When Reasoning Hurts: Source-Aware Evaluation of Frontier LLMs for Clinical SOAP Note Generation
Pith reviewed 2026-06-30 12:14 UTC · model grok-4.3
The pith
Non-reasoning GPT-5.4 produces higher-quality SOAP notes than its reasoning-enabled version across three clinical datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
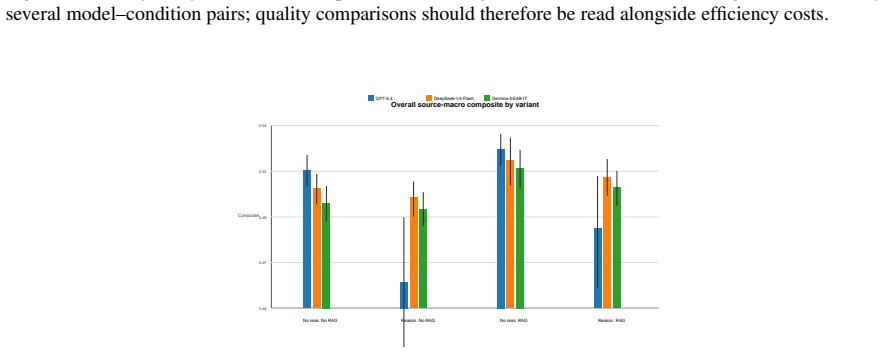
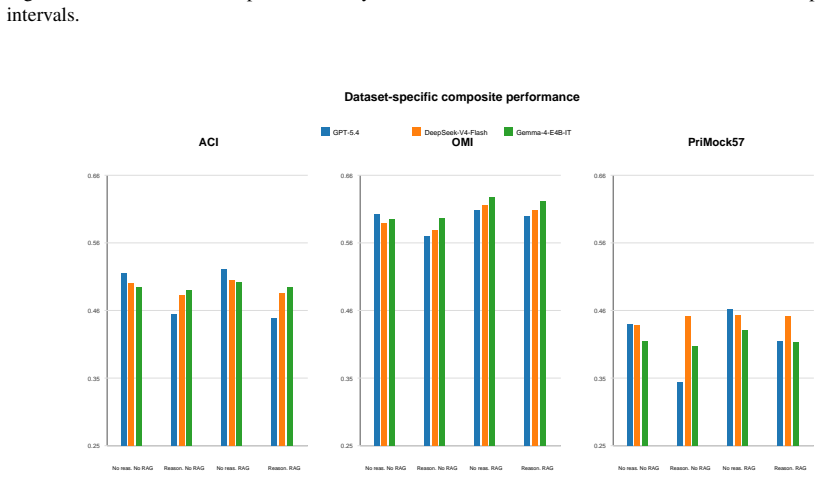
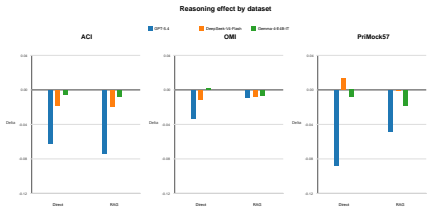
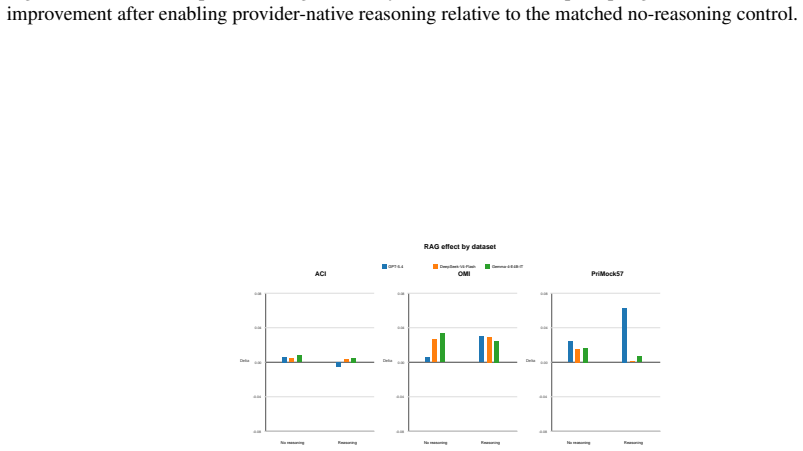
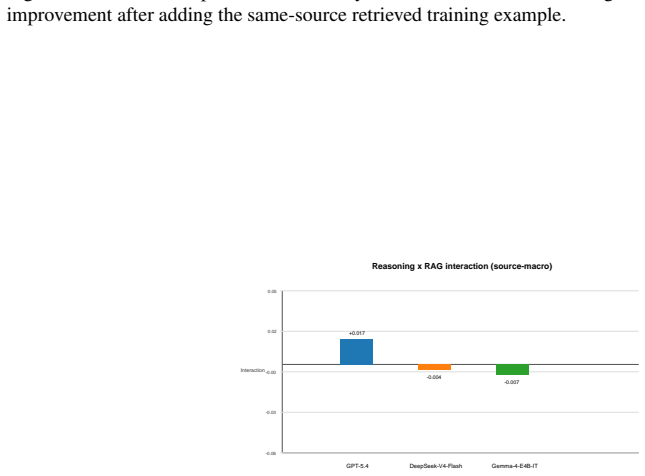
A non-reasoning GPT-5.4 configuration achieves the highest overall quality, while DeepSeek-V4-Flash performs best among reasoning-enabled configurations. Enabling reasoning significantly degrades GPT-5.4 performance across all three datasets, whereas same-source RAG yields smaller, model-dependent improvements.
What carries the argument
A source-aware 2x2 design that toggles provider-native reasoning and same-source RAG independently, scored by seven automatic metrics plus two reference-aware LLM judges on SOAP notes generated from dialogue.
If this is right
- Stronger reasoning capability should not be assumed to improve fidelity-sensitive SOAP note generation without dedicated task-specific evaluation.
- Model configuration choices, such as disabling reasoning, can outweigh general benchmark rankings for clinical documentation tasks.
- Same-source RAG produces only modest and model-dependent gains relative to the effect of toggling reasoning.
- Benchmark performance on medical reasoning does not reliably predict quality on structured clinical output.
Where Pith is reading between the lines
- Clinical tool developers may need separate optimization paths for reasoning versus documentation accuracy rather than relying on unified frontier models.
- Future medical LLM evaluations should add structured generation tasks to existing reasoning benchmarks to prevent overgeneralization of capabilities.
- The performance drop from reasoning could reflect added verbosity or formatting drift, suggesting targeted post-processing as a possible mitigation.
Load-bearing premise
Seven automatic metrics together with two reference-aware LLM judges serve as a reliable proxy for clinical fidelity, completeness, and overall quality of the generated SOAP notes.
What would settle it
Human clinician ratings on the same model outputs that rank reasoning-enabled versions higher in fidelity or completeness than the non-reasoning versions would contradict the main result.
Figures
read the original abstract
Reasoning-enabled LLMs perform strongly on medical reasoning benchmarks, but it remains unclear whether these gains transfer to structured clinical documentation; we investigate this question using SOAP note generation from clinical dialogue in a source-aware benchmark spanning OMI Health, ACI-Bench, and PriMock57. We evaluate GPT-5.4, DeepSeek-V4-Flash, and Gemma-4-E4B in a controlled 2x2 design that independently toggles provider-native reasoning and same-source retrieval-augmented generation (RAG). Outputs are assessed using seven automatic metrics alongside two reference-aware LLM judges. Both evaluation approaches agree that a non-reasoning GPT-5.4 configuration achieves the highest overall quality, while DeepSeek-V4-Flash performs best among reasoning-enabled configurations. Enabling reasoning significantly degrades GPT-5.4 performance across all three datasets, whereas same-source RAG yields smaller, model-dependent improvements. Overall, the findings indicate that stronger reasoning capability should not be assumed to improve fidelity-sensitive SOAP note generation without dedicated, task-specific evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates three frontier LLMs (GPT-5.4, DeepSeek-V4-Flash, Gemma-4-E4B) on SOAP note generation from clinical dialogues across OMI Health, ACI-Bench, and PriMock57 datasets. In a controlled 2x2 design toggling provider-native reasoning and same-source RAG, it reports that non-reasoning GPT-5.4 yields the highest overall quality per seven automatic metrics and two reference-aware LLM judges, reasoning degrades GPT-5.4 performance across datasets, DeepSeek-V4-Flash leads among reasoning models, and RAG effects are smaller and model-dependent. The abstract concludes that reasoning gains do not transfer to fidelity-sensitive clinical documentation without task-specific evaluation.
Significance. If the chosen proxies reliably track clinical fidelity, the controlled multi-model, multi-dataset comparison would indicate that reasoning can actively harm structured output quality in clinical settings, with direct implications for LLM deployment in medical documentation workflows. The source-aware benchmark and explicit 2x2 ablation are strengths that allow clear isolation of reasoning versus retrieval effects.
major comments (2)
- [Abstract and evaluation approach paragraph] Abstract and evaluation approach paragraph: the headline claim that reasoning 'significantly degrades' GPT-5.4 performance rests on agreement between automatic metrics and LLM judges, yet no statistical tests, confidence intervals, or error bars are reported to support the significance assertion or the cross-dataset consistency.
- [Evaluation approach paragraph] Evaluation approach paragraph: the central finding that non-reasoning configurations outperform reasoning ones depends on the assumption that the seven automatic metrics plus two reference-aware LLM judges are valid proxies for clinical fidelity, completeness, and quality; no correlation with expert clinician ratings or analysis of clinically critical errors (e.g., omitted contraindications or medication reconciliation failures) is provided to ground this assumption.
minor comments (1)
- [Abstract] The three datasets are introduced without brief characterizations or citations in the abstract; adding one-sentence descriptions would improve accessibility for readers outside clinical NLP.
Simulated Author's Rebuttal
We thank the referee for highlighting issues with statistical support and proxy validation. We address each comment below, indicating planned changes to the manuscript.
read point-by-point responses
-
Referee: Abstract and evaluation approach paragraph: the headline claim that reasoning 'significantly degrades' GPT-5.4 performance rests on agreement between automatic metrics and LLM judges, yet no statistical tests, confidence intervals, or error bars are reported to support the significance assertion or the cross-dataset consistency.
Authors: We agree that formal statistical support is needed to substantiate the 'significantly degrades' claim and cross-dataset consistency. In revision we will add paired statistical tests (t-tests or Wilcoxon signed-rank as appropriate), p-values, confidence intervals, and error bars for the primary metric differences, computed both per dataset and aggregated where possible. These will appear in the results section and be referenced in the abstract. revision: yes
-
Referee: Evaluation approach paragraph: the central finding that non-reasoning configurations outperform reasoning ones depends on the assumption that the seven automatic metrics plus two reference-aware LLM judges are valid proxies for clinical fidelity, completeness, and quality; no correlation with expert clinician ratings or analysis of clinically critical errors (e.g., omitted contraindications or medication reconciliation failures) is provided to ground this assumption.
Authors: This limitation is correctly identified. The study relies on established automatic metrics and LLM judges commonly used in clinical NLP benchmarks. We will add an expanded limitations subsection that (a) cites prior work examining correlations between these metrics and clinician judgments and (b) explicitly states that direct expert review of critical errors was not performed. A dedicated clinician validation study lies outside the scope of the current controlled benchmark paper. revision: partial
Circularity Check
No circularity: pure empirical model comparison on fixed benchmarks
full rationale
The paper reports a controlled 2x2 experimental evaluation of three LLMs under reasoning and RAG toggles, scored by seven automatic metrics plus two LLM judges across three fixed datasets. No derivations, equations, fitted parameters, or predictions appear; the central claims are direct statements of observed metric differences. No self-citations are invoked to justify uniqueness or forbid alternatives, and the evaluation pipeline is externally falsifiable on the same public benchmarks. The analysis is therefore self-contained with no load-bearing step that reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Automatic metrics and LLM-as-judge evaluations are valid proxies for clinical note quality
Reference graph
Works this paper leans on
-
[1]
InProceedings of the Clini- calNLP 2023 Workshop, pages 1–14
Overview of the MEDIQA-Chat 2023 shared tasks on the summarization & generation of doctor– patient conversations. InProceedings of the Clini- calNLP 2023 Workshop, pages 1–14. Association for Computational Linguistics. Simon Brake and Timothy Schaaf
2023
-
[2]
HuatuoGPT-o1, Towards Medical Complex Reasoning with LLMs
HuatuoGPT-o1: Towards medical complex reasoning with LLMs.arXiv preprint arXiv:2412.18925. Dasol Choi, Junhyuk Seo, Won Cul Cha, Minha Kim, Sejin Heo, Hansol Chang, and Taerim Kim
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
arXiv preprint arXiv:2507.06715
CLI-RAG: A retrieval-augmented framework for clinically struc- tured and context aware text generation with llms. arXiv preprint arXiv:2507.06715. Chin-Yew Lin
-
[4]
InProceedings of the 2024 IEEE International Conference on Big Data, pages 5050–5059
Clinicsum: Utilizing lan- guage models for generating clinical summaries from patient-doctor conversations. InProceedings of the 2024 IEEE International Conference on Big Data, pages 5050–5059. Omi Health
2024
-
[5]
Case-specific rubrics for clin- ical AI evaluation: Methodology, validation, and LLM–clinician agreement across 823 encounters. arXiv preprint arXiv:2604.24710. Junda Wang, Zonghai Yao, Zhichao Yang, Huixue Zhou, Rumeng Li, Xun Wang, Yucheng Xu, and Hong Yu
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
InFindings of the Association for Computational Lin- guistics: ACL 2024, pages 15183–15201, Bangkok, Thailand
NoteChat: A dataset of synthetic patient- physician conversations conditioned on clinical notes. InFindings of the Association for Computational Lin- guistics: ACL 2024, pages 15183–15201, Bangkok, Thailand. Association for Computational Linguistics. Rui Wang et al
2024
-
[7]
Why chain of thought fails in clinical text understanding.arXiv preprint arXiv:2509.21933. 6 Yunfei Xie et al
-
[8]
Guangzhi Xiong, Qiao Jin, Zhiyong Lu, and Aidong Zhang
A preliminary study of o1 in medicine: Are we closer to an AI doctor?arXiv preprint arXiv:2409.15277. Guangzhi Xiong, Qiao Jin, Zhiyong Lu, and Aidong Zhang
-
[9]
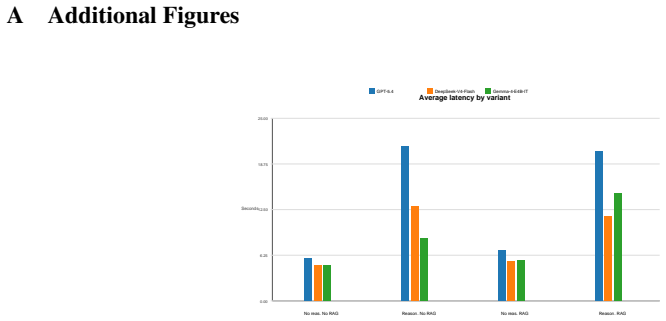
BERTScore: Evaluating text generation with BERT. InInterna- tional Conference on Learning Representations. 7 A Additional Figures Average latency by variant 0.00 6.25 12.50 18.75 25.00 Seconds No reas. No RAG Reason. No RAG No reas. RAG Reason. RAG GPT-5.4 DeepSeek-V4-Flash Gemma-4-E4B-IT Figure 1: Latency analysis for the saved provider reasoning run. Pr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.