Automated sign detection across the Electronic Babylonian Library: A large-scale dataset and end-to-end cuneiform OCR pipeline
Pith reviewed 2026-06-26 10:59 UTC · model grok-4.3
The pith
A DETR-based system detects cuneiform signs on tablets with up to 37% higher accuracy and yields 2.9 million detections from 87,668 fragments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
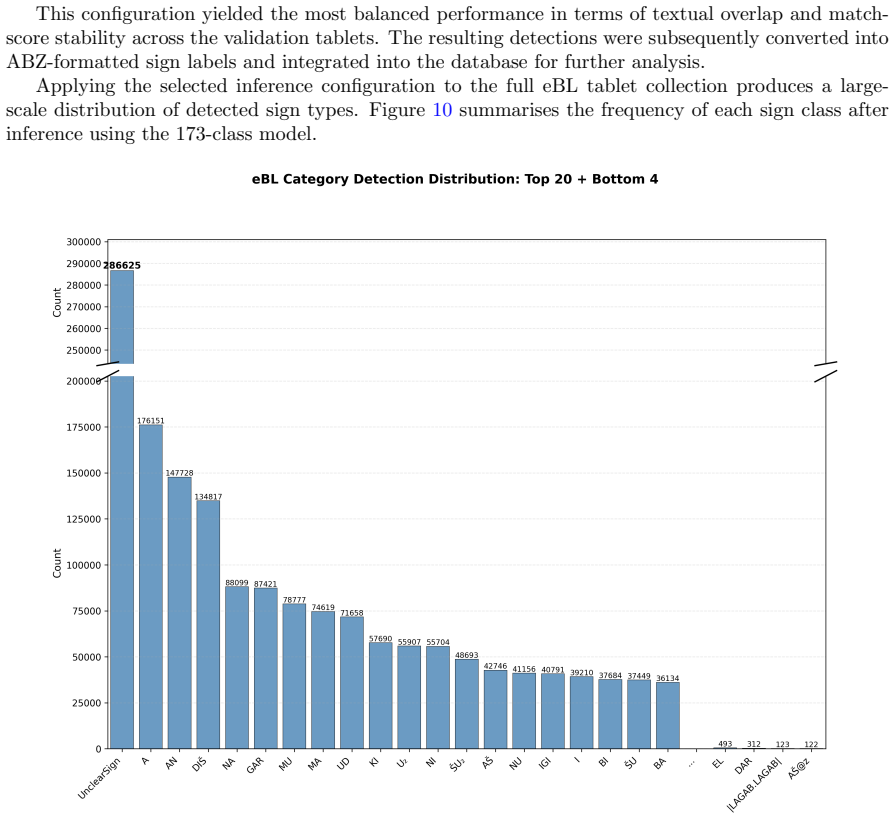
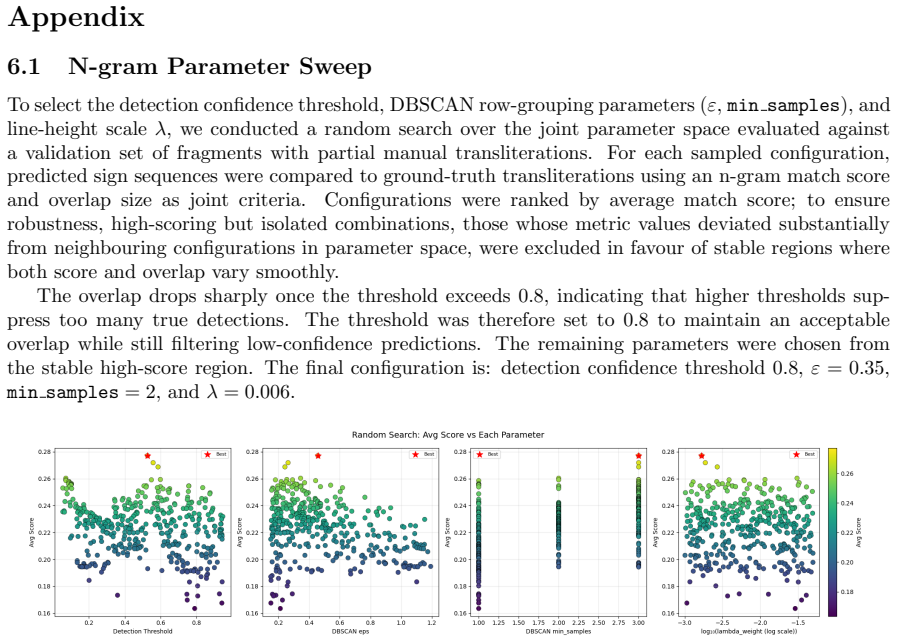
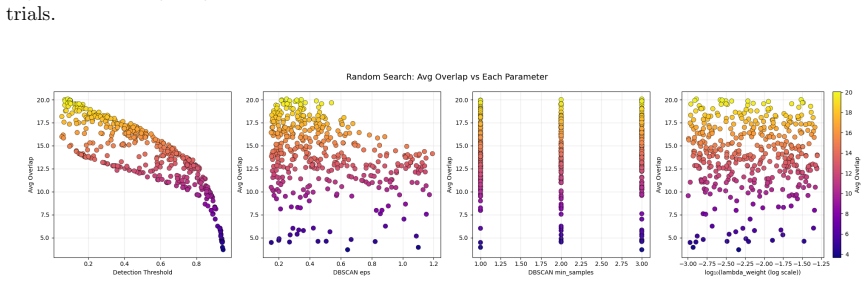
The authors train a Deformable Detection Transformer object detector on the largest annotated cuneiform sign dataset to date, evaluate it at 173-class and 106-class granularities, and combine it with automatic tablet-side extraction, heuristic line grouping, and n-gram-based textual similarity evaluation; the integrated system improves COCO-style metrics by 28-37% over prior work and, when applied to 87,668 eBL fragments, produces nearly 2.9 million sign detections while operating without linguistic priors.
What carries the argument
Deformable Detection Transformer (DETR) object detection model that locates cuneiform signs in tablet images, extended by heuristic line grouping and n-gram textual similarity evaluation that align detections with tablet structure.
If this is right
- Up to 37% gains on COCO detection metrics compared with earlier cuneiform sign detectors.
- Nearly 2.9 million sign detections produced across the 87,668-fragment eBL corpus.
- Scalable processing pipeline that works without linguistic priors.
- Explicit support for later addition of multimodal and linguistic modeling layers.
Where Pith is reading between the lines
- The released detections could supply initial sign inventories that speed up manual decipherment of the remaining unstudied tablets.
- The noted sensitivity to damage indicates that pairing the visual output with language models would be a direct next test.
- The large annotated dataset can function as a public benchmark for other ancient-script vision tasks.
- The same extraction-plus-grouping pattern may transfer to other complex sign systems such as Egyptian hieroglyphs.
Load-bearing premise
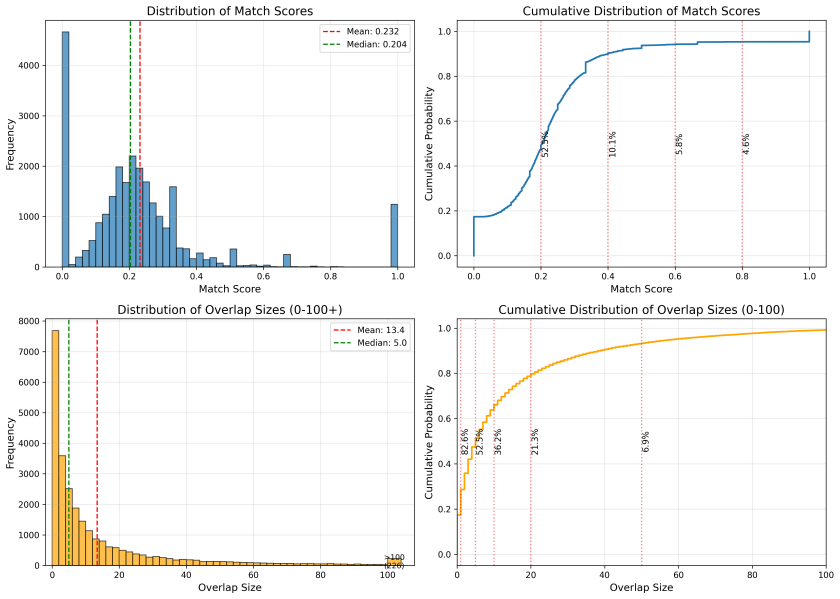
Heuristic line grouping and n-gram similarity can reliably link visual sign detections to textual lines even on damaged or irregularly laid-out tablets.
What would settle it
Measure whether the full pipeline's accuracy on a test set of heavily damaged tablets falls below the accuracy of the visual detector alone.
Figures

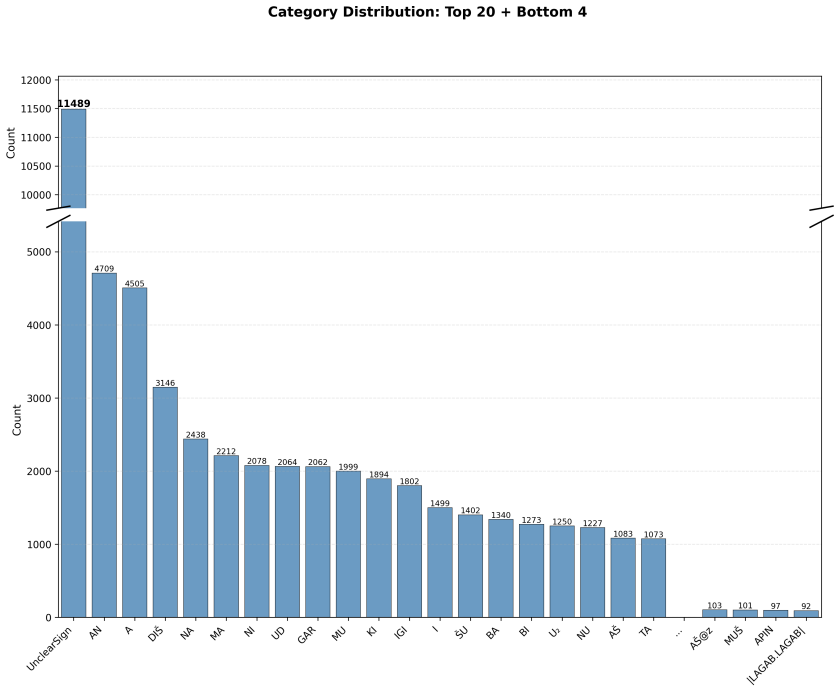
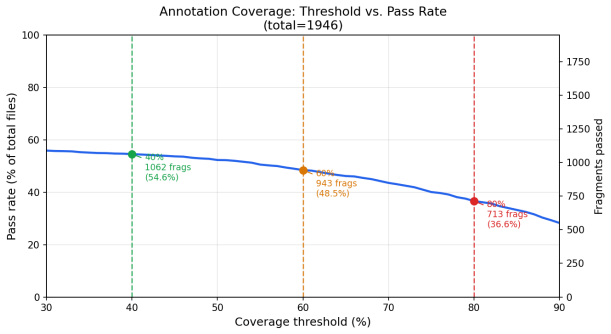



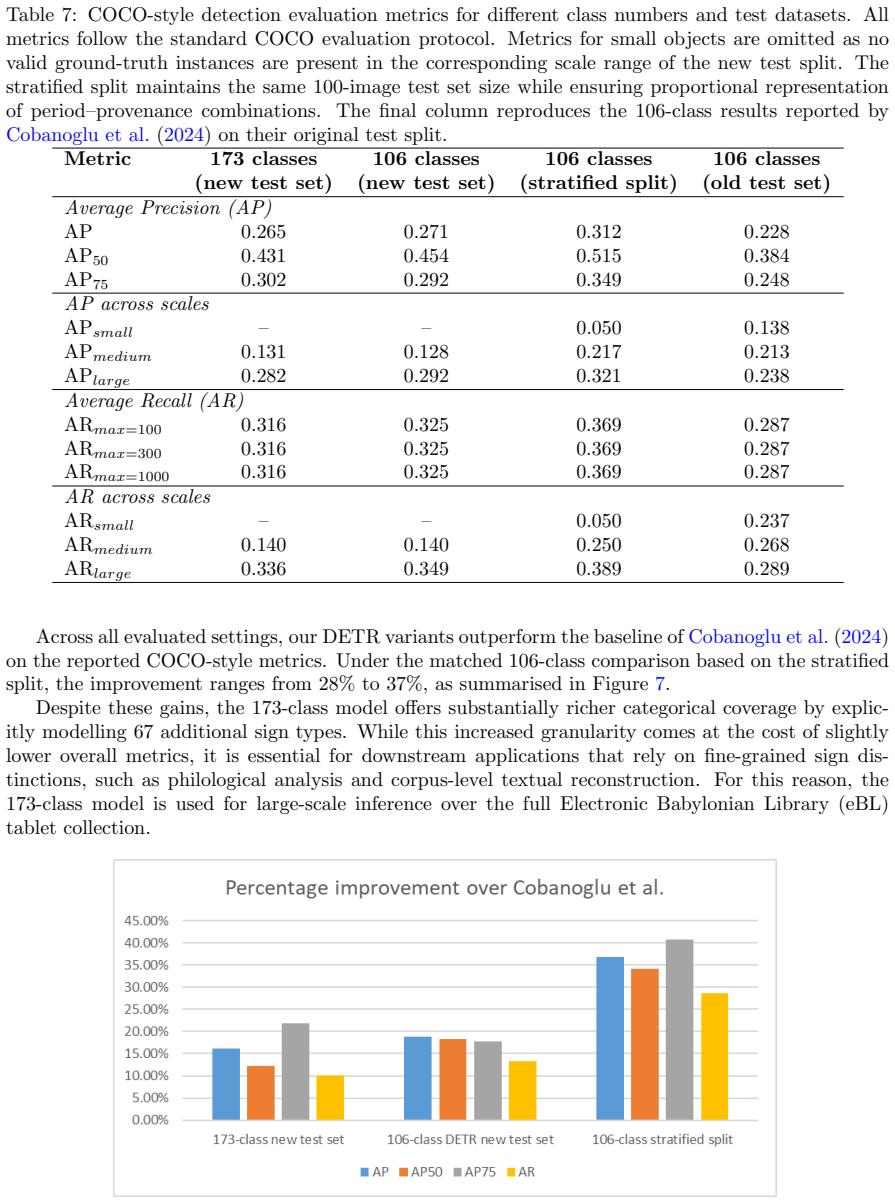

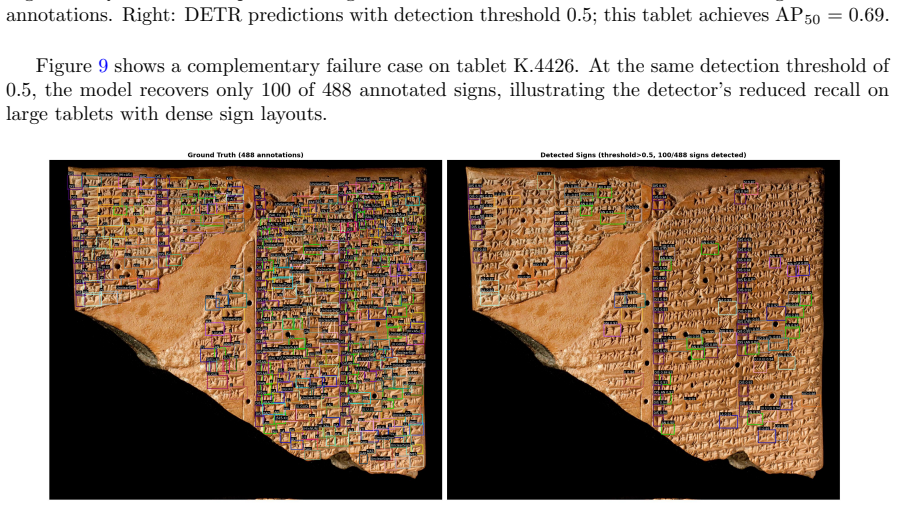
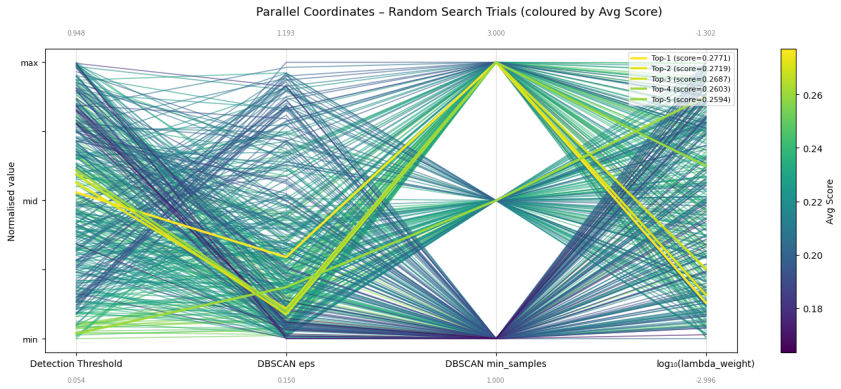
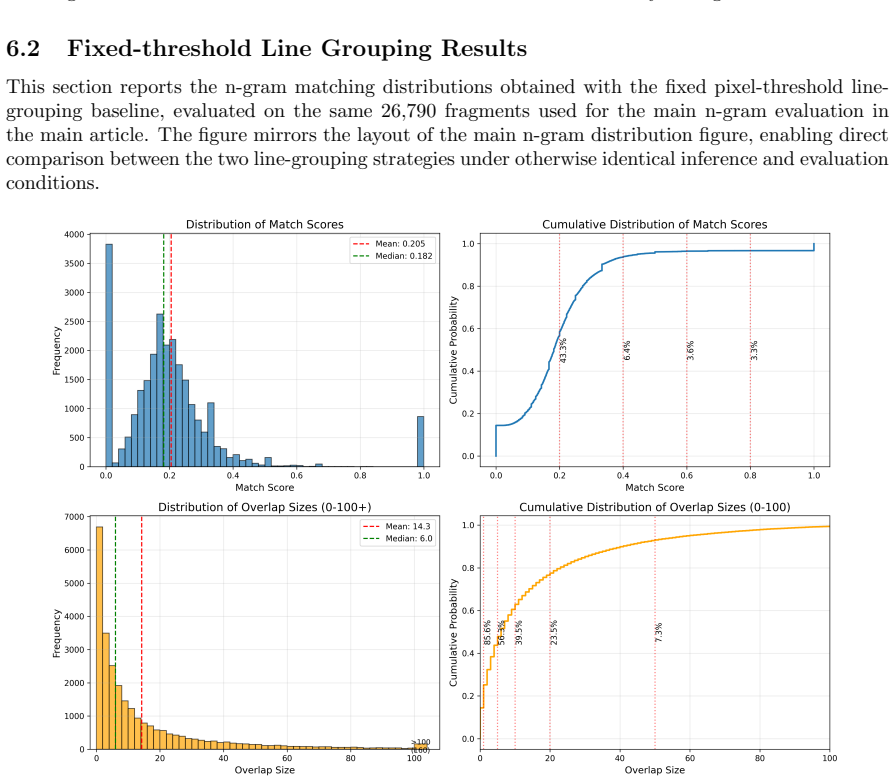
read the original abstract
Learning to read cuneiform tablets is an extremely demanding task; consequently, of the roughly half million excavated tablets, only a small fraction has been analysed by Assyriologists. Computer vision offers a promising avenue for decipherment but requires large, densely annotated datasets. To address this limitation, the largest annotated cuneiform sign dataset to date is used, and a Deformable Detection Transformer (DETR)-based object detection model is evaluated under two class granularities of 173 and 106 classes. The proposed system integrates automatic tablet-side extraction, heuristic line grouping, and n-gram-based textual similarity evaluation to bridge visual sign detection and textual structure, and achieves consistent improvements of up to 28-37% over prior work on COCO-style detection metrics. At inference, the method is applied to 87,668 tablet fragments from the Electronic Babylonian Library (eBL) corpus, producing nearly 2.9 million sign detections. Although the approach operates without linguistic priors and remains sensitive to tablet damage and layout variability, it provides a scalable and interpretable foundation for corpus-wide cuneiform analysis and supports future integration with multimodal and linguistic modelling frameworks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a Deformable DETR-based object detection pipeline for cuneiform signs, trained on the largest annotated dataset to date under 173- and 106-class granularities. It integrates automatic tablet-side extraction, heuristic line grouping, and n-gram-based textual similarity evaluation to link visual detections to textual structure, reports consistent 28-37% gains over prior work on COCO-style metrics, and applies the system to 87,668 eBL tablet fragments to produce nearly 2.9 million sign detections. The approach is described as operating without linguistic priors while remaining sensitive to damage and layout variability.
Significance. If the reported detection gains prove robust and the heuristic components are shown to deliver measurable improvements in bridging visual detections to textual structure, the work would supply a scalable, interpretable foundation for corpus-wide cuneiform analysis. The scale of inference across nearly 88k fragments and the production of millions of detections constitute a concrete strength that could support future multimodal and linguistic integration.
major comments (3)
- [Abstract] Abstract: the central claim of 28-37% gains on COCO-style metrics is presented without dataset size, annotation protocol, train/test split details, baseline specifications, error bars, or ablation isolating the contribution of the heuristic line grouping and n-gram stages versus the DETR detector alone.
- [Abstract] Abstract: no precision, recall, or alignment-error metrics are supplied for the heuristic line grouping and n-gram-based textual similarity evaluation on held-out transcribed tablets, leaving the end-to-end bridging claim unquantified and inseparable from isolated sign-detection performance.
- [Abstract] Abstract: the inference results (87,668 fragments, 2.9 million detections) are stated at high level, yet the abstract itself flags remaining sensitivity to tablet damage and layout variability without reporting any quantitative evaluation of the heuristics under those conditions.
minor comments (1)
- The abstract would be strengthened by a single sentence stating the total number of annotated signs or images in the training dataset.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract. We agree that greater precision is needed regarding the scope of the reported results and will revise the abstract accordingly. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 28-37% gains on COCO-style metrics is presented without dataset size, annotation protocol, train/test split details, baseline specifications, error bars, or ablation isolating the contribution of the heuristic line grouping and n-gram stages versus the DETR detector alone.
Authors: The manuscript body (Sections 3–4) specifies the dataset as the largest annotated cuneiform sign collection to date under 173- and 106-class granularities, the train/test protocol, and the Deformable DETR baseline comparisons that produce the 28–37% COCO-metric gains. We will revise the abstract to include a concise reference to dataset scale and the DETR-based detector while noting that full ablations appear in the main text. Error bars are not reported because the evaluation adheres to the standard single-run COCO protocol. This revision will be made. revision: yes
-
Referee: [Abstract] Abstract: no precision, recall, or alignment-error metrics are supplied for the heuristic line grouping and n-gram-based textual similarity evaluation on held-out transcribed tablets, leaving the end-to-end bridging claim unquantified and inseparable from isolated sign-detection performance.
Authors: We acknowledge that the manuscript does not supply separate precision, recall, or alignment-error figures for the heuristic line-grouping and n-gram stages on held-out transcribed tablets. The heuristics serve as post-processing to connect detections to textual structure; their effect is shown only through the end-to-end corpus-scale output rather than isolated quantitative evaluation. We will revise the abstract to state explicitly that the reported COCO gains pertain to the detection stage and that the bridging heuristics are not separately quantified on held-out data. This is a limitation of the current work. revision: partial
-
Referee: [Abstract] Abstract: the inference results (87,668 fragments, 2.9 million detections) are stated at high level, yet the abstract itself flags remaining sensitivity to tablet damage and layout variability without reporting any quantitative evaluation of the heuristics under those conditions.
Authors: The exact inference figures (87,668 fragments, ~2.9 million detections) are already stated in the abstract; we will ensure they remain prominent. The abstract already notes sensitivity to damage and layout variability. Because no separate quantitative stress-test of the heuristics under those conditions was performed, we will revise the abstract to clarify that robustness claims are limited to the detection metrics and that the heuristics inherit the same sensitivities. This revision will be made. revision: yes
Circularity Check
No significant circularity: empirical detector application with external metrics
full rationale
The paper applies an off-the-shelf Deformable DETR object detector to a new cuneiform sign dataset under two class granularities, followed by heuristic post-processing (tablet-side extraction, line grouping, n-gram similarity). No equations, first-principles derivations, or parameter predictions are claimed; performance is reported via standard COCO-style metrics on held-out data. The integration heuristics are described qualitatively without reducing any quantitative result to a fitted input or self-citation chain. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A Deformable DETR model trained on annotated sign images can produce usable detections on unseen cuneiform tablet photographs.
- domain assumption Heuristic line grouping and n-gram textual similarity can bridge visual detections to textual structure without linguistic priors.
Reference graph
Works this paper leans on
-
[1]
Ahmed, K. K. (2012). Online sumarians cuneiform detection based on symbol structural vector algorithm. Journal of the College of Education for Women , 23(2)
2012
-
[2]
and Mara, H
Bogacz, B. and Mara, H. (2022). Digital assyriology---advances in visual cuneiform analysis. Journal on Computing and Cultural Heritage (JOCCH) , 15(2):1--22
2022
-
[3]
Borger, R. (1988). Assyrisch-babylonische Zeichenliste . Neukirchen-Vluyn, 4 edition
1988
-
[4]
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., and Zagoruyko, S. (2020). End-to-end object detection with transformers
2020
-
[5]
Chammas, E., Mokbel, C., and Likforman-Sulem, L. (2018). Handwriting recognition of historical documents with few labelled data. In 2018 13th IAPR International Workshop on Document Analysis Systems (DAS) , pages 43--48. IEEE
2018
-
[6]
Cobanoglu, Y., S\'aenz, L., Khait, I., and Jim\'enez, E. (2024). Sign detection for cuneiform tablets. it -- Information Technology , (65)
2024
-
[7]
M., and Ommer, B
Dencker, T., Klinkisch, P., Maul, S. M., and Ommer, B. (2020). Deep learning of cuneiform sign detection with weak supervision using transliteration alignment. Plos one , 15(12):e0243039
2020
-
[8]
Devlin, J., Chang, M.-W., Lee, K., and Toutanova, K. (2019). Bert: Pre-training of deep bidirectional transformers for language understanding
2019
-
[9]
The ``electronic babylonian library'' (ebl) platform
electronic Babylonian Library (eBL) (2026). The ``electronic babylonian library'' (ebl) platform. https://www.ebl.lmu.de/. Database platform, accessed 2026-05-20
2026
-
[10]
Ester, M., Kriegel, H.-P., Sander, J., and Xu, X. (1996). A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining (KDD) , pages 226--231. AAAI Press
1996
-
[11]
Garces Arias, E., Pai, V., Sch \"o ffel, M., Heumann, C., and A enmacher, M. (2023). Automatic transcription of handwritten old O ccitan language. In Bouamor, H., Pino, J., and Bali, K., editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages 15416--15439, Singapore. Association for Computational Linguistics
2023
-
[12]
S., Yochai, N., and Lalazar, R
Gordin, S., Alper, M., Romach, A., Santos, L. S., Yochai, N., and Lalazar, R. (2024). Cured: Deep learning optical character recognition for cuneiform text editions and legacy materials. In Proceedings of the 1st Workshop on Machine Learning for Ancient Languages (ML4AL 2024) , pages 130--140
2024
-
[13]
Kahle, P., Colutto, S., Hackl, G., and M\"uhlberger, G. (2017). Transkribus---a service platform for transcription, recognition and retrieval of historical documents. In 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR) , volume 04, pages 19--24
2017
-
[14]
o ffel, M., H \
Koch, P., Nu \ n ez, G. V., Garces Arias, E., Heumann, C., Sch \"o ffel, M., H \"a berlin, A., and Assenmacher, M. (2023). A tailored handwritten-text-recognition system for medieval L atin. In Anderson, A., Gordin, S., Li, B., Liu, Y., and Passarotti, M. C., editors, Proceedings of the Ancient Language Processing Workshop , pages 103--110, Varna, Bulgari...
2023
-
[15]
al\"a, A., Gori, F., H\
Lewenstein, O., L\'opez, D., Dankwardt, C., Alrawi, M. F., Grill, L., Mak, B., Set\"al\"a, A., Gori, F., H\"atinen, A., Rauchhaus, F., F\"oldi, Z., and Jim\'enez, E. (2026). A large-scale dataset of annotated cuneiform sign images for digital palaeography. Journal of Open Humanities Data
2026
-
[16]
Li, M., Lv, T., Chen, J., Cui, L., Lu, Y., Florencio, D., Zhang, C., Li, Z., and Wei, F. (2022). Trocr: Transformer-based optical character recognition with pre-trained models
2022
-
[17]
Lin, T.-Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Doll \'a r, P., and Zitnick, C. L. (2014). Microsoft coco: Common objects in context. In Fleet, D., Pajdla, T., Schiele, B., and Tuytelaars, T., editors, Computer Vision -- ECCV 2014 , pages 740--755, Cham. Springer International Publishing
2014
-
[18]
Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.-Y., and Berg, A. C. (2016). Ssd: Single shot multibox detector. In European conference on computer vision , pages 21--37. Springer
2016
-
[19]
and Jin, L
Liu, Y. and Jin, L. (2017). Deep matching prior network: Toward tighter multi-oriented text detection. In Proceedings of the IEEE conference on computer vision and pattern recognition , pages 1962--1969
2017
-
[20]
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., and Guo, B. (2021). Swin transformer: Hierarchical vision transformer using shifted windows
2021
-
[21]
Mikulinsky, R., Alper, M., Gordin, S., Jim \'e nez, E., Cohen, Y., and Averbuch-Elor, H. (2025). Protosnap: Prototype alignment for cuneiform signs. In Proceedings of the International Conference on Learning Representations (ICLR)
2025
-
[22]
Pavlopoulos, J., Kougia, V., Garces Arias, E., Platanou, P., Shabalin, S., Liagkou, K., Papadatos, E., Essler, H., Camps, J.-B., and Fischer, F. (2024). Challenging error correction in recognised byzantine G reek. In Pavlopoulos, J., Sommerschield, T., Assael, Y., Gordin, S., Cho, K., Passarotti, M., Sprugnoli, R., Liu, Y., Li, B., and Anderson, A., edito...
2024
-
[23]
Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., and Sutskever, I. (2019). Language models are unsupervised multitask learners
2019
-
[24]
Reade, J. E. (2017). The manufacture, evaluation and conservation of clay tablets inscribed in cuneiform: Traditional problems and solutions. Iraq , 79:163--202
2017
-
[25]
A., Jasim, A
Saeed, E. A., Jasim, A. D., and Malik, M. A. A. (2024). Create distinctive databases of ancient languages and using a computer vision model to accurately recognise and classify them. Data in Brief , 56:110809
2024
-
[26]
G., and Zotter, C
Sarawgi, A., Arias, E. G., and Zotter, C. (2025). Digitising nepal's written heritage: A comprehensive htr pipeline for old nepali manuscripts
2025
-
[27]
Simonjetz, F., Laasonen, J., Cobanoglu, Y., Fraser, A., and Jim\'enez, E. (2024). Reconstruction of cuneiform literary texts as text matching
2024
-
[28]
Streck, M. P. (2010). Gro es fach altorientalistik: Der umfang des keilschriftlichen textkorpus. Mitteilungen der Deutschen Orient-Gesellschaft , (142):35--58
2010
-
[29]
Wang, K., Babenko, B., and Belongie, S. (2011). End-to-end scene text recognition. In 2011 International conference on computer vision , pages 1457--1464. IEEE
2011
-
[30]
J., Coates, A., and Ng, A
Wang, T., Wu, D. J., Coates, A., and Ng, A. Y. (2012). End-to-end text recognition with convolutional neural networks. In Proceedings of the 21st international conference on pattern recognition (ICPR2012) , pages 3304--3308. IEEE
2012
-
[31]
Wigington, C., Tensmeyer, C., Davis, B., Barrett, W., Price, B., and Cohen, S. (2018). Start, follow, read: End-to-end full-page handwriting recognition. In Proceedings of the European conference on computer vision (ECCV) , pages 367--383
2018
-
[32]
C., Su, G., Schloen, S
Williams, E. C., Su, G., Schloen, S. R., Prosser, M., Paulus, S., and Krishnan, S. (2025). Deepscribe: localisation and classification of elamite cuneiform signs via deep learning. ACM Journal on Computing and Cultural Heritage , 18(2):1--32
2025
-
[33]
Yesiltepe, B., Asuroglu, T., and Aktas, A. Z. (2019). Computerised H ittite C uneiform S ign R ecognition and K nowledge- B ased S ystem A pplication examples. European Scientific Journal , 15(33):32--53
2019
-
[34]
Zhou, X., Yao, C., Wen, H., Wang, Y., Zhou, S., He, W., and Liang, J. (2017). East: an efficient and accurate scene text detector. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition , pages 5551--5560
2017
-
[35]
Zhu, X., Su, W., Lu, L., Li, B., Wang, X., and Dai, J. (2021a). Deformable detr: Deformable transformers for end-to-end object detection
-
[36]
Zhu, Y., Chen, J., Liang, L., Kuang, Z., Jin, L., and Zhang, W. (2021b). Fourier contour embedding for arbitrary-shaped text detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 3123--3131
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.