CAVEWOMAN: How Large Language Models Behave Under Linguistic Input and Output Compression
Pith reviewed 2026-06-26 00:48 UTC · model grok-4.3
The pith
Compressing the model's output cuts realized inference cost 1.4-3x while compressing the user's input raises net cost about 1.15x because models reply longer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
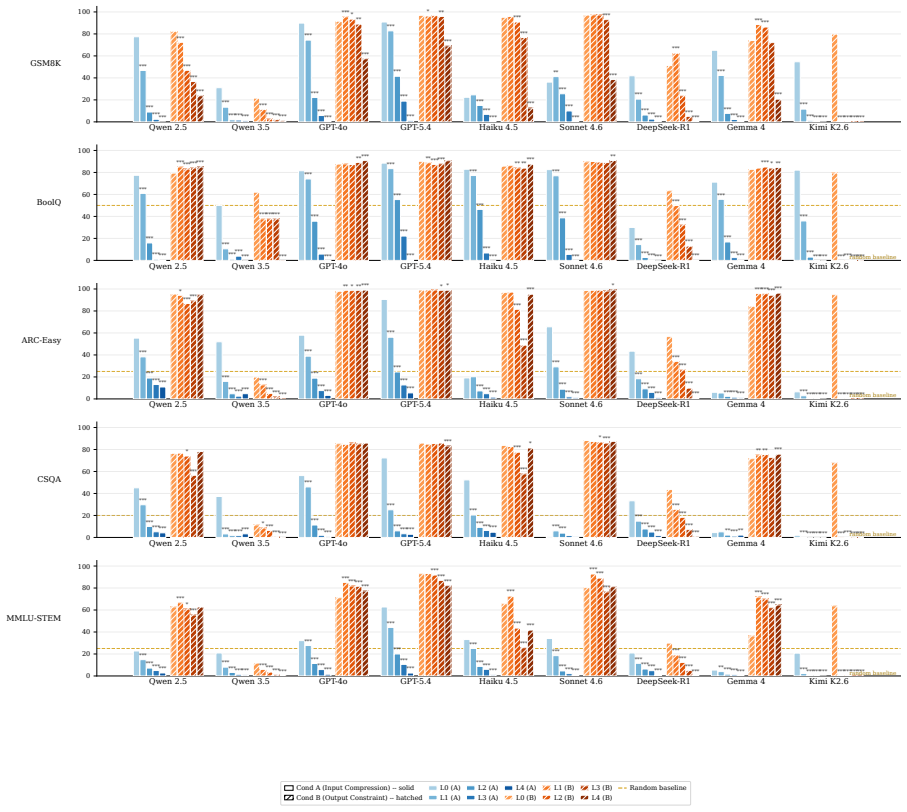
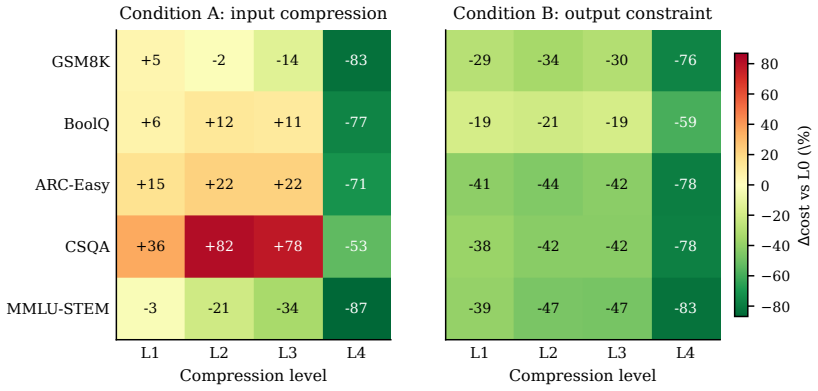
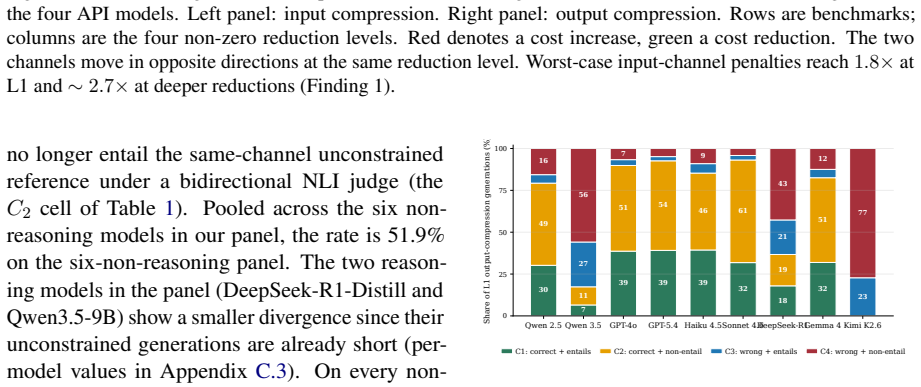
Output compression cuts realized cost on most API models (1.4-2.4x per model, up to 3x in the best case) and on all four open-weight models under public-tier pricing. Input compression has the opposite effect, a strict lose-lose: it raises net cost rather than lowering it (~1.15x on the five-benchmark mean, up to 1.8x on the worst dataset and 2.7x under stronger compression), because models compensate with longer responses even as accuracy collapses. Under the same setting, surface text diverges from the unconstrained reference: on the non-reasoning models, roughly half of all generations are correct yet their surface text no longer entails the model's own unconstrained baseline generation.
What carries the argument
The Cavewoman two-channel evaluation protocol that scores every generation on task accuracy, realized per-item cost, and reference-text agreement against the model's unconstrained reference for both input and output channels on identical items.
If this is right
- Models respond to shorter input by generating longer outputs that raise total token spend.
- Task accuracy falls with increasing input compression strength while response length rises.
- Roughly half of correct generations under input compression no longer match the model's own unconstrained reference text.
- The cost increase and divergence hold across eight models and five datasets at multiple compression levels.
- Length-controlled re-scoring and alternative semantic measures still show the surface-text divergence.
Where Pith is reading between the lines
- Prompt engineers who shorten inputs to control cost may need to monitor total spend rather than input length alone.
- Applications that rely on consistent surface phrasing could see unexpected output changes even when the answer remains correct.
- Testing whether summarization or other compression styles avoid the length-compensation effect would clarify if the pattern is specific to grammar-free shortening.
- The same protocol could be applied to measure cost effects under chain-of-thought or few-shot prompting.
Load-bearing premise
That the short grammar-free phrasing at five reduction levels produces effects that generalize beyond the tested prompt templates and datasets without confounding from model-specific tokenization or safety filters.
What would settle it
A new run on the same models and tasks where input compression at the tested levels does not increase average response length or net realized cost.
Figures




read the original abstract
"Talk short. Drop grammar. Save token." This caveman style is widely promoted as a way to cut inference cost, but whether it actually saves anything depends on which channel (the user's prompt or the model's response) is being compressed. We present Cavewoman, a two-channel evaluation protocol that scores every generation on task accuracy, realized per-item cost, and reference-text agreement against the model's unconstrained reference. We evaluate eight models on five datasets at five reduction levels, with both channels measured on the same items. Output compression cuts realized cost on most API models (1.4-2.4x per model, up to 3x in the best case) and on all four open-weight models under public-tier pricing. Input compression has the opposite effect, a strict lose-lose: it raises net cost rather than lowering it (~1.15x on the five-benchmark mean, up to 1.8x on the worst dataset and 2.7x under stronger compression), because models compensate with longer responses even as accuracy collapses. Under the same setting, surface text diverges from the unconstrained reference: on the non-reasoning models, roughly half of all generations are correct yet their surface text no longer entails the model's own unconstrained baseline generation. The divergence survives length-controlled re-scoring, multiple-comparisons correction, and replication under complementary semantic measures. Code and data are available at https://github.com/danielle34/cavewoman.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the CAVEWOMAN two-channel evaluation protocol to measure the effects of 'caveman-style' linguistic compression (short, grammar-free phrasing at five reduction levels) on both user inputs and model outputs. Across eight models and five datasets, it reports that output compression reduces realized per-item cost (1.4-2.4x per model, up to 3x), while input compression produces a net cost increase (~1.15x mean, up to 2.7x) because models generate longer responses even as accuracy collapses; it further documents surface-text divergence from unconstrained baselines that survives length controls and multiple-comparison correction. Code and data are released.
Significance. If the directional cost asymmetry holds under broader conditions, the result is practically significant for prompt engineering and API-cost management in deployed LLMs. The two-channel design (accuracy + realized cost + reference agreement on identical items) and public release of code/data are strengths that support reproducibility and falsifiability.
major comments (3)
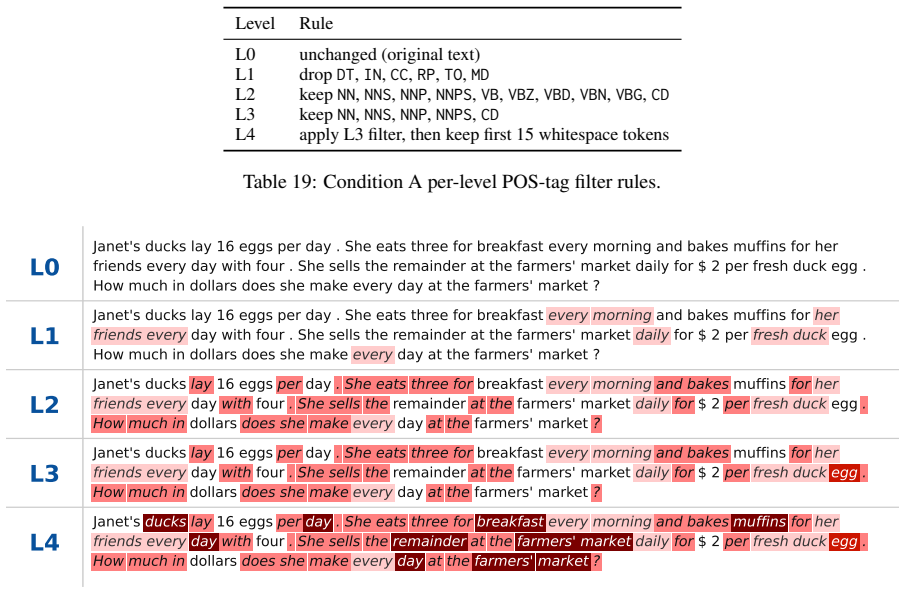
- [Abstract / Methods] The headline claim that input compression produces a strict net-cost increase (via compensatory longer outputs) is load-bearing for the central contribution, yet the abstract and available description provide no explicit definition of the five reduction levels or the exact compression procedure; without this, it is impossible to assess whether the observed 1.15–2.7× multiplier is independent of the particular prompt templates and model tokenizers (as flagged by the skeptic concern).
- [Results (divergence analysis)] The divergence result (roughly half of correct generations no longer entail the model's own unconstrained baseline) is presented as surviving length-controlled re-scoring and complementary semantic measures, but the manuscript must specify the exact entailment or semantic similarity metric and the statistical test used after multiple-comparisons correction to allow readers to judge robustness.
- [Results (cost analysis)] The cost ratios are reported separately for API models and open-weight models under public-tier pricing; the paper should include an explicit table or section showing per-model token counts (prompt + completion) before and after compression so that the 1.4–3× savings and 1.15× penalty can be directly verified rather than taken as aggregate summaries.
minor comments (2)
- [Abstract] The abstract states 'Code and data are available at https://github.com/danielle34/cavewoman' but does not indicate whether the repository contains the exact prompt templates, compression scripts, and raw per-item logs needed for replication.
- [Methods] Notation for the five reduction levels is not introduced; a short table or equation defining the levels (e.g., word-count targets or grammar-removal rules) would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us improve the clarity and verifiability of the manuscript. We address each major comment below and have incorporated revisions to strengthen the presentation of methods, divergence analysis, and cost results.
read point-by-point responses
-
Referee: [Abstract / Methods] The headline claim that input compression produces a strict net-cost increase (via compensatory longer outputs) is load-bearing for the central contribution, yet the abstract and available description provide no explicit definition of the five reduction levels or the exact compression procedure; without this, it is impossible to assess whether the observed 1.15–2.7× multiplier is independent of the particular prompt templates and model tokenizers (as flagged by the skeptic concern).
Authors: We agree that an explicit definition of the five reduction levels and the compression procedure should be provided upfront for reproducibility. The full Methods section already contains the operational definition (including the grammar-free shortening rules at each level and tokenizer-agnostic character-based reduction targets), but we have now added a concise summary of the levels and procedure to the abstract and a dedicated subsection at the start of Methods. We also include example prompts at each level and note that the procedure is applied uniformly before tokenization. This makes the reported multipliers directly interpretable with respect to the chosen templates and tokenizers. revision: yes
-
Referee: [Results (divergence analysis)] The divergence result (roughly half of correct generations no longer entail the model's own unconstrained baseline) is presented as surviving length-controlled re-scoring and complementary semantic measures, but the manuscript must specify the exact entailment or semantic similarity metric and the statistical test used after multiple-comparisons correction to allow readers to judge robustness.
Authors: We accept this request for explicit specification. The revised Results section now states that entailment was assessed via a prompted GPT-4o judge (with the exact prompt template provided in the appendix), that length-controlled re-scoring used the same judge on truncated outputs, and that the primary statistical test was a paired McNemar test with Bonferroni correction across the five datasets and eight models. We also report the complementary cosine-similarity results using sentence embeddings from a fixed model. These details were present in the supplementary material but have been moved into the main text for visibility. revision: yes
-
Referee: [Results (cost analysis)] The cost ratios are reported separately for API models and open-weight models under public-tier pricing; the paper should include an explicit table or section showing per-model token counts (prompt + completion) before and after compression so that the 1.4–3× savings and 1.15× penalty can be directly verified rather than taken as aggregate summaries.
Authors: We agree that raw per-model token counts would allow direct verification of the reported ratios. We have added a new table (Table 3) in the Results section that lists, for each of the eight models, the mean prompt tokens and completion tokens under the unconstrained condition and under each compression channel at the strongest reduction level. The table also reports the resulting per-item cost multipliers under the pricing tiers used in the paper. This table is now referenced in both the cost-analysis subsection and the abstract. revision: yes
Circularity Check
No circularity: empirical measurements independent of inputs
full rationale
The paper reports direct experimental measurements of accuracy, token counts, and cost ratios on eight models across five datasets at five compression levels, using external task labels and each model's own unconstrained generations as baselines. No equations, fitted parameters, or derivations are present; reported effects (e.g., 1.15–2.7× cost multipliers) are computed from observed outputs rather than defined by the compression procedure itself. No self-citations, ansatzes, or uniqueness theorems are invoked as load-bearing steps. The evaluation protocol is self-contained against the measured quantities.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Unconstrained model generations serve as a valid baseline for measuring both task accuracy and surface-text agreement.
Reference graph
Works this paper leans on
-
[1]
LLML ingua: Compressing Prompts for Accelerated Inference of Large Language Models
Jiang, Huiqiang and Wu, Qianhui and Lin, Chin-Yew and Yang, Yuqing and Qiu, Lili. LLML ingua: Compressing Prompts for Accelerated Inference of Large Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.825
-
[2]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Compressing context to enhance inference efficiency of large language models , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[3]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Llmlingua-2: Data distillation for efficient and faithful task-agnostic prompt compression , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[4]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Longllmlingua: Accelerating and enhancing llms in long context scenarios via prompt compression , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[5]
International Conference on Learning Representations , volume=
Recomp: Improving retrieval-augmented lms with context compression and selective augmentation , author=. International Conference on Learning Representations , volume=
-
[6]
Advances in Neural Information Processing Systems , volume=
Learning to compress prompts with gist tokens , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Adapting language models to compress contexts , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[8]
The Twelfth International Conference on Learning Representations , year=
In-context Autoencoder for Context Compression in a Large Language Model , author=. The Twelfth International Conference on Learning Representations , year=
-
[9]
Prompt compression for large language models: A survey , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[10]
Advances in Neural Information Processing Systems , volume=
Fundamental limits of prompt compression: A rate-distortion framework for black-box language models , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
, author=
Understanding aphasia. , author=. 1993 , publisher=
1993
-
[12]
Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing , pages=
Controlling output length in neural encoder-decoders , author=. Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing , pages=
2016
-
[13]
Positional Encoding to Control Output Sequence Length
Takase, Sho and Okazaki, Naoaki. Positional Encoding to Control Output Sequence Length. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v1/N19-1401
-
[14]
Proceedings of the AAAI Conference on Artificial Intelligence , number=
Hansel: Output length controlling framework for large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , number=
-
[15]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Tokenskip: Controllable chain-of-thought compression in llms , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[16]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Sketch-of-thought: Efficient llm reasoning with adaptive cognitive-inspired sketching , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[17]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Token-budget-aware llm reasoning , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[18]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Fewer is more: Boosting math reasoning with reinforced context pruning , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[19]
The Eleventh International Conference on Learning Representations , year=
Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation , author=. The Eleventh International Conference on Learning Representations , year=
-
[20]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
On faithfulness and factuality in abstractive summarization , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[21]
Transactions of the Association for Computational Linguistics , volume=
SummaC: Re-visiting NLI-based models for inconsistency detection in summarization , author=. Transactions of the Association for Computational Linguistics , volume=. 2022 , publisher=
2022
-
[22]
Advances in Neural Information Processing Systems , volume=
Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
arXiv preprint arXiv:2307.13702 , year=
Measuring faithfulness in chain-of-thought reasoning , author=. arXiv preprint arXiv:2307.13702 , year=
-
[24]
Proceedings of the 2nd Workshop on Uncertainty-Aware NLP (UncertaiNLP 2025) , pages=
Demystify Verbosity Compensation Behavior of Large Language Models , author=. Proceedings of the 2nd Workshop on Uncertainty-Aware NLP (UncertaiNLP 2025) , pages=
2025
-
[25]
arXiv preprint arXiv:2601.00624 , year=
Do Chatbot LLMs Talk Too Much? The YapBench Benchmark , author=. arXiv preprint arXiv:2601.00624 , year=
-
[26]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Same task, more tokens: the impact of input length on the reasoning performance of large language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[27]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
The impact of reasoning step length on large language models , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[28]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
An empirical study of llm reasoning ability under strict output length constraint , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[29]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Reasoning in token economies: budget-aware evaluation of LLM reasoning strategies , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[30]
Lingjiao Chen and Matei Zaharia and James Zou , journal=. Frugal. 2024 , url=
2024
-
[31]
International Conference on Learning Representations , volume=
Hybrid llm: Cost-efficient and quality-aware query routing , author=. International Conference on Learning Representations , volume=
-
[32]
Gonzalez and M Waleed Kadous and Ion Stoica , booktitle=
Isaac Ong and Amjad Almahairi and Vincent Wu and Wei-Lin Chiang and Tianhao Wu and Joseph E. Gonzalez and M Waleed Kadous and Ion Stoica , booktitle=. Route. 2025 , url=
2025
-
[33]
Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
What will it take to fix benchmarking in natural language understanding? , author=. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
2021
-
[34]
Transactions on Machine Learning Research , issn=
Holistic Evaluation of Language Models , author=. Transactions on Machine Learning Research , issn=. 2023 , url=
2023
-
[35]
Proceedings of the 1st Workshop on Natural Language Generation, Evaluation, and Metrics (GEM 2021) , pages=
The gem benchmark: Natural language generation, its evaluation and metrics , author=. Proceedings of the 1st Workshop on Natural Language Generation, Evaluation, and Metrics (GEM 2021) , pages=
2021
-
[36]
arXiv preprint arXiv:2110.14168 , year=
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
-
[37]
Boolq: Exploring the surprising difficulty of natural yes/no questions , author=. Proceedings of the 2019 conference of the north American chapter of the association for computational linguistics: Human language technologies, volume 1 (long and short papers) , pages=
2019
-
[38]
arXiv preprint arXiv:1803.05457 , year=
Think you have solved question answering? try arc, the ai2 reasoning challenge , author=. arXiv preprint arXiv:1803.05457 , year=
-
[39]
Commonsenseqa: A question answering challenge targeting commonsense knowledge , author=. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages=
2019
-
[40]
International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations , year=
-
[41]
2024 , howpublished =
Wilpel , title =. 2024 , howpublished =
2024
-
[42]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
500xcompressor: Generalized prompt compression for large language models , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[43]
arXiv preprint arXiv:2603.23525 , year=
Prompt Compression in Production Task Orchestration: A Pre-Registered Randomized Trial , author=. arXiv preprint arXiv:2603.23525 , year=
-
[44]
2021 , url=
Pengcheng He and Xiaodong Liu and Jianfeng Gao and Weizhu Chen , booktitle=. 2021 , url=
2021
-
[45]
Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks
Reimers, Nils and Gurevych, Iryna. Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1410
-
[46]
Bai, Shuai and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Song, Sibo and Dang, Kai and Wang, Peng and Wang, Shijie and Tang, Jun and Zhong, Humen and Zhu, Yuanzhi and Yang, Mingkun and Li, Zhaohai and Wan, Jianqiang and Wang, Pengfei and Ding, Wei and Fu, Zheren and Xu, Yiheng and Ye, Jiabo and Zhang, Xi and Xie, Tianbao and Cheng, Z...
-
[47]
arXiv preprint arXiv:2505.09388 , year=
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
-
[48]
2026 , howpublished =
2026
-
[49]
arXiv preprint arXiv:2501.12948 , year=
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
-
[50]
arXiv preprint arXiv:2410.21276 , year=
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
-
[51]
2025 , month = oct, note =
System Card: Claude Haiku 4.5 , author =. 2025 , month = oct, note =
2025
-
[52]
2025 , month = nov, note =
System Card: Claude Opus 4.5 , author =. 2025 , month = nov, note =
2025
-
[53]
2025 , month = sep, note =
System Card: Claude Sonnet 4.5 , author =. 2025 , month = sep, note =
2025
-
[54]
2026 , month = feb, howpublished =
2026
-
[55]
2026 , month = mar, howpublished =
Introducing. 2026 , month = mar, howpublished =
2026
-
[56]
2026 , month = sep, note =
System Card: Claude Sonnet 4.6 , author =. 2026 , month = sep, note =
2026
-
[57]
2026 , howpublished =
Caveman , author =. 2026 , howpublished =
2026
-
[58]
2026 , howpublished =
Caveman Compression , author =. 2026 , howpublished =
2026
-
[59]
Cost-Performance Optimization for Processing Low-Resource Language Tasks Using Commercial LLM s
Nag, Arijit and Mukherjee, Animesh and Ganguly, Niloy and Chakrabarti, Soumen. Cost-Performance Optimization for Processing Low-Resource Language Tasks Using Commercial LLM s. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.920
-
[60]
The 2023 Conference on Empirical Methods in Natural Language Processing , year=
Do All Languages Cost the Same? Tokenization in the Era of Commercial Language Models , author=. The 2023 Conference on Empirical Methods in Natural Language Processing , year=
2023
-
[61]
2026 , publisher=
Kimi K2.6 Technical Report , author=. 2026 , publisher=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.