DRIVESPATIAL: A Benchmark for Spatiotemporal Intelligence in VLMs for Autonomous Driving
Pith reviewed 2026-05-25 05:08 UTC · model grok-4.3
The pith
Vision-language models trail humans by 28.4 points on a benchmark for spatiotemporal intelligence in autonomous driving
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
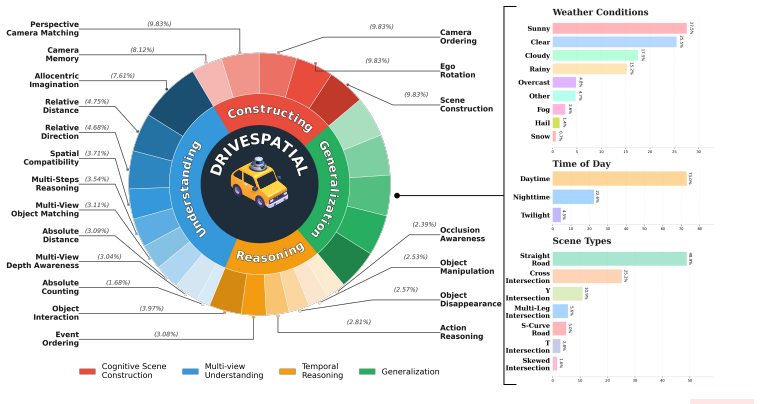
The paper establishes that current VLMs lack the scene-construction ability needed for reliable spatiotemporal driving intelligence, as shown by a 28.4-point gap between the strongest model and humans on the DriveSpatial benchmark, where cognitive scene construction emerges as the key bottleneck.
What carries the argument
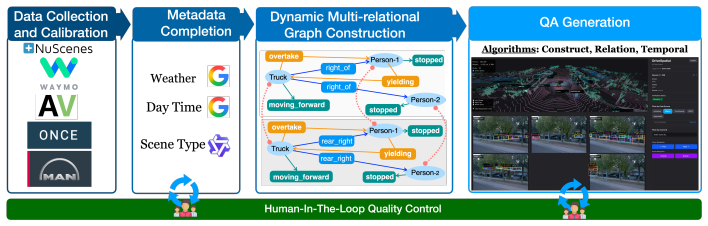
The dynamic multi-relational scene graph that encodes object states, spatial relations, interactions, camera visibility, and temporal correspondences to generate QA pairs enforcing genuine cross-view and spatiotemporal reasoning.
If this is right
- Explicit BEV grounding consistently improves VLM performance on the benchmark tasks.
- Language-only prompting is insufficient for achieving strong results on spatiotemporal driving questions.
- The benchmark isolates four distinct abilities that can be measured separately through its construction pipeline.
- Releasing DriveSpatial and its pipeline will enable targeted research on improving VLM scene construction for driving.
Where Pith is reading between the lines
- Architectures with explicit mechanisms for maintaining object continuity across views and time may be needed beyond current prompting approaches.
- The identified gap could motivate training methods that reward internal reconstruction of dynamic scenes rather than direct QA accuracy.
- Comparable limitations may appear in other multi-sensor temporal reasoning settings such as robotics navigation.
Load-bearing premise
The QA pairs generated from the dynamic multi-relational scene graph accurately isolate and test the four claimed abilities without allowing models to exploit shortcuts or dataset artifacts.
What would settle it
A VLM that reaches human-level accuracy on DriveSpatial using only its standard training and without any explicit scene construction mechanisms or graph-derived supervision would challenge the conclusion that current models inherently lack scene-construction ability.
Figures




read the original abstract
Spatiotemporal intelligence in autonomous driving (AD) requires an agent to integrate multi-view observations into a coherent scene representation, maintain object continuity across viewpoints and time, and reason about spatial relations, interactions, and future dynamics. However, existing AD vision-language benchmarks largely focus on single-view, static, ego-centric, or single-source question answering, leaving it unclear whether current Vision-Language Models (VLMs) can truly construct and reason over dynamic driving scenes. We introduce DriveSpatial, a benchmark of 15.6K human-verified QA pairs across 20 tasks from five large-scale AD datasets. DriveSpatial evaluates four abilities: Cognitive Scene Construction, Multi-view Relational Understanding, Temporal Reasoning, and Generalization. Unlike prior benchmarks, DriveSpatial is generated from a dynamic multi-relational scene graph that encodes object states, spatial relations, interactions, camera visibility, and temporal correspondences, enabling QA pairs that enforce genuine cross-view and spatiotemporal reasoning. Evaluating 15 representative VLMs reveals a substantial human-model gap: the strongest model trails humans by 28.4 points, with Cognitive Scene Construction emerging as the key bottleneck. Further diagnostics show that language-only prompting is insufficient, while explicit BEV grounding consistently improves performance. These results suggest that current VLMs lack the scene-construction ability needed for reliable spatiotemporal driving intelligence. DriveSpatial and its construction pipeline will be released to support future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DriveSpatial, a benchmark of 15.6K human-verified QA pairs spanning 20 tasks drawn from five large-scale autonomous driving datasets. The benchmark is constructed from a dynamic multi-relational scene graph that encodes object states, spatial relations, interactions, camera visibility, and temporal correspondences. It targets four abilities (Cognitive Scene Construction, Multi-view Relational Understanding, Temporal Reasoning, and Generalization) and evaluates 15 VLMs, reporting that the strongest model trails the human baseline by 28.4 points with Cognitive Scene Construction identified as the primary bottleneck. Additional diagnostics indicate that language-only prompting is insufficient while explicit BEV grounding improves results.
Significance. If the QA pairs validly isolate the four target abilities without permitting shortcut solutions, the reported human-model gap would constitute a clear empirical demonstration that current VLMs lack reliable scene-construction capabilities for spatiotemporal driving tasks. The public release of the benchmark and its construction pipeline would provide a reusable resource for the community.
major comments (2)
- [§3] §3 (Benchmark Construction): The claim that the dynamic multi-relational scene graph 'enables QA pairs that enforce genuine cross-view and spatiotemporal reasoning' is central to attributing the 28.4-point gap to missing scene-construction ability rather than benchmark artifacts. The manuscript describes human verification of factual correctness but supplies no explicit controls, adversarial testing, or ablation showing that individual questions cannot be solved via language priors, single-view cues, or dataset biases.
- [§4.3] §4.3 (Per-Ability Breakdown) and Table 2: The identification of Cognitive Scene Construction as the key bottleneck rests on the per-task accuracy tables. Without reported human error analysis or item-level validation that each of the 20 tasks requires the stated ability and resists non-spatiotemporal shortcuts, the attribution of the gap to this specific ability remains under-supported.
minor comments (2)
- [§4.1] The selection criteria and full list of the 15 evaluated VLMs are referenced in §4.1 but would benefit from an explicit table or appendix entry for reproducibility.
- [Figure 3] Figure 3 (example QA pairs) would be clearer with explicit annotation of which scene-graph relations are required to answer each question correctly.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, proposing revisions to strengthen the supporting evidence for our claims.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The claim that the dynamic multi-relational scene graph 'enables QA pairs that enforce genuine cross-view and spatiotemporal reasoning' is central to attributing the 28.4-point gap to missing scene-construction ability rather than benchmark artifacts. The manuscript describes human verification of factual correctness but supplies no explicit controls, adversarial testing, or ablation showing that individual questions cannot be solved via language priors, single-view cues, or dataset biases.
Authors: The dynamic multi-relational scene graph encodes cross-camera visibility, temporal object correspondences, and multi-relational facts by construction, so that questions are generated only when the required information spans multiple views or time steps; human verification then confirms factual correctness of the resulting QA pairs. We agree, however, that this design argument would be substantially strengthened by explicit controls. We will add an ablation subsection that includes (i) performance of language-only models on the full benchmark, (ii) single-view versus multi-view question subsets, and (iii) a small set of adversarial questions designed to be solvable by dataset bias alone. These additions will appear in the revised §3. revision: yes
-
Referee: [§4.3] §4.3 (Per-Ability Breakdown) and Table 2: The identification of Cognitive Scene Construction as the key bottleneck rests on the per-task accuracy tables. Without reported human error analysis or item-level validation that each of the 20 tasks requires the stated ability and resists non-spatiotemporal shortcuts, the attribution of the gap to this specific ability remains under-supported.
Authors: Task groupings were derived directly from the scene-graph properties used to generate each question (e.g., tasks requiring object-state fusion across cameras are labeled Cognitive Scene Construction). Human performance was collected on the identical item set to establish the reference. We acknowledge that an item-level analysis of shortcut resistance and human error patterns would provide stronger corroboration. We will therefore append, in the revised §4.3, (a) representative question examples annotated with the minimal scene-graph facts needed to answer them correctly and (b) a brief human-error categorization on a 200-item subsample. These changes will be reflected in an updated Table 2 caption and accompanying text. revision: yes
Circularity Check
No circularity: purely empirical benchmark with no derivations or self-referential reductions
full rationale
The paper constructs a benchmark of 15.6K QA pairs from a dynamic multi-relational scene graph and reports empirical VLM performance gaps against humans. No equations, fitted parameters, predictions, or first-principles derivations appear in the provided text. The claim that the graph enables QA pairs enforcing spatiotemporal reasoning is a construction description, not a reduction of an output to its inputs by definition or self-citation. The evaluation is externally benchmarked by human baselines and model scores, rendering the result self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The dynamic multi-relational scene graph accurately encodes object states, spatial relations, interactions, camera visibility, and temporal correspondences from the source AD datasets.
Reference graph
Works this paper leans on
-
[1]
Edward C Tolman, Benbow F Ritchie, and Donald Kalish. Studies in spatial learning. ii. place learning versus response learning.Journal of experimental psychology, 36(3):221, 1946
work page 1946
-
[2]
Cognitive maps in rats and men.Psychological review, 55(4):189, 1948
Edward C Tolman. Cognitive maps in rats and men.Psychological review, 55(4):189, 1948
work page 1948
-
[3]
The hippocampus and context revisited
Lynn Nadel. The hippocampus and context revisited. 2008
work page 2008
-
[4]
The effect of vehicle navigation systems on the formation of cognitive maps
Gary E Burnett and Kate Lee. The effect of vehicle navigation systems on the formation of cognitive maps. InInternational conference of traffic and transport psychology, 2005
work page 2005
-
[5]
Omnidrive: A holistic vision-language dataset for autonomous driving with counterfactual reasoning
Shihao Wang, Zhiding Yu, Xiaohui Jiang, Shiyi Lan, Min Shi, Nadine Chang, Jan Kautz, Ying Li, and Jose M Alvarez. Omnidrive: A holistic vision-language dataset for autonomous driving with counterfactual reasoning. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22442–22452, 2025
work page 2025
-
[6]
Zhiqi Li, Zhiding Yu, Shiyi Lan, Jiahan Li, Jan Kautz, Tong Lu, and Jose M Alvarez. Is ego status all you need for open-loop end-to-end autonomous driving? InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14864–14873, 2024
work page 2024
-
[7]
Holistic autonomous driving understanding by bird’s-eye-view injected multi-modal large models
Xinpeng Ding, Jianhua Han, Hang Xu, Xiaodan Liang, Wei Zhang, and Xiaomeng Li. Holistic autonomous driving understanding by bird’s-eye-view injected multi-modal large models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13668–13677, 2024
work page 2024
-
[8]
Shaoyuan Xie, Lingdong Kong, Yuhao Dong, Chonghao Sima, Wenwei Zhang, Qi Alfred Chen, Ziwei Liu, and Liang Pan. Are vlms ready for autonomous driving? an empirical study from the reliability, data and metric perspectives. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 6585–6597, October 2025
work page 2025
-
[9]
Yi Xu, Yuxin Hu, Zaiwei Zhang, Gregory P Meyer, Siva Karthik Mustikovela, Siddhartha Srinivasa, Eric M Wolff, and Xin Huang. Vlm-ad: End-to-end autonomous driving through vision-language model supervision.Conference on Robot Learning (CoRL), 2024
work page 2024
-
[10]
Robotron-drive: All-in-one large multimodal model for autonomous driving
Zhijian Huang, Chengjian Feng, Feng Yan, Baihui Xiao, Zequn Jie, Yujie Zhong, Xiaodan Liang, and Lin Ma. Robotron-drive: All-in-one large multimodal model for autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8011–8021, 2025
work page 2025
-
[11]
Jiajun Cao, Qizhe Zhang, Peidong Jia, Xuhui Zhao, Bo Lan, Xiaoan Zhang, Zhuo Li, Xiaobao Wei, Sixiang Chen, Liyun Li, et al. Fastdrivevla: Efficient end-to-end driving via plug-and-play reconstruction- based token pruning.the Association for the Advancement of Artificial Intelligence (AAAI), 2026
work page 2026
-
[12]
Drivegpt4: Interpretable end-to-end autonomous driving via large language model
Zhenhua Xu, Yujia Zhang, Enze Xie, Zhen Zhao, Yong Guo, Kwan-Yee K Wong, Zhenguo Li, and Hengshuang Zhao. Drivegpt4: Interpretable end-to-end autonomous driving via large language model. IEEE Robotics and Automation Letters, 2024
work page 2024
-
[13]
Covla: Comprehensive vision-language-action dataset for autonomous driving
Hidehisa Arai, Keita Miwa, Kento Sasaki, Kohei Watanabe, Yu Yamaguchi, Shunsuke Aoki, and Issei Yamamoto. Covla: Comprehensive vision-language-action dataset for autonomous driving. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1933–1943. IEEE, 2025
work page 1933
-
[14]
Emma: End-to-end multimodal model for autonomous driving.TMLR, 2025
Jyh-Jing Hwang, Runsheng Xu, Hubert Lin, Wei-Chih Hung, Jingwei Ji, Kristy Choi, Di Huang, Tong He, Paul Covington, Benjamin Sapp, et al. Emma: End-to-end multimodal model for autonomous driving.TMLR, 2025
work page 2025
-
[15]
Drivelm: Driving with graph visual question answering
Chonghao Sima, Katrin Renz, Kashyap Chitta, Li Chen, Hanxue Zhang, Chengen Xie, Jens Beißwenger, Ping Luo, Andreas Geiger, and Hongyang Li. Drivelm: Driving with graph visual question answering. InEuropean conference on computer vision, pages 256–274. Springer, 2024
work page 2024
-
[16]
DriveVLM: The convergence of autonomous driving and large vision-language models
Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, XianPeng Lang, and Hang Zhao. DriveVLM: The convergence of autonomous driving and large vision-language models. In8th Annual Conference on Robot Learning, 2024. 10
work page 2024
-
[17]
Futuresightdrive: Thinking visually with spatio-temporal cot for autonomous driving
Shuang Zeng, Xinyuan Chang, Mengwei Xie, Xinran Liu, Yifan Bai, Zheng Pan, Mu Xu, and Xing Wei. Futuresightdrive: Thinking visually with spatio-temporal cot for autonomous driving. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[18]
Kexin Tian, Jingrui Mao, Yunlong Zhang, Jiwan Jiang, Yang Zhou, and Zhengzhong Tu. Nuscenes- spatialqa: A spatial understanding and reasoning benchmark for vision-language models in autonomous driving.arXiv preprint arXiv:2504.03164, 2025
-
[19]
Maplm: A real-world large-scale vision-language benchmark for map and traffic scene understanding
Xu Cao, Tong Zhou, Yunsheng Ma, Wenqian Ye, Can Cui, Kun Tang, Zhipeng Cao, Kaizhao Liang, Ziran Wang, James M Rehg, et al. Maplm: A real-world large-scale vision-language benchmark for map and traffic scene understanding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21819–21830, 2024
work page 2024
-
[20]
Mohsen Gholami, Ahmad Rezaei, Zhou Weimin, Sitong Mao, Shunbo Zhou, Yong Zhang, and Moham- mad Akbari. Spatial reasoning with vision-language models in ego-centric multi-view scenes.arXiv preprint arXiv:2509.06266, 2025
-
[21]
Xianda Guo, Ruijun Zhang, Yiqun Duan, Yuhang He, Dujun Nie, Wenke Huang, Chenming Zhang, Shuai Liu, Hao Zhao, and Long Chen. Surds: Benchmarking spatial understanding and reasoning in driving scenarios with vision language models. InNeurIPS, 2025
work page 2025
-
[22]
Automated evaluation of large vision-language models on self-driving corner cases
Kai Chen, Yanze Li, Wenhua Zhang, Yanxin Liu, Pengxiang Li, Ruiyuan Gao, Lanqing Hong, Meng Tian, Xinhai Zhao, Zhenguo Li, et al. Automated evaluation of large vision-language models on self-driving corner cases. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 7817–7826. IEEE, 2025
work page 2025
-
[23]
Lingoqa: Visual question answering for autonomous driving
Ana-Maria Marcu, Long Chen, Jan Hünermann, Alice Karnsund, Benoit Hanotte, Prajwal Chidananda, Saurabh Nair, Vijay Badrinarayanan, Alex Kendall, Jamie Shotton, et al. Lingoqa: Visual question answering for autonomous driving. InEuropean Conference on Computer Vision, pages 252–269. Springer, 2024
work page 2024
-
[24]
Guanlin Wu, Boyan Su, Yang Zhao, Pu Wang, Yichen Lin, and Hao Frank Yang. Towards physics- informed spatial intelligence with human priors: An autonomous driving pilot study.International Conference on Learning Representations (ICLR), 2025
work page 2025
-
[25]
Christian Fruhwirth-Reisinger, Dušan Mali´c, Wei Lin, David Schinagl, Samuel Schulter, and Horst Possegger. Stsbench: A spatio-temporal scenario benchmark for multi-modal large language models in autonomous driving.Conference and Workshop on Neural Information Processing Systems, 2025
work page 2025
-
[26]
Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario
Tianwen Qian, Jingjing Chen, Linhai Zhuo, Yang Jiao, and Yu-Gang Jiang. Nuscenes-qa: A multi-modal visual question answering benchmark for autonomous driving scenario. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 4542–4550, 2024
work page 2024
-
[27]
nuscenes: A multimodal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krish- nan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020
work page 2020
-
[28]
Benjamin Wilson, William Qi, Tanmay Agarwal, John Lambert, Jagjeet Singh, Siddhesh Khandelwal, Bowen Pan, Ratnesh Kumar, Andrew Hartnett, Jhony Kaesemodel Pontes, et al. Argoverse 2: Next generation datasets for self-driving perception and forecasting.Conference on Neural Information Processing Systems, 202
-
[29]
Felix Fent, Fabian Kuttenreich, Florian Ruch, Farija Rizwin, Stefan Juergens, Lorenz Lechermann, Christian Nissler, Andrea Perl, Ulrich V oll, Min Yan, et al. Man truckscenes: A multimodal dataset for autonomous trucking in diverse conditions.Advances in Neural Information Processing Systems, 37:62062–62082, 2024
work page 2024
-
[30]
Scalability in perception for autonomous driving: Waymo open dataset
Pei Sun, Henrik Kretzschmar, Xerxes Dotiwalla, Aurelien Chouard, Vijaysai Patnaik, Paul Tsui, James Guo, Yin Zhou, Yuning Chai, Benjamin Caine, et al. Scalability in perception for autonomous driving: Waymo open dataset. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2446–2454, 2020. 11
work page 2020
-
[31]
One million scenes for autonomous driving: Once dataset
Jiageng Mao, Minzhe Niu, Chenhan Jiang, Hanxue Liang, Jingheng Chen, Xiaodan Liang, Yamin Li, Chaoqiang Ye, Wei Zhang, Zhenguo Li, et al. One million scenes for autonomous driving: Once dataset. Conference and Workshop on Neural Information Processing Systems, 2021
work page 2021
-
[32]
Xingcheng Zhou, Mingyu Liu, Ekim Yurtsever, Bare Luka Zagar, Walter Zimmer, Hu Cao, and Alois C Knoll. Vision language models in autonomous driving: A survey and outlook.arXiv preprint arXiv:2310.14414, 2023
-
[33]
Can Cui, Yunsheng Ma, Xu Cao, Wenqian Ye, Yang Zhou, Kaizhao Liang, Jintai Chen, Juanwu Lu, Zichong Yang, et al. A survey on multimodal large language models for autonomous driving.arXiv preprint arXiv:2311.12320, 2023
-
[34]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, et al. Kimi-vl technical report.arXiv preprint arXiv:2504.07491, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Llava-onevision: Easy visual task transfer.TMLR, 2024
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.TMLR, 2024
work page 2024
-
[40]
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Zhiyu Wu, Xiaokang Chen, Zizheng Pan, Xingchao Liu, Wen Liu, Damai Dai, Huazuo Gao, Yiyang Ma, Chengyue Wu, Bingxuan Wang, et al. Deepseek-vl2: Mixture-of-experts vision-language models for advanced multimodal understanding.arXiv preprint arXiv:2412.10302, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Khoa V o, Thinh Phan, Kashu Yamazaki, Minh Tran, and Ngan Le. Henasy: Learning to assemble scene-entities for interpretable egocentric video-language model.Advances in Neural Information Processing Systems, 37:86483–86499, 2024
work page 2024
-
[43]
Thanh-Dat Truong, Huu-Thien Tran, Tran Thai Son, Bhiksha Raj, and Khoa Luu. Directed- tokens: A robust multi-modality alignment approach to large language-vision models.arXiv preprint arXiv:2508.14264, 2025
-
[44]
GAIA-1: A Generative World Model for Autonomous Driving
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. Gaia-1: A generative world model for autonomous driving.arXiv preprint arXiv:2309.17080, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Yuqi Wang, Jiawei He, Lue Fan, Hongxin Li, Yuntao Chen, and Zhaoxiang Zhang. Driving into the future: Multiview visual forecasting and planning with world model for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
work page 2024
-
[46]
Xiaofeng Wang, Zheng Zhu, Guan Huang, Xinze Chen, Jiagang Zhu, and Jiwen Lu. Drivedreamer: Towards real-world-driven world models for autonomous driving.arXiv preprint arXiv:2309.09777, 2023. 12
-
[47]
Dolphins: Multimodal language model for driving
Yingzi Ma, Yulong Cao, Jiachen Sun, Marco Pavone, and Chaowei Xiao. Dolphins: Multimodal language model for driving. InEuropean Conference on Computer Vision, pages 403–420. Springer, 2024
work page 2024
-
[48]
Rea- son2drive: Towards interpretable and chain-based reasoning for autonomous driving
Ming Nie, Renyuan Peng, Chunwei Wang, Xinyue Cai, Jianhua Han, Hang Xu, and Li Zhang. Rea- son2drive: Towards interpretable and chain-based reasoning for autonomous driving. InEuropean Conference on Computer Vision, pages 292–308. Springer, 2024
work page 2024
-
[49]
Fangyu Liu, Guy Emerson, and Nigel Collier. Visual spatial reasoning.Transactions of the Association for Computational Linguistics, 11:635–651, 2023
work page 2023
-
[50]
Fatemeh Shiri, Xiao-Yu Guo, Mona Golestan Far, Xin Yu, Gholamreza Haffari, and Yuan-Fang Li. An empirical analysis on spatial reasoning capabilities of large multimodal models.arXiv preprint arXiv:2411.06048, 2024
-
[51]
Mengfei Du, Binhao Wu, Zejun Li, Xuanjing Huang, and Zhongyu Wei. Embspatial-bench: Bench- marking spatial understanding for embodied tasks with large vision-language models.arXiv preprint arXiv:2406.05756, 2024
-
[52]
An-Chieh Cheng, Hongxu Yin, Yang Fu, Qiushan Guo, Ruihan Yang, Jan Kautz, Xiaolong Wang, and Sifei Liu. Spatialrgpt: Grounded spatial reasoning in vision-language models.Advances in Neural Information Processing Systems, 37:135062–135093, 2024
work page 2024
-
[53]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities
Boyuan Chen, Zhuo Xu, Sean Kirmani, Brain Ichter, Dorsa Sadigh, Leonidas Guibas, and Fei Xia. Spatialvlm: Endowing vision-language models with spatial reasoning capabilities. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14455–14465, 2024
work page 2024
-
[54]
Spatialbot: Precise spatial understanding with vision language models
Wenxiao Cai, Iaroslav Ponomarenko, Jianhao Yuan, Xiaoqi Li, Wankou Yang, Hao Dong, and Bo Zhao. Spatialbot: Precise spatial understanding with vision language models. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 9490–9498. IEEE, 2025
work page 2025
-
[55]
Spatialllm: A compound 3d- informed design towards spatially-intelligent large multimodal models
Wufei Ma, Luoxin Ye, Celso M de Melo, Alan Yuille, and Jieneng Chen. Spatialllm: A compound 3d- informed design towards spatially-intelligent large multimodal models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17249–17260, 2025
work page 2025
-
[56]
Robospa- tial: Teaching spatial understanding to 2d and 3d vision-language models for robotics
Chan Hee Song, Valts Blukis, Jonathan Tremblay, Stephen Tyree, Yu Su, and Stan Birchfield. Robospa- tial: Teaching spatial understanding to 2d and 3d vision-language models for robotics. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15768–15780, 2025
work page 2025
-
[57]
Gemini Robotics: Bringing AI into the Physical World
Gemini Robotics Team, Saminda Abeyruwan, Joshua Ainslie, Jean-Baptiste Alayrac, Montserrat Gon- zalez Arenas, Travis Armstrong, Ashwin Balakrishna, Robert Baruch, Maria Bauza, Michiel Blokzijl, et al. Gemini robotics: Bringing ai into the physical world.arXiv preprint arXiv:2503.20020, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Yuecheng Liu, Dafeng Chi, Shiguang Wu, Zhanguang Zhang, Yaochen Hu, Lingfeng Zhang, Yingxue Zhang, Shuang Wu, Tongtong Cao, Guowei Huang, et al. Spatialcot: Advancing spatial reason- ing through coordinate alignment and chain-of-thought for embodied task planning.arXiv preprint arXiv:2501.10074, 2025
-
[60]
Mengdi Jia, Zekun Qi, Shaochen Zhang, Wenyao Zhang, Xinqiang Yu, Jiawei He, He Wang, and Li Yi. Omnispatial: Towards comprehensive spatial reasoning benchmark for vision language models.arXiv preprint arXiv:2506.03135, 2025
-
[61]
Zhaolu Kang, Junhao Gong, Jiaxu Yan, Wanke Xia, Yian Wang, Ziwen Wang, Huaxuan Ding, Zhuo Cheng, Wenhao Cao, Zhiyuan Feng, et al. Hssbench: Benchmarking humanities and social sciences ability for multimodal large language models.arXiv preprint arXiv:2506.03922, 2025
-
[62]
Spatial-dise: A unified benchmark for evaluating spatial reasoning in vision-language models
Xinmiao Huang, Qisong He, Zhenglin Huang, Boxuan Wang, Zhuoyun Li, Guangliang Cheng, and Yi Dong. Spatial-dise: A unified benchmark for evaluating spatial reasoning in vision-language models. arXiv preprint arXiv:2510.13394, 2025. 13
-
[63]
Ilias Stogiannidis, Steven McDonagh, and Sotirios A Tsaftaris. Mind the gap: Benchmarking spatial reasoning in vision-language models.arXiv preprint arXiv:2503.19707, 2025
-
[65]
Jingli Lin, Runsen Xu, Shaohao Zhu, Sihan Yang, Peizhou Cao, Yunlong Ran, Miao Hu, and Chenming Zhu. Mmsi-video-bench: A holistic benchmark for video-based spatial intelligence.arXiv preprint arXiv:2512.10863, 2025
-
[66]
Cambrian-S: Towards Spatial Supersensing in Video
Shusheng Yang, Jihan Yang, Pinzhi Huang, Ellis Brown, Zihao Yang, Yue Yu, Shengbang Tong, and Zihan Zhen. Cambrian-s: Towards spatial supersensing in video.arXiv preprint arXiv:2511.04670, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
Agqa: A benchmark for compositional spatio-temporal reasoning
Madeleine Grunde-McLaughlin, Ranjay Krishna, and Maneesh Agrawala. Agqa: A benchmark for compositional spatio-temporal reasoning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021
work page 2021
-
[68]
Next-qa: Next phase of question-answering to explaining temporal actions
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa: Next phase of question-answering to explaining temporal actions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021
work page 2021
-
[69]
Visuospatial perspective taking in multimodal language models.arXiv preprint arXiv:2603.23510, 2026
Jonathan Prunty, Seraphina Zhang, Patrick Quinn, Jianxun Lian, Xing Xie, and Lucy Cheke. Visuospatial perspective taking in multimodal language models.arXiv preprint arXiv:2603.23510, 2026
-
[70]
Egocentric bias in vision-language models.arXiv preprint arXiv:2602.15892, 2026
Maijunxian Wang, Yijiang Li, Bingyang Wang, Tianwei Zhao, Ran Ji, Qingying Gao, Emmy Liu, and Hokin Deng. Egocentric bias in vision-language models.arXiv preprint arXiv:2602.15892, 2026
-
[71]
Hengyi Wang, Ruiqiang Zhang, Chang Liu, Guanjie Wang, Zehua Ma, Han Fang, and Weiming Zhang. Allocentric perceiver: Disentangling allocentric reasoning from egocentric visual priors via frame instantiation.arXiv preprint arXiv:2602.05789, 2026
-
[72]
Jaeyun Jang, Seunghui Shin, Taeho Park, and Hyoseok Hwang. Keep it sympl: Symbolic projective layout for allocentric spatial reasoning in vision-language models.arXiv preprint arXiv:2602.19117, 2026
-
[73]
Atin Pothiraj, Elias Stengel-Eskin, Jaemin Cho, and Mohit Bansal. Capture: Evaluating spatial reasoning in vision language models via occluded object counting.arXiv preprint arXiv:2504.15485, 2025
-
[74]
Zhaochen Liu, Kaiwen Gao, Shuyi Liang, Bin Xiao, Limeng Qiao, Lin Ma, and Tingting Jiang. Beyond the visible: Benchmarking occlusion perception in multimodal large language models.arXiv preprint arXiv:2508.04059, 2025
-
[75]
Qihui Zhu, Shouwei Ruan, Xiao Yang, Hao Jiang, Yao Huang, Shiji Zhao, Hanwei Fan, Hang Su, and Xingxing Wei. Mind over space: Can multimodal large language models mentally navigate?arXiv preprint arXiv:2603.21577, 2026
-
[76]
Video2layout: Recall and reconstruct metric-grounded cognitive map for spatial reasoning
Yibin Huang, Wang Xu, Wanyue Zhang, Helu Zhi, Jingjing Huang, Yangbin Xu, Yangang Sun, and Conghui Zhu. Video2layout: Recall and reconstruct metric-grounded cognitive map for spatial reasoning. arXiv preprint arXiv:2511.16160, 2025
-
[77]
Baining Zhao, Ziyou Wang, Jianjie Fang, Chen Gao, Fanhang Man, Jinqiang Cui, Xin Wang, and Xinlei Chen. Embodied-r: Collaborative framework for activating embodied spatial reasoning in foundation models via reinforcement learning.arXiv preprint arXiv:2504.12680, 2025
-
[78]
Talk2car: Taking control of your self-driving car
Thierry Deruyttere, Simon Vandenhende, Dusan Grujicic, Luc Van Gool, and Marie Francine Moens. Talk2car: Taking control of your self-driving car. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 2088–2098, 2019
work page 2019
-
[79]
Textual explanations for self-driving vehicles
Jinkyu Kim, Anna Rohrbach, Trevor Darrell, John Canny, and Zeynep Akata. Textual explanations for self-driving vehicles. InProceedings of the European conference on computer vision (ECCV), pages 563–578, 2018. 14
work page 2018
-
[80]
Yuichi Inoue, Yuki Yada, Kotaro Tanahashi, and Yu Yamaguchi. Nuscenes-mqa: Integrated evalua- tion of captions and qa for autonomous driving datasets using markup annotations.arXiv preprint arXiv:2312.06352, 2023
-
[81]
Keishi Ishihara, Kento Sasaki, Tsubasa Takahashi, Daiki Shiono, and Yu Yamaguchi. Stride-qa: Visual question answering dataset for spatiotemporal reasoning in urban driving scenes.arXiv preprint arXiv:2508.10427, 2025
-
[82]
Xiaosong Jia, Zhenjie Yang, Qifeng Li, Zhiyuan Zhang, and Junchi Yan. Bench2drive: Towards multi- ability benchmarking of closed-loop end-to-end autonomous driving.arXiv preprint arXiv:2406.03877, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.