UxSID: Semantic-Aware User Interests Modeling for Ultra-Long Sequence
Pith reviewed 2026-05-20 22:24 UTC · model grok-4.3
The pith
Semantic IDs group user interests into shared memory to model ultra-long sequences with target-aware attention at lower cost
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
UxSID explores semantic-group shared interest memory. By utilizing Semantic IDs and a dual-level attention strategy, it captures target-aware preferences without the heavy cost of item-specific models. This end-to-end architecture balances computational parsimony with semantic awareness, achieving state-of-the-art performance and a 0.337% revenue lift in large-scale advertising A/B test.
What carries the argument
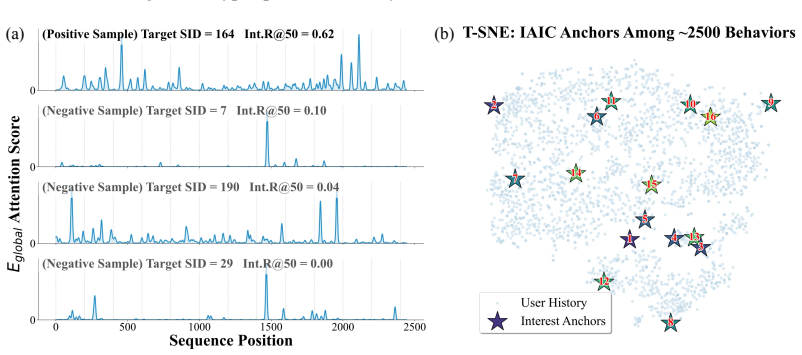
Semantic IDs (SIDs) paired with dual-level attention that builds and queries semantic-group shared interest memory for target-aware preference capture
If this is right
- The model reaches state-of-the-art results on ultra-long sequence tasks
- It produces a measurable revenue increase when deployed in real advertising systems
- Computation stays lower than item-specific approaches while retaining more semantic detail than compression-only methods
Where Pith is reading between the lines
- The same semantic-grouping idea could scale sequence models in domains that also face very long histories, such as video or news consumption
- If Semantic IDs prove stable, they might reduce reliance on ever-larger item embedding tables in production systems
Load-bearing premise
Semantic IDs can cluster user interests reliably enough to keep target-specific signals intact and outperform both full item search and generic compression
What would settle it
Replace Semantic IDs with random non-semantic groupings, retrain, and check whether recommendation accuracy and revenue lift disappear
Figures





read the original abstract
Modeling ultra-long user sequences involves a difficult trade-off between efficiency and effectiveness. While current paradigms rely on either item-specific search or item-agnostic compression, we propose UxSID, a framework exploring a third path: semantic-group shared interest memory. By utilizing Semantic IDs (SIDs) and a dual-level attention strategy, UxSID captures target-aware preferences without the heavy cost of item-specific models. This end-to-end architecture balances computational parsimony with semantic awareness, achieving state-of-the-art performance and a 0.337% revenue lift in large-scale advertising A/B test.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes UxSID, a framework for modeling ultra-long user sequences in advertising that uses Semantic IDs (SIDs) to partition sequences into shared interest memory units and applies a dual-level attention strategy to capture target-aware preferences. It claims this balances computational efficiency with semantic awareness, outperforming item-specific search and item-agnostic compression approaches while delivering state-of-the-art performance and a 0.337% revenue lift in a large-scale A/B test.
Significance. If the empirical claims hold after proper validation, the work could demonstrate a viable third path for ultra-long sequence modeling that avoids both the quadratic cost of item-specific attention and the information loss of aggressive compression. The end-to-end architecture with pre-grouped semantic memory has clear practical relevance for large-scale recommendation and advertising systems.
major comments (2)
- [Abstract] Abstract: The central empirical claim of a 0.337% revenue lift from the A/B test is presented without any information on the baseline models compared against, statistical significance testing, dataset sizes, number of users/items, or ablation studies isolating the contribution of SIDs versus dual-level attention. This leaves the primary performance result unsupported.
- [Method and Experiments] Method (assumed §3) and Experiments (assumed §4): The core assumption that Semantic IDs create shared memory units whose internal statistics still permit the target-aware attention layer to recover item-level preferences is not tested. No mutual-information analysis between SID clusters and the target item is reported, nor is there an ablation that replaces learned SIDs with random grouping at identical memory budget to quantify information loss.
minor comments (2)
- [Notation] Clarify in the notation section whether SIDs are pre-assigned by an external clustering step or learned jointly, and how the vocabulary size is chosen.
- [Figures] Figure captions should explicitly state the memory budget (number of SID groups) used in each compared method so that efficiency claims can be directly compared.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below, indicating planned revisions where appropriate to strengthen the presentation of our empirical results and methodological assumptions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central empirical claim of a 0.337% revenue lift from the A/B test is presented without any information on the baseline models compared against, statistical significance testing, dataset sizes, number of users/items, or ablation studies isolating the contribution of SIDs versus dual-level attention. This leaves the primary performance result unsupported.
Authors: We agree that the abstract, due to its length constraints, summarizes the revenue lift without embedding all supporting details. The full manuscript reports the A/B test setup, baselines, and statistical results in the Experiments section. To address the concern directly, we will revise the abstract to concisely note the primary baseline, statistical significance, and high-level dataset scale while retaining the core claim. revision: yes
-
Referee: [Method and Experiments] Method (assumed §3) and Experiments (assumed §4): The core assumption that Semantic IDs create shared memory units whose internal statistics still permit the target-aware attention layer to recover item-level preferences is not tested. No mutual-information analysis between SID clusters and the target item is reported, nor is there an ablation that replaces learned SIDs with random grouping at identical memory budget to quantify information loss.
Authors: The referee correctly identifies that we have not provided a direct mutual-information analysis or a random-grouping ablation at fixed memory budget. Our current results demonstrate end-to-end gains over both item-specific and item-agnostic baselines, which indirectly supports the utility of learned SIDs, but these additional diagnostics would strengthen the validation of the core assumption. We will incorporate both the mutual-information metrics and the random-grouping ablation in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical A/B test outcome stands independent of internal definitions
full rationale
The paper frames UxSID as an end-to-end model whose performance claims rest on a reported 0.337% revenue lift from a large-scale advertising A/B test. No equations, fitted parameters, or self-referential definitions appear in the abstract or described architecture that would reduce a claimed prediction back to its own inputs by construction. The dual-level attention and Semantic ID grouping are presented as design choices whose value is measured externally rather than derived tautologically. This is the common case of a self-contained empirical result with no load-bearing self-citation chain or ansatz smuggling.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
UxSID employs a dual-level attention strategy: it first extracts item-agnostic user interests from raw sequences, and then performs a semantic-specific query over global behaviors and those agnostic interests to generate semantic-specific preferences.
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Lortho = ||P P^T / ||P||_2^2 - I||_F (orthogonality constraint on interest anchors)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A survey of user lifelong behavior modeling: Perspectives on efficiency and effectiveness
Rui Zhou, Qinglin Jia, Bo Chen, Peng Xu, Yijia Sun, Siyuan Lou, Chaoxin Fu, Mengyuan Fu, Guoming Shen, Zheli Zhou, et al. A survey of user lifelong behavior modeling: Perspectives on efficiency and effectiveness. 2026
work page 2026
-
[2]
Robust anomaly detection for multivariate time series through stochastic recurrent neural network,
Qi Pi, Weijie Bian, Guorui Zhou, Xiaoqiang Zhu, and Kun Gai. Practice on long sequential user behavior modeling for click-through rate prediction. InProceedings of the 25th ACM SIGKDD international conference on knowledge discovery & data mining, page 2671–2679. ACM, 2019. doi: 10.1145/3292500. 3330666
-
[3]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
work page 2017
-
[4]
Deep interest network for click-through rate prediction
Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. Deep interest network for click-through rate prediction. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining, pages 1059–1068, 2018
work page 2018
-
[5]
Deep interest evolution network for click-through rate prediction
Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. Deep interest evolution network for click-through rate prediction. InProceedings of the AAAI conference on artificial intelligence, volume 33, pages 5941–5948, 2019
work page 2019
-
[6]
Transact: Transformer-based realtime user action model for recommendation at pinterest
Xue Xia, Pong Eksombatchai, Nikil Pancha, Dhruvil Deven Badani, Po-Wei Wang, Neng Gu, Saurabh Vish- was Joshi, Nazanin Farahpour, Zhiyuan Zhang, and Andrew Zhai. Transact: Transformer-based realtime user action model for recommendation at pinterest. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 5249–5259, 2023
work page 2023
-
[7]
Qi Pi, Guorui Zhou, Yujing Zhang, Zhe Wang, Lejian Ren, Ying Fan, Xiaoqiang Zhu, and Kun Gai. Search-based user interest modeling with lifelong sequential behavior data for click-through rate prediction. InProceedings of the 29th ACM International Conference on Information & Knowledge Management, pages 2685–2692, 2020
work page 2020
-
[8]
Twin: Two-stage interest network for lifelong user behavior modeling in ctr prediction at kuaishou
Jianxin Chang, Chenbin Zhang, Zhiyi Fu, Xiaoxue Zang, Lin Guan, Jing Lu, Yiqun Hui, Dewei Leng, Yanan Niu, Yang Song, et al. Twin: Two-stage interest network for lifelong user behavior modeling in ctr prediction at kuaishou. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 3785–3794, 2023
work page 2023
-
[9]
Learning universal user representations via self-supervised lifelong behaviors modeling
Bei Yang, Ke Liu, Xiaoxiao Xu, Renjun Xu, Hong Liu, et al. Learning universal user representations via self-supervised lifelong behaviors modeling. 2021
work page 2021
-
[10]
Trans- formers are good clusterers for lifelong user behavior sequence modeling
Xingmei Wang, Shiyao Wang, Wuchao Li, Jiaxin Deng, Song Lu, Defu Lian, and Guorui Zhou. Trans- formers are good clusterers for lifelong user behavior sequence modeling. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, pages 3123–3132, 2025
work page 2025
-
[11]
Pinnerformer: Sequence modeling for user representation at pinterest
Nikil Pancha, Andrew Zhai, Jure Leskovec, and Charles Rosenberg. Pinnerformer: Sequence modeling for user representation at pinterest. InProceedings of the 28th ACM SIGKDD conference on knowledge discovery and data mining, pages 3702–3712, 2022
work page 2022
-
[12]
Kirti Jain and Rajni Jindal. Sampling and noise filtering methods for recommender systems: A literature review.Engineering Applications of Artificial Intelligence, 122:106129, 2023
work page 2023
-
[13]
Recommender systems with generative retrieval
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, et al. Recommender systems with generative retrieval. Advances in Neural Information Processing Systems, 36:10299–10315, 2023
work page 2023
-
[14]
Kun Zhang, Jingming Zhang, Wei Cheng, Yansong Cheng, Jiaqi Zhang, Hao Lu, Xu Zhang, Haixiang Gan, Jiangxia Cao, Tenglong Wang, et al. Onemall: One model, more scenarios–end-to-end generative recommender family at kuaishou e-commerce.arXiv preprint arXiv:2601.21770, 2026
-
[15]
Ruining He, Lukasz Heldt, Lichan Hong, Raghunandan Keshavan, Shifan Mao, Nikhil Mehta, Zhengyang Su, Alicia Tsai, Yueqi Wang, Shao-Chuan Wang, et al. Plum: Adapting pre-trained language models for industrial-scale generative recommendations.arXiv preprint arXiv:2510.07784, 2025
-
[16]
Das: Dual-aligned semantic ids empowered industrial recommender system
Wencai Ye, Mingjie Sun, Shaoyun Shi, Peng Wang, Wenjin Wu, and Peng Jiang. Das: Dual-aligned semantic ids empowered industrial recommender system. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, pages 6217–6224, 2025. 12
work page 2025
-
[17]
Huanjie Wang, Xinchen Luo, Honghui Bao, Zhang Zixing, Lejian Ren, Yunfan Wu, Hongwei Zhang, Liwei Guan, and Guang Chen. Pit: A dynamic personalized item tokenizer for end-to-end generative recommendation.arXiv preprint arXiv:2602.08530, 2026
-
[18]
Junwei Yin, Senjie Kou, Changhao Li, Shuli Wang, Xue Wei, Yinqiu Huang, Yinhua Zhu, Haitao Wang, and Xingxing Wang. Dos: Dual-flow orthogonal semantic ids for recommendation in meituan.arXiv preprint arXiv:2602.04460, 2026
-
[19]
Tian Xia, Jiaqi Zhang, Yueyang Liu, Hongjian Dou, Tingya Yin, Jiangxia Cao, Xulei Liang, Tianlu Xie, Lihao Liu, Xiang Chen, et al. Qarm v2: Quantitative alignment multi-modal recommendation for reasoning user sequence modeling.arXiv preprint arXiv:2602.08559, 2026
-
[20]
Deep Session Interest Network for Click-Through Rate Prediction
Yufei Feng, Fuyu Lv, Weichen Shen, Menghan Wang, Fei Sun, Yu Zhu, and Keping Yang. Deep session interest network for click-through rate prediction.arXiv preprint arXiv:1905.06482, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[21]
User-aware multi-interest learning for candidate matching in recommenders
Zheng Chai, Zhihong Chen, Chenliang Li, Rong Xiao, Houyi Li, Jiawei Wu, Jingxu Chen, and Haihong Tang. User-aware multi-interest learning for candidate matching in recommenders. InProceedings of the 45th international ACM SIGIR conference on research and development in information retrieval, pages 1326–1335, 2022
work page 2022
-
[22]
Multi-interest network with dynamic routing for recommendation at tmall
Chao Li, Zhiyuan Liu, Mengmeng Wu, Yuchi Xu, Huan Zhao, Pipei Huang, Guoliang Kang, Qiwei Chen, Wei Li, and Dik Lun Lee. Multi-interest network with dynamic routing for recommendation at tmall. In Proceedings of the 28th ACM international conference on information and knowledge management, pages 2615–2623, 2019
work page 2019
-
[23]
Multi-grained preference enhanced transformer for multi-behavior sequential recommendation
Chuan He, Yongchao Liu, Qiang Li, Weiqiang Wang, Xing Fu, Xinyi Fu, Chuntao Hong, and Xinwei Yao. Multi-grained preference enhanced transformer for multi-behavior sequential recommendation. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 872–883, 2025
work page 2025
-
[24]
Behavior sequence transformer for e- commerce recommendation in alibaba
Qiwei Chen, Huan Zhao, Wei Li, Pipei Huang, and Wenwu Ou. Behavior sequence transformer for e- commerce recommendation in alibaba. InProceedings of the 1st international workshop on deep learning practice for high-dimensional sparse data, pages 1–4, 2019
work page 2019
-
[25]
Self-attentive sequential recommendation
Wang-Cheng Kang and Julian McAuley. Self-attentive sequential recommendation. In2018 IEEE international conference on data mining (ICDM), pages 197–206. IEEE, 2018
work page 2018
-
[26]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Michael He, et al. Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations.arXiv preprint arXiv:2402.17152, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Mtgr: Industrial-scale generative recommendation framework in meituan
Ruidong Han, Bin Yin, Shangyu Chen, He Jiang, Fei Jiang, Xiang Li, Chi Ma, Mincong Huang, Xiaoguang Li, Chunzhen Jing, et al. Mtgr: Industrial-scale generative recommendation framework in meituan. In Proceedings of the 34th ACM International Conference on Information and Knowledge Management, pages 5731–5738, 2025
work page 2025
-
[28]
A survey on sequential recommendation.Frontiers of Computer Science, 20(3):2003606, 2026
Li-Wei Pan, Wei-Ke Pan, Mei-Yan Wei, Hong-Zhi Yin, and Zhong Ming. A survey on sequential recommendation.Frontiers of Computer Science, 20(3):2003606, 2026
work page 2026
-
[29]
arXiv preprint arXiv:2108.04468(2021)
Qiwei Chen, Changhua Pei, Shanshan Lv, Chao Li, Junfeng Ge, and Wenwu Ou. End-to-end user behavior retrieval in click-through rateprediction model.arXiv preprint arXiv:2108.04468, 2021
-
[30]
Sampling is all you need on modeling long-term user behaviors for ctr prediction
Yue Cao, Xiaojiang Zhou, Jiaqi Feng, Peihao Huang, Yao Xiao, Dayao Chen, and Sheng Chen. Sampling is all you need on modeling long-term user behaviors for ctr prediction. InProceedings of the 31st ACM International Conference on Information & Knowledge Management, pages 2974–2983, 2022
work page 2022
-
[31]
Twin v2: Scaling ultra-long user behavior sequence modeling for enhanced ctr prediction at kuaishou
Zihua Si, Lin Guan, ZhongXiang Sun, Xiaoxue Zang, Jing Lu, Yiqun Hui, Xingchao Cao, Zeyu Yang, Yichen Zheng, Dewei Leng, et al. Twin v2: Scaling ultra-long user behavior sequence modeling for enhanced ctr prediction at kuaishou. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management, pages 4890–4897, 2024
work page 2024
-
[32]
Xiang Xu, Hao Wang, Wei Guo, Luankang Zhang, Wanshan Yang, Runlong Yu, Yong Liu, Defu Lian, and Enhong Chen. Multi-granularity interest retrieval and refinement network for long-term user behavior modeling in ctr prediction. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, pages 2745–2755, 2025. 13
work page 2025
-
[34]
Lrea: Low-rank efficient attention on modeling long-term user behaviors for ctr prediction
Xin Song, Xiaochen Li, Jinxin Hu, Hong Wen, Zulong Chen, Yu Zhang, Xiaoyi Zeng, and Jing Zhang. Lrea: Low-rank efficient attention on modeling long-term user behaviors for ctr prediction. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2843–2847, 2025
work page 2025
-
[35]
Dv365: Extremely long user history modeling at instagram
Wenhan Lyu, Devashish Tyagi, Yihang Yang, Ziwei Li, Ajay Somani, Karthikeyan Shanmugasundaram, Nikola Andrejevic, Ferdi Adeputra, Curtis Zeng, Arun K Singh, et al. Dv365: Extremely long user history modeling at instagram. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 4717–4727, 2025
work page 2025
-
[36]
Longer: Scaling up long sequence modeling in industrial recommenders
Zheng Chai, Qin Ren, Xijun Xiao, Huizhi Yang, Bo Han, Sijun Zhang, Di Chen, Hui Lu, Wenlin Zhao, Lele Yu, et al. Longer: Scaling up long sequence modeling in industrial recommenders. InProceedings of the Nineteenth ACM Conference on Recommender Systems, pages 247–256, 2025
work page 2025
-
[37]
Xiao Lv, Jiangxia Cao, Shijie Guan, Xiaoyou Zhou, Zhiguang Qi, Yaqiang Zang, Ben Wang, and Guorui Zhou. Marm: Unlocking the recommendation cache scaling-law through memory augmentation and scalable complexity. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, pages 2022–2031, 2025
work page 2022
-
[38]
Qarm: Quantitative alignment multi-modal recommendation at kuaishou
Xinchen Luo, Jiangxia Cao, Tianyu Sun, Jinkai Yu, Rui Huang, Wei Yuan, Hezheng Lin, Yichen Zheng, Shiyao Wang, Qigen Hu, et al. Qarm: Quantitative alignment multi-modal recommendation at kuaishou. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, pages 5915–5922, 2025
work page 2025
-
[39]
OneRec: Unifying Retrieve and Rank with Generative Recommender and Iterative Preference Alignment
Jiaxin Deng, Shiyao Wang, Kuo Cai, Lejian Ren, Qigen Hu, Weifeng Ding, Qiang Luo, and Guorui Zhou. Onerec: Unifying retrieve and rank with generative recommender and iterative preference alignment.arXiv preprint arXiv:2502.18965, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Farewell to item ids: Unlocking the scaling potential of large ranking models via semantic tokens
Zhen Zhao, Tong Zhang, Jie Xu, Qingliang Cai, Qile Zhang, Leyuan Yang, Daorui Xiao, and Xiaojia Chang. Farewell to item ids: Unlocking the scaling potential of large ranking models via semantic tokens. arXiv preprint arXiv:2601.22694, 2026
-
[41]
Finite Scalar Quantization: VQ-VAE Made Simple
Fabian Mentzer, David Minnen, Eirikur Agustsson, and Michael Tschannen. Finite scalar quantization: Vq-vae made simple.arXiv preprint arXiv:2309.15505, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Lifelong sequential modeling with personalized memorization for user response prediction
Kan Ren, Jiarui Qin, Yuchen Fang, Weinan Zhang, Lei Zheng, Weijie Bian, Guorui Zhou, Jian Xu, Yong Yu, Xiaoqiang Zhu, et al. Lifelong sequential modeling with personalized memorization for user response prediction. InProceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 565–574, 2019
work page 2019
-
[43]
Kuairec: A fully-observed dataset and insights for evaluating recommender systems
Chongming Gao, Shijun Li, Wenqiang Lei, Jiawei Chen, Biao Li, Peng Jiang, Xiangnan He, Jiaxin Mao, and Tat-Seng Chua. Kuairec: A fully-observed dataset and insights for evaluating recommender systems. InProceedings of the 31st ACM International Conference on Information & Knowledge Management, CIKM ’22, page 540–550, 2022. doi: 10.1145/3511808.3557220. UR...
-
[44]
Wide & deep learning for recommender systems
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al. Wide & deep learning for recommender systems. InProceedings of the 1st workshop on deep learning for recommender systems, pages 7–10, 2016
work page 2016
-
[45]
Learnable item tokenization for generative recommendation
Wenjie Wang, Honghui Bao, Xinyu Lin, Jizhi Zhang, Yongqi Li, Fuli Feng, See-Kiong Ng, and Tat-Seng Chua. Learnable item tokenization for generative recommendation. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management, pages 2400–2409, 2024
work page 2024
-
[46]
Guorui Zhou, Hengrui Hu, Hongtao Cheng, Huanjie Wang, Jiaxin Deng, Jinghao Zhang, Kuo Cai, Lejian Ren, Lu Ren, Liao Yu, et al. Onerec-v2 technical report.arXiv preprint arXiv:2508.20900, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023. 14 A Online Implementation Long-term User History Storage Training Data Storage UxSID Ranking Mode...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
We use users’ interaction histories to create video sequences sorted by timestamp and filter out users with less than 50 comments. For each video sequence, the last 7 videos are used for testing, the 8th to 14th last videos are used for validation, and the rest are used for training. We fix the user’s interaction history up to 2k. Industrial Dataset:Colle...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.