Valdi: Value Diffusion World Models
Pith reviewed 2026-07-02 15:44 UTC · model grok-4.3
The pith
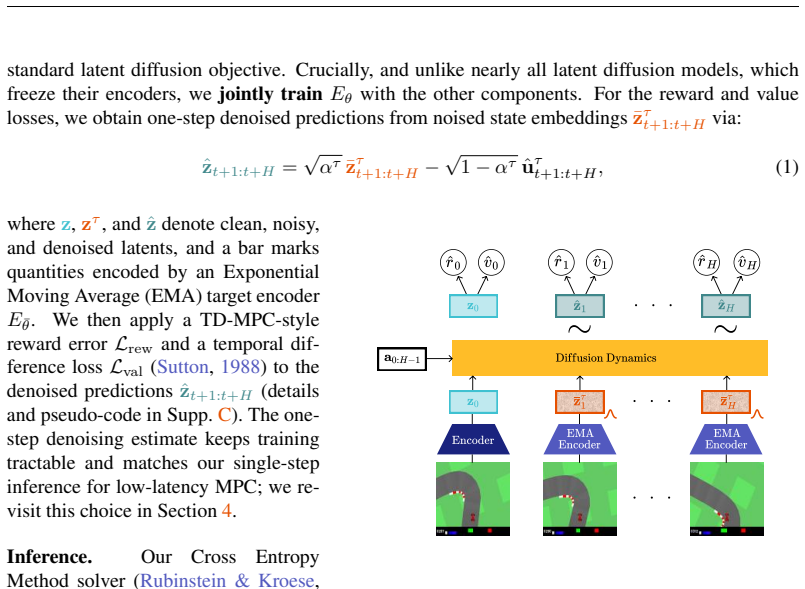
Valdi trains a latent diffusion world model end-to-end so one diffusion step suffices for model-predictive control.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
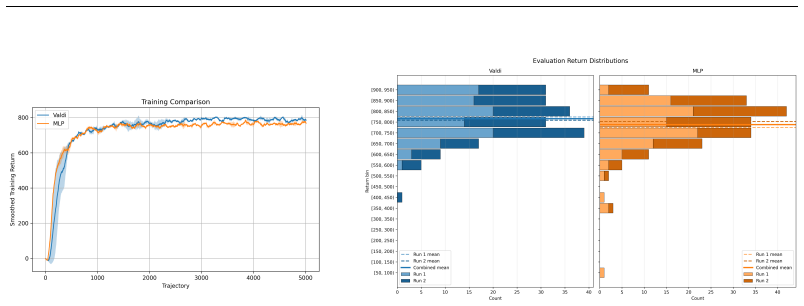
Valdi combines end-to-end online training for MPC with a latent diffusion dynamics model. In preliminary experiments on the CarRacing environment, Valdi using a single diffusion step at both training and inference matches a deterministic MLP baseline, while exposing a trade-off between predictive multimodality and control performance.
What carries the argument
latent diffusion dynamics model trained end-to-end for model predictive control
If this is right
- A single diffusion step at inference is sufficient to reach deterministic-level control performance in this environment.
- End-to-end training removes the need for separate pre-training of the diffusion model before it can be used in MPC.
- Increasing the number of diffusion steps to capture more multimodality can degrade closed-loop control performance.
- The same architecture supports both fast deterministic-like planning and uncertain dynamics modeling depending on step count.
Where Pith is reading between the lines
- The single-step regime may extend to other continuous-control benchmarks where latency constraints dominate.
- The observed multimodality-control trade-off suggests tuning the diffusion schedule specifically for value estimation rather than full trajectory distribution matching.
- If the latent diffusion step count can be made adaptive at runtime, the same model could switch between fast and high-fidelity regimes without retraining.
Load-bearing premise
A single diffusion step in the latent space is expressive enough to support effective model-predictive control when the model is trained end-to-end.
What would settle it
An experiment in CarRacing where the single-step Valdi controller achieves lower cumulative reward than the deterministic MLP baseline under identical training and evaluation conditions.
Figures



read the original abstract
World models can enable Model Predictive Control (MPC), but this requires dynamics prediction that is both fast enough for online use and expressive enough to represent uncertain futures. Diffusion models offer a natural mechanism for modeling uncertain dynamics, yet their iterative inference procedure makes them difficult to use for low-latency latent planning. We bridge this gap with Value Diffusion World Models (Valdi), combining end-to-end online training for MPC with a latent diffusion dynamics model. In preliminary experiments on the CarRacing environment, we show that Valdi, using a single diffusion step at both training and inference, matches a deterministic MLP baseline. Our experiments expose a trade-off between predictive multimodality and control performance in this setup. Code is available at https://github.com/Kit115/ValueDiffusionWorldModels.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Value Diffusion World Models (Valdi), which combine end-to-end online training for MPC with a latent diffusion dynamics model to achieve both low-latency inference and expressive uncertain dynamics. The central claim, based on preliminary experiments in the CarRacing environment, is that Valdi using a single diffusion step at both training and inference matches a deterministic MLP baseline while exposing a trade-off between predictive multimodality and control performance.
Significance. If the result holds under more detailed validation, it would indicate that diffusion-based world models can be made compatible with real-time MPC via single-step inference. However, the reported parity with a deterministic baseline suggests the diffusion mechanism may not be contributing the intended multimodality or uncertainty modeling, which would limit the significance unless the method is shown to provide advantages in settings where uncertainty matters for control.
major comments (2)
- [Abstract] Abstract: the claim that Valdi 'bridges this gap' with diffusion is undercut by the single-step result, as a one-step diffusion process at inference is equivalent to a standard conditional predictor (or mean regressor under common noise schedules) and does not demonstrate the iterative denoising or multimodality that distinguishes diffusion models.
- [Experiments] Experiments (preliminary CarRacing results): no details are provided on training curves, statistical significance, exact architecture, how the multimodality-control trade-off was quantified, or whether the single-step model was compared against a multi-step diffusion variant, so the support for the performance match cannot be assessed and the weakest assumption (that single-step latent diffusion suffices for effective MPC) remains untested.
minor comments (1)
- [Abstract] The public code link is a strength for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback on this preliminary work. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that Valdi 'bridges this gap' with diffusion is undercut by the single-step result, as a one-step diffusion process at inference is equivalent to a standard conditional predictor (or mean regressor under common noise schedules) and does not demonstrate the iterative denoising or multimodality that distinguishes diffusion models.
Authors: We agree that single-step inference does not leverage the iterative denoising process that defines diffusion models and is functionally closer to a conditional predictor. The manuscript's contribution centers on an end-to-end MPC training framework that incorporates a latent diffusion dynamics model while meeting real-time constraints via single-step sampling. The reported result is the observed trade-off between predictive multimodality and control performance under this constraint. We will revise the abstract to remove the phrasing 'bridges this gap' and instead emphasize the single-step feasibility result together with the multimodality-control trade-off. revision: yes
-
Referee: [Experiments] Experiments (preliminary CarRacing results): no details are provided on training curves, statistical significance, exact architecture, how the multimodality-control trade-off was quantified, or whether the single-step model was compared against a multi-step diffusion variant, so the support for the performance match cannot be assessed and the weakest assumption (that single-step latent diffusion suffices for effective MPC) remains untested.
Authors: The current manuscript presents only high-level preliminary findings. We will expand the experiments section in revision to include training curves, exact architecture specifications, statistical significance across multiple random seeds, a precise description of how the multimodality-control trade-off was quantified (by varying the diffusion timestep and sampling procedure), and, where compute permits, a direct comparison against a multi-step diffusion variant. These additions will allow readers to assess the performance match and test the single-step assumption more rigorously. revision: yes
Circularity Check
No circularity: purely empirical performance comparison with no derivation chain
full rationale
The paper reports a preliminary experimental result: Valdi with one diffusion step matches an MLP baseline in CarRacing MPC. No equations, fitted parameters, uniqueness theorems, or self-citations are invoked to derive or predict this outcome; the match is presented as an observed fact from end-to-end training and evaluation. The noted trade-off between multimodality and control is likewise an experimental observation. Because the central claim is a direct empirical comparison rather than a reduction of any quantity to its inputs by construction, no circularity patterns apply.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, Daniel Dworakowski, Jiaojiao Fan, Michele Fenzi, Francesco Ferroni, Sanja Fidler, Dieter Fox, Songwei Ge, Yunhao Ge, Jinwei Gu, Siddharth Gururani, Ethan He, Jiahui Huang, Jacob Samuel Huffman, Pooya Jannaty, Jingyi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Diffusion for world modeling: Visual details matter in atari
Eloi Alonso, Adam Jelley, Vincent Micheli, Anssi Kanervisto, Amos Storkey, Tim Pearce, and Fran c ois Fleuret. Diffusion for world modeling: Visual details matter in atari. NeurIPS, 2024
2024
-
[3]
Lejepa: Provable and scalable self-supervised learning without the heuristics
Randall Balestriero and Yann LeCun. Lejepa: Provable and scalable self-supervised learning without the heuristics. arXiv.org, 2025
2025
-
[4]
End-to-end autonomous driving: Challenges and frontiers
Li Chen, Penghao Wu, Kashyap Chitta, Bernhard Jaeger, Andreas Geiger, and Hongyang Li. End-to-end autonomous driving: Challenges and frontiers. PAMI, 2024
2024
-
[5]
Vista: A generalizable driving world model with high fidelity and versatile controllability
Shenyuan Gao, Jiazhi Yang, Li Chen, Kashyap Chitta, Yihang Qiu, Andreas Geiger, Jun Zhang, and Hongyang Li. Vista: A generalizable driving world model with high fidelity and versatile controllability. In NeurIPS, 2024
2024
-
[6]
Model predictive control: Theory and practice—a survey
Carlos E Garcia, David M Prett, and Manfred Morari. Model predictive control: Theory and practice—a survey. Automatica, 1989
1989
-
[7]
David Ha and J \"u rgen Schmidhuber. World models. arXiv.org, 1803.10122, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor
Tuomas Haarnoja, Aurick Zhou, Pieter Abbeel, and Sergey Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. In ICML, 2018 a
2018
-
[9]
Soft Actor-Critic Algorithms and Applications
Tuomas Haarnoja, Aurick Zhou, Kristian Hartikainen, George Tucker, Sehoon Ha, Jie Tan, Vikash Kumar, Henry Zhu, Abhishek Gupta, Pieter Abbeel, and Sergey Levine. Soft actor-critic algorithms and applications. arXiv.org, 1812.05905, 2018 b
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
Learning latent dynamics for planning from pixels
Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels. In ICML, pp.\ 2555--2565. PMLR, 2019
2019
-
[11]
Lillicrap, Jimmy Ba, and Mohammad Norouzi
Danijar Hafner, Timothy P. Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination. In ICLR, 2020
2020
-
[12]
Mastering diverse domains through world models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models. arXiv.org, 2023
2023
-
[13]
Training Agents Inside of Scalable World Models
Danijar Hafner, Wilson Yan, and Timothy Lillicrap. Training agents inside of scalable world models. arXiv.org, 2509.24527, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
arXiv preprint arXiv:2203.04955 , year=
Nicklas Hansen, Xiaolong Wang, and Hao Su. Temporal difference learning for model predictive control. arXiv.org, 2203.04955, 2022
-
[15]
Td-mpc2: Scalable, robust world models for continuous control
Nicklas Hansen, Hao Su, and Xiaolong Wang. Td-mpc2: Scalable, robust world models for continuous control. arXiv.org, 2023
2023
-
[16]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In NeurIPS, 2020
2020
-
[17]
Video diffusion models
Jonathan Ho, Tim Salimans, Alexey Gritsenko, William Chan, Mohammad Norouzi, and David J Fleet. Video diffusion models. In NIPS, 2022
2022
-
[18]
Lillicrap, Jonathan J
Timothy P. Lillicrap, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, and Daan Wierstra. Continuous control with deep reinforcement learning. In ICLR, 2016
2016
-
[19]
LeWorldModel: Stable End-to-End Joint-Embedding Predictive Architecture from Pixels
Lucas Maes, Quentin Le Lidec, Damien Scieur, Yann LeCun, and Randall Balestriero. LeWorldModel : Stable end-to-end joint-embedding predictive architecture from pixels. arXiv.org, 2603.19312, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
The cross-entropy method: a unified approach to combinatorial optimization, monte-carlo simulation, and machine learning, 2004
Reuven Y Rubinstein and Dirk P Kroese. The cross-entropy method: a unified approach to combinatorial optimization, monte-carlo simulation, and machine learning, 2004
2004
-
[21]
Progressive distillation for fast sampling of diffusion models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. arXiv.org, 2022
2022
-
[22]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. arXiv.org, 2010.02502, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[23]
Learning to predict by the methods of temporal differences
Richard S Sutton. Learning to predict by the methods of temporal differences. Machine Learning, 3 0 (1): 0 9--44, 1988
1988
-
[24]
Gymnasium: A standard interface for reinforcement learning environments
Mark Towers, Ariel Kwiatkowski, Jordan Terry, John U Balis, Gianluca De Cola, Tristan Deleu, Manuel Goul \ a o, Andreas Kallinteris, Markus Krimmel, Arjun KG, et al. Gymnasium: A standard interface for reinforcement learning environments. arXiv.org, 2024
2024
-
[25]
Model predictive path integral control: From theory to parallel computation
Grady Williams, Andrew Aldrich, and Evangelos A Theodorou. Model predictive path integral control: From theory to parallel computation. Journal of Guidance, Control, and Dynamics, 2017
2017
-
[26]
Resim: Reliable world simulation for autonomous driving
Jiazhi Yang, Kashyap Chitta, Shenyuan Gao, Long Chen, Yuqian Shao, Xiaosong Jia, Hongyang Li, Andreas Geiger, Xiangyu Yue, and Li Chen. Resim: Reliable world simulation for autonomous driving. In NeurIPS, 2025
2025
-
[27]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In CVPR, pp.\ 586--595, 2018
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.