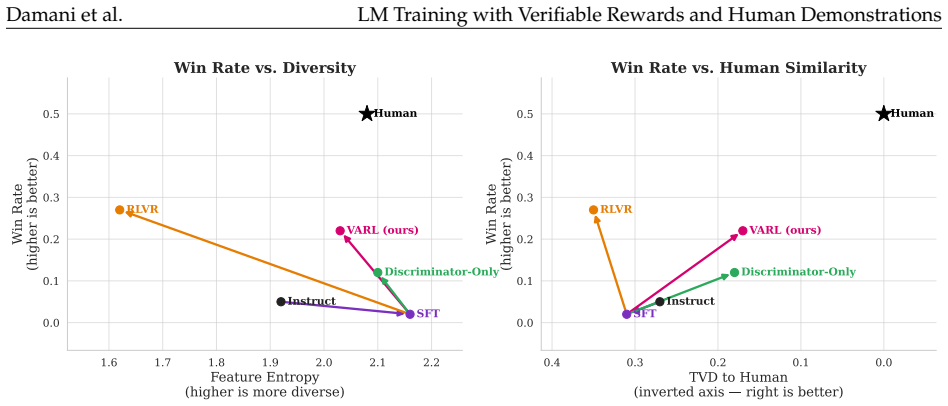
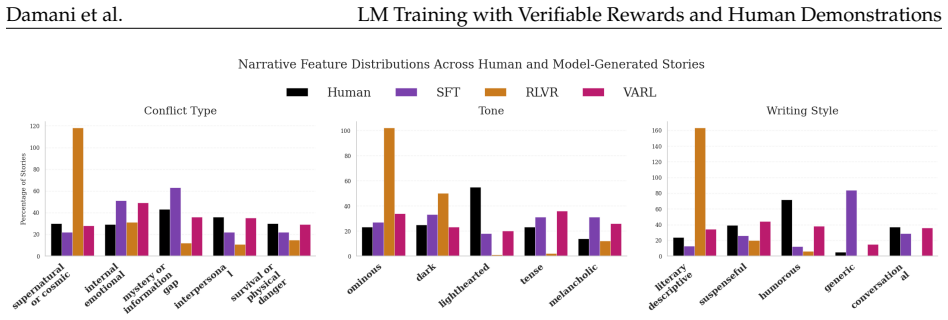
- Story generation achieves higher human win rates together with greater diversity and more human-like qualities.
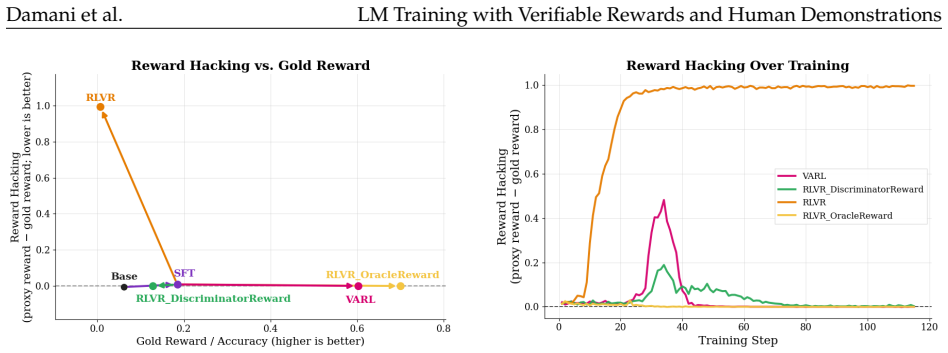
- A simple reward-hacking benchmark shows near-elimination of model misbehavior while benchmark scores remain high.
- The method supplies a route that jointly optimizes verifiable and non-verifiable task properties.
Where Pith is reading between the lines
- The same discriminator signal could be added to other RLVR domains where output naturalness matters, such as dialogue or summarization.
- Using demonstrations directly may lower the amount of preference data needed compared with separate reward-model training.
- The framework offers one concrete way to move from pure accuracy optimization toward outputs that better match the full human distribution.
Load-bearing premise
The discriminator trained on human demonstrations remains a stable proxy for the human distribution and does not create new instabilities or shifts that weaken the verifiable reward signal.
What would settle it
Training runs in which the combined objective produces lower verifiable accuracy than pure RLVR, or in which the discriminator reward leads to new forms of hacking on the non-verifiable aspects.
Figures






read the original abstract
RL with verifiable rewards (RLVR) has emerged as a powerful paradigm for training LMs on tasks with well-defined success metrics, such as code generation and mathematical reasoning. However, current RLVR methods optimize only what can be objectively scored, often neglecting subjective, non-verifiable aspects of human-like outputs, such as style and structure. This limitation leads to well-documented failure modes such as diversity collapse, unnatural-sounding responses, and reward hacking. We propose an adversarial generator-discriminator framework that augments verifiable rewards with a learned signal from human demonstrations. A generator model is trained using RL to maximize both task accuracy and an adversarial reward derived from a discriminator. The discriminator, trained alongside the generator policy, learns to distinguish human-written outputs from model-generated ones. The discriminator serves as a learned proxy for the human output distribution, providing feedback on aspects of generation that are difficult to formalize as scalar rewards. Across diverse domains, including bug fixing and open-ended generation, our approach consistently improves non-verifiable properties while preserving the accuracy gains of RLVR. In bug fixing, our method produces solutions with significantly lower edit distance compared to RLVR baselines while matching end performance. In story generation, our method significantly improves win rate while producing stories that are diverse and more human-like. And in a simple reward hacking benchmark, our method nearly eliminates model misbehavior while maintaining high benchmark scores. Together, these results show that our approach bridges RL and SFT, offering a scalable path toward jointly optimizing the verifiable and non-verifiable properties of a task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an adversarial generator-discriminator framework that augments RL with verifiable rewards (RLVR) by training a discriminator on human demonstrations to provide a learned signal for non-verifiable output properties such as style and structure. The generator policy is optimized via RL to maximize both the verifiable task reward and the adversarial reward from the discriminator. Experiments are described in bug fixing (lower edit distance with matched end performance), story generation (higher win rate with more diverse and human-like outputs), and a reward-hacking benchmark (near-elimination of misbehavior while maintaining high scores), with the central claim that non-verifiable properties improve while verifiable accuracy gains from RLVR are preserved.
Significance. If the empirical claims are substantiated with detailed ablations and controls, the work would offer a concrete mechanism for jointly optimizing verifiable task metrics and human-like qualities in LM training, addressing documented RLVR pathologies such as diversity collapse and reward hacking without requiring fully specified scalar rewards for the latter.
major comments (3)
- [Abstract] Abstract: the central claim that the method 'consistently improves non-verifiable properties while preserving the accuracy gains of RLVR' is asserted without any quantitative metrics, baseline comparisons, statistical tests, or ablation results. This absence is load-bearing because the preservation of verifiable performance is the key differentiator from standard RLVR and must be demonstrated explicitly rather than stated.
- [Method] Method description (inferred from abstract): no specification is given for how the verifiable reward and the discriminator-derived adversarial reward are combined during policy optimization (additive, weighted sum, scheduled, etc.), nor for the relative frequencies of discriminator and policy updates. Without these details it is impossible to evaluate whether the two signals conflict or whether the discriminator remains a stable proxy rather than introducing instabilities or distribution shift that could erode verifiable accuracy.
- [Experiments] Experiments (bug fixing, story generation, reward-hacking sections): the abstract reports qualitative improvements ('significantly lower edit distance', 'significantly improves win rate', 'nearly eliminates model misbehavior') but supplies neither the exact numerical values, the RLVR baselines used for comparison, nor any ablation isolating the contribution of the adversarial term to verifiable metrics. These omissions prevent assessment of whether the claimed preservation of accuracy is robust.
minor comments (1)
- [Abstract] The abstract uses the term 'significantly' for improvements without accompanying p-values, confidence intervals, or effect sizes, which is a presentation issue that should be corrected once the quantitative results are added.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight areas where additional clarity will strengthen the manuscript. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the method 'consistently improves non-verifiable properties while preserving the accuracy gains of RLVR' is asserted without any quantitative metrics, baseline comparisons, statistical tests, or ablation results. This absence is load-bearing because the preservation of verifiable performance is the key differentiator from standard RLVR and must be demonstrated explicitly rather than stated.
Authors: We agree that the abstract would be strengthened by including representative quantitative metrics. The experiments section contains the supporting numerical results, baselines, and ablations; we will revise the abstract to incorporate key values (e.g., edit distances, win rates) and note the preservation of verifiable performance with reference to those results. revision: yes
-
Referee: [Method] Method description (inferred from abstract): no specification is given for how the verifiable reward and the discriminator-derived adversarial reward are combined during policy optimization (additive, weighted sum, scheduled, etc.), nor for the relative frequencies of discriminator and policy updates. Without these details it is impossible to evaluate whether the two signals conflict or whether the discriminator remains a stable proxy rather than introducing instabilities or distribution shift that could erode verifiable accuracy.
Authors: The current method description presents the framework at a conceptual level. We will expand it to specify that the rewards are combined via a fixed weighted sum (with the weighting coefficient reported) and to detail the alternating update schedule between discriminator and policy, thereby clarifying stability and potential interactions between the signals. revision: yes
-
Referee: [Experiments] Experiments (bug fixing, story generation, reward-hacking sections): the abstract reports qualitative improvements ('significantly lower edit distance', 'significantly improves win rate', 'nearly eliminates model misbehavior') but supplies neither the exact numerical values, the RLVR baselines used for comparison, nor any ablation isolating the contribution of the adversarial term to verifiable metrics. These omissions prevent assessment of whether the claimed preservation of accuracy is robust.
Authors: The experiments section reports the numerical results, RLVR baselines, and ablations isolating the adversarial contribution. To address the concern directly, we will add explicit numerical values and ablation summaries to the abstract and ensure the experiments section prominently displays the verifiable-metric ablations with statistical comparisons. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper defines a method that augments RLVR with an adversarial discriminator trained on external human demonstrations to provide a learned proxy reward for non-verifiable properties. All load-bearing claims (improved edit distance, win rates, reduced hacking while preserving accuracy) are presented as empirical outcomes from experiments on bug fixing, story generation, and a hacking benchmark. No equations, derivations, or self-citations reduce the central result to a fitted parameter or input by construction; the verifiable rewards and human data remain independent external signals. This is the most common honest finding for an empirical methods paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Morgan Kaufmann Publishers Inc. ISBN 1558607072. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022. Julian Aron Prenn...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[2]
Black-box on-policy distillation of large language models.arXiv preprint arXiv:2511.10643,
URLhttps://openreview.net/forum?id=1MUZsrJxi9. Tianzhu Ye, Li Dong, Zewen Chi, Xun Wu, Shaohan Huang, and Furu Wei. Black-box on-policy distillation of large language models, 2026. URLhttps://arxiv.org/abs/2511.10643. Lantao Yu, Weinan Zhang, Jun Wang, and Yong Yu. Seqgan: sequence generative adversarial nets with policy gradient. InProceedings of the Thi...
-
[3]
29 + 54 - 2
A simple solution is 29 + 54 = 83, then 83 - 2 = 81, then 81 + 2 = 83 - 2 + 2 = 56. This uses all three numbers. We’ll set expr = “29 + 54 - 2”. We leave test.py unchanged so that the existing verification remains correct. </think> { “solution.py”: “numbers = [2, 29, 54] target = 56 expr = \“29 + 54 - 2\“”, 25 Damani et al. LM Training with Verifiable Rew...
-
[4]
Try: 54 - (29 - 2) = 54 - 27 = 27. Nope. Now try: (54 - 29) + 2 = 25 + 2 = 27. Nope. Try: (29 +
-
[5]
- 2 = 83 - 2 = 81. Nope. Try: 29 + (54 - 2) = 29 + 52 = 81. Nope. Try: (2 + 29) * 54 = 31 * 54 = 1674. Nope. Try: 54 + (29 / 2) = 54 + 14.5 = 68.5. Nope. Try: (54 / 2) - 29 = 27 - 29 = -2. Nope. Try: (54 + 2) / 29 = 56 / 29 = 1.931. Nope. Try: 54 / (29 - 2) = 54 / 27 = 2. Nope. Try: 54 - (29 /
-
[6]
= 54 - 14.5 = 39.5. Nope. Try: (29 * 2) - 54 = 58 - 54 = 4. Nope. Try: (54 / 2) + 29 = 27 + 29 =
-
[7]
(54/2) + 29
This works. So the expression “(54/2) + 29” uses each number once and evaluates to 56. </think> 26 Damani et al. LM Training with Verifiable Rewards and Human Demonstrations { “solution.py”: “numbers = [2, 29, 54] target = 56 expr = ’(54/2) + 29’ # edit this!”, “test.py”: “def verify_solution(numbers, target, expr) -> bool: import re try: # Extract all nu...
-
[8]
Plot & Structure (max 3 sentences) * Provide a concise summary of the story * Identify whether the story has a clear setup, conflict, climax, and resolution * Comment on how well-structured it is
-
[9]
Characterization (max 3 sentences) * Describe the main characters * Assess their depth, consistency, and development
-
[10]
Coherence & Logical Consistency (max 3 sentences) * Identify any plot holes, contradictions, or confusing elements * Comment on overall clarity and logical flow
-
[11]
Style & Expression (max 3 sentences) * Describe the tone (e.g., formal, humorous, dark) * Assess verbosity (concise vs repetitive) * Evaluate descriptive richness (imagery vs plain narration)
-
[12]
good story
Engagement & Originality (max 3 sentences) * Assess emotional impact (engaging, flat, etc.) * Evaluate originality (novel vs cliché) 29 Damani et al. LM Training with Verifiable Rewards and Human Demonstrations * Mention any particularly creative or predictable elements — GENERAL INSTRUCTIONS: * Each section MUST be at most 3 sentences (strict limit) * Pr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.