Parameter-Efficient Fine-Tuning of Large Pretrained Models for Instance Segmentation Tasks
Pith reviewed 2026-06-28 15:12 UTC · model grok-4.3
The pith
Sequential adapters plus LoRA on deformable attention let transformer models reach competitive instance segmentation results while updating only 1-6% of parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
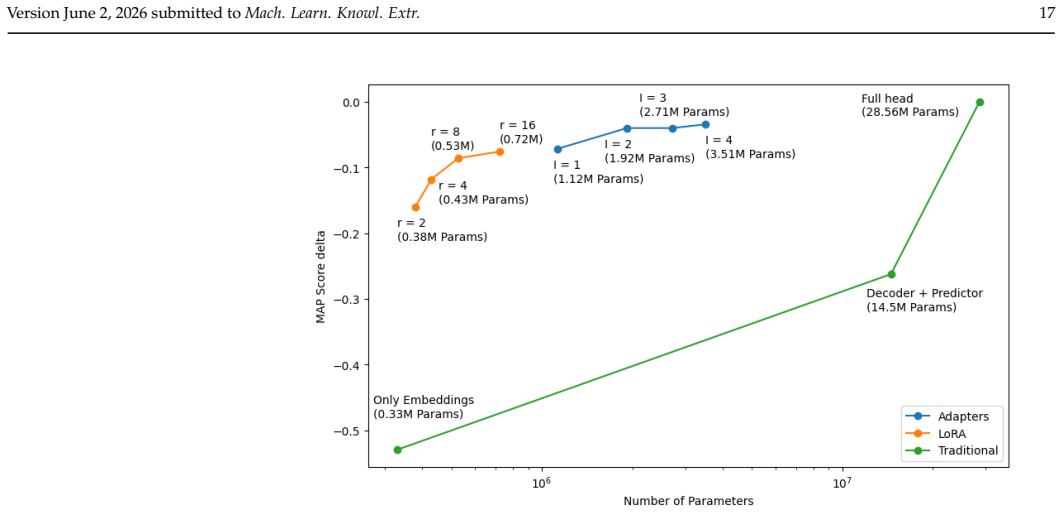
Integrating sequentially arranged adapter modules and applying LoRA to deformable attention achieves competitive performance on instance segmentation while fine-tuning only about 1-6% of model parameters, compared with the 40-55% required by traditional fine-tuning. Two to three adapters per transformer block give the best performance-efficiency trade-off, and LoRA on deformable attention is often more parameter-efficient than adapter configurations alone. Effectiveness varies with dataset complexity and model architecture.
What carries the argument
Sequentially arranged adapter modules combined with LoRA applied to deformable attention layers inside the transformer blocks.
If this is right
- Two or three adapters per transformer block strike the reported optimal balance between accuracy and parameter count.
- LoRA applied to deformable attention can exceed the efficiency of adapter-only setups on some datasets.
- PEFT performance varies systematically with dataset complexity and model architecture.
- Instance segmentation transfer learning becomes feasible at much lower computational cost than full fine-tuning.
Where Pith is reading between the lines
- The same sequential-adapter-plus-LoRA pattern could be tested on other dense prediction tasks such as semantic segmentation or depth estimation.
- Automated search over the number and placement of adapters might reduce the need for manual per-dataset tuning.
- Lower fine-tuning cost could allow models to be refreshed more often when new labeled data arrives.
Load-bearing premise
The four chosen benchmark datasets and two base models are representative enough for the efficiency claims to generalize.
What would settle it
A new large-scale instance segmentation dataset where full fine-tuning reaches the same mAP while updating fewer than 6% of parameters would falsify the claimed efficiency advantage.
Figures





read the original abstract
Research and applications in artificial intelligence have recently shifted with the rise of large pretrained models, which deliver state-of-the-art results across numerous tasks. However, the substantial increase in parameters introduces a need for parameter-efficient training strategies. Despite significant advancements, limited research has explored parameter-efficient fine-tuning (PEFT) methods in the context of transformer-based models for instance segmentation. Addressing this gap, this study investigates the effectiveness of PEFT methods, specifically adapters and Low-Rank Adaptation (LoRA), applied to two models across four benchmark datasets. Integrating sequentially arranged adapter modules and applying LoRA to deformable attention--explored here for the first time--achieves competitive performance while fine-tuning only about 1-6% of model parameters, a marked improvement over the 40-55% required in traditional fine-tuning. Key findings indicate that using 2-3 adapters per transformer block offers an optimal balance of performance and efficiency. Furthermore, LoRA, exhibits strong parameter efficiency when applied to deformable attention, and in certain cases surpasses adapter configurations. These results show that the impact of PEFT techniques varies based on dataset complexity and model architecture, underscoring the importance of context-specific tuning. Overall, this work demonstrates the potential of PEFT to enable scalable, customizable, and computationally efficient transfer learning for instance segmentation tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates parameter-efficient fine-tuning (PEFT) via adapters and LoRA (applied to deformable attention, claimed as first exploration) for transformer-based instance segmentation models. Across two base models and four benchmark datasets, it asserts that sequential adapters (optimally 2-3 per block) and LoRA achieve competitive performance while updating only 1-6% of parameters versus 40-55% for full fine-tuning, with results varying by dataset complexity and architecture.
Significance. If the empirical findings are robustly documented, the work would fill a noted gap in PEFT applications to instance segmentation and support more scalable transfer learning with large vision models by substantially reducing trainable parameters.
major comments (2)
- [Abstract] Abstract: the central efficiency claim (competitive performance at 1-6% parameters vs. 40-55% full fine-tuning) is stated with specific percentages but supplies no numerical results, baselines, error bars, or statistical tests, rendering the claim unverifiable from the provided text.
- [Abstract] Abstract / experimental claims: the assertion that 1-6% efficiency and optimality of 2-3 adapters generalize is supported only by four datasets and two models; the text itself notes variation with dataset complexity and architecture, yet no further cross-validation, additional datasets, or sensitivity analysis is described to substantiate broader applicability.
minor comments (1)
- [Abstract] Abstract: phrasing such as 'explored here for the first time' would benefit from a supporting citation or explicit novelty statement in the introduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point-by-point below and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central efficiency claim (competitive performance at 1-6% parameters vs. 40-55% full fine-tuning) is stated with specific percentages but supplies no numerical results, baselines, error bars, or statistical tests, rendering the claim unverifiable from the provided text.
Authors: We acknowledge that the abstract presents the parameter-efficiency claims in summary form without embedding specific mAP values or statistical details. The full manuscript contains tables reporting exact performance metrics, parameter counts, and comparisons against full fine-tuning baselines across all datasets. We will revise the abstract to include one or two concrete quantitative highlights (e.g., mAP deltas on COCO and Cityscapes) while preserving brevity, and we will explicitly reference the experimental section for error bars and statistical comparisons. revision: yes
-
Referee: [Abstract] Abstract / experimental claims: the assertion that 1-6% efficiency and optimality of 2-3 adapters generalize is supported only by four datasets and two models; the text itself notes variation with dataset complexity and architecture, yet no further cross-validation, additional datasets, or sensitivity analysis is described to substantiate broader applicability.
Authors: The study deliberately evaluates two distinct transformer architectures on four standard instance-segmentation benchmarks chosen to span varying complexity. The manuscript already states that outcomes depend on dataset and architecture; we do not claim universal generalization. Adding further datasets or exhaustive sensitivity sweeps would require new large-scale experiments outside the current scope. We will expand the discussion and limitations sections to more explicitly qualify the scope of the claims and note the absence of additional cross-validation. revision: partial
Circularity Check
No circularity: empirical comparison with no derivations
full rationale
This is an empirical study reporting experimental results of adapter and LoRA configurations on four benchmark datasets with two base models. No equations, derivations, or fitted parameters are present that could reduce to inputs by construction. Claims about 1-6% parameter efficiency and optimal 2-3 adapters are direct experimental outcomes, not self-definitional or self-citation dependent. The paper is self-contained against its own benchmarks with no load-bearing self-citations or uniqueness theorems invoked.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Segment Anything.arXiv2023, arXiv:2304.02643
Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Rolland, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.Y.; et al. Segment Anything.arXiv2023, arXiv:2304.02643. Available online: http://arxiv.org/abs/2304.02643 (accessed on)
-
[2]
Double Transfer Learning to Detect Lithium-Ion Batteries on X-Ray Images
Rohrschneider, D.; Abou Baker, N.; Handmann, U. Double Transfer Learning to Detect Lithium-Ion Batteries on X-Ray Images. In Proceedings of the 17th International Work-Conference on Artificial Neural Networks (IWANN), Ponta Delgada, Portugal, 19–21 June 2023; pp. 175–188
2023
-
[3]
Qiu, Y.; Jin, Y. ChatGPT and Finetuned BERT: A comparative Study for Developing Intelligent Design Dupport Systems.Intell. Syst. Appl.2024,21, 200308. https://doi.org/10.1016/j.iswa.2023.200308
-
[4]
Few-Shot Issue Report Classification with Adapters
Ebrahim, F.; Joy, M. Few-Shot Issue Report Classification with Adapters. In Proceedings of the International Workshop on NL-Based Software Engineering, Lisbon, Portugal, 20 April 2024; pp. 41–44
2024
-
[5]
QLoRA: Efficient Finetuning of Quantized LLMs
Dettmers, T.; Pagnoni, A.; Holtzman, A.; Zettlemoyer, L. QLoRA: Efficient Finetuning of Quantized LLMs. In Proceedings of the 37th International Conference on Neural Information Processing Systems (NeurIPS), New Orleans, LA, USA, 10–15 December 2024; pp. 10088–10115
2024
-
[6]
LLaMA-Adapter: Efficient Fine-tuning of Large Language Models with Zero-initialized Attention
Zhang, R.; Han, J.; Liu, C.; Zhou, A.; Lu, P .; Qiao, Y.; Li, H.; Gao, P . LLaMA-Adapter: Efficient Fine-tuning of Large Language Models with Zero-initialized Attention. In Proceedings of the 12th International Conference on Learning Representations (ICLR), Vienna, Austria, 7–11 May 2024
2024
-
[7]
Multilingual Domain Adaptation for NMT: Decoupling Language and Domain Information with Adapters
Stickland, A.C.; Berard, A.; Nikoulina, V . Multilingual Domain Adaptation for NMT: Decoupling Language and Domain Information with Adapters. In Proceedings of the 6th Conference on Machine Translation, Punta Cana, Dominican Republic, 10–11 November 2021; pp. 578–598. Version June 2, 2026 submitted toMach. Learn. Knowl. Extr. 24
2021
-
[8]
Simple, Scalable Adaptation for Neural Machine Translation
Bapna, A.; Firat, O. Simple, Scalable Adaptation for Neural Machine Translation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 1538–1548
2019
-
[9]
LoRA: Low-Rank Adaptation of Large Language Models
Hu, E.J.; Shen, Y.; Wallis, P .; Allen-Zhu, Z.; Li, Y.; Wang, S.; Wang, L.; Chen, W. LoRA: Low-Rank Adaptation of Large Language Models. In Proceedings of the 10th International Conference on Learning Representations (ICLR), Online, 25–29 April 2022
2022
-
[10]
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Li, X.L.; Liang, P . Prefix-Tuning: Optimizing Continuous Prompts for Generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Bangkok, Thailand, 1–6 August 2021; pp. 4582–4597
2021
-
[11]
Chen, G.; Liu, F.; Meng, Z.; Liang, S. Revisiting Parameter-Efficient Tuning: Are We Really There Yet? In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 2612—-2626
2022
-
[12]
The Power of Scale for Parameter-Efficient Prompt Tuning
Lester, B.; Al-Rfou, R.; Constant, N. The Power of Scale for Parameter-Efficient Prompt Tuning. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Punta Cana, Dominican Republic, 7–11 November 2021; pp. 3045–3059
2021
-
[13]
Parameter- Efficient Transfer Learning for NLP
Houlsby, N.; Giurgiu, A.; Jastrzebski, S.; Morrone, B.; De Laroussilhe, Q.; Gesmundo, A.; Attariyan, M.; Gelly, S. Parameter- Efficient Transfer Learning for NLP . In Proceedings of the 36th International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019; pp. 2790–2799
2019
-
[14]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 9th International Conference on Learning Representations (ICLR), Online, 3–7 May 2021
2021
-
[15]
Vision Transformer Adapter for Dense Predictions
Chen, Z.; Duan, Y.; Wang, W.; He, J.; Lu, T.; Dai, J.; Qiao, Y. Vision Transformer Adapter for Dense Predictions. In Proceedings of the 11th International Conference on Learning Representations (ICLR), Online, 1–5 May 2023
2023
-
[16]
Don’t Waste SAM
Abou Baker, N.; Handmann, U. Don’t Waste SAM. In Proceedings of the 31st European Symposium on Artificial Neural Networks (ESANN), Bruges, Belgium, 4–6 October 2023; pp. 429–434
2023
-
[17]
SAM-Adapter: Adapting Segment Anything in Underperformed Scenes
Chen, T.; Zhu, L.; Ding, C.; Cao, R.; Wang, Y.; Zhang, S.; Li, Z.; Sun, L.; Zang, Y.; Mao, P . SAM-Adapter: Adapting Segment Anything in Underperformed Scenes. In Proceedings of the International Conference on Computer Vision Workshops (ICCVW), Paris, France, 2–3 October 2023; pp. 3359–3367
2023
-
[18]
Wu, J.; Ji, W.; Liu, Y.; Fu, H.; Xu, M.; Xu, Y.; Jin, Y. Medical SAM Adapter: Adapting Segment Anything Model for Medical Image Segmentation.arXiv2023, arxiv:2304.12620. Available online: http://arxiv.org/abs/2304.12620 (accessed on)
-
[19]
Learning Transferable Visual Models From Natural Language Supervision
Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P .; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning (ICML), Online, 18–24 July 2021; pp. 8748–8763
2021
-
[20]
CLIP-Adapter: Better Vision-Language Models with Feature Adapters.Int
Gao, P .; Geng, S.; Zhang, R.; Ma, T.; Fang, R.; Zhang, Y.; Li, H.; Qiao, Y. CLIP-Adapter: Better Vision-Language Models with Feature Adapters.Int. J. Comput. Vis.2024,132, 581–595
2024
-
[21]
Emerging Properties in Self-Supervised Vision Transformers
Caron, M.; Touvron, H.; Misra, I.; Jégou, H.; Mairal, J.; Bojanowski, P .; Joulin, A. Emerging Properties in Self-Supervised Vision Transformers. In Proceedings of the International Conference on Computer Vision (ICCV), Online, 11–17 October 2021; pp. 9650–9660
2021
-
[22]
DINOv2: Learning Robust Visual Features without Supervision.Transact
Oquab, M.; Darcet, T.; Moutakanni, T.; Vo, H.V .; Szafraniec, M.; Khalidov, V .; Fernandez, P .; Haziza, D.; Massa, F.; El-Nouby, A.; et al. DINOv2: Learning Robust Visual Features without Supervision.Transact. Mach. Learn. Res.2024
2024
-
[23]
Zhang, B.; Chen, Y.; Bai, L.; Zhao, Y.; Sun, Y.; Yuan, Y.; Zhang, J.; Ren, H. Learning to Adapt Foundation Model DINOv2 for Capsule Endoscopy Diagnosis.arXiv2024, arxiv:2406.10508. Available online: http://arxiv.org/abs/2406.10508 (accessed on)
-
[24]
Surgical-DINO: Adapter Learning of Foundation Models for Depth Estimation in Endoscopic Surgery.Int
Cui, B.; Islam, M.; Bai, L.; Ren, H. Surgical-DINO: Adapter Learning of Foundation Models for Depth Estimation in Endoscopic Surgery.Int. J. Comput. Assist. Radiol. Surg.2024,19, 1013–1020. https://doi.org/10.1007/s11548-024-03083-5
-
[25]
Low Rank Adaptation for Stable Domain Adaptation of Vision Transformers.Opt
Filatov, N.; Kindulov, M. Low Rank Adaptation for Stable Domain Adaptation of Vision Transformers.Opt. Mem. Neural Netw. 2023,32, 277–283. https://doi.org/10.3103/S1060992X2306005X
-
[26]
One-for-All: Generalized LoRA for Parameter-Efficient Fine-tuning.arXiv2023, arxiv:2306.07967
Chavan, A.; Liu, Z.; Gupta, D.; Xing, E.; Shen, Z. One-for-All: Generalized LoRA for Parameter-Efficient Fine-tuning.arXiv2023, arxiv:2306.07967. Available online: http://arxiv.org/abs/2306.07967 (accessed on)
-
[27]
Chen, X.; Liu, J.; Wang, Y.; Wang, P .P .; Brand, M.; Wang, G.; Koike-Akino, T. SuperLoRA: Parameter-Efficient Unified Adaptation of Multi-Layer Attention Modules.arXiv2024, arxiv:2403.11887. Available online: http://arxiv.org/abs/2403.11887 (accessed on)
-
[28]
Leiñena, J.; Saiz, F.A.; Barandiaran, I. Latent Diffusion Models to Enhance the Performance of Visual Defect Segmentation Networks in Steel Surface Inspection.Sensors2024,24, 6016. https://doi.org/10.3390/s24186016
-
[29]
Segment Everything Everywhere All at Once
Zou, X.; Yang, J.; Zhang, H.; Li, F.; Li, L.; Wang, J.; Wang, L.; Gao, J.; Lee, Y.J. Segment Everything Everywhere All at Once. In Proceedings of the 37th International Conference on Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 10–15 December 2024; p. 868
2024
-
[30]
Mask DINO: Towards a Unified Transformer-Based Framework for Object Detection and Segmentation
Li, F.; Zhang, H.; Xu, H.; Liu, S.; Zhang, L.; Ni, L.M.; Shum, H.Y. Mask DINO: Towards a Unified Transformer-Based Framework for Object Detection and Segmentation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 3041–3050
2023
-
[31]
Scribble-Supervised Video Object Segmentation.IEEE/CAA J
Huang, P .; Han, J.; Liu, N.; Ren, J.; Zhang, D. Scribble-Supervised Video Object Segmentation.IEEE/CAA J. Autom. Sin.2022, 9, 339–353. https://doi.org/10.1109/JAS.2021.1004210. Version June 2, 2026 submitted toMach. Learn. Knowl. Extr. 25
-
[32]
SAM 2: Segment Anything in Images and Videos.arXiv2024, arxiv:2408.00714
Ravi, N.; Gabeur, V .; Hu, Y.T.; Hu, R.; Ryali, C.; Ma, T.; Khedr, H.; Rädle, R.; Rolland, C.; Gustafson, L.; et al. SAM 2: Segment Anything in Images and Videos.arXiv2024, arxiv:2408.00714. Available online: http://arxiv.org/abs/2408.00714 (accessed on)
-
[33]
Deep Residual Learning for Image Recognition
He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV , USA, 26 June –1 July 2016; pp. 770–778
2016
-
[34]
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the International Conference on Computer Vision (ICCV), Online, 11–17 October 2021; pp. 9992–10002
2021
-
[35]
Per-Pixel Classification is Not All You Need for Semantic Segmentation
Cheng, B.; Schwing, A.; Kirillov, A. Per-Pixel Classification is Not All You Need for Semantic Segmentation. In Proceedings of the 35th International Conference on Neural Information Processing Systems (NeurIPS), Online, 6–14 December 2021; pp. 17864–17875
2021
-
[36]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. In Proceedings of the 9th International Conference on Learning Representations (ICLR), Online, 3–7 May 2021
2021
-
[37]
Focal Modulation Networks
Yang, J.; Li, C.; Dai, X.; Gao, J. Focal Modulation Networks. In Proceedings of the 36th International Conference on Neural Information Processing Systems (NeurIPS), New Orleans, LA, USA, 28 Novemeber–9 December 2022; pp. 4203–4217
2022
-
[38]
Feature Pyramid Networks for Object Detection
Lin, T.Y.; Dollár, P .; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944
2017
-
[39]
Masked-attention Mask Transformer for Universal Image Segmenta- tion
Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-attention Mask Transformer for Universal Image Segmenta- tion. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 1280–1289
2022
-
[40]
LoRA-Torch: PyTorch Reimplementation of LoRA
Lin, B. LoRA-Torch: PyTorch Reimplementation of LoRA. Available online: https://github.com/Baijiong-Lin/LoRA-Torch (accessed on 14 November 2024)
2024
-
[41]
Trotter, C.; Atkinson, G.; Sharpe, M.; Richardson, K.; McGough, A.S.; Wright, N.; Burville, B.; Berggren, P . NDD20: A large- Scale Few-shot Dolphin Dataset for Coarse and Fine-grained Categorisation.arXiv2020, arxiv:2005.13359. Available online: http://arxiv.org/abs/2005.13359 (accessed on)
arXiv 2005
-
[42]
ZeroWaste Dataset: Towards Deformable Object Segmentation in Cluttered Scenes
Bashkirova, D.; Abdelfattah, M.; Zhu, Z.; Akl, J.; Alladkani, F.; Hu, P .; Ablavsky, V .; Calli, B.; Bargal, S.A.; Saenko, K. ZeroWaste Dataset: Towards Deformable Object Segmentation in Cluttered Scenes. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 22–24 August 2022; pp. 21147–21157
2022
-
[43]
ETHSeg: An Amodel Instance Segmentation Network and a Real-world Dataset for X-Ray Waste Inspection
Qiu, L.; Xiong, Z.; Wang, X.; Liu, K.; Li, Y.; Chen, G.; Han, X.; Cui, S. ETHSeg: An Amodel Instance Segmentation Network and a Real-world Dataset for X-Ray Waste Inspection. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 22–24 August 2022; pp. 2273–2282
2022
-
[44]
The Cityscapes Dataset for Semantic Urban Scene Understanding
Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV , USA, 26 June–1 July 2016; pp. 3213–3223
2016
-
[45]
A Simple Framework for Open-Vocabulary Segmentation and Detection
Zhang, H.; Li, F.; Zou, X.; Liu, S.; Li, C.; Yang, J.; Zhang, L. A Simple Framework for Open-Vocabulary Segmentation and Detection. In Proceedings of the International Conference on Computer Vision (ICCV), Paris, France, 2–6 October 2023; pp. 1020–1031
2023
-
[46]
OneFormer: One Transformer to Rule Universal Image Segmentation
Jain, J.; Li, J.; Chiu, M.T.; Hassani, A.; Orlov, N.; Shi, H. OneFormer: One Transformer to Rule Universal Image Segmentation. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; pp. 2989–2998. Disclaimer/Publisher’s Note:The statements, opinions and data contained in all publications...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.