Handoff Debt: The Rediscovery Cost When Coding Agents Take Over Interrupted Tasks
Pith reviewed 2026-06-28 14:07 UTC · model grok-4.3
The pith
Context from prior coding agents reduces successor effort by 20 to 63 percent in interrupted tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
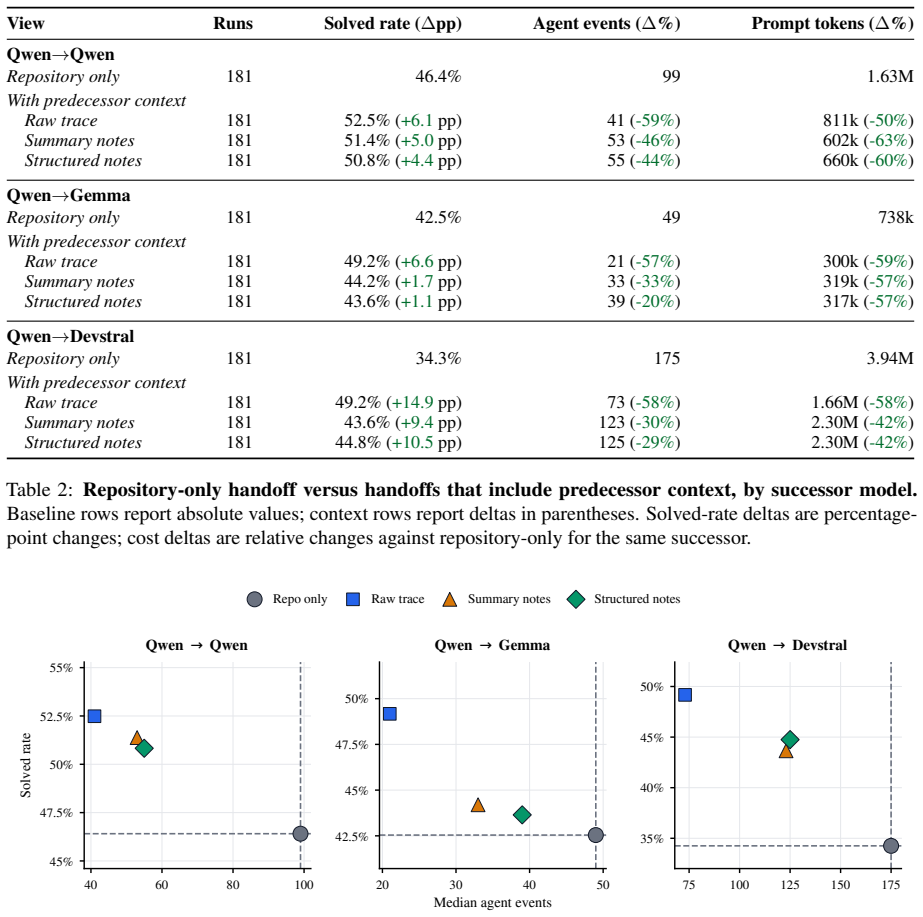
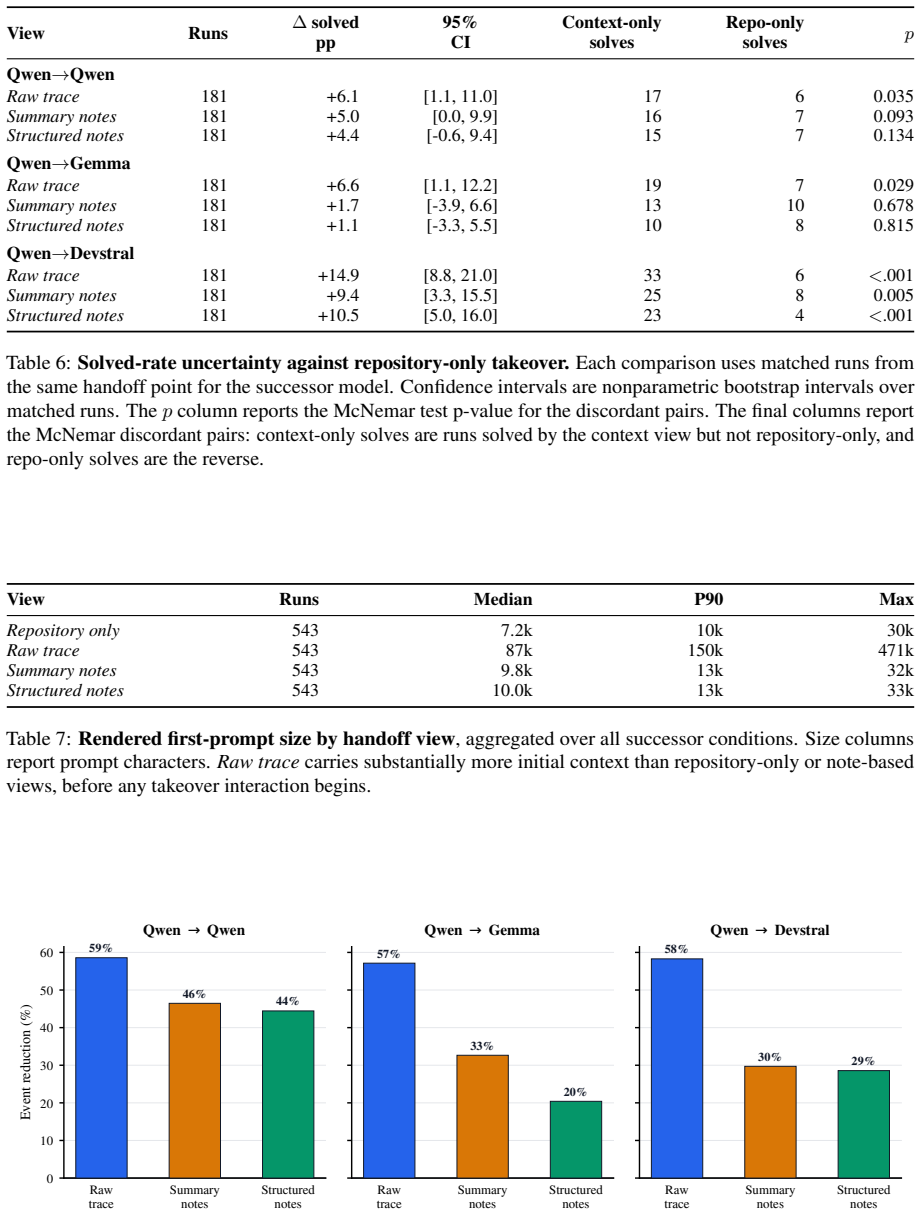
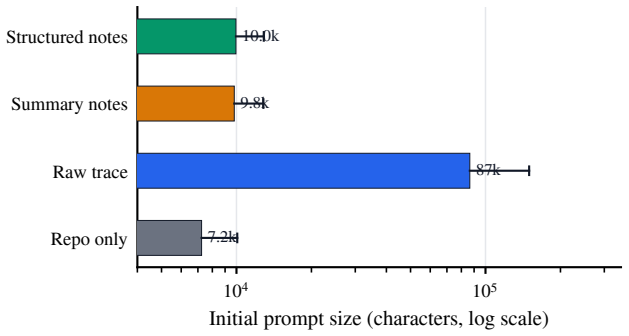
Across three successor models, context-bearing handoffs reduce median agent events by 20--59% and cumulative prompt tokens by 42--63% relative to repository-only takeover. Solved-rate effects are smaller and model-dependent, but efficiency gains are consistent.
What carries the argument
The takeover protocol that interrupts a coding agent at deterministic handoff points, freezes the repository, and measures successor performance under four handoff views (repository state only, raw trace, summary notes, structured notes).
If this is right
- Efficiency gains from context-bearing handoffs hold across different successor models.
- Solved-rate improvements depend on the specific model receiving the handoff.
- Benchmarks should report resumption cost in addition to whether a task is solved.
- Handoff debt becomes a measurable dimension of multi-agent coding performance.
Where Pith is reading between the lines
- Teams using multiple coding agents might reduce total token spend by adopting structured note handoffs as standard practice.
- The protocol could be extended to test handoffs between human engineers and agents or between agents with non-deterministic interruption points.
- If handoff debt scales with task complexity, longer-running projects would see larger cumulative savings from better context transfer.
Load-bearing premise
The four handoff views and the deterministic interruption points chosen are representative of the information and interruption patterns in actual multi-agent or human-AI software workflows.
What would settle it
A replication on new tasks or models that finds no reduction in agent events or prompt tokens when richer handoff context is supplied would falsify the efficiency claim.
Figures

read the original abstract
Coding-agent benchmarks evaluate whether a single uninterrupted agent can resolve a repository issue. Real software work is messier: tasks are interrupted, reassigned, reviewed, and resumed from partial states left by another agent or engineer. We study this missing dimension through \emph{handoff debt}: the rediscovery cost imposed when a predecessor's work is opaque or incomplete. Our takeover protocol interrupts a coding agent at deterministic handoff points, freezes the repository, and evaluates successor agents under four handoff views: repository state only, raw trace, summary notes, and structured notes. Across 75 source tasks, the protocol generates 181 handoff-point tasks and 724 takeover runs per successor model. Across three successor models, context-bearing handoffs reduce median agent events by 20--59\% and cumulative prompt tokens by 42--63\% relative to repository-only takeover. Solved-rate effects are smaller and model-dependent, but efficiency gains are consistent. These findings suggest that coding-agent evaluation should report not only whether a task is solved, but also how costly that work is for another agent to resume.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces 'handoff debt' as the rediscovery cost when coding agents resume interrupted tasks and presents an empirical takeover protocol study. Agents are interrupted at deterministic points across 75 source tasks (yielding 181 handoff-point tasks), with successors evaluated under four handoff views (repository state only, raw trace, summary notes, structured notes) in 724 runs per model. Context-bearing handoffs yield 20-59% reductions in median agent events and 42-63% in cumulative prompt tokens vs. repository-only; solved-rate effects are smaller and model-dependent. The work recommends that coding-agent benchmarks report resumption costs in addition to solve rates.
Significance. If the measured efficiency gains hold, the study identifies a practically relevant gap in current single-agent coding benchmarks by quantifying resumption costs in interrupted workflows. The scale (three successor models, 724 runs each) supplies concrete, reproducible quantitative support for the efficiency claims within the tested protocol. This could usefully inform future benchmark design, though the ad-hoc handoff views limit broader claims.
major comments (1)
- [Takeover Protocol (abstract and methods)] The central efficiency claims (20--59% median event reduction and 42--63% token reduction) are obtained under author-chosen deterministic interruption points and four fixed handoff views. No comparison or validation is described against the distribution of interruption stages or information needs that arise in actual multi-agent or human-AI software workflows (see protocol description in the abstract and methods). This assumption is load-bearing for the suggestion that benchmarks should routinely report resumption costs.
minor comments (1)
- [Abstract] The abstract states that solved-rate effects are 'smaller and model-dependent' without reporting the actual percentages or any statistical tests, which makes it difficult to evaluate the relative importance of efficiency vs. correctness outcomes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the positive assessment of the study's scale and potential utility for benchmark design. We address the major comment below.
read point-by-point responses
-
Referee: [Takeover Protocol (abstract and methods)] The central efficiency claims (20--59% median event reduction and 42--63% token reduction) are obtained under author-chosen deterministic interruption points and four fixed handoff views. No comparison or validation is described against the distribution of interruption stages or information needs that arise in actual multi-agent or human-AI software workflows (see protocol description in the abstract and methods). This assumption is load-bearing for the suggestion that benchmarks should routinely report resumption costs.
Authors: The takeover protocol is intentionally designed as a controlled empirical study using deterministic interruption points to ensure reproducibility and to isolate the impact of different handoff views. As described in the methods, these points are chosen to create a range of handoff scenarios across the 75 source tasks. We do not provide or claim a validation against the empirical distribution of real-world interruption stages or information needs in multi-agent or human-AI workflows, as that would require a separate observational study which is beyond the scope of this paper. The efficiency claims are presented as results under this specific protocol. The recommendation that benchmarks report resumption costs is based on the observation that, even under controlled conditions, context-bearing handoffs yield substantial efficiency gains; this suggests the dimension is worth measuring, without asserting that the exact percentages apply universally. We can add a sentence in the discussion section acknowledging this scope limitation if the editor deems it necessary. revision: partial
Circularity Check
No circularity: empirical measurement study with direct experimental results
full rationale
The paper defines a takeover protocol with four handoff views and deterministic interruption points, then reports measured reductions in agent events and tokens from 724 takeover runs across 181 handoff-point tasks. No equations, derivations, fitted parameters, or self-citation chains are present that reduce the reported percentages to quantities constructed from the same inputs. The central claims are direct empirical outputs from the protocol runs, with no load-bearing step that collapses by construction to a prior assumption or fit.
Axiom & Free-Parameter Ledger
invented entities (1)
-
handoff debt
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jimenez, Carlos E and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , booktitle=
-
[2]
Yang, John and Jimenez, Carlos E and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , journal=
-
[3]
Wang, Xingyao and Li, Boxuan and Song, Yufan and Xu, Frank F and Tang, Xiangru and Zhuge, Mingchen and Pan, Jiayi and Song, Yueqi and Li, Bowen and Singh, Jaskirat and others , booktitle=
-
[4]
Agentless: Demystifying
Xia, Chunqiu Steven and Deng, Yinlin and Dunn, Soren and Zhang, Lingming , journal =. Agentless: Demystifying. 2024 , url =
2024
-
[5]
and Burger, Doug and Wang, Chi , journal =
Wu, Qingyun and Bansal, Gagan and Zhang, Jieyu and Wu, Yiran and Li, Beibin and Zhu, Erkang and Jiang, Li and Zhang, Xiaoyun and Zhang, Shaokun and Liu, Jiale and Awadallah, Ahmed Hassan and White, Ryen W. and Burger, Doug and Wang, Chi , journal =. 2023 , url =
2023
-
[6]
and Lin, Kevin and Wooders, Sarah and Gonzalez, Joseph E
Packer, Charles and Fang, Vivian and Patil, Shishir G. and Lin, Kevin and Wooders, Sarah and Gonzalez, Joseph E. , journal =. 2023 , url =
2023
-
[7]
International Conference on Learning Representations , volume=
Efficient streaming language models with attention sinks , author=. International Conference on Learning Representations , volume=
-
[8]
and Yang, John and Ho, Leyton and Patwardhan, Tejal and Liu, Kevin and Madry, Aleksander , year =
Chowdhury, Neil and Aung, James and Shern, Chan Jun and Jaffe, Oliver and Sherburn, Dane and Starace, Giulio and Mays, Evan and Dias, Rachel and Aljubeh, Marwan and Glaese, Mia and Jimenez, Carlos E. and Yang, John and Ho, Leyton and Patwardhan, Tejal and Liu, Kevin and Madry, Aleksander , year =. Introducing
-
[9]
Liu, Xiao and Yu, Hao and Zhang, Hanchen and Xu, Yifan and Lei, Xuanyu and Lai, Hanyu and Gu, Yu and Ding, Hangliang and Men, Kaiwen and Yang, Kejuan and others , booktitle=
-
[10]
International Conference on Learning Representations , volume=
Mint: Evaluating llms in multi-turn interaction with tools and language feedback , author=. International Conference on Learning Representations , volume=
-
[11]
Zhou, Shuyan and Xu, Frank F and Zhu, Hao and Zhou, Xuhui and Lo, Robert and Sridhar, Abishek and Cheng, Xianyi and Ou, Tianyue and Bisk, Yonatan and Fried, Daniel and others , booktitle=
-
[12]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains , author =. arXiv preprint arXiv:2406.12045 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
2024 , howpublished =
2024
-
[14]
Longformer: The Long-Document Transformer
Longformer: The long-document transformer , author=. arXiv preprint arXiv:2004.05150 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[15]
Proceedings of the 17th Working Conference on Reverse Engineering , year =
On the Use of Automated Text Summarization Techniques for Summarizing Source Code , author =. Proceedings of the 17th Working Conference on Reverse Engineering , year =
-
[16]
Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics , year =
Summarizing Source Code using a Neural Attention Model , author =. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics , year =
-
[17]
Datamation , volume =
How Do Committees Invent? , author =. Datamation , volume =
-
[18]
Computer , volume =
No Silver Bullet: Essence and Accidents of Software Engineering , author =. Computer , volume =
-
[19]
IEEE Transactions on software engineering , volume=
An empirical study of speed and communication in globally distributed software development , author=. IEEE Transactions on software engineering , volume=. 2003 , publisher=
2003
-
[20]
2023 , url =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle =. 2023 , url =
2023
-
[21]
Advances in neural information processing systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in neural information processing systems , volume=
-
[22]
Qin, Yujia and Liang, Shihao and Ye, Yining and Zhu, Kunlun and Yan, Lan and Lu, Yaxi and Lin, Yankai and Cong, Xin and Tang, Xiangru and Qian, Bill and others , booktitle=
-
[23]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[24]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Voyager: An Open-Ended Embodied Agent with Large Language Models , author =. arXiv preprint arXiv:2305.16291 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
arXiv preprint arXiv:2602.05892 , year=
ContextBench: A Benchmark for Context Retrieval in Coding Agents , author=. arXiv preprint arXiv:2602.05892 , year=
-
[26]
Shi, Yu and Li, Hao and Adams, Bram and Hassan, Ahmed E , journal=
-
[27]
arXiv preprint arXiv:2510.03588 , year=
REFINE: Enhancing Program Repair Agents through Context-Aware Patch Refinement , author=. arXiv preprint arXiv:2510.03588 , year=
-
[28]
Runtime Execution Traces Guided Automated Program Repair with Multi-Agent Debate
Runtime Execution Traces Guided Automated Program Repair with Multi-Agent Debate , author=. arXiv preprint arXiv:2604.02647 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
arXiv preprint arXiv:2602.01465 , year=
Agyn: A Multi-Agent System for Team-Based Autonomous Software Engineering , author=. arXiv preprint arXiv:2602.01465 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.