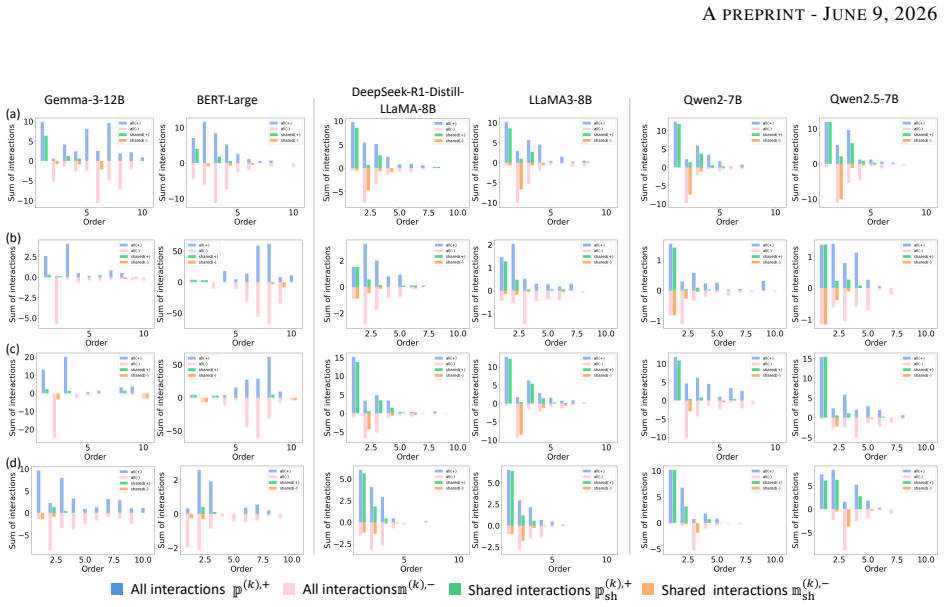
Cross-LLM Consistency in Inference: Evidence from Shared Interactions
Pith reviewed 2026-06-27 19:49 UTC · model grok-4.3
The pith
Large language models share interaction patterns in their internal inference when predicting the same tokens from the same prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
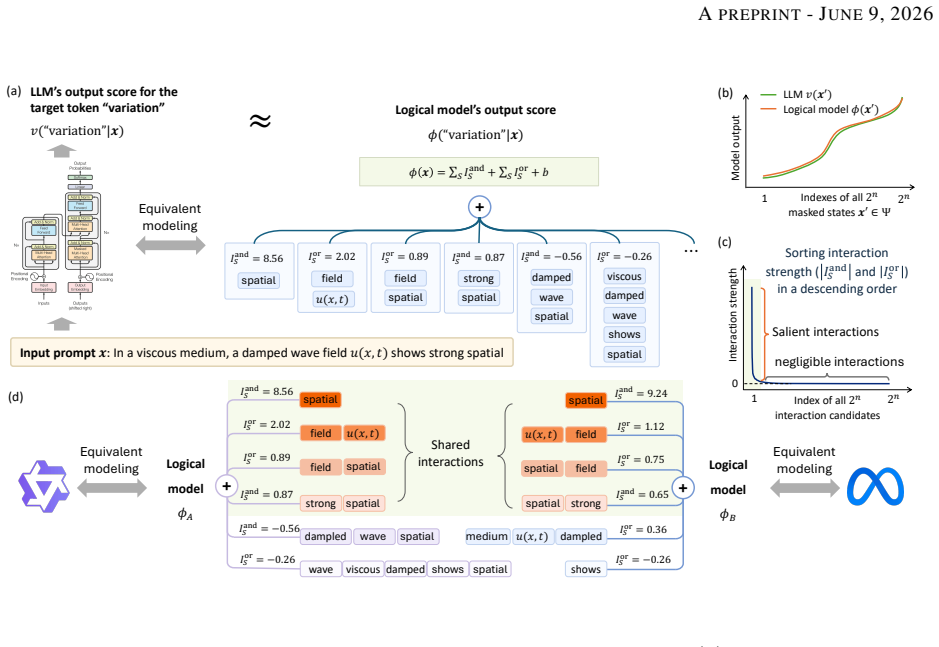
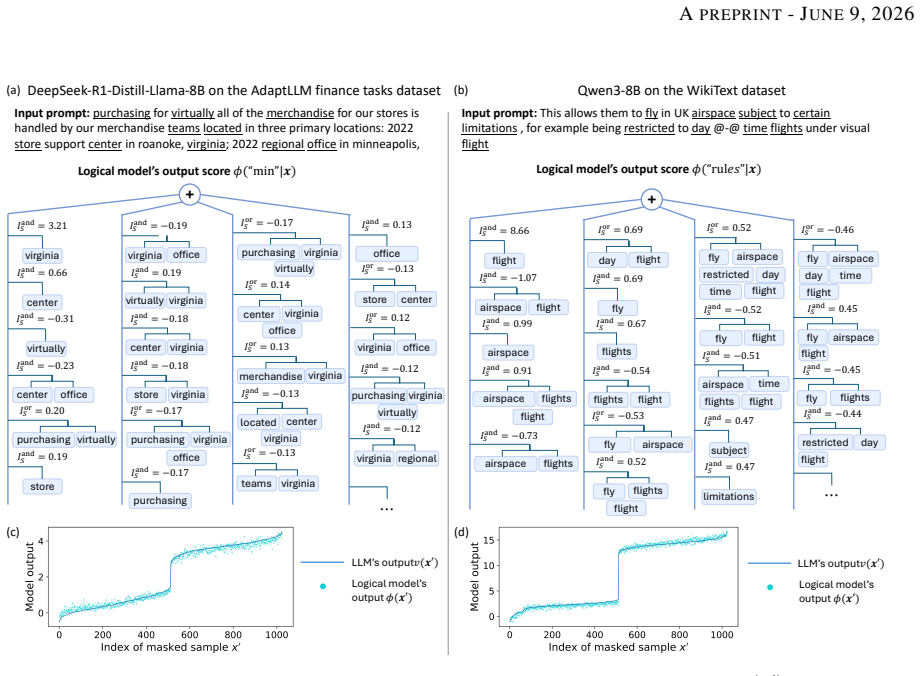
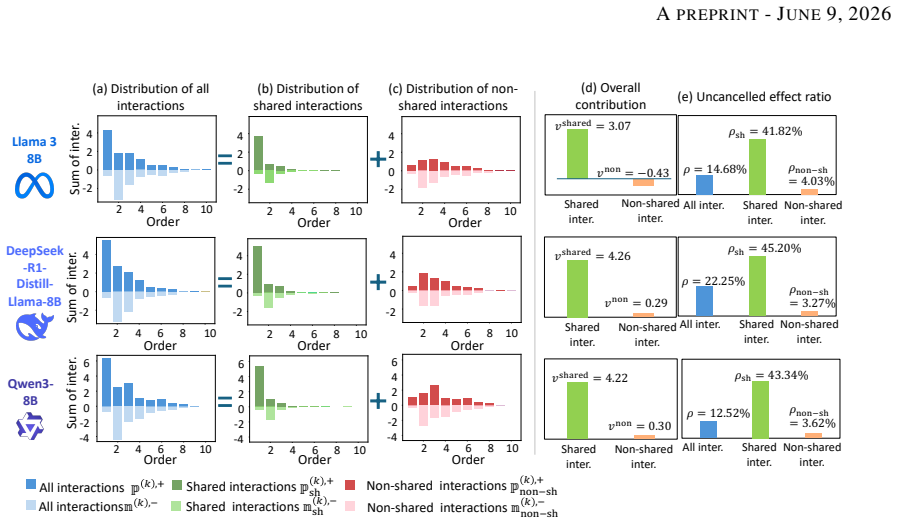
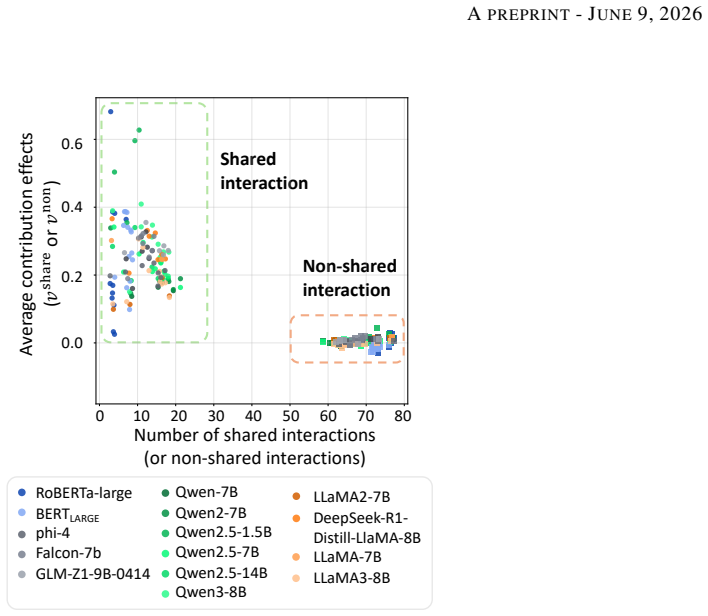
LLMs often share interaction patterns when predicting the same target token from the same prompt. This consistency is more pronounced among advanced LLMs. Shared interactions also tend to be lower-order and show weaker positive-negative cancellation than non-shared interactions. These results suggest that advanced LLMs may be implicitly optimized toward common inference patterns, even though the mechanisms that give rise to such cross-model consistency remain open.
What carries the argument
interaction-based explanations, which decompose each model's prediction into additive and higher-order interactions among input features to enable direct comparison of inference mechanisms across models
Load-bearing premise
Interaction-based explanations accurately capture and compare the internal inference mechanisms across different LLMs.
What would settle it
Applying the same interaction decomposition to a new collection of LLMs and prompts and finding no measurable overlap in the extracted interaction sets would falsify the reported consistency.
Figures

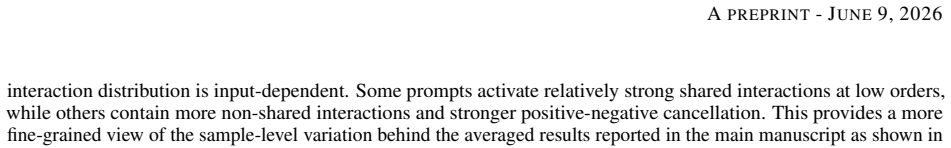

read the original abstract
Large language models (LLMs) differ in architecture, training data, and optimization procedures, yet they may still develop similar internal inference patterns. In this paper, we examine this hypothesis using interaction-based explanations. We find that LLMs often share interaction patterns when predicting the same target token from the same prompt. This consistency is more pronounced among advanced LLMs. Shared interactions also tend to be lower-order and show weaker positive-negative cancellation than non-shared interactions. These results suggest that advanced LLMs may be implicitly optimized toward common inference patterns, even though the mechanisms that give rise to such cross-model consistency remain open.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper examines the hypothesis that LLMs develop similar internal inference patterns despite differences in architecture, training data, and optimization. Using interaction-based explanations, it finds that LLMs often share interaction patterns when predicting the same target token from the same prompt, with this consistency more pronounced among advanced LLMs. Shared interactions tend to be lower-order and show weaker positive-negative cancellation than non-shared interactions.
Significance. If these results hold after addressing methodological concerns, they would indicate convergence toward common inference patterns in advanced LLMs. This could advance interpretability research by providing evidence of implicit optimization across models, though the observational nature requires robust validation of the explanation method.
major comments (2)
- [Abstract] Abstract: The abstract states findings but supplies no methods, sample sizes, statistical tests, or controls, so it is impossible to determine whether the data support the claim as stated.
- [Methods] Methods: No evidence is provided that the interaction extraction procedure normalizes for differences in model scale, tokenizer, or layer structure; without such normalization, apparent sharing could arise from the explanation method itself rather than from shared inference. This assumption is load-bearing for the central claim.
minor comments (2)
- Consider adding a table or section summarizing the specific LLMs, prompts, and sample sizes used to improve reproducibility.
- [Results] Clarify the precise definition and measurement of 'lower-order' interactions and 'positive-negative cancellation' with reference to the relevant equations or algorithms.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive report. The comments highlight important points about clarity and methodological robustness. We address each major comment below, indicating planned revisions where appropriate. We believe these changes will strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states findings but supplies no methods, sample sizes, statistical tests, or controls, so it is impossible to determine whether the data support the claim as stated.
Authors: We agree that the abstract, as a concise summary, omits specific methodological details, sample sizes, and statistical tests. This is standard due to length limits, with full details provided in the Methods and Results sections of the manuscript (including prompt counts, interaction extraction steps, and consistency metrics with associated tests). To improve accessibility, we will revise the abstract to include a brief clause on the interaction-based method and mention of controls for prompt consistency. revision: partial
-
Referee: [Methods] Methods: No evidence is provided that the interaction extraction procedure normalizes for differences in model scale, tokenizer, or layer structure; without such normalization, apparent sharing could arise from the explanation method itself rather than from shared inference. This assumption is load-bearing for the central claim.
Authors: This is a substantive methodological concern. The current manuscript describes the interaction extraction procedure but does not explicitly demonstrate or justify normalization steps for model scale, tokenizer vocabulary differences, or layer alignment. We will add a dedicated subsection to the Methods section that provides this evidence, including any scaling factors, alignment techniques, or robustness analyses across architectures to rule out method-induced artifacts. revision: yes
Circularity Check
Observational study with no derivation chain or self-referential reductions
full rationale
The paper is an empirical observational study that reports findings on shared interaction patterns across LLMs using interaction-based explanations. The abstract and provided text contain no equations, derivations, fitted parameters presented as predictions, or self-citations that serve as load-bearing premises for a claimed result. The central claims are direct empirical observations (e.g., consistency more pronounced among advanced LLMs) rather than any mathematical reduction that collapses to the inputs by construction. This is the most common honest outcome for non-derivational work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Harkirat Behl, Sébastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Har- rison, Russell J Hewett, Mojan Javaheripi, Piero Kauffmann, et al. Phi-4 technical report.arXiv preprint arXiv:2412.08905, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Qwen 2.5: A comprehensive review of the leading resource-efficient llm with potentioal to surpass all competitors
Imtiaz Ahmed, Sadman Islam, Partha Protim Datta, Imran Kabir, Md Naseef Ur Rahman Chowdhury, and Ahshanul Haque. Qwen 2.5: A comprehensive review of the leading resource-efficient llm with potentioal to surpass all competitors. 2025
2025
-
[3]
The Falcon Series of Open Language Models
Ebtesam Almazrouei, Hamza Alobeidli, Abdulaziz Alshamsi, Alessandro Cappelli, Ruxandra Cojocaru, Mérouane Debbah, Étienne Goffinet, Daniel Hesslow, Julien Launay, Quentin Malartic, et al. The falcon series of open language models.arXiv preprint arXiv:2311.16867, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
On the dangers of stochastic parrots: Can language models be too big? InProceedings of the 2021 ACM conference on fairness, accountability, and transparency, pages 610–623, 2021
Emily M Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. On the dangers of stochastic parrots: Can language models be too big? InProceedings of the 2021 ACM conference on fairness, accountability, and transparency, pages 610–623, 2021
2021
-
[6]
Holistic evaluation of language models.Annals of the New York Academy of Sciences, 1525(1):140–146, 2023
Rishi Bommasani, Percy Liang, and Tony Lee. Holistic evaluation of language models.Annals of the New York Academy of Sciences, 1525(1):140–146, 2023
2023
-
[7]
Proxyspex: Inference-efficient interpretability via sparse feature interactions in llms.Advances in Neural Information Processing Systems, 38:72306–72340, 2026
Landon Butler, Abhineet Agarwal, Justin Kang, Yigit Efe Erginbas, Bin Yu, and Kannan Ramchandran. Proxyspex: Inference-efficient interpretability via sparse feature interactions in llms.Advances in Neural Information Processing Systems, 38:72306–72340, 2026
2026
-
[8]
Defining and extracting generalizable interaction primitives from dnns
Lu Chen, Siyu Lou, Benhao Huang, and Quanshi Zhang. Defining and extracting generalizable interaction primitives from dnns. InInternational Conference on Learning Representations, volume 2024, pages 23780– 23802, 2024
2024
-
[9]
Convfinqa: Exploring the chain of numerical reasoning in conversational finance question answering
Zhiyu Chen, Shiyang Li, Charese Smiley, Zhiqiang Ma, Sameena Shah, and William Yang Wang. Convfinqa: Exploring the chain of numerical reasoning in conversational finance question answering. InProceedings of the 2022 conference on empirical methods in natural language processing, pages 6279–6292, 2022
2022
-
[10]
Adapting large language models via reading comprehension
Daixuan Cheng, Shaohan Huang, and Furu Wei. Adapting large language models via reading comprehension. In International Conference on Learning Representations, volume 2024, pages 48624–48652, 2024. 10 APREPRINT- JUNE9, 2026
2024
-
[11]
Discovering and explaining the representation bottleneck of dnns
Huiqi Deng, Qihan Ren, Hao Zhang, and Quanshi Zhang. Discovering and explaining the representation bottleneck of dnns. InInternational Conference on Learning Representations, 2022
2022
-
[12]
Unifying fourteen post-hoc attribution methods with taylor interactions.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(7):4625–4640, 2024
Huiqi Deng, Na Zou, Mengnan Du, Weifu Chen, Guocan Feng, Ziwei Yang, Zheyang Li, and Quanshi Zhang. Unifying fourteen post-hoc attribution methods with taylor interactions.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(7):4625–4640, 2024
2024
-
[13]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
2019
-
[14]
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Team Glm, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Dan Zhang, Diego Rojas, Guanyu Feng, Hanlin Zhao, et al. Chatglm: A family of large language models from glm-130b to glm-4 all tools.arXiv preprint arXiv:2406.12793, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Towards the three-phase dynamics of generalization power of a dnn.arXiv e-prints, pages arXiv–2505, 2025
Yuxuan He, Junpeng Zhang, Hongyuan Zhang, and Quanshi Zhang. Towards the three-phase dynamics of generalization power of a dnn.arXiv e-prints, pages arXiv–2505, 2025
2025
-
[18]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. Qwen2. 5-coder technical report.arXiv preprint arXiv:2409.12186, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Mate- jovicova, Alexandre Ramé, Morgane Rivière, Louis Rouillard, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 4, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Learning to understand: Identifying interactions via the möbius transform.Advances in Neural Information Processing Systems, 37:46160–46202, 2024
Justin S Kang, Yigit E Erginbas, Landon Butler, Ramtin Pedarsani, and Kannan Ramchandran. Learning to understand: Identifying interactions via the möbius transform.Advances in Neural Information Processing Systems, 37:46160–46202, 2024
2024
-
[21]
Spex: Scaling feature interaction explanations for llms.arXiv preprint arXiv:2502.13870, 2025
Justin Singh Kang, Landon Butler, Abhineet Agarwal, Yigit Efe Erginbas, Ramtin Pedarsani, Kannan Ramchan- dran, and Bin Yu. Spex: Scaling feature interaction explanations for llms.arXiv preprint arXiv:2502.13870, 2025
-
[22]
Does a neural network really encode symbolic concepts? InInternational conference on machine learning, pages 20452–20469
Mingjie Li and Quanshi Zhang. Does a neural network really encode symbolic concepts? InInternational conference on machine learning, pages 20452–20469. PMLR, 2023
2023
-
[23]
Towards the difficulty for a deep neural network to learn concepts of different complexities.Advances in Neural Information Processing Systems, 36:41283–41304, 2023
Dongrui Liu, Huiqi Deng, Xu Cheng, Qihan Ren, Kangrui Wang, and Quanshi Zhang. Towards the difficulty for a deep neural network to learn concepts of different complexities.Advances in Neural Information Processing Systems, 36:41283–41304, 2023
2023
-
[24]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach.arXiv preprint arXiv:1907.11692, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[25]
Www’18 open challenge: financial opinion mining and question answering
Macedo Maia, Siegfried Handschuh, André Freitas, Brian Davis, Ross McDermott, Manel Zarrouk, and Alexandra Balahur. Www’18 open challenge: financial opinion mining and question answering. InCompanion proceedings of the the web conference 2018, pages 1941–1942, 2018
2018
-
[26]
Good debt or bad debt: Detecting semantic orientations in economic texts.Journal of the Association for Information Science and Technology, 65 (4):782–796, 2014
Pekka Malo, Ankur Sinha, Pekka Korhonen, Jyrki Wallenius, and Pyry Takala. Good debt or bad debt: Detecting semantic orientations in economic texts.Journal of the Association for Information Science and Technology, 65 (4):782–796, 2014
2014
-
[27]
Pointer Sentinel Mixture Models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models.arXiv preprint arXiv:1609.07843, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[28]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[29]
Towards a unified game-theoretic view of adversarial perturbations and robustness.Advances in Neural Information Processing Systems, 34:3797–3810, 2021
Jie Ren, Die Zhang, Yisen Wang, Lu Chen, Zhanpeng Zhou, Yiting Chen, Xu Cheng, Xin Wang, Meng Zhou, Jie Shi, et al. Towards a unified game-theoretic view of adversarial perturbations and robustness.Advances in Neural Information Processing Systems, 34:3797–3810, 2021. 11 APREPRINT- JUNE9, 2026
2021
-
[30]
Defining and quantifying the emergence of sparse concepts in dnns
Jie Ren, Mingjie Li, Qirui Chen, Huiqi Deng, and Quanshi Zhang. Defining and quantifying the emergence of sparse concepts in dnns. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20280–20289, 2023
2023
-
[31]
Bayesian neural networks avoid encoding complex and perturbation-sensitive concepts
Qihan Ren, Huiqi Deng, Yunuo Chen, Siyu Lou, and Quanshi Zhang. Bayesian neural networks avoid encoding complex and perturbation-sensitive concepts. InInternational Conference on Machine Learning, pages 28889– 28913. PMLR, 2023
2023
-
[32]
Where we have arrived in proving the emergence of sparse interaction primitives in dnns
Qihan Ren, Jiayang Gao, Wen Shen, and Quanshi Zhang. Where we have arrived in proving the emergence of sparse interaction primitives in dnns. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[33]
Towards the dynamics of a dnn learning symbolic interactions.Advances in Neural Information Processing Systems, 37:50653–50688, 2024
Qihan Ren, Junpeng Zhang, Yang Xu, Yue Xin, Dongrui Liu, and Quanshi Zhang. Towards the dynamics of a dnn learning symbolic interactions.Advances in Neural Information Processing Systems, 37:50653–50688, 2024
2024
-
[34]
On the foundations of combinatorial theory: I
Gian-Carlo Rota. On the foundations of combinatorial theory: I. theory of möbius functions. InClassic Papers in Combinatorics, pages 332–360. Springer, 1964
1964
-
[35]
Agam Shah, Abhinav Gullapalli, Ruchit Vithani, Michael Galarnyk, and Sudheer Chava. Finer-ord: financial named entity recognition open research dataset.arXiv preprint arXiv:2302.11157, 2023
-
[36]
Talking about large language models.Communications of the ACM, 67(2):68–79, 2024
Murray Shanahan. Talking about large language models.Communications of the ACM, 67(2):68–79, 2024
2024
-
[37]
Sentfin 1.0: Entity-aware sentiment analysis for financial news.Journal of the Association for Information Science and Technology, 73(9):1314–1335, 2022
Ankur Sinha, Satishwar Kedas, Rishu Kumar, and Pekka Malo. Sentfin 1.0: Entity-aware sentiment analysis for financial news.Journal of the Association for Information Science and Technology, 73(9):1314–1335, 2022
2022
-
[38]
Understanding and sharing intentions: The origins of cultural cognition.Behavioral and brain sciences, 28(5):675–691, 2005
Michael Tomasello, Malinda Carpenter, Josep Call, Tanya Behne, and Henrike Moll. Understanding and sharing intentions: The origins of cultural cognition.Behavioral and brain sciences, 28(5):675–691, 2005
2005
-
[39]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
A unified approach to interpreting and boosting adversarial transferability
Xin Wang, Jie Ren, Shuyun Lin, Xiangming Zhu, Yisen Wang, and Quanshi Zhang. A unified approach to interpreting and boosting adversarial transferability. InInternational Conference on Learning Representations, 2021
2021
-
[42]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Explaining generalization power of a dnn using interactive concepts
Huilin Zhou, Hao Zhang, Huiqi Deng, Dongrui Liu, Wen Shen, Shih-Han Chan, and Quanshi Zhang. Explaining generalization power of a dnn using interactive concepts. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 17105–17113, 2024
2024
-
[44]
Towards the first principles of explaining dnns: interactions explain the learning dynamics.Frontiers of Information Technology & Electronic Engineering, 26(7): 1017–1026, 2025
Huilin Zhou, Qihan Ren, Junpeng Zhang, and Quanshi Zhang. Towards the first principles of explaining dnns: interactions explain the learning dynamics.Frontiers of Information Technology & Electronic Engineering, 26(7): 1017–1026, 2025
2025
-
[45]
General scales unlock ai evaluation with explanatory and predictive power.Nature, 652(8108):58–67, 2026
Lexin Zhou, Lorenzo Pacchiardi, Fernando Martínez-Plumed, Katherine M Collins, Yael Moros-Daval, Seraphina Zhang, Qinlin Zhao, Yitian Huang, Luning Sun, Jonathan E Prunty, et al. General scales unlock ai evaluation with explanatory and predictive power.Nature, 652(8108):58–67, 2026. 12 APREPRINT- JUNE9, 2026 A Sparsity Property of Interactions Ren et al. ...
2026
-
[46]
That is, interactions involving too many input variables have zero or negligible contribution to the output
Bounded interaction order.The network does not rely on extremely high-order interactions. That is, interactions involving too many input variables have zero or negligible contribution to the output. Formally, there exists an order threshold M such that the interaction effect I(S) vanishes for any subset S with |S|> M
-
[47]
Specifically, let ¯u(m) denote the average output change when m variables are revealed, compared with the fully masked baseline: ¯u(m) =E S⊆N,|S|=m [v(xS)−v(x ∅)]
Monotonic response under masking.When more input variables are masked, the average network response decreases monotonically. Specifically, let ¯u(m) denote the average output change when m variables are revealed, compared with the fully masked baseline: ¯u(m) =E S⊆N,|S|=m [v(xS)−v(x ∅)]. Then, form ′ < m, the average response satisfies ¯u(m′) ≤¯u(m). This...
-
[48]
In particular, for anym ′ < m, there exists a positive constantp >0such that ¯u(m′) ≥ m′ m p ¯u(m)
Polynomial lower bound on average response.The average response does not decay too sharply when fewer variables are revealed. In particular, for anym ′ < m, there exists a positive constantp >0such that ¯u(m′) ≥ m′ m p ¯u(m). This polynomial lower bound rules out the case where the model output is dominated by dense, extremely high-order interactions. Tog...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.