Simulating Eating Disorder Patients with LLMs: Evaluating Psychological Persona Stability in Multi-Turn Conversations
Pith reviewed 2026-06-30 22:15 UTC · model grok-4.3
The pith
LLM eating disorder simulations overshoot true severity and miss moderate cases entirely.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
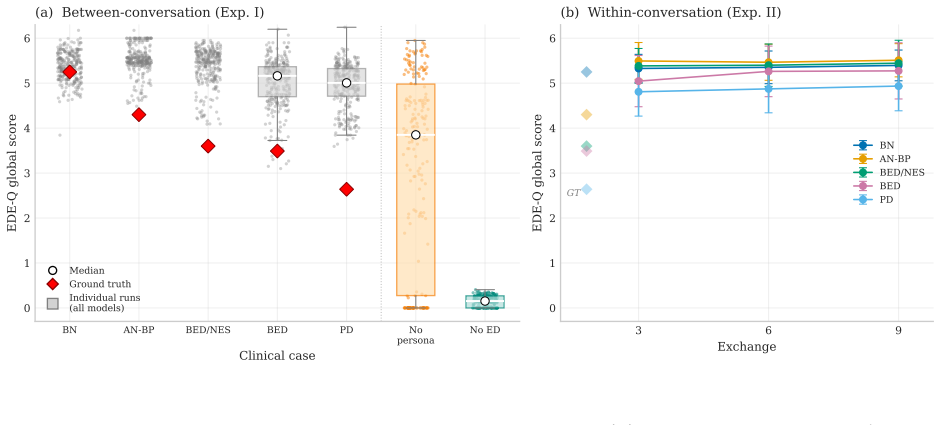
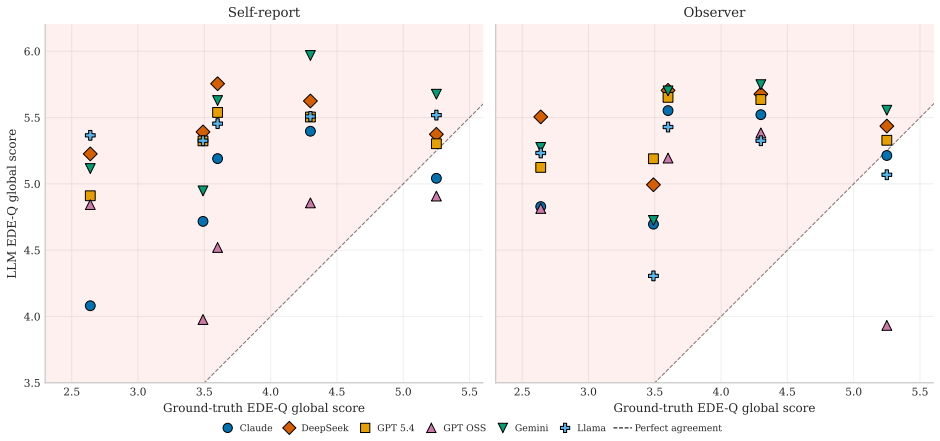
LLMs assigned eating disorder personas based on published case vignettes produce outputs with negligible variability across conversations. All tested models overshoot the ground-truth EDE-Q severity scores by 12-30% of the scale range. The models accurately differentiate cases along behavioral dimensions but uniformly maximize cognitive-affective dimensions at ceiling levels. This pattern persists even when additional conversational context is provided, which instead increases the degree of overshoot. The result is that LLMs can simulate severe eating pathology but cannot produce moderate clinical presentations, indicating a missing middle in their clinical representations.
What carries the argument
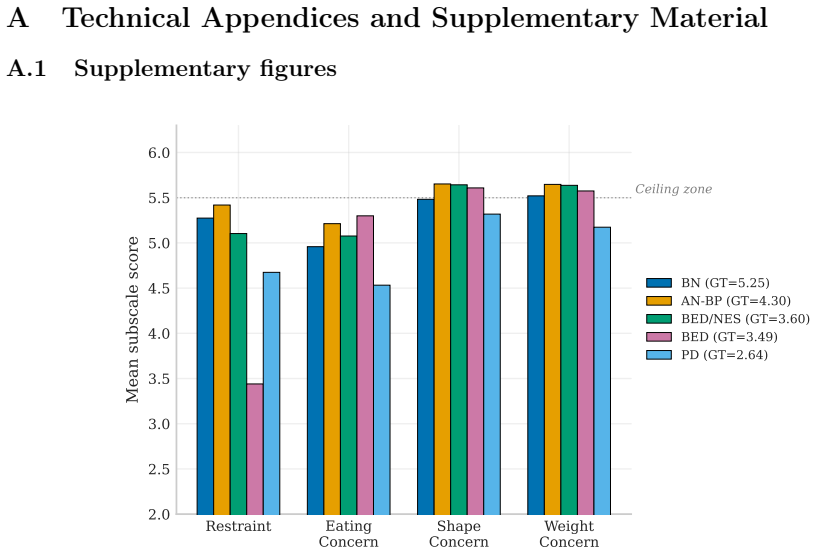
Selective stereotyping mechanism, in which behavioral items such as dietary restraint vary by case while cognitive-affective items such as body dissatisfaction are maximized at ceiling independent of vignette severity.
If this is right
- LLMs maintain high persona stability across multi-turn conversations without meaningful drift.
- Additional conversational context does not improve accuracy and instead compounds the severity overshoot.
- LLMs succeed at portraying severe eating pathology but cannot represent moderate clinical presentations.
- The missing middle limits use cases that require graduated symptom severity for training or research.
Where Pith is reading between the lines
- Ceiling effects on affective symptoms may appear in LLM simulations of other clinical conditions where emotional content dominates behavioral content.
- Fine-tuning or prompting strategies that penalize uniform maximization of cognitive items could reduce the observed bias.
- Deployments in clinical training would need explicit calibration checks for moderate-severity cases to avoid systematic distortion.
- Repeating the protocol with real patient self-report data rather than vignettes could test whether the overshoot is vignette-specific.
Load-bearing premise
The published case vignettes supply reliable ground-truth EDE-Q scores that can be directly compared with LLM-generated responses.
What would settle it
If LLM EDE-Q scores for the same vignettes aligned with the published ground truths within typical measurement error of roughly 0.3 points instead of overshooting by 0.7-1.8 points, the claim of systematic inaccuracy would be falsified.
Figures



read the original abstract
Large language model (LLM)-based simulations of clinical patients are increasingly used for research and training, yet their validity requires persona stability: coherent maintenance of an assigned psychological profile across and within conversations. We evaluate this prerequisite using eating disorder personas grounded in five published case vignettes, a dual-assessment framework (self-report + independent observer ratings), and validated psychometric instruments (EDE-Q) with known ground-truth scores. Across six LLMs and two experiments (between-conversation stability (Exp. I) and within-conversation stability (Exp. II)), we find that LLMs are paradoxically too stable and too inaccurate: variability is negligible, yet all models systematically overshoot ground-truth severity by 12-30% of the scale range (0.7-1.8 points on a 0-6 scale). The mechanism is selective stereotyping: models differentiate cases on behavioural items (dietary restraint) but maximise cognitive-affective items (body dissatisfaction, weight preoccupation) at ceiling regardless of case severity. Additional conversational context does not improve accuracy; it compounds the overshoot. LLMs can portray severe eating pathology but lack a representation of moderate clinical presentations, a "missing middle".
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates LLM-based simulation of eating disorder patients using five published case vignettes with assigned EDE-Q ground-truth scores. Across six LLMs and two experiments (between-conversation stability in Exp. I; within-conversation in Exp. II), it employs a dual-assessment framework (LLM self-report plus independent observer ratings on the EDE-Q) and reports negligible response variability yet systematic overshoot of ground-truth severity by 0.7-1.8 points (12-30% of scale range). The proposed mechanism is selective stereotyping, with differentiation on behavioral items (dietary restraint) but ceiling maximization on cognitive-affective items (body dissatisfaction, weight preoccupation) regardless of case severity; additional context worsens accuracy, implying LLMs can represent severe but not moderate presentations (the 'missing middle').
Significance. If the ground-truth comparisons and instrument transfer are valid, the findings would be significant for the expanding use of LLMs in clinical training and research, as they identify a systematic bias that restricts representation of the full severity spectrum. The structured design with multiple models, dual assessment, and validated instruments (EDE-Q) provides a replicable template for testing persona fidelity; the explicit reporting of overshoot magnitudes and subscale patterns strengthens falsifiability.
major comments (3)
- [Methods (Case Vignettes subsection)] Methods (Case Vignettes subsection): The overshoot claim (0.7-1.8 points) and 'missing middle' conclusion rest on the five vignettes supplying precise, validated EDE-Q global and subscale scores that are directly comparable to LLM outputs. The manuscript must detail the exact mapping procedure from narrative descriptions to 0-6 item scores, including any interpretive assumptions or independent clinical verification, because vignette-to-instrument translation is not automatic and directly determines whether the reported effect sizes are interpretable.
- [§3 (Dual-Assessment Framework) and Results (Selective Stereotyping)] §3 (Dual-Assessment Framework) and Results (Selective Stereotyping): The claim that models differentiate behavioral items but maximize cognitive-affective items at ceiling requires explicit reporting of per-subscale means, standard deviations, and statistical contrasts (e.g., restraint vs. shape concern differences) for each model and experiment. Without these, the mechanism cannot be distinguished from uniform severity inflation or instrument-specific response styles.
- [Exp. II (Within-conversation stability)] Exp. II (Within-conversation stability): The finding that additional conversational context compounds overshoot is load-bearing for the stability conclusion, yet the manuscript provides insufficient detail on prompt construction, context length, and controls for order effects. This leaves open whether the effect is due to persona drift or to how context is injected.
minor comments (2)
- [Abstract] Abstract: The range '12-30% of the scale range' should be accompanied by model-specific or subscale-specific percentages to allow precise evaluation of the effect size.
- [Figures] Figures (e.g., severity plots): Ensure variability measures (error bars or individual trajectory lines) are legible to visually support the 'negligible variability' claim across turns and models.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which highlight opportunities to strengthen the methodological transparency of our work on LLM-based eating disorder persona simulations. We address each major comment below and will incorporate revisions to enhance replicability.
read point-by-point responses
-
Referee: [Methods (Case Vignettes subsection)] Methods (Case Vignettes subsection): The overshoot claim (0.7-1.8 points) and 'missing middle' conclusion rest on the five vignettes supplying precise, validated EDE-Q global and subscale scores that are directly comparable to LLM outputs. The manuscript must detail the exact mapping procedure from narrative descriptions to 0-6 item scores, including any interpretive assumptions or independent clinical verification, because vignette-to-instrument translation is not automatic and directly determines whether the reported effect sizes are interpretable.
Authors: We agree that explicit documentation of the vignette-to-EDE-Q mapping is essential for interpretability of the effect sizes. The five case vignettes are drawn from published clinical case studies in which EDE-Q scores were originally assigned or derivable from the symptom descriptions. In the revised manuscript, we will add a dedicated subsection in Methods that details the item-by-item mapping procedure from narrative elements to 0-6 scores, including the interpretive assumptions applied (e.g., inferring severity levels from descriptions of dietary behaviors or body image concerns). We will also clarify that no new independent clinical verification was conducted by our team beyond reliance on the published sources, making the process fully transparent for readers. revision: yes
-
Referee: [§3 (Dual-Assessment Framework) and Results (Selective Stereotyping)] §3 (Dual-Assessment Framework) and Results (Selective Stereotyping): The claim that models differentiate behavioral items but maximize cognitive-affective items at ceiling requires explicit reporting of per-subscale means, standard deviations, and statistical contrasts (e.g., restraint vs. shape concern differences) for each model and experiment. Without these, the mechanism cannot be distinguished from uniform severity inflation or instrument-specific response styles.
Authors: We agree that per-subscale reporting is required to rigorously support the selective stereotyping mechanism over alternatives such as uniform inflation. The revised manuscript will include tables reporting mean EDE-Q subscale scores (Restraint, Eating Concern, Shape Concern, Weight Concern) and standard deviations for each of the six models in both experiments. We will additionally report statistical contrasts (e.g., paired t-tests or mixed ANOVA) between the behavioral Restraint subscale and the cognitive-affective Shape/Weight Concern subscales to demonstrate the differentiation pattern and rule out uniform response styles. revision: yes
-
Referee: [Exp. II (Within-conversation stability)] Exp. II (Within-conversation stability): The finding that additional conversational context compounds overshoot is load-bearing for the stability conclusion, yet the manuscript provides insufficient detail on prompt construction, context length, and controls for order effects. This leaves open whether the effect is due to persona drift or to how context is injected.
Authors: We acknowledge that greater detail on Experiment II is needed to isolate the source of the compounding overshoot. In the revised Methods, we will expand the description of prompt construction by providing the full templates used for context injection, report exact context lengths (both in number of turns and approximate token counts), and detail the controls for order effects, including any randomization or counterbalancing of context presentation across trials. These additions will allow readers to evaluate whether the observed effect stems from persona representation rather than prompt engineering artifacts. revision: yes
Circularity Check
No circularity: empirical reporting study with independent observations
full rationale
The paper is an empirical evaluation of LLM persona stability using published case vignettes as ground-truth, dual-assessment ratings on EDE-Q, and direct comparison of model outputs to those scores. No derivations, equations, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the provided text. Central claims rest on experimental observations (overshoot magnitudes, selective stereotyping) rather than any reduction to inputs by construction. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can be prompted to maintain assigned psychological personas based on published case vignettes
- domain assumption EDE-Q scores from the five published case vignettes constitute valid ground-truth for measuring simulation accuracy
Reference graph
Works this paper leans on
-
[1]
Consistently Simulating Human Personas with Multi-Turn Reinforcement Learning, October 2025
Marwa Abdulhai, Ryan Cheng, Donovan Clay, Tim Althoff, Sergey Levine, and Natasha Jaques. Consistently Simulating Human Personas with Multi-Turn Reinforcement Learning, October 2025
2025
-
[2]
Opler, Pamela Valera, and Eric Jarmon
Sebastian Acevedo, Esha Aneja, Douglas J. Opler, Pamela Valera, and Eric Jarmon. Evaluating the Efficacy of ChatGPT-3.5 Versus Human-Delivered Text-Based Cognitive-Behavioral Therapy: A Comparative Pilot Study.American Journal of Psychotherapy, 79(1):4–11, March 2026. ISSN 0002-9564, 2575-6559. doi: 10.1176/appi.psychotherapy.20240070
-
[3]
Victor Ajluni. Artificial intelligence in psychiatric education: Enhancing clinical competence through simulation.Industrial Psychiatry Journal, 34(1):11, January 2025. ISSN 0972-6748. doi: 10.4103/ipj.ipj_377_24
-
[4]
SaySelf: Teaching LLMs to express confidence with self-reflective rationales
Tilman Beck, Hendrik Schuff, Anne Lauscher, and Iryna Gurevych. Sensitivity, Performance, Robustness: Deconstructing the Effect of Sociodemographic Prompting. In Yvette Graham and Matthew Purver, editors,Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2589–2615, St....
-
[5]
Doll, Zafra Cooper, Marianne O’Connor, Robert L
Kristin Bohn, Helen A. Doll, Zafra Cooper, Marianne O’Connor, Robert L. Palmer, and Christo- pher G. Fairburn. The measurement of impairment due to eating disorder psychopathology. Behaviour Research and Therapy, 46(10):1105–1110, 2008
2008
-
[6]
The threat of analytic flexibility in using large language models to simulate human data, April 2026
Jamie Cummins. The threat of analytic flexibility in using large language models to simulate human data, April 2026
2026
-
[7]
Kerstin Denecke, Octavio Rivera-Romero, Guillermo López-Campos, Enrique Dorronzoro, and Elia Gabarron. Uncovering AI’s hidden risks: An empirical analysis of health-related AI incidents and their ethical implications.AI and Ethics, 6(2):169, February 2026. ISSN 2730-5961. doi: 10.1007/s43681-026-01012-7
-
[8]
F. Elif Ergüney-Okumuş. Integrating EMDR With Enhanced Cognitive Behavioral Therapy in the Treatment of Bulimia Nervosa: A Single Case Study.Journal of EMDR Practice and Research, 15(4):231–243, May 2023. doi: 10.1891/EMDR-D-21-00012
-
[9]
Fairburn and Sarah J
Christopher G. Fairburn and Sarah J. Beglin. Eating disorder examination questionnaire. In Cognitive Behavior Therapy and Eating Disorders, pages 309–313. Guilford Press, 2008
2008
-
[10]
Christopher G. Fairburn, Zafra Cooper, and Roz Shafran. Cognitive behaviour therapy for eating disorders: A “transdiagnostic” theory and treatment.Behaviour Research and Therapy, 41(5):509–528, 2003. doi: 10.1016/S0005-7967(02)00088-8
-
[12]
Garner, Marion P
David M. Garner, Marion P. Olmsted, Yvonne Bohr, and Paul E. Garfinkel. The eating attitudes test: Psychometric features and clinical correlates.Psychological Medicine, 12(4):871–878, 1982. 12
1982
-
[13]
Stable Personas: Dual-Assessment of Temporal Stability in LLM-Based Human Simulation, January 2026
Jana Gonnermann-Müller, Jennifer Haase, Nicolas Leins, Thomas Kosch, and Sebastian Pokutta. Stable Personas: Dual-Assessment of Temporal Stability in LLM-Based Human Simulation, January 2026
2026
-
[15]
Designing LLM-Agents with Personalities: A Psychometric Approach, October 2024
Muhua Huang, Xijuan Zhang, Christopher Soto, and James Evans. Designing LLM-Agents with Personalities: A Psychometric Approach, October 2024
2024
-
[16]
When AI takes the couch: Psychometric jailbreaks reveal internal conflict in frontier models, December 2025
Afshin Khadangi, Hanna Marxen, Amir Sartipi, Igor Tchappi, and Gilbert Fridgen. When AI takes the couch: Psychometric jailbreaks reveal internal conflict in frontier models, December 2025
2025
-
[17]
Quantifying AI Psychology: A Psychometrics Benchmark for Large Language Models, June 2024
Yuan Li, Yue Huang, Hongyi Wang, Xiangliang Zhang, James Zou, and Lichao Sun. Quantifying AI Psychology: A Psychometrics Benchmark for Large Language Models, June 2024
2024
-
[18]
TRUTH DECAY: Quantifying Multi-Turn Sycophancy in Language Models, February 2025
Joshua Liu, Aarav Jain, Soham Takuri, Srihan Vege, Aslihan Akalin, Kevin Zhu, Sean O’Brien, and Vasu Sharma. TRUTH DECAY: Quantifying Multi-Turn Sycophancy in Language Models, February 2025
2025
-
[19]
Daniel Cabrera Lozoya, Mike Conway, Edoardo Sebastiano De Duro, and Simon D’Alfonso. Leveraging Large Language Models for Simulated Psychotherapy Client Interactions: Develop- ment and Usability Study of Client101.JMIR Medical Education, 11(1):e68056, July 2025. doi: 10.2196/68056
-
[20]
Kristine H. Luce and Janis H. Crowther. The reliability of the Eating Disorder Examination— self-report questionnaire version (EDE-Q).International Journal of Eating Disorders, 25(3): 349–351, 1999. doi: 10.1002/(SICI)1098-108X(199904)25:3<349::AID-EAT15>3.0.CO;2-M
-
[21]
Pedro Henrique Luz de Araujo, Paul Röttger, Dirk Hovy, and Benjamin Roth. Principled Per- sonas: Defining and Measuring the Intended Effects of Persona Prompting on Task Performance. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Proceedings of the 2025 Conference on Empirical Methods in Natural Language Proces...
-
[22]
Manning, Kehang Zhu, and John J
Benjamin S. Manning, Kehang Zhu, and John J. Horton. Automated Social Science: Language Models as Scientist and Subjects, April 2024
2024
-
[23]
Ng, Makeda Moore, Isabelle Felix, and Chad E
Akihiko Masuda, Stacey Y. Ng, Makeda Moore, Isabelle Felix, and Chad E. Drake. Acceptance and commitment therapy as a treatment for a Latina young adult woman with purging: A case report.Practice Innovations, 1(1):20–35, 2016. ISSN 2377-8903. doi: 10.1037/pri0000012
-
[24]
Bernou Melisse and Teresa Arora. Cognitive behavioral therapy-enhanced through video- conferencing for night eating syndrome, binge-eating disorder and comorbid insomnia: A Case Report.Journal of Eating Disorders, 12(1):175, November 2024. ISSN 2050-2974. doi: 10.1186/s40337-024-01131-8. 13
-
[25]
Konstantinos Mitsopoulos, Ritwik Bose, Brodie Mather, Archna Bhatia, Kevin Gluck, Bonnie Dorr, Christian Lebiere, and Peter Pirolli. Psychologically-Valid Generative Agents: A Novel Approach to Agent-Based Modeling in Social Sciences.Proceedings of the AAAI Symposium Series, 2(1):340–348, 2023. ISSN 2994-4317. doi: 10.1609/aaaiss.v2i1.27698
-
[26]
Trustworthy AI Psychotherapy: Multi-Agent LLM Workflow for Counseling and Explainable Mental Disorder Diagnosis, August 2025
Mithat Can Ozgun, Jiahuan Pei, Koen Hindriks, Lucia Donatelli, Qingzhi Liu, and Junxiao Wang. Trustworthy AI Psychotherapy: Multi-Agent LLM Workflow for Counseling and Explainable Mental Disorder Diagnosis, August 2025
2025
-
[27]
Cunningham, Joel Z
Davide Paglieri, Logan Cross, William A. Cunningham, Joel Z. Leibo, and Alexander Sasha Vezhnevets. Persona Generators: Generating Diverse Synthetic Personas at Scale, February 2026
2026
-
[28]
Arjun Panickssery, Samuel R. Bowman, and Shi Feng. LLM Evaluators Recognize and Favor Their Own Generations.Advances in Neural Information Processing Systems, 37:68772–68802, December 2024. doi: 10.52202/079017-2197
-
[29]
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative Agents: Interactive Simulacra of Human Behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, UIST ’23, pages 1–22, New York, NY, USA, October 2023. Association for Computing Machinery. ISB...
-
[30]
Zou, Aaron Shaw, Benjamin Mako Hill, Carrie Cai, Meredith Ringel Morris, Robb Willer, Percy Liang, and Michael S
Joon Sung Park, Carolyn Q. Zou, Aaron Shaw, Benjamin Mako Hill, Carrie Cai, Meredith Ringel Morris, Robb Willer, Percy Liang, and Michael S. Bernstein. Generative Agent Simulations of 1,000 People, November 2024
2024
-
[31]
In-Context Impersonation Reveals Large Language Models’ Strengths and Biases.Advances in Neural Information Processing Systems, 36:72044–72057, December 2023
Leonard Salewski, Stephan Alaniz, Isabel Rio-Torto, Eric Schulz, and Zeynep Akata. In-Context Impersonation Reveals Large Language Models’ Strengths and Biases.Advances in Neural Information Processing Systems, 36:72044–72057, December 2023
2023
-
[32]
Personagym: Evaluating persona agents and LLMs
Vinay Samuel, Henry Peng Zou, Yue Zhou, Shreyas Chaudhari, Ashwin Kalyan, Tanmay Rajpurohit, Ameet Deshpande, Karthik Narasimhan, and Vishvak Murahari. Personagym: Evaluating persona agents and LLMs. InFindings of the Association for Computational Linguistics: EMNLP 2025, pages 6999–7022, Suzhou, China, November 2025. Association for Computational Linguis...
-
[33]
Quantifying Language Models’ Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting
Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. Quantifying Language Models’ Sensitivity to Spurious Features in Prompt Design or: How I learned to start worrying about prompt formatting. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=RIu5lyNXjT
2024
-
[34]
Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R. Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R. Johnston, Shauna Kravec, Timothy Maxwell, Sam McCandlish, Kamal Ndousse, Oliver Rausch, Nicholas Schiefer, Da Yan, Miranda Zhang, and Ethan Perez. Towards Understanding Sycophancy in Language Models. InThe Twelf...
2024
-
[35]
Patrick E. Shrout and Joseph L. Fleiss. Intraclass correlations: Uses in assessing rater reliability. Psychological Bulletin, 86(2):420–428, 1979. doi: 10.1037/0033-2909.86.2.420. 14
-
[36]
Jansen, and Jang Hyun Kim
Seungjong Sun, Eungu Lee, Dongyan Nan, Xiangying Zhao, Wonbyung Lee, Bernard J. Jansen, and Jang Hyun Kim. Random Silicon Sampling: Simulating Human Sub-Population Opinion Using a Large Language Model Based on Group-Level Demographic Information, February 2024
2024
-
[37]
Noah Wang, Z.y. Peng, Haoran Que, Jiaheng Liu, Wangchunshu Zhou, Yuhan Wu, Hongcheng Guo, Ruitong Gan, Zehao Ni, Jian Yang, Man Zhang, Zhaoxiang Zhang, Wanli Ouyang, Ke Xu, Wenhao Huang, Jie Fu, and Junran Peng. RoleLLM: Benchmarking, Eliciting, and Enhancing Role-Playing Abilities of Large Language Models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar...
-
[38]
Incharacter: Evaluating personality fidelity in role-playing agents through psychological interviews
Xintao Wang, Yunze Xiao, Jen-tse Huang, Siyu Yuan, Rui Xu, Haoran Guo, Quan Tu, Yaying Fei, Ziang Leng, and Wei Wang. Incharacter: Evaluating personality fidelity in role-playing agents through psychological interviews. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1840–1873, Bangk...
-
[39]
Toward an Evaluation Science for Generative AI Systems, March 2025
Laura Weidinger, Inioluwa Deborah Raji, Hanna Wallach, Margaret Mitchell, Angelina Wang, Olawale Salaudeen, Rishi Bommasani, Deep Ganguli, Sanmi Koyejo, and William Isaac. Toward an Evaluation Science for Generative AI Systems, March 2025
2025
-
[40]
From Symptoms to Systems: An Expert-Guided Approach to Understanding Risks of Generative AI for Eating Disorders, December 2025
Amy Winecoff and Kevin Klyman. From Symptoms to Systems: An Expert-Guided Approach to Understanding Risks of Generative AI for Eating Disorders, December 2025
2025
-
[41]
LingxiDiagBench: A Multi- Agent Framework for Benchmarking LLMs in Chinese Psychiatric Consultation and Diagnosis, February 2026
Shihao Xu, Tiancheng Zhou, Jiatong Ma, Yanli Ding, Yiming Yan, Ming Xiao, Guoyi Li, Haiyang Geng, Yunyun Han, Jianhua Chen, and Yafeng Deng. LingxiDiagBench: A Multi- Agent Framework for Benchmarking LLMs in Chinese Psychiatric Consultation and Diagnosis, February 2026
2026
-
[42]
Cummings, and Byron Reeves
Leo Yeykelis, Kaavya Pichai, James J. Cummings, and Byron Reeves. Using Large Language Models to Create AI Personas for Replication and Prediction of Media Effects: An Empirical Test of 133 Published Experimental Research Findings, August 2024
2024
-
[43]
Persona Drift for Adaptive Flow in Stage-Aware CBT Chatbots
Soyoung Yun, Minjoo Kim, Yeohyang Kim, and Hayoung Oh. Persona Drift for Adaptive Flow in Stage-Aware CBT Chatbots. InCompanion of the 2025 ACM International Joint Conference on Pervasive and Ubiquitous Computing, UbiComp Companion ’25, pages 1645–1651, New York, NY, USA, December 2026. Association for Computing Machinery. ISBN 979-8-4007-1477-1. doi: 10....
-
[44]
Gonzalez, and Ion Stoica
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena.Advances in Neural Information Processing Systems, 36:46595–46623, December 2023
2023
-
[45]
Mingqian Zheng, Jiaxin Pei, Lajanugen Logeswaran, Moontae Lee, and David Jurgens. When “A Helpful Assistant” Is Not Really Helpful: Personas in System Prompts Do Not Improve Performances of Large Language Models. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Findings of the Association for Computational Linguistics: EMNLP 2024, pages 15126...
-
[46]
Take me step-by- step through your thought process, what you choose to do, and how you feel physically and emotionally the next morning.”
“Imagine it’s a Friday night and your fridge has pizzas and leftover cake from a party. Take me step-by- step through your thought process, what you choose to do, and how you feel physically and emotionally the next morning.”
-
[47]
“Got it. In that Friday-night moment, what are the main urges or rules you notice (for example, ‘I should/shouldn’t’ thoughts), and how do they affect what you actually do? Describe your emotions, motivation, and any coping strategies you try.” 24
-
[48]
“And the next morning—how do you interpret what happened the night before? What do you tell yourself, how does your mood shift, and does it change what you do with food or your plans that day?” Block B — Corporate lunch
-
[49]
What about corporate lunch with your colleagues? What’s your experience like in that setting—your thoughts, emotions, motivation, and behavior in the moment?
“What about corporate lunch with your colleagues? What’s your experience like in that setting—your thoughts, emotions, motivation, and behavior in the moment?”
-
[50]
“In those kinds of social-meal situations, what feels most noticeable internally (e.g., being observed, comparisons, pressure to seem ‘normal’)? Walk me through your inner dialogue and how it shapes what you choose to eat or avoid.”
-
[51]
“After the corporate lunch is over, what tends to linger for you (physically, emotionally, mentally), and what do you do afterward? Describe any coping strategies and how your feelings change over the rest of the day.” Block C — Food intake
-
[52]
“Let’s talk about your food intake. Over the past week, what has your average daily food intake looked like? Please describe your thinking, emotions, motivation, and behavior as you go through a typical day—include any inner dialogue, emotional shifts, and coping strategies.”
-
[53]
“Thanks—that’s helpful. When during the day does eating (or not eating) feel easiest vs hardest, and what’s usually going through your mind in those moments? Describe your thoughts, emotions, motivation, and what you tend to do next.”
-
[54]
Imagine you are the individual and you are completing the questionnaires
“Are there any patterns across the week (workdays vs weekend, stress vs calm days) that change how you eat or how you feel about eating? Walk me through it with your inner dialogue and emotional shifts.” A.6 Assessment prompts All assessment prompts instruct the model to return structured JSON. Because no observer-report versions of the EDE-Q, CIA, or EAT...
-
[55]
ISSN 1942-969X. doi: 10.1037/tra0001675 PD Akihiko Masuda, Stacey Y. Ng, Makeda Moore, Isabelle Felix, and Chad E. Drake. Acceptance and commitment therapy as a treatment for a Latina young adult woman with purging: A case report.Practice Innovations, 1(1):20–35, 2016. ISSN 2377-8903. doi: 10.1037/pri0000012 A.9.1 Scripted conversation partner questions S...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.