Breaking the Solver Bottleneck: Training Task Generators at the Learnable Frontier
Pith reviewed 2026-06-27 10:33 UTC · model grok-4.3
The pith
PROPEL trains task generators at a target solve rate using a one-time activation probe as proxy for repeated solver evaluations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PROPEL trains a lightweight activation probe on a one-time labeled corpus of generated tasks and solver outcomes; the probe predicts target-solver pass rate from a frozen generator reference model and serves as a proxy for solve rate during generator optimization, reducing generator evaluation to a single forward pass and shifting generation toward the targeted solve rate.
What carries the argument
The activation probe that predicts target-solver pass rate from generator activations after one-time training on labeled tasks and outcomes.
If this is right
- The fraction of coding tasks at the learnable frontier rises from 10.1% to 20.0% for a 3B solver and from 5.3% to 12.6% for a 7B solver.
- For SWE the share of generations at the targeted solve rate rises from 9.8% to 19.6% for a 27B model on repositories not seen during probe or generator training.
- Generator optimization reduces to single forward passes instead of repeated solver rollouts.
- The same probe-based approach applies across math, code, and software-engineering domains at multiple model scales.
Where Pith is reading between the lines
- Continuous retraining of generators could become feasible as solvers improve without incurring proportional evaluation costs.
- The amortization technique may transfer to other settings where evaluation is expensive but a cheap proxy signal can be learned once.
- If the probe generalizes across model scales, it could support curriculum generation that tracks an improving solver over long training runs.
Load-bearing premise
The probe trained once on initial labeled data continues to predict solve rates accurately for tasks produced by the generator after optimization, including on repositories unseen during probe training.
What would settle it
Direct measurement showing that the probe's predicted pass rates diverge from actual target-solver outcomes on tasks from the optimized generator, especially on new repositories, would falsify the central claim.
Figures






read the original abstract
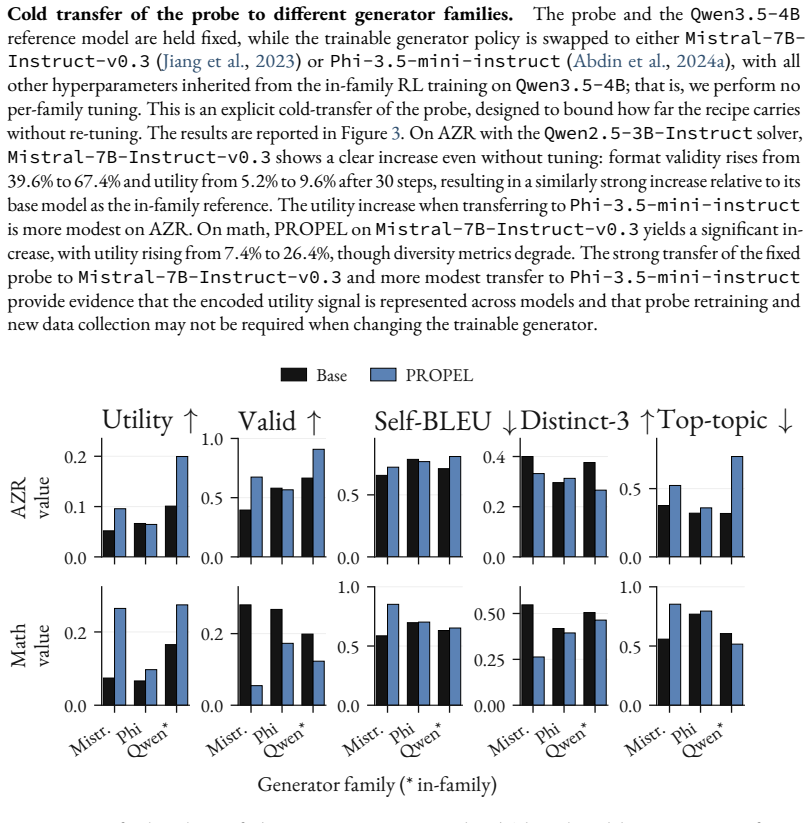
The limiting resource for training agents via reinforcement learning (RL) is increasingly frontier task supply: valid, solvable tasks just difficult enough to train the current model. As reasoning and agentic models improve, fixed task distributions saturate, while naive synthetic generation yields tasks that are trivial, impossible, or ill-posed. Training a task generator with RL to optimize validity and learnability can address this bottleneck, but direct optimization requires repeated solver rollouts per candidate. For software-engineering (SWE) tasks, a single rollout can take tens of minutes; solver-in-the-loop generator training is intractable. We introduce PROPEL, a solver-amortized framework for training task generators at the targeted solve rate. PROPEL trains a lightweight activation probe on a one-time labeled corpus of generated tasks and solver outcomes. The probe predicts target-solver pass rate from a frozen generator reference model and serves as a proxy for solve rate during generator optimization, reducing generator evaluation to a single forward pass. Across math, code, and software-engineering at multiple model scales, PROPEL shifts generation toward the targeted solve rate: for coding, tasks generated at the learnable frontier increase from $10.1\% \rightarrow 20.0\%$ for a Qwen2.5-3B-Instruct solver and from $5.3\% \rightarrow 12.6\%$ for a Qwen2.5-7B-Instruct solver. For SWE, PROPEL increases the share of generations at the targeted solve rate from $9.8\% \rightarrow 19.6\%$ for Qwen3.5-27B on repositories not seen during training of probe and generator.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PROPEL, a solver-amortized framework that trains a lightweight activation probe once on generated tasks and solver outcomes to predict target-solver pass rates from a frozen reference model; this proxy then enables RL optimization of a task generator to produce tasks at a targeted solve rate without repeated solver rollouts. It reports that the fraction of generated tasks at the learnable frontier rises from 10.1% to 20.0% (Qwen2.5-3B coding), 5.3% to 12.6% (Qwen2.5-7B coding), and 9.8% to 19.6% (Qwen3.5-27B SWE on unseen repositories).
Significance. If the probe remains accurate after generator-induced distribution shift, the method would meaningfully reduce the computational cost of frontier task generation for RL training of agentic models, particularly in high-latency domains like SWE where direct solver-in-the-loop training is intractable.
major comments (2)
- [Abstract] Abstract: the central empirical claims (10.1%→20.0%, 5.3%→12.6%, 9.8%→19.6%) are computed from the probe's predictions on the optimized generator's outputs, yet no post-optimization correlation, accuracy, or calibration statistics between probe scores and actual target-solver pass rates are reported on the final task distribution.
- [SWE evaluation] SWE evaluation paragraph: the probe is trained on a one-time corpus from seen repositories while the reported lift is measured on unseen repositories; no ablation or hold-out validation quantifies probe generalization error under the distribution shift produced by RL optimization against the probe itself.
minor comments (2)
- [Abstract] Abstract and results: reported percentages lack error bars, confidence intervals, or details on the number of generations and solver rollouts used for evaluation.
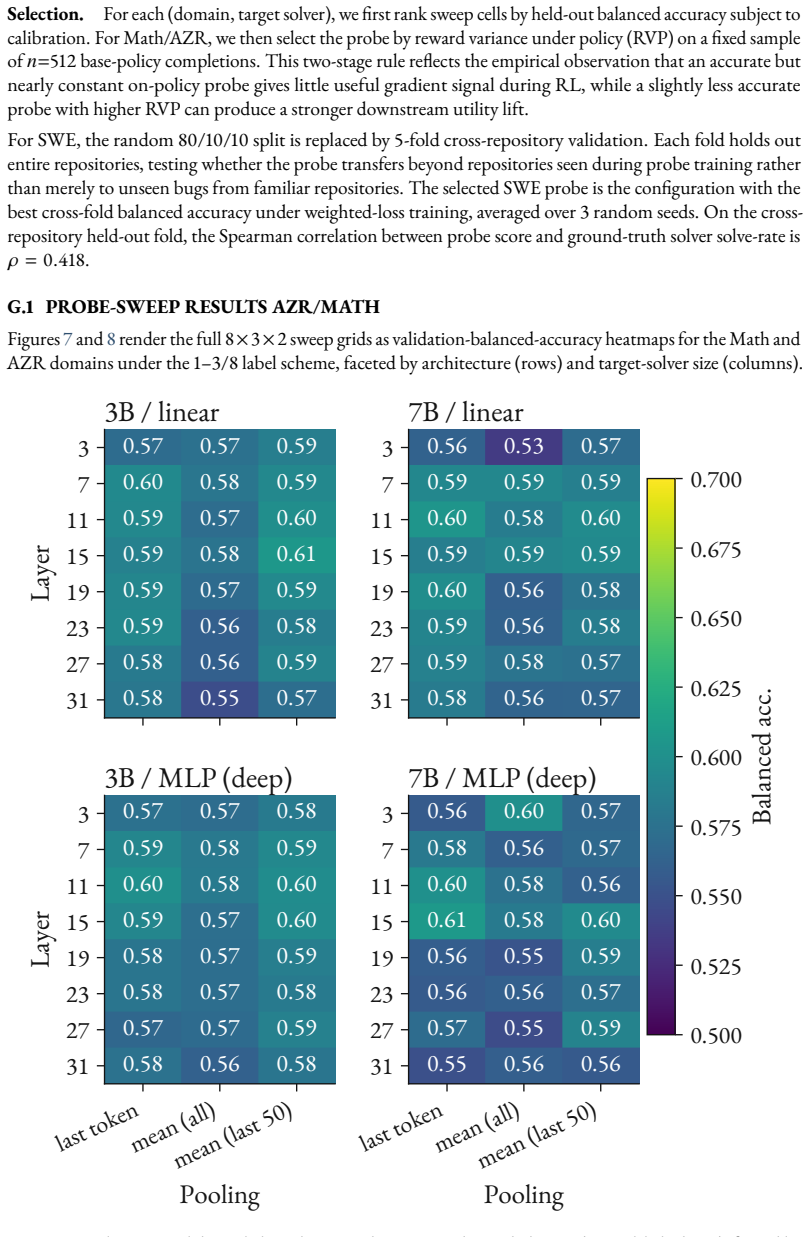
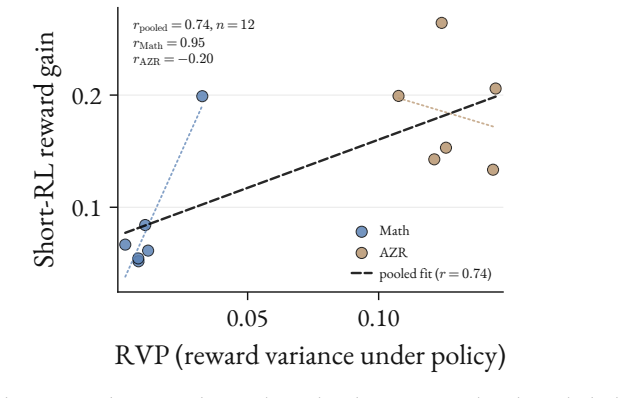
- [Methods] Notation: the precise definition of 'tasks generated at the learnable frontier' (target solve-rate bin) and how the probe threshold is chosen should be stated explicitly in the methods.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and precise comments. They correctly identify gaps in post-optimization validation of the probe. We respond to each major comment below and commit to revisions that add the requested empirical checks.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claims (10.1%→20.0%, 5.3%→12.6%, 9.8%→19.6%) are computed from the probe's predictions on the optimized generator's outputs, yet no post-optimization correlation, accuracy, or calibration statistics between probe scores and actual target-solver pass rates are reported on the final task distribution.
Authors: We agree that the reported lifts rely on probe predictions rather than direct solver measurements on the final optimized distributions. The manuscript reports probe accuracy and calibration on the initial training corpus (held-out tasks from the same generation process), but does not include a post-RL verification step that reruns the target solver on samples from the optimized generator. We will add a limited-scale validation experiment: sample 200–500 tasks from each optimized generator, obtain ground-truth solver outcomes, and report Pearson correlation, calibration plots, and accuracy metrics between probe scores and actual pass rates. This will be included in a new subsection and referenced from the abstract. revision: yes
-
Referee: [SWE evaluation] SWE evaluation paragraph: the probe is trained on a one-time corpus from seen repositories while the reported lift is measured on unseen repositories; no ablation or hold-out validation quantifies probe generalization error under the distribution shift produced by RL optimization against the probe itself.
Authors: The experiment intentionally evaluates on unseen repositories to demonstrate out-of-distribution generalization of both probe and generator. However, we did not quantify how the RL-induced shift (generator outputs optimized against the probe) affects probe accuracy on those unseen repositories. We will add an ablation that (1) generates tasks from the optimized generator on the unseen repositories, (2) obtains a modest number of actual solver labels, and (3) reports probe error, correlation, and calibration specifically on this shifted distribution. The results will be presented alongside the existing SWE numbers. revision: yes
Circularity Check
Fitted activation probe used for both RL optimization and reported share at targeted solve rate
specific steps
-
fitted input called prediction
[Abstract]
"PROPEL trains a lightweight activation probe on a one-time labeled corpus of generated tasks and solver outcomes. The probe predicts target-solver pass rate from a frozen generator reference model and serves as a proxy for solve rate during generator optimization, reducing generator evaluation to a single forward pass. [...] PROPEL shifts generation toward the targeted solve rate: for coding, tasks generated at the learnable frontier increase from 10.1% → 20.0% for a Qwen2.5-3B-Instruct solver"
The probe is fitted to the initial corpus. Generator optimization then explicitly maximizes or targets the probe's predicted pass rate. The reported percentage increase is the fraction of new tasks whose probe-predicted rate falls in the target band. This percentage therefore rises by construction once the RL objective against the fitted probe succeeds, without requiring the probe to remain calibrated on the shifted distribution.
full rationale
The paper trains the probe once on initial generated tasks plus solver labels, then uses it as the sole proxy during generator RL. The headline metric (share of generations at the targeted solve rate) is computed from the probe's predictions on the post-optimization outputs. Because the optimization objective directly targets the probe's output, any increase in that share is the expected result of successful proxy optimization rather than an independent external measurement.
Axiom & Free-Parameter Ledger
free parameters (1)
- probe parameters
axioms (1)
- domain assumption Probe predictions remain valid for tasks from the optimized generator
Reference graph
Works this paper leans on
-
[1]
2023 , url=
Efficient Memory Management for Large Language Model Serving with PagedAttention , author=. 2023 , url=
2023
-
[2]
2019 , eprint=
Jointly Measuring Diversity and Quality in Text Generation Models , author=. 2019 , eprint=
2019
-
[3]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[4]
2026 , eprint=
Beyond Benchmarks: MathArena as an Evaluation Platform for Mathematics with LLMs , author=. 2026 , eprint=
2026
-
[5]
2024 , eprint=
Phi-4 Technical Report , author=. 2024 , eprint=
2024
-
[6]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[7]
2026 , howpublished=
Anomaly , title=. 2026 , howpublished=
2026
-
[8]
The Twelfth International Conference on Learning Representations , year=
Reward Model Ensembles Help Mitigate Overoptimization , author=. The Twelfth International Conference on Learning Representations , year=
-
[9]
2026 , eprint=
Hidden Failures in Robustness: Why Supervised Uncertainty Quantification Needs Better Evaluation , author=. 2026 , eprint=
2026
-
[10]
arXiv preprint arXiv:2108.07732 , year=
Program Synthesis with Large Language Models , author=. arXiv preprint arXiv:2108.07732 , year=
-
[11]
2026 , eprint=
SWE-EVO: Benchmarking Coding Agents in Long-Horizon Software Evolution Scenarios , author=. 2026 , eprint=
2026
-
[12]
arXiv preprint arXiv:2403.07974 , year=
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code , author=. arXiv preprint arXiv:2403.07974 , year=
-
[13]
2021 , eprint=
Evaluating Large Language Models Trained on Code , author=. 2021 , eprint=
2021
-
[14]
arXiv preprint arXiv:2509.16941 , year=
Swe-bench pro: Can ai agents solve long-horizon software engineering tasks? , author=. arXiv preprint arXiv:2509.16941 , year=
-
[15]
arXiv preprint arXiv:2512.17419 , year=
SWE-Bench++: A Framework for the Scalable Generation of Software Engineering Benchmarks from Open-Source Repositories , author=. arXiv preprint arXiv:2512.17419 , year=
-
[16]
2025 , eprint=
Multi-SWE-bench: A Multilingual Benchmark for Issue Resolving , author=. 2025 , eprint=
2025
-
[17]
arXiv preprint arXiv:2601.13295 , year=
CooperBench: Why Coding Agents Cannot be Your Teammates Yet , author=. arXiv preprint arXiv:2601.13295 , year=
-
[18]
IEEE Transactions on Software Engineering , volume=
On the nature of merge conflicts: a study of 2,731 open source java projects hosted by github , author=. IEEE Transactions on Software Engineering , volume=. 2018 , publisher=
2018
-
[19]
Empirical Software Engineering , volume=
An empirical investigation into merge conflicts and their effect on software quality , author=. Empirical Software Engineering , volume=. 2020 , publisher=
2020
-
[20]
Automated Software Engineering , volume=
Indicators for merge conflicts in the wild: survey and empirical study , author=. Automated Software Engineering , volume=. 2018 , publisher=
2018
-
[21]
arXiv preprint arXiv:2409.12917 , year=
Training language models to self-correct via reinforcement learning , author=. arXiv preprint arXiv:2409.12917 , year=
-
[22]
arXiv preprint arXiv:2505.06120 , year=
Llms get lost in multi-turn conversation , author=. arXiv preprint arXiv:2505.06120 , year=
-
[23]
2025 , eprint=
BugPilot: Complex Bug Generation for Efficient Learning of SWE Skills , author=. 2025 , eprint=
2025
-
[24]
arXiv preprint arXiv:2504.07164 , year=
R2E-Gym: Procedural environments and hybrid verifiers for scaling open-weights swe agents , author=. arXiv preprint arXiv:2504.07164 , year=
-
[25]
arXiv preprint arXiv:2512.12216 , year=
Training Versatile Coding Agents in Synthetic Environments , author=. arXiv preprint arXiv:2512.12216 , year=
-
[26]
arXiv preprint arXiv:2602.16819 , year=
Hybrid-Gym: Training Coding Agents to Generalize Across Tasks , author=. arXiv preprint arXiv:2602.16819 , year=
-
[27]
arXiv preprint arXiv:2412.21139 , year=
Training software engineering agents and verifiers with swe-gym , author=. arXiv preprint arXiv:2412.21139 , year=
-
[28]
arXiv preprint arXiv:2506.09003 , year=
Swe-flow: Synthesizing software engineering data in a test-driven manner , author=. arXiv preprint arXiv:2506.09003 , year=
-
[29]
arXiv preprint arXiv:2512.18552 , year=
Toward training superintelligent software agents through self-play swe-rl , author=. arXiv preprint arXiv:2512.18552 , year=
-
[30]
arXiv preprint arXiv:2511.03928 , year=
SynQuE: Estimating Synthetic Dataset Quality Without Annotations , author=. arXiv preprint arXiv:2511.03928 , year=
-
[31]
arXiv preprint arXiv:2107.03374 , year=
Evaluating Large Language Models Trained on Code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[32]
2021 , eprint=
Measuring Mathematical Problem Solving With the MATH Dataset , author=. 2021 , eprint=
2021
-
[33]
2026 , url=
John Yang and Kilian Lieret and Carlos E Jimenez and Alexander Wettig and Kabir Khandpur and Yanzhe Zhang and Binyuan Hui and Ofir Press and Ludwig Schmidt and Diyi Yang , booktitle=. 2026 , url=
2026
-
[34]
arXiv preprint arXiv:2404.02605 , year=
Multi-SWE-bench: A Multilingual Benchmark for Issue Resolving , author=. arXiv preprint arXiv:2404.02605 , year=
-
[35]
Neural Information Processing Systems , year=
CrossCodeEval: A Diverse and Multilingual Benchmark for Cross-File Code Completion , author=. Neural Information Processing Systems , year=
-
[36]
arXiv preprint arXiv:2306.03091 , year=
RepoBench: Benchmarking Repository-Level Code Auto-Completion Systems , author=. arXiv preprint arXiv:2306.03091 , year=
-
[37]
arXiv preprint arXiv:2406.15877 , year=
BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions , author=. arXiv preprint arXiv:2406.15877 , year=
-
[38]
arXiv preprint arXiv:2410.03859 , year=
SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains? , author=. arXiv preprint arXiv:2410.03859 , year=
-
[39]
Neural Information Processing Systems , year=
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering , author=. Neural Information Processing Systems , year=
-
[40]
ACM SIGSOFT International Symposium on Software Testing and Analysis , year=
AutoCodeRover: Autonomous Program Improvement , author=. ACM SIGSOFT International Symposium on Software Testing and Analysis , year=
-
[41]
arXiv preprint arXiv:2407.16741 , year=
OpenHands: An Open Platform for AI Software Developers as Generalist Agents , author=. arXiv preprint arXiv:2407.16741 , year=
-
[42]
arXiv preprint arXiv:2312.13010 , year=
AgentCoder: Multi-Agent-based Code Generation with Iterative Testing and Optimisation , author=. arXiv preprint arXiv:2312.13010 , year=
-
[43]
International Conference on Machine Learning , year=
Executable Code Actions Elicit Better LLM Agents , author=. International Conference on Machine Learning , year=
-
[44]
arXiv preprint arXiv:2407.01489 , year=
Agentless: Demystifying LLM-based Software Engineering Agents , author=. arXiv preprint arXiv:2407.01489 , year=
-
[45]
Proceedings of the ACM on Software Engineering , year=
CodePlan: Repository-level Coding using LLMs and Planning , author=. Proceedings of the ACM on Software Engineering , year=
-
[46]
arXiv preprint arXiv:2406.04244 , year=
Benchmark Data Contamination of Large Language Models: A Survey , author=. arXiv preprint arXiv:2406.04244 , year=
-
[47]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Investigating Data Contamination in Modern Benchmarks for Large Language Models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=. 2024 , address=
2024
-
[48]
arXiv preprint arXiv:2502.14425 , year=
A Survey on Data Contamination for Large Language Models , author=. arXiv preprint arXiv:2502.14425 , year=
-
[49]
The Twelfth International Conference on Learning Representations , year=
SWE-bench: Can Language Models Resolve Real-World GitHub Issues? , author=. The Twelfth International Conference on Learning Representations , year=
-
[50]
arXiv preprint arXiv:2410.06992 , year=
SWE-Bench+: Enhanced Coding Benchmark for LLMs , author=. arXiv preprint arXiv:2410.06992 , year=
-
[51]
arXiv preprint arXiv:2505.23419 , year=
SWE-bench Goes Live! , author=. arXiv preprint arXiv:2505.23419 , year=
-
[52]
2009 IEEE 31st International Conference on Software Engineering , pages=
Predicting faults using the complexity of code changes , author=. 2009 IEEE 31st International Conference on Software Engineering , pages=. 2009 , organization=
2009
-
[53]
Empirical Software Engineering , volume=
Evaluating code complexity triggers, use of complexity measures and the influence of code complexity on maintenance time , author=. Empirical Software Engineering , volume=. 2017 , publisher=
2017
-
[54]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[55]
ArXiv , year=
LiveBench: A Challenging, Contamination-Free LLM Benchmark , author=. ArXiv , year=
-
[56]
2025 , eprint=
Agent-RLVR: Training Software Engineering Agents via Guidance and Environment Rewards , author=. 2025 , eprint=
2025
-
[57]
ArXiv , year=
SWE-Perf: Can Language Models Optimize Code Performance on Real-World Repositories? , author=. ArXiv , year=
-
[58]
ArXiv , year=
A Careful Examination of Large Language Model Performance on Grade School Arithmetic , author=. ArXiv , year=
-
[59]
arXiv preprint arXiv:2311.09783 , year=
Investigating the Impact of Data Contamination of Large Language Models in Text-to-SQL Translation , author=. arXiv preprint arXiv:2311.09783 , year=
-
[60]
2026 , eprint=
Features as Rewards: Scalable Supervision for Open-Ended Tasks via Interpretability , author=. 2026 , eprint=
2026
-
[61]
SkyRL-v0: Train Real-World Long-Horizon Agents via Reinforcement Learning , author =
-
[62]
2025 , eprint=
Absolute Zero: Reinforced Self-play Reasoning with Zero Data , author=. 2025 , eprint=
2025
-
[63]
2022 , eprint=
General Intelligence Requires Rethinking Exploration , author=. 2022 , eprint=
2022
-
[64]
2025 , eprint=
SwS: Self-aware Weakness-driven Problem Synthesis in Reinforcement Learning for LLM Reasoning , author=. 2025 , eprint=
2025
-
[65]
2021 , eprint=
Replay-Guided Adversarial Environment Design , author=. 2021 , eprint=
2021
-
[66]
2025 , eprint=
Bootstrapping Task Spaces for Self-Improvement , author=. 2025 , eprint=
2025
-
[67]
Proceedings of the 40th International Conference on Machine Learning , year =
Scaling Laws for Reward Model Overoptimization , author =. Proceedings of the 40th International Conference on Machine Learning , year =
-
[68]
2025 , eprint=
Reasoning Models Know When They're Right: Probing Hidden States for Self-Verification , author=. 2025 , eprint=
2025
-
[69]
2025 , eprint=
Mining Intrinsic Rewards from LLM Hidden States for Efficient Best-of-N Sampling , author=. 2025 , eprint=
2025
-
[70]
2026 , eprint=
Silence the Judge: Reinforcement Learning with Self-Verifier via Latent Geometric Clustering , author=. 2026 , eprint=
2026
-
[71]
2025 , eprint=
RLAD: Training LLMs to Discover Abstractions for Solving Reasoning Problems , author=. 2025 , eprint=
2025
-
[72]
2025 , eprint=
Nudging the Boundaries of LLM Reasoning , author=. 2025 , eprint=
2025
-
[73]
2024 , eprint=
OMNI-EPIC: Open-endedness via Models of human Notions of Interestingness with Environments Programmed in Code , author=. 2024 , eprint=
2024
-
[74]
2023 , eprint=
Reward-Free Curricula for Training Robust World Models , author=. 2023 , eprint=
2023
-
[75]
2025 , eprint=
KL-Regularized Reinforcement Learning is Designed to Mode Collapse , author=. 2025 , eprint=
2025
-
[76]
2023 , eprint=
Generalization through Diversity: Improving Unsupervised Environment Design , author=. 2023 , eprint=
2023
-
[77]
2025 , eprint=
No Answer Needed: Predicting LLM Answer Accuracy from Question-Only Linear Probes , author=. 2025 , eprint=
2025
-
[78]
2025 , eprint=
Temporal Predictors of Outcome in Reasoning Language Models , author=. 2025 , eprint=
2025
-
[79]
2025 , eprint=
Calibrating LLM Judges: Linear Probes for Fast and Reliable Uncertainty Estimation , author=. 2025 , eprint=
2025
-
[80]
2025 , eprint=
CLUE: Non-parametric Verification from Experience via Hidden-State Clustering , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.