Trinity: Unifying Class-Agnostic Terrain and Semantic Segmentation for Unstructured Outdoor Environments by Leveraging Synthetic Data
Pith reviewed 2026-06-29 16:48 UTC · model grok-4.3
The pith
A single transformer learns both semantic classes and unlabeled terrain regions from visual appearance alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
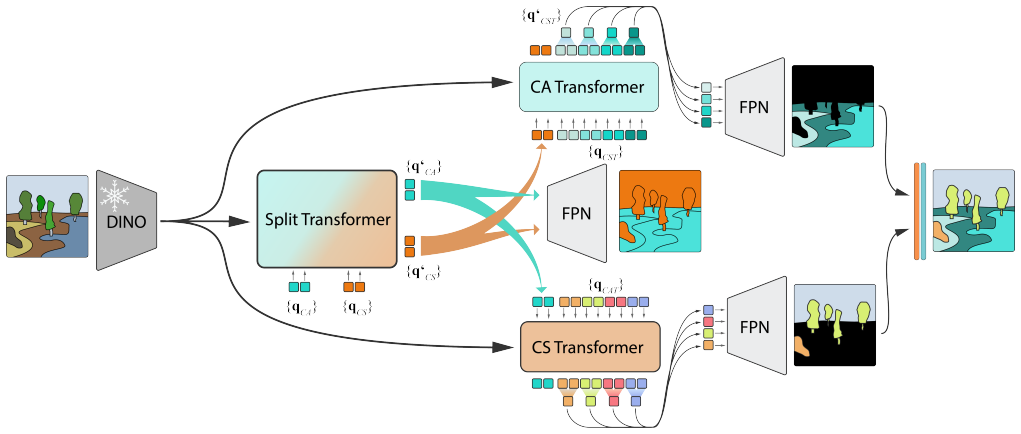
Trinity is a unified transformer architecture that jointly outputs class-specific semantic segmentation and class-agnostic terrain segmentation. Terrain segmentation relies solely on visual appearance, without predefined semantic labels or robot-dependent traversability scores. This formulation produces robot-agnostic visual terrain priors usable for tasks such as traversability estimation, visual odometry, and mission planning. Training is enabled by the RUGDSynth synthetic dataset and the EXTerra real-world dataset that supplies both label types.
What carries the argument
The Trinity transformer network that shares a backbone to produce both semantic class maps and class-agnostic terrain maps in a single forward pass.
If this is right
- Terrain segmentation becomes independent of any particular robot's capabilities or annotation scheme.
- The same visual terrain priors can be reused across different platforms without new labeling.
- Synthetic data generation at scale becomes practical for covering diverse terrain appearances.
- Joint training of the two tasks improves feature sharing inside the network for outdoor scenes.
Where Pith is reading between the lines
- The separation of terrain appearance from robot-specific scoring could simplify transfer when a robot's wheels, mass, or sensors change.
- Class-agnostic terrain maps might serve as an additional input channel for other perception modules such as visual odometry.
- The dual-annotation real dataset could become a benchmark for testing how well appearance-based terrain generalizes beyond the training environments.
Load-bearing premise
Visual appearance by itself is enough to define terrain regions that remain useful when later paired with any robot's own experience.
What would settle it
A controlled test in which terrain maps produced by the class-agnostic head, when fused with robot-specific data, yield no improvement or a measurable drop in traversability estimation accuracy relative to semantic segmentation alone.
Figures





read the original abstract
Terrain understanding is fundamental for mobile robots operating in unstructured outdoor environments. Existing vision-based traversability estimation methods rely on robot-specific annotations or semantic class mappings, limiting transferability across platforms and requiring costly re-annotation when robot capabilities change, while standard semantic segmentation methods only focus on specific predefined classes, which do not capture the variety of terrains. In this work, we propose a transformer-based architecture that jointly performs class-specific semantic segmentation and class-agnostic terrain segmentation within a unified network, called Trinity. Terrain regions are segmented based solely on visual appearance, without predefined semantic labels or robot-dependent traversability scores. This formulation enables the learning of robot-agnostic visual terrain priors that can be combined with robot-specific experience for downstream tasks such as traversability estimation, visual odometry, and mission planning. To enable large-scale training with diverse terrain appearances, we extend the OAISYS simulator and introduce RUGDSynth, a synthetic dataset inspired by RUGD with class-agnostic terrain samples. Furthermore, we present the EXTerra Dataset, providing real-world images annotated with both class-specific and class-agnostic terrain labels. Experiments demonstrate the feasibility of the proposed task and the effectiveness of our joint segmentation approach in complex outdoor environments. Code and datasets will be released with this publication (after review).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a transformer-based architecture called Trinity that unifies class-specific semantic segmentation and class-agnostic terrain segmentation for outdoor robot environments. By using synthetic data from an extended OAISYS simulator (RUGDSynth) and a new real dataset (EXTerra), the model learns terrain segmentation based on visual appearance without semantic labels or robot-specific scores. This is intended to provide robot-agnostic priors for downstream tasks. Experiments are presented to show the feasibility of the joint task and the effectiveness of the approach.
Significance. If the results hold, this work could have significant impact by enabling more generalizable terrain understanding for mobile robots in unstructured environments, addressing the limitations of robot-specific annotations. The creation and release of the RUGDSynth and EXTerra datasets, along with the code, would be a substantial contribution to the robotics community. The class-agnostic approach is a promising way to handle terrain variety beyond predefined classes.
major comments (2)
- [Experiments] The claim of effectiveness of the joint segmentation approach requires supporting quantitative evidence. Please provide specific metrics such as mean Intersection over Union (mIoU) for both semantic and terrain segmentation tasks, along with comparisons to baseline models trained separately on each task and ablations on the use of synthetic data.
- [Method] §3: The description of the Trinity architecture should detail the loss functions used for the joint training and how the class-agnostic terrain labels are incorporated, as this is central to validating the unified network's performance.
minor comments (3)
- [Abstract] The abstract mentions 'complex outdoor environments' but could specify the types of terrains or conditions tested for better context.
- [Introduction] Ensure that the motivation for robot-agnostic priors is clearly distinguished from the demonstrated results, as the combination with robot-specific experience is presented as a future possibility.
- [Datasets] Provide more details on the annotation process for class-agnostic terrain labels in EXTerra to allow readers to understand the visual appearance criteria used.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We will revise the paper to address the requests for additional quantitative evidence and expanded methodological details.
read point-by-point responses
-
Referee: [Experiments] The claim of effectiveness of the joint segmentation approach requires supporting quantitative evidence. Please provide specific metrics such as mean Intersection over Union (mIoU) for both semantic and terrain segmentation tasks, along with comparisons to baseline models trained separately on each task and ablations on the use of synthetic data.
Authors: We agree that the current presentation of results would be strengthened by explicit quantitative metrics. In the revised manuscript we will report mIoU for both the semantic segmentation and class-agnostic terrain segmentation tasks on EXTerra, include direct comparisons against models trained separately on each task, and add ablation studies that isolate the contribution of the RUGDSynth synthetic data. revision: yes
-
Referee: [Method] §3: The description of the Trinity architecture should detail the loss functions used for the joint training and how the class-agnostic terrain labels are incorporated, as this is central to validating the unified network's performance.
Authors: We will expand Section 3 to specify the loss functions employed during joint training and to clarify how the class-agnostic terrain labels are generated and combined with the semantic labels within the shared network. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes a new transformer architecture (Trinity) for joint semantic and class-agnostic terrain segmentation, along with new synthetic (RUGDSynth) and real (EXTerra) datasets. No equations, fitted parameters, predictions, or derivations are present in the provided text. The formulation of terrain segmentation via visual appearance is presented as a definitional choice enabling robot-agnostic priors, not as a result derived from prior fitted quantities or self-citations. The work is self-contained as an architectural and data contribution with no load-bearing steps that reduce to inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Au- tonomous vehicle perception: The technology of today and tomorrow,
J. Van Brummelen, M. O’Brien, D. Gruyer, and H. Najjaran, “Au- tonomous vehicle perception: The technology of today and tomorrow,” Transportation Research Part C: Emerging Technologies, 2018
2018
-
[2]
AI4MARS: A Dataset for Terrain-Aware Autonomous Driving on Mars,
R. M. Swan, D. Atha, H. A. Leopold, M. Gildner, S. Oij, C. Chiu, and M. Ono, “AI4MARS: A Dataset for Terrain-Aware Autonomous Driving on Mars,” inIEEE/CVF Conf. on Computer Vision and Pattern Recognition Workshops (CVPRW), 2021
2021
-
[3]
Fast traversability estimation for wild visual navigation,
J. Frey, M. Mattamala, N. Chebrolu, C. Cadena, M. Fallon, and M. Hutter, “Fast traversability estimation for wild visual navigation,” Proc. of Robotics: Science and Systems (RSS), 2023
2023
-
[4]
V-STRONG: Visual Self-Supervised Traversability Learning for Off-road Naviga- tion,
S. Jung, J. Lee, X. Meng, B. Boots, and A. Lambert, “V-STRONG: Visual Self-Supervised Traversability Learning for Off-road Naviga- tion,” inProc. of the IEEE Int. Conf. on Robotics and Automation (ICRA), 2024
2024
-
[5]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,” inProc. of the IEEE/CVF Int. Conf. on Computer Vision (ICCV), 2023
2023
-
[6]
A Photorealistic Terrain Simulation Pipeline for Unstruc- tured Outdoor Environments,
M. G. M ¨uller, M. Durner, A. Gawel, W. St ¨urzl, R. Triebel, and R. Siegwart, “A Photorealistic Terrain Simulation Pipeline for Unstruc- tured Outdoor Environments,” inProc. of the IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), Sep. 2021
2021
-
[7]
A RUGD Dataset for Autonomous Navigation and Visual Perception in Unstructured Outdoor Environments,
M. Wigness, S. Eum, J. G. Rogers, D. Han, and H. Kwon, “A RUGD Dataset for Autonomous Navigation and Visual Perception in Unstructured Outdoor Environments,” inProc. of the IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), 2019
2019
-
[8]
Semantic Image Segmenta- tion: Two Decades of Research,
G. Csurka, R. V olpi, and B. Chidlovskii, “Semantic Image Segmenta- tion: Two Decades of Research,”Foundations and Trends in Computer Graphics and Vision, 2022
2022
-
[9]
Semantic segmentation using Vision Transformers: A survey,
H. Thisanke, C. Deshan, K. Chamith, S. Seneviratne, R. Vi- danaarachchi, and D. Herath, “Semantic segmentation using Vision Transformers: A survey,”Engineering Applications of Artificial Intel- ligence, Nov. 2023
2023
-
[10]
Autonomous Rock Instance Segmenta- tion for Extra-Terrestrial Robotic Missions,
M. Durner, W. Boerdijk, Y . Fanger, R. Sakagami, D. L. Risch, R. Triebel, and A. Wedler, “Autonomous Rock Instance Segmenta- tion for Extra-Terrestrial Robotic Missions,” inProc. of the IEEE Aerospace Conf., 2023
2023
-
[11]
RockFormer: A U-Shaped Transformer Network for Martian Rock Segmentation,
H. Liu, M. Yao, X. Xiao, and Y . Xiong, “RockFormer: A U-Shaped Transformer Network for Martian Rock Segmentation,”IEEE Trans. on Geoscience and Remote Sensing, 2023
2023
-
[12]
DeepTerramechanics: Terrain Classification and Slip Estimation for Ground Robots via Deep Learning
R. Gonzalez and K. Iagnemma, “Deepterramechanics: Terrain classifi- cation and slip estimation for ground robots via deep learning,”arXiv preprint arXiv:1806.07379, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[13]
R. Castilla-Arquillo, C. Perez-del Pulgar, L. Gerdes, A. Garcia-Cerezo, and M. A. Olivares-Mendez, “OmniUnet: A Multimodal Network for Unstructured Terrain Segmentation on Planetary Rovers Using RGB, Depth, and Thermal Imagery,”arXiv preprint arXiv:2508.00580, 2025. TABLE IV EVALUATION ONEXTERRADATASET Model cs ca mIoU mIoU mPre mRec SAM[5]35.0610.0651.73...
-
[14]
Mars Terrain Segmentation with Less Labels,
E. Goh, J. Chen, and B. Wilson, “Mars Terrain Segmentation with Less Labels,” inProc. of the IEEE Aerospace Conf., 2022
2022
-
[15]
S5Mars: Semi- Supervised Learning for Mars Semantic Segmentation,
J. Zhang, L. Lin, Z. Fan, W. Wang, and J. Liu, “S5Mars: Semi- Supervised Learning for Mars Semantic Segmentation,”IEEE Trans. on Geoscience and Remote Sensing, 2024
2024
-
[16]
MTSNet: Joint Feature Adaptation and Enhancement for Text-Guided Multi-view Martian Terrain Segmentation,
Y . Fang, X. Rao, X. Gao, W. Li, and Z. Min, “MTSNet: Joint Feature Adaptation and Enhancement for Text-Guided Multi-view Martian Terrain Segmentation,” inProc. of the ACM Int. Conf. on Multimedia, Melbourne VIC Australia, 2024
2024
-
[17]
CRLNet: Cascaded Resolution Learning Network for Natural Scenes Segmen- tation,
W. Li, S. Tian, G. Hua, M. Liao, Y . Zhang, and W. Zou, “CRLNet: Cascaded Resolution Learning Network for Natural Scenes Segmen- tation,”IEEE Intelligent Systems, 2026
2026
-
[18]
RELLIS-3D Dataset: Data, Benchmarks and Analysis,
P. Jiang, P. Osteen, M. Wigness, and S. Saripalli, “RELLIS-3D Dataset: Data, Benchmarks and Analysis,” inProc. of the IEEE Int. Conf. on Robotics and Automation (ICRA), 2021
2021
-
[19]
GA-Nav: Efficient Terrain Segmen- tation for Robot Navigation in Unstructured Outdoor Environments,
T. Guan, D. Kothandaraman, R. Chandra, A. J. Sathyamoorthy, K. Weerakoon, and D. Manocha, “GA-Nav: Efficient Terrain Segmen- tation for Robot Navigation in Unstructured Outdoor Environments,” IEEE Robotics and Automation Letters, 2022
2022
-
[20]
Contextual-aware terrain segmentation network for navigable areas with triple aggregation,
W. Li, M. Liao, and W. Zou, “Contextual-aware terrain segmentation network for navigable areas with triple aggregation,”Expert Systems with Applications, 2025
2025
-
[21]
Temporally Consistent Unsupervised Segmentation for Mobile Robot Perception,
C. Ellis, M. Wigness, C. Lennon, and L. Fiondella, “Temporally Consistent Unsupervised Segmentation for Mobile Robot Perception,” arXiv preprint arXiv:2507.22194, 2025
-
[22]
Geometric and visual terrain classification for autonomous mobile navigation,
F. Schilling, X. Chen, J. Folkesson, and P. Jensfelt, “Geometric and visual terrain classification for autonomous mobile navigation,” in Proc. of the IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), 2017
2017
-
[23]
Learning Ground Traversability From Simulations,
R. O. Chavez-Garcia, J. Guzzi, L. M. Gambardella, and A. Giusti, “Learning Ground Traversability From Simulations,”IEEE Robotics and Automation Letters, 2018
2018
-
[24]
Real-time Optimal Navigation Planning Using Learned Motion Costs,
B. Yang, L. Wellhausen, T. Miki, M. Liu, and M. Hutter, “Real-time Optimal Navigation Planning Using Learned Motion Costs,” inProc. of the IEEE Int. Conf. on Robotics and Automation (ICRA), 2021
2021
-
[25]
Semantic Terrain Classification for Off-Road Autonomous Driving,
A. Shaban, X. Meng, J. Lee, B. Boots, and D. Fox, “Semantic Terrain Classification for Off-Road Autonomous Driving,” inProc. of the Conf. on Robot Learning (CORL), 2022
2022
-
[26]
BADGR: An Autonomous Self- Supervised Learning-Based Navigation System,
G. Kahn, P. Abbeel, and S. Levine, “BADGR: An Autonomous Self- Supervised Learning-Based Navigation System,”IEEE Robotics and Automation Letters, 2021
2021
-
[27]
Where Should I Walk? Predicting Terrain Properties From Images Via Self-Supervised Learning,
L. Wellhausen, A. Dosovitskiy, R. Ranftl, K. Walas, C. Cadena, and M. Hutter, “Where Should I Walk? Predicting Terrain Properties From Images Via Self-Supervised Learning,”IEEE Robotics and Automation Letters, 2019
2019
-
[28]
WayFAST: Navigation With Predictive Traversability in the Field,
M. V . Gasparino, A. N. Sivakumar, Y . Liu, A. E. B. Velasquez, V . A. H. Higuti, J. Rogers, H. Tran, and G. Chowdhary, “WayFAST: Navigation With Predictive Traversability in the Field,”IEEE Robotics and Automation Letters, 2022
2022
-
[29]
TerraPN: Unstructured Terrain Navigation using Online Self-Supervised Learning,
A. J. Sathyamoorthy, K. Weerakoon, T. Guan, J. Liang, and D. Manocha, “TerraPN: Unstructured Terrain Navigation using Online Self-Supervised Learning,” inProc. of the IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), 2022
2022
-
[30]
Bayesian Nonparametric Submodular Video Partition for Robust Anomaly Detection,
H. Sapkota and Q. Yu, “Bayesian Nonparametric Submodular Video Partition for Robust Anomaly Detection,” inConf. on Computer Vision and Pattern Recognition, 2022
2022
-
[31]
Uncertainty Estimation for Planetary Robotic Terrain Segmentation,
M. G. M ¨uller, M. Durner, W. Boerdijk, H. Blum, A. Gawel, W. St¨urzl, R. Siegwart, and R. Triebel, “Uncertainty Estimation for Planetary Robotic Terrain Segmentation,” inProc. of the IEEE Aerospace Conf., 2023
2023
-
[32]
Entropy Maximization and Meta Classification for Out-of-Distribution Detection in Semantic Segmentation,
R. Chan, M. Rottmann, and H. Gottschalk, “Entropy Maximization and Meta Classification for Out-of-Distribution Detection in Semantic Segmentation,” inProc. of the IEEE/CVF Int. Conf. on Computer Vision (ICCV), 2021
2021
-
[33]
Simultaneous Seman- tic Segmentation and Outlier Detection in Presence of Domain Shift,
P. Bevandi ´c, I. Kreˇso, M. Orˇsi´c, and S. ˇSegvi´c, “Simultaneous Seman- tic Segmentation and Outlier Detection in Presence of Domain Shift,” inPattern Recognition, 2019
2019
-
[34]
Detecting Road Obstacles by Erasing Them,
K. Lis, S. Honari, P. Fua, and M. Salzmann, “Detecting Road Obstacles by Erasing Them,” inIEEE Trans. on Pattern Analysis and Machine Intelligence, 2024
2024
-
[35]
OmniAL: A Unified CNN Framework for Unsupervised Anomaly Localization,
Y . Zhao, “OmniAL: A Unified CNN Framework for Unsupervised Anomaly Localization,” inConf. on Computer Vision and Pattern Recognition, 2023
2023
-
[36]
Uninformed Students: Student-Teacher Anomaly Detection With Discriminative Latent Embeddings,
P. Bergmann, M. Fauser, D. Sattlegger, and C. Steger, “Uninformed Students: Student-Teacher Anomaly Detection With Discriminative Latent Embeddings,” inConf. on Computer Vision and Pattern Recog- nition, 2020
2020
-
[37]
DeSTSeg: Segmentation Guided Denoising Student-Teacher for Anomaly Detec- tion,
X. Zhang, S. Li, X. Li, P. Huang, J. Shan, and T. Chen, “DeSTSeg: Segmentation Guided Denoising Student-Teacher for Anomaly Detec- tion,” inConf. on Computer Vision and Pattern Recognition, 2023
2023
-
[38]
Multi-Scale Patch-Based Rep- resentation Learning for Image Anomaly Detection and Segmenta- tion,
C.-C. Tsai, T.-H. Wu, and S.-H. Lai, “Multi-Scale Patch-Based Rep- resentation Learning for Image Anomaly Detection and Segmenta- tion,” inIEEE/CVF Winter Conf. on Applications of Computer Vision (WACV), 2022
2022
-
[39]
Open- World Semantic Segmentation Including Class Similarity,
M. Sodano, F. Magistri, L. Nunes, J. Behley, and C. Stachniss, “Open- World Semantic Segmentation Including Class Similarity,” inConf. on Computer Vision and Pattern Recognition, 2024
2024
-
[40]
SCIM: Simultaneous Clustering, Inference, and Mapping for Open- World Semantic Scene Understanding,
H. Blum, M. G. M ¨uller, A. Gawel, R. Siegwart, and C. Cadena, “SCIM: Simultaneous Clustering, Inference, and Mapping for Open- World Semantic Scene Understanding,” inRobotics Research, 2023
2023
-
[41]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khali- dov, P. Fernandez, D. Haziza, F. Massa, A. El-Noubyet al., “Dinov2: Learning robust visual features without supervision,”arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.