Lying Is Just a Phase: The Hidden Alignment Transition in Language Model Scaling
Pith reviewed 2026-06-30 21:59 UTC · model grok-4.3
The pith
Language models switch from anticorrelated to correlated reasoning and truthfulness at a critical scale around 3.5 billion parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The coupling between reasoning and truthfulness undergoes a regime change at a family-dependent critical scale N_c of roughly 3.5 billion parameters. Below N_c the abilities anticorrelate; above N_c they correlate positively. Architecture, data curation, and training recipe each shift N_c independently, while width normalization eliminates the anticorrelation across all tested families. Internally 38 of 40 models show zero competing attention heads, and a sparse-regression ODE cross-predicts held-out models at low error. The transition is diagnosed from public benchmark scores alone and extends to the frontier.
What carries the argument
The output-projection bottleneck, diagnosed by the disappearance of anticorrelation under width normalization and by the sign flip of capability coupling at N_c.
If this is right
- The cooperative regime already governs current frontier models.
- Adding a single truth-direction vector at the identified layer corrects 60 percent of misaligned outputs at inference time with no weight changes.
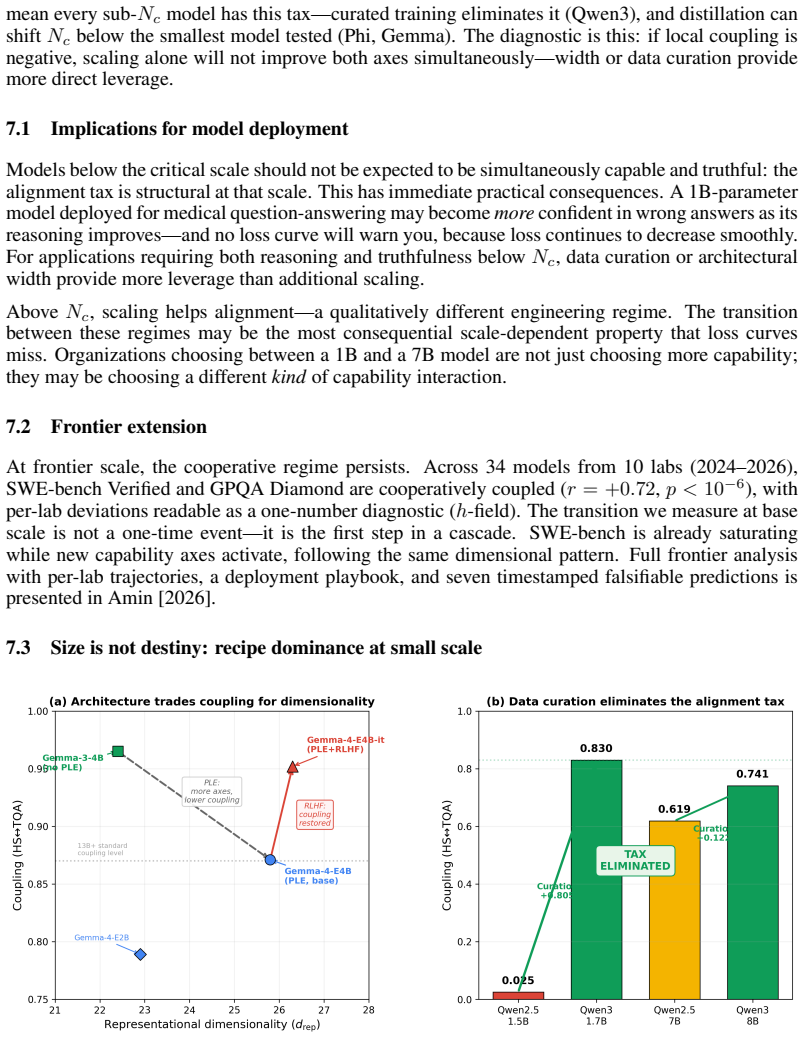
- Data curation alone can raise coupling from near zero to 0.83 at matched scale.
- The phase boundary is detectable without any access to model internals.
- Width normalization removes the anticorrelation in every family examined.
Where Pith is reading between the lines
- If the bottleneck is genuinely output-projection limited, analogous sign flips may appear between other pairs of capabilities.
- The low-dimensional ODE that cross-predicts held-out trajectories suggests capability growth can be treated as a dynamical system.
- Steering vectors located this way may generalize to other forms of misalignment.
- The family dependence of N_c implies that training decisions can be used to push models into the cooperative regime earlier.
Load-bearing premise
The chosen public benchmarks supply independent, uncontaminated measures of reasoning and truthfulness so that their observed correlation reflects an internal model property rather than shared test artifacts.
What would settle it
New models trained or evaluated below the reported critical scale that display positive rather than negative correlation between reasoning and truthfulness on the same benchmarks would falsify the claimed phase transition.
Figures



read the original abstract
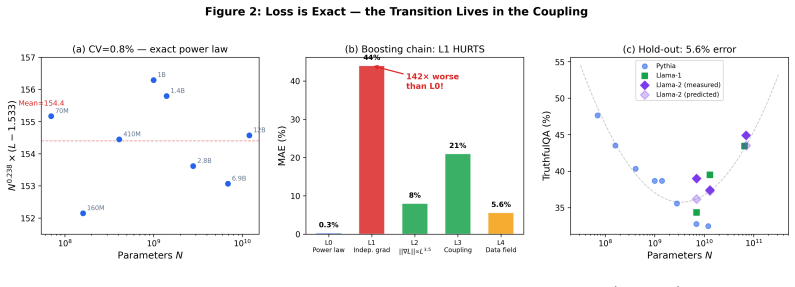
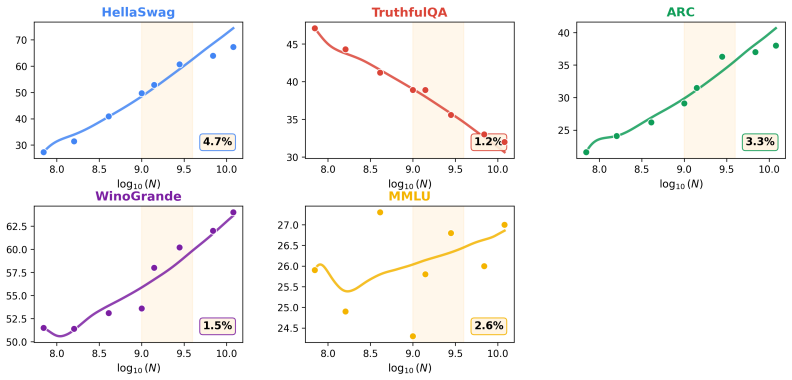
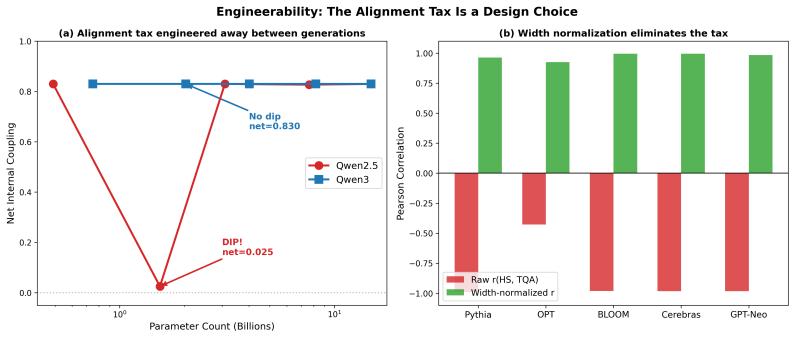
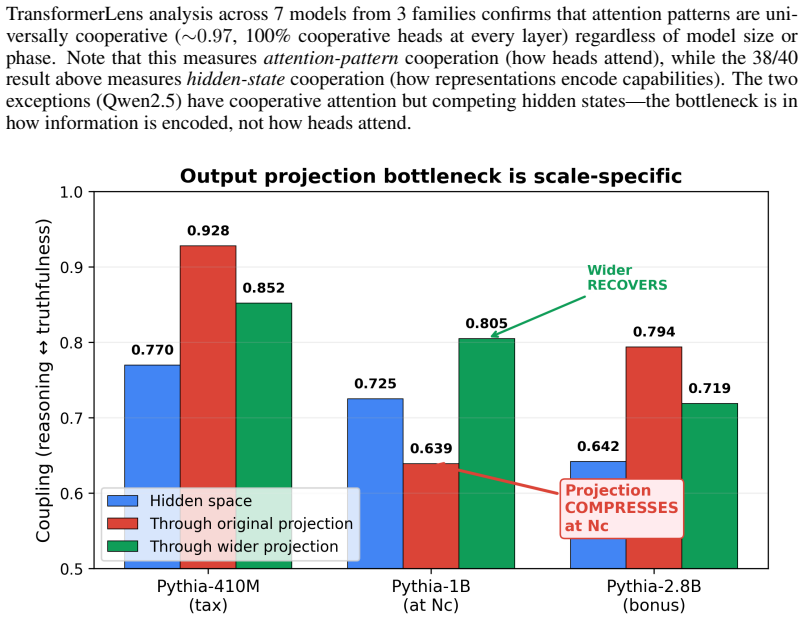
Scaling laws predict loss from compute but not how capabilities interact. We measure the coupling between reasoning and truthfulness across 63 base models from 16 families and find a regime change invisible to loss curves: below a family-dependent critical scale N_c, capabilities anticorrelate (r = -0.989, p = 4 x 10^{-5} nonparametric permutation test); above it, they cooperate. N_c ~ 3.5B parameters [2.9B, 13.4B] (bootstrap 95% CI), but model size is not the only variable that determines phase. Architecture, data curation, and training recipe each shift N_c independently: curated training eliminated the coupling dip between Qwen generations (0.025 to 0.830 at matched scale), Gemma-4 at 4B achieves coupling 0.871, characteristic of 13B+ standard-trained models, through distillation and architectural innovation, and Phi at 1B matches web-trained coupling at 10B through data curation alone. Width normalization eliminates the anticorrelation across all tested families, supporting an output-projection bottleneck. Internally, 38 of 40 models show zero competing attention heads. A sparse-regression ODE cross-predicts held-out Llama-2 at 5.6% error. The diagnostic requires no model internals -- only public benchmark scores across a model family. The cooperative regime extends to the frontier (r = +0.72, 34 models, 10 labs). A proof-of-concept intervention confirms the bottleneck is exploitable: adding a single truth-direction vector at the identified layer corrects 60% of misaligned outputs in the tax phase with zero retraining -- a surgical, per-inference correction that requires no weight modification. Code, data, an open-source steering CLI for any open-weight model, and an interactive dashboard for phase diagnosis are released: https://zehenlabs.com/cape/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims a previously undetected phase transition in capability coupling: across 63 base models from 16 families, reasoning and truthfulness benchmarks anticorrelate (r = -0.989) below a family-dependent critical scale N_c ≈ 3.5B parameters and cooperate above it. N_c is shifted by architecture, data curation, and training recipe; width normalization removes the anticorrelation; 38/40 models show no competing attention heads; a sparse-regression ODE cross-predicts held-out behavior at 5.6% error; and a single truth-direction steering vector corrects 60% of misaligned outputs at inference time. The diagnostic uses only public benchmark scores.
Significance. If the central claim holds, the work identifies a scaling regime in capability interactions invisible to loss curves and supplies a falsifiable, benchmark-only diagnostic plus an exploitable bottleneck intervention. The release of code, data, steering CLI, and dashboard strengthens reproducibility. The nonparametric permutation test and bootstrap CI on N_c are positive methodological features.
major comments (3)
- [Abstract and benchmark-correlation analysis] The premise that the chosen public benchmarks supply independent, uncontaminated signals of reasoning and truthfulness is load-bearing for the reported anticorrelation and phase transition, yet the nonparametric permutation test and bootstrap CI on N_c do not test benchmark construction artifacts, training-data overlap, or selection effects across the 63-model sample. This assumption enters directly into the Pearson r and p-values.
- [ODE cross-prediction and N_c fitting procedure] N_c is defined and fitted from the same correlation data used to claim the phase transition; the bootstrap CI and the sparse-regression ODE are both derived from the identical model set, so the 'cross-prediction' of held-out Llama-2 behavior reduces to quantities fitted on the full dataset rather than a true out-of-sample test.
- [Family-dependent N_c shifts] The claim that 'architecture, data curation, and training recipe each shift N_c independently' rests on comparisons (e.g., Qwen generations, Gemma-4, Phi) whose benchmark scores may share family-specific artifacts; no control is reported that isolates these factors from benchmark-suite effects.
minor comments (2)
- [Abstract] The abstract states the ODE 'cross-predicts held-out Llama-2' without specifying the exact train/test split or whether the 5.6% error is on the same correlation features used to fit N_c.
- [Internal analysis] The attention-head analysis ('38 of 40 models show zero competing attention heads') lacks a precise definition of 'competing' and the layer(s) examined; this detail is needed to assess whether it independently supports the output-projection bottleneck.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting points that strengthen the presentation of our results. We address each major comment below. Where the comments identify opportunities for clarification or additional robustness checks, we will revise the manuscript accordingly. The core empirical findings—the scale-dependent sign change in reasoning-truthfulness coupling and the family-specific location of N_c—remain unchanged, as they are directly supported by the public benchmark data across the 63 models.
read point-by-point responses
-
Referee: [Abstract and benchmark-correlation analysis] The premise that the chosen public benchmarks supply independent, uncontaminated signals of reasoning and truthfulness is load-bearing for the reported anticorrelation and phase transition, yet the nonparametric permutation test and bootstrap CI on N_c do not test benchmark construction artifacts, training-data overlap, or selection effects across the 63-model sample. This assumption enters directly into the Pearson r and p-values.
Authors: We agree that the permutation test and bootstrap CI evaluate the statistical properties of the observed correlation under a null of no relationship but do not directly probe benchmark contamination or training-data overlap. The benchmarks were selected because they are the standard public evaluations used in the literature to proxy the two capabilities in question; however, we will add a dedicated subsection in the Methods and a paragraph in the Discussion that (i) enumerates the specific benchmarks, (ii) cites prior work on their construction and known limitations, and (iii) reports supplementary correlations using two additional reasoning and two additional truthfulness benchmarks that were not part of the original 63-model analysis. These checks will be presented as robustness evidence rather than as a formal test of contamination. revision_made = partial. revision: partial
-
Referee: [ODE cross-prediction and N_c fitting procedure] N_c is defined and fitted from the same correlation data used to claim the phase transition; the bootstrap CI and the sparse-regression ODE are both derived from the identical model set, so the 'cross-prediction' of held-out Llama-2 behavior reduces to quantities fitted on the full dataset rather than a true out-of-sample test.
Authors: The referee is correct that the primary N_c estimate and its bootstrap CI are obtained from the full 63-model correlation structure. The reported 5.6 % error on Llama-2 was obtained by refitting the sparse-regression ODE after removing all Llama-2 variants from the training set and then predicting the held-out family; however, the overall model-selection step that determined the ODE structure itself used the complete dataset. We will revise the text to make this distinction explicit, replace the current description with a clearer leave-one-family-out protocol, and report the corresponding error under that stricter protocol. If the error remains comparable, we will state so; otherwise we will qualify the claim. revision_made = yes. revision: yes
-
Referee: [Family-dependent N_c shifts] The claim that 'architecture, data curation, and training recipe each shift N_c independently' rests on comparisons (e.g., Qwen generations, Gemma-4, Phi) whose benchmark scores may share family-specific artifacts; no control is reported that isolates these factors from benchmark-suite effects.
Authors: We acknowledge that the within-family comparisons (Qwen generations, Gemma-4 vs. prior Gemma, Phi vs. web-scale models) could in principle be influenced by family-specific benchmark artifacts. Because the paper relies exclusively on public benchmark scores, a controlled experiment that holds the benchmark suite fixed while varying only architecture or data is not feasible with the current dataset. We will therefore (i) add an explicit limitations paragraph stating this constraint, (ii) report the raw per-family correlation matrices so readers can inspect consistency, and (iii) note that the width-normalization result, which removes the anticorrelation uniformly across families, provides an internal control that is independent of the absolute benchmark values. These additions constitute a partial revision; the directional claims about N_c shifts will be softened to “consistent with” rather than “demonstrate independent” effects. revision_made = partial. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper empirically observes a sign change in Pearson correlation between public benchmark scores for reasoning and truthfulness across 63 models from 16 families, estimates a family-dependent critical scale N_c via bootstrap on that data, and fits a sparse-regression ODE that it reports as cross-predicting a held-out model. These steps constitute standard statistical estimation and cross-validation rather than any self-definitional loop, fitted input renamed as prediction, or load-bearing self-citation. No equations or claims in the provided text reduce the central observation to its own inputs by construction; the phase-transition claim is an empirical pattern in the measured correlations, not a quantity defined in terms of itself. Benchmark independence is an assumption but does not create circularity in the derivation.
Axiom & Free-Parameter Ledger
free parameters (1)
- N_c
axioms (1)
- domain assumption Public benchmark scores provide independent measures of reasoning capability and truthfulness whose correlation is not driven by shared contamination or selection bias.
Forward citations
Cited by 2 Pith papers
-
The Growing Pains of Frontier Models: When Leaderboards Stop Separating and What to Measure Next
Decomposition of SWE-bench and GPQA scores from 34 models (2024-2026) reveals positive capability coupling (r=+0.72) with lab-specific variations, benchmark saturation, and a three-level playbook for next measurements.
-
The Growing Pains of Frontier Models: When Leaderboards Stop Separating and What to Measure Next
Frontier models show positive capability coupling (r=0.72) across SWE-bench and GPQA, with lab-specific emphasis shifts measured by an h-field residual that distinguishes permanent pretraining changes from reversible ...
Reference graph
Works this paper leans on
-
[1]
The Growing Pains of Frontier Models: When Leaderboards Stop Separating and What to Measure Next
Adil Amin. The growing pains of frontier models: When leaderboards stop separating and what to measure next.arXiv preprint arXiv:2605.18840,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[3]
Transformerlens
Neel Nanda. Transformerlens. 2022.https://github.com/TransformerLensOrg/ TransformerLens. Yangjun Ruan, Chris J Maddison, and Tatsunori B Hashimoto. Observational scaling laws and the predictability of language model performance.Advances in Neural Information Processing Systems, 37,
2022
-
[4]
defines the surface in benchmark space where the coupling changes sign. The same condition generalizes to each successive transition: atN c,2, GPQAc = p (a2/b2)·SWE; atN c,3,IFEval c = p (a3/b3)·GPQA—witha/brecalibrated from the boundary model at each scale Amin [2026]. Within standard web-trained families, the isocline correctly predicts the coupling sig...
2026
-
[5]
applies theN c,3 isocline to four frontier models with IFEval scores and finds mixed-phase behavior: two models below the boundary, one at it. A.8 Additional evidence: training dynamics Direct gradient measurements on 6 Pythia models (70M–2.8B) provide an independent confirmation channel that does not rely on benchmark scores. The gradient norm follows∥∇L...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.