Supersede: Diagnosing and Training the Memory-Update Gap in LLM Agents
Pith reviewed 2026-06-29 02:08 UTC · model grok-4.3
The pith
LLM agents fail to maintain current facts in long conversations even with stronger models or more memory, but GRPO fine-tuning on Supersede raises held-out accuracy from 9% to 16.7%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The supersession gap is a distinct unsolved failure in LLM agents that requires using the current value of a fact and discarding superseded values; this bottleneck is not closed by stronger models or proportionally larger memory but can be narrowed by GRPO fine-tuning on the Supersede environment, which nearly doubles held-out supersession accuracy on real conversations.
What carries the argument
The Supersede reinforcement-learning environment, which converts measurement of temporal fact currency into a reward signal by penalizing answers based on stale values and rewarding those based on current values.
If this is right
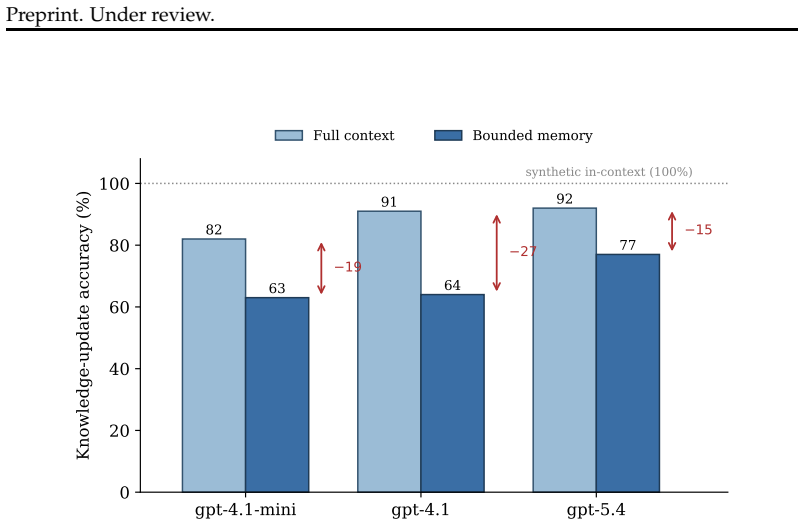
- Memory maintenance, not comprehension, is the core bottleneck because full-context accuracy saturates near 92% while bounded-memory accuracy falls to 77%.
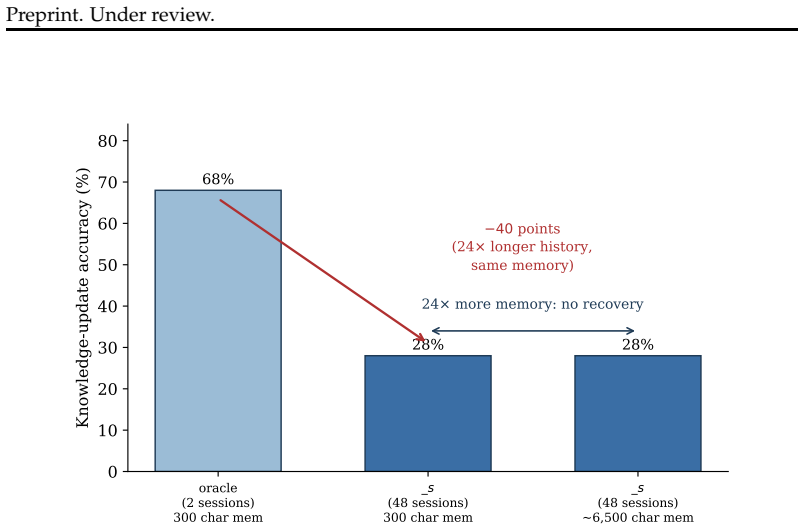
- The failure scales with conversation length rather than compression ratio, as accuracy drops from 68% to 28% when the conversation grows 24x with no recovery from extra memory.
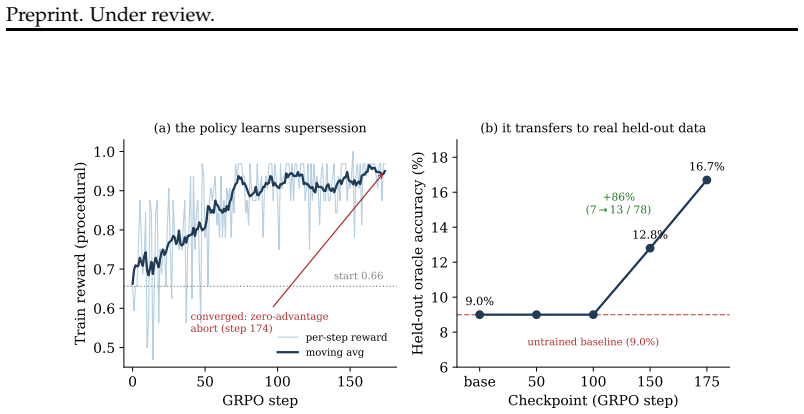
- GRPO fine-tuning on Supersede produces a learned policy that transfers to held-out real conversations, as evidenced by the monotonic improvement curve across checkpoints.
- The supersession gap is trainable rather than only measurable, closing part of the performance difference between full context and self-maintained memory.
Where Pith is reading between the lines
- Targeted RL on temporal currency might generalize to other agent failures involving changing user state or plans.
- Combining Supersede-style rewards with existing memory architectures could produce agents that handle longer sessions without full context.
- Real-world deployments of personal assistants may require explicit supersession training to avoid errors on outdated information such as addresses or prices.
Load-bearing premise
The knowledge-update subset of LongMemEval and the Supersede environment accurately isolate and measure the supersession ability without confounding factors from the specific data or reward design.
What would settle it
An experiment showing that GRPO-trained agents achieve no accuracy gain over baseline on a fresh set of conversations containing updated facts while the monotonic checkpoint curve disappears.
Figures

read the original abstract
Large language model (LLM) agents operate over long, multi-session interactions in which facts change: a user moves, a price updates, a plan is revised. Acting correctly requires using the current value of a fact and discarding values that have been superseded. We isolate this ability on real conversational data and show that it is a distinct, unsolved failure. On the knowledge-update subset of LongMemEval, replacing an agent's full context with a bounded, self-maintained memory drops accuracy from 92% to 77% even on a frontier model (gpt-5.4), a gap that is statistically significant (paired McNemar p<0.005) and persists across model scale while full-context accuracy saturates near 92%. The bottleneck is therefore memory maintenance, not comprehension, and is not closed by a stronger model. We then ask whether this is merely an undersized memory, and find it is not: as the conversation grows 24x, accuracy falls further (from 68% to 28%), and granting the agent proportionally more memory yields no detectable recovery (28% to 28%, n=25). The failure scales with the length of the conversation, not the compression ratio. We release Supersede, an open reinforcement-learning environment (on the verifiers / prime-rl stack) that turns this measurement into a training signal: agents are rewarded for answering from the current value and penalized for stale ones. Finally, we close the loop and show the gap is trainable: GRPO fine-tuning a small open model (Qwen2.5-3B) on this environment nearly doubles its held-out supersession accuracy on real, unseen conversations (9.0% to 16.7%, a single run), along a monotonic checkpoint curve indicating the learned policy, not the harness, carries the gain. To our knowledge this is the first trainable environment whose reward targets temporal fact-currency, and the first evidence the supersession gap can be trained down, not only measured.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that LLM agents suffer from a distinct 'supersession gap' in which they fail to discard superseded facts and use current values during long multi-session interactions. On the knowledge-update subset of LongMemEval, bounded self-maintained memory drops accuracy from 92% to 77% even for gpt-5.4 (paired McNemar p<0.005), the gap persists across model scales while full-context performance saturates, and accuracy falls from 68% to 28% as conversations grow 24x with no recovery from proportionally larger memory (n=25). The authors introduce the open Supersede RL environment and show that GRPO fine-tuning of Qwen2.5-3B nearly doubles held-out supersession accuracy from 9.0% to 16.7% along a monotonic checkpoint curve.
Significance. If the central claims hold after additional validation, the work identifies a practically important limitation for LLM agents in dynamic real-world settings and supplies the first evidence that the supersession gap is trainable rather than purely architectural. The release of the Supersede environment on the verifiers/prime-rl stack is a concrete, reusable contribution that could support further research on temporal fact maintenance.
major comments (3)
- [Abstract] Abstract: the claim that the supersession gap is isolated and distinct rests on the knowledge-update subset of LongMemEval, yet no filtering criteria, selection procedure, or fraction of explicit supersession cases versus other memory failures are supplied; without these details it is impossible to rule out confounding factors in the data harness.
- [Abstract] Abstract: the memory-size ablation uses n=25 and the GRPO training result is reported from a single run; these sample sizes are insufficient to support the statistical-significance and trainability conclusions at the level required for the central claim.
- [Abstract] Abstract: the Supersede reward is described only as 'rewarded for answering from the current value and penalized for stale ones'; the absence of the precise reward function, verifier implementation, and any analysis of potential lexical or length-based cues prevents assessment of whether the 9.0%→16.7% lift reflects policy learning or harness artifacts.
minor comments (2)
- [Abstract] The model identifier 'gpt-5.4' appears without clarification of whether it is a real frontier model, a placeholder, or a specific variant.
- [Abstract] The abstract would be clearer if it defined 'supersession gap' and 'temporal fact-currency' on first use rather than relying on context.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the supersession gap is isolated and distinct rests on the knowledge-update subset of LongMemEval, yet no filtering criteria, selection procedure, or fraction of explicit supersession cases versus other memory failures are supplied; without these details it is impossible to rule out confounding factors in the data harness.
Authors: We agree that the abstract does not supply these details. We will revise the abstract to include a summary of the filtering criteria, selection procedure, and fraction of explicit supersession cases. revision: yes
-
Referee: [Abstract] Abstract: the memory-size ablation uses n=25 and the GRPO training result is reported from a single run; these sample sizes are insufficient to support the statistical-significance and trainability conclusions at the level required for the central claim.
Authors: We acknowledge the limited sample sizes. The n=25 reflects the available long conversations, and the GRPO result is from one run. We will add explicit discussion of these limitations in the revision while noting the supporting monotonic checkpoint curve. revision: partial
-
Referee: [Abstract] Abstract: the Supersede reward is described only as 'rewarded for answering from the current value and penalized for stale ones'; the absence of the precise reward function, verifier implementation, and any analysis of potential lexical or length-based cues prevents assessment of whether the 9.0%→16.7% lift reflects policy learning or harness artifacts.
Authors: The precise reward function and verifier are in the released Supersede code. We will add the exact reward formulation to the methods section and include analysis ruling out lexical or length-based cues. revision: yes
Circularity Check
No significant circularity; empirical claims rest on held-out measurements and external reward.
full rationale
The paper's core claims rest on direct empirical measurements (accuracy drops on LongMemEval knowledge-update subset, memory-size ablation with n=25, and GRPO training lift from 9.0% to 16.7% on held-out real conversations) rather than any derivation that reduces to its own inputs. The Supersede environment defines reward externally as answering from current value vs. stale ones; evaluation uses unseen conversational data distinct from training. No self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations appear in the reported chain. The result is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The LongMemEval knowledge-update subset measures supersession ability without significant confounds from model comprehension or data artifacts.
Reference graph
Works this paper leans on
-
[1]
2025 , note =
Wu, Di and Wang, Hongwei and Yu, Wenhao and Zhang, Yuwei and Chang, Kai-Wei and Yu, Dong , booktitle =. 2025 , note =
2025
-
[2]
Evaluating Very Long-Term Conversational Memory of
Maharana, Adyasha and Lee, Dong-Ho and Tulyakov, Sergey and Bansal, Mohit and Barbieri, Francesco and Fang, Yuwei , booktitle =. Evaluating Very Long-Term Conversational Memory of. 2024 , note =
2024
-
[3]
He, Zexue and Wang, Yu and Zhi, Churan and Hu, Yuanzhe and Chen, Tzu-Ping and Yin, Lang and Chen, Ze and Wu, Tong Arthur and Ouyang, Siru and Wang, Zihan and Pei, Jiaxin and McAuley, Julian and Choi, Yejin and Pentland, Alex , journal =
-
[5]
Evaluating Memory in
Hu, Yuanzhe and Wang, Yu and McAuley, Julian , journal =. Evaluating Memory in
-
[6]
Yu, Hongli and Chen, Tinghong and Feng, Jiangtao and Chen, Jiangjie and Dai, Weinan and Yu, Qiying and Zhang, Ya-Qin and Ma, Wei-Ying and Liu, Jingjing and Wang, Mingxuan and Zhou, Hao , journal =
-
[7]
2026 , note =
Chen, Guanzheng and Shieh, Michael Qizhe and Bing, Lidong , journal =. 2026 , note =
2026
-
[8]
Chhikara, Prateek and Khant, Dev and Aryan, Saket and Singh, Taranjeet and Yadav, Deshraj , journal =
-
[9]
2025 , howpublished =
Environments Hub: A Community Hub To Scale. 2025 , howpublished =
2025
-
[10]
2026 , howpublished =
The Open Source Community is Backing. 2026 , howpublished =
2026
-
[11]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Bi, Xiao and Zhang, Haowei and Zhang, Mingchuan and Li, Y. K. and Wu, Y. and Guo, Daya , journal =. 2024 , note =
2024
-
[13]
and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =. 2022 , note =
2022
-
[14]
2026 , howpublished =
Dreaming: Better Memory for a More Helpful. 2026 , howpublished =
2026
-
[17]
2026 , howpublished =
Using. 2026 , howpublished =
2026
-
[18]
2026 , howpublished =
Personalization and Memory in. 2026 , howpublished =
2026
-
[19]
2025 , note =
Tan, Haoran and Zhang, Zeyu and Ma, Chen and Chen, Xu and Dai, Quanyu and Dong, Zhenhua , booktitle =. 2025 , note =
2025
-
[20]
and Jiang, Yuxin and Wong, Kam-Fai , journal =
Du, Yiming and Wang, Baojun and Xiang, Yifan and Wang, Zhaowei and Huang, Wenyu and Xue, Boyang and Liang, Bin and Zeng, Xingshan and Mi, Fei and Bai, Haoli and Shang, Lifeng and Pan, Jeff Z. and Jiang, Yuxin and Wong, Kam-Fai , journal =
-
[21]
Li, Ruoran and Zhang, Xinghua and Yu, Haiyang and Duan, Shitong and Li, Xiang and Xiang, Wenxin and Liao, Chonghua and Guo, Xudong and Li, Yongbin and Suo, Jinli , journal =
-
[22]
Using Claude 's chat search and memory to build on previous context
Anthropic . Using Claude 's chat search and memory to build on previous context. https://support.anthropic.com/en/articles/11817273, 2026
-
[23]
LongRLVR : Long-context reinforcement learning requires verifiable context rewards
Guanzheng Chen, Michael Qizhe Shieh, and Lidong Bing. LongRLVR : Long-context reinforcement learning requires verifiable context rewards. arXiv preprint arXiv:2603.02146, 2026. ICLR 2026
-
[24]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0 : Building production-ready AI agents with scalable long-term memory. arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Pan, Yuxin Jiang, and Kam-Fai Wong
Yiming Du, Baojun Wang, Yifan Xiang, Zhaowei Wang, Wenyu Huang, Boyang Xue, Bin Liang, Xingshan Zeng, Fei Mi, Haoli Bai, Lifeng Shang, Jeff Z. Pan, Yuxin Jiang, and Kam-Fai Wong. Memory-T1 : Reinforcement learning for temporal reasoning in multi-session agents. arXiv preprint arXiv:2512.20092, 2025
-
[26]
Personalization and memory in Gemini
Google . Personalization and memory in Gemini . https://gemini.google/release-notes/, 2026
2026
-
[27]
MemoryArena : Benchmarking agent memory in interdependent multi-session agentic tasks
Zexue He, Yu Wang, Churan Zhi, Yuanzhe Hu, Tzu-Ping Chen, Lang Yin, Ze Chen, Tong Arthur Wu, Siru Ouyang, Zihan Wang, Jiaxin Pei, Julian McAuley, Yejin Choi, and Alex Pentland. MemoryArena : Benchmarking agent memory in interdependent multi-session agentic tasks. arXiv preprint arXiv:2602.16313, 2026
-
[28]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA : Low-rank adaptation of large language models. In International Conference on Learning Representations (ICLR), 2022. arXiv:2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
Evaluating Memory in LLM Agents via Incremental Multi-Turn Interactions
Yuanzhe Hu, Yu Wang, and Julian McAuley. Evaluating memory in LLM agents via incremental multi-turn interactions. arXiv preprint arXiv:2507.05257, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
The open source community is backing OpenEnv for agentic RL
Hugging Face and Meta PyTorch and contributors . The open source community is backing OpenEnv for agentic RL . https://huggingface.co/blog/openenv-agentic-rl, 2026
2026
-
[31]
MemPO : Self-memory policy optimization for long-horizon agents, 2026
Ruoran Li, Xinghua Zhang, Haiyang Yu, Shitong Duan, Xiang Li, Wenxin Xiang, Chonghua Liao, Xudong Guo, Yongbin Li, and Jinli Suo. MemPO : Self-memory policy optimization for long-horizon agents, 2026
2026
-
[32]
Evaluating Very Long-Term Conversational Memory of LLM Agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of LLM agents. In Annual Meeting of the Association for Computational Linguistics (ACL), 2024. arXiv:2402.17753
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Dreaming: Better memory for a more helpful ChatGPT
OpenAI . Dreaming: Better memory for a more helpful ChatGPT . https://openai.com/index/chatgpt-memory-dreaming/, 2026. Self-reported internal evaluation; methodology and dataset not released
2026
-
[34]
Question answering under temporal conflict: Evaluating and organizing evolving knowledge with LLMs
Atahan \"O zer and C a g atay Y ld z. Question answering under temporal conflict: Evaluating and organizing evolving knowledge with LLMs . arXiv preprint arXiv:2506.07270, 2025
-
[35]
Environments hub: A community hub to scale RL to open AGI
Prime Intellect . Environments hub: A community hub to scale RL to open AGI . https://www.primeintellect.ai/blog/environments, 2025. Open registry and library (verifiers) for reinforcement-learning environments
2025
-
[36]
Qwen Team . Qwen2.5 technical report. arXiv preprint arXiv:2412.15115, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. DeepSeekMath : Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300, 2024. Introduces Group Relative Policy Optimization (GRPO)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
MemBench : Towards more comprehensive evaluation on the memory of LLM -based agents
Haoran Tan, Zeyu Zhang, Chen Ma, Xu Chen, Quanyu Dai, and Zhenhua Dong. MemBench : Towards more comprehensive evaluation on the memory of LLM -based agents. In Findings of the Association for Computational Linguistics: ACL 2025, 2025. arXiv:2506.21605
-
[39]
From Recall to Forgetting: Benchmarking Long-Term Memory for Personalized Agents
Md Nayem Uddin, Kumar Shubham, Eduardo Blanco, Chitta Baral, and Gengyu Wang. From recall to forgetting: Benchmarking long-term memory for personalized agents. arXiv preprint arXiv:2604.20006, 2026. Introduces the Memora benchmark and the Forgetting-Aware Memory Accuracy (FAMA) metric
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. LongMemEval : Benchmarking chat assistants on long-term interactive memory. In International Conference on Learning Representations (ICLR), 2025. arXiv:2410.10813
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
MemAgent: Reshaping Long-Context LLM with Multi-Conv RL-based Memory Agent
Hongli Yu, Tinghong Chen, Jiangtao Feng, Jiangjie Chen, Weinan Dai, Qiying Yu, Ya-Qin Zhang, Wei-Ying Ma, Jingjing Liu, Mingxuan Wang, and Hao Zhou. MemAgent : Reshaping long-context LLM with multi-conv RL -based memory agent. arXiv preprint arXiv:2507.02259, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Yi Yu, Liuyi Yao, Yuexiang Xie, Qingquan Tan, Jiaqi Feng, Yaliang Li, and Libing Wu. Agentic memory: Learning unified long-term and short-term memory management for large language model agents. arXiv preprint arXiv:2601.01885, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.