dVLA-RL: Reinforcement Learning over Denoising Trajectories for Discrete Diffusion Vision-Language-Action Models
Pith reviewed 2026-06-26 08:09 UTC · model grok-4.3
The pith
By modeling denoising in discrete diffusion VLAs as a Markov Decision Process, reinforcement learning can optimize the joint probability of entire generation paths instead of intractable marginal action probabilities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
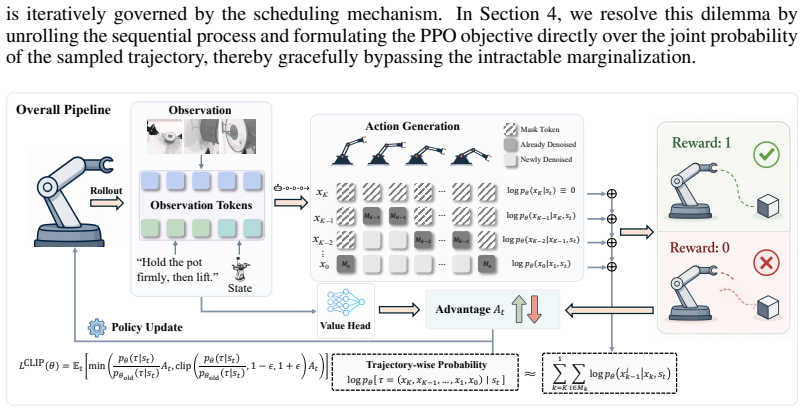
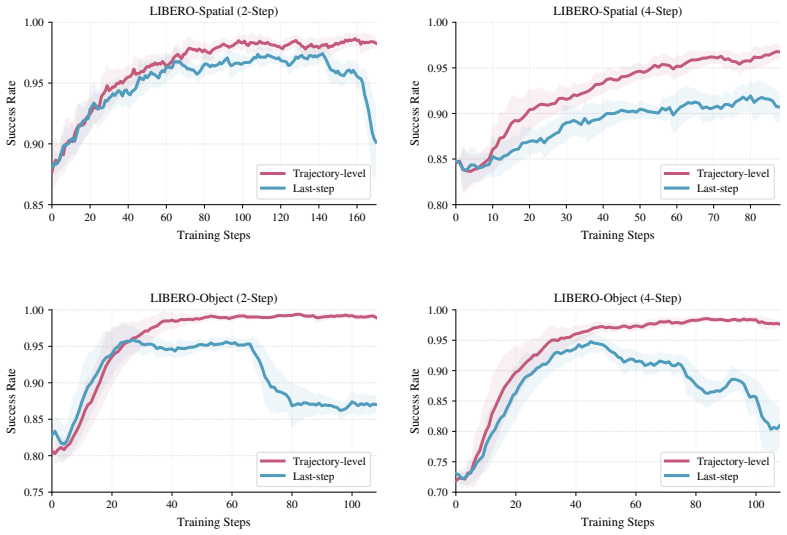
dVLA-RL shifts the RL objective from the marginal probability of the final action to the joint probability of the sampled denoising trajectory; by treating the denoising process as an MDP, this joint probability is expressed exactly as the product of the step-wise transition probabilities, yielding a unified objective that natively handles variable numbers of denoising steps.
What carries the argument
The trajectory-level objective that formulates the path probability as the product of MDP transition probabilities over the denoising sequence.
If this is right
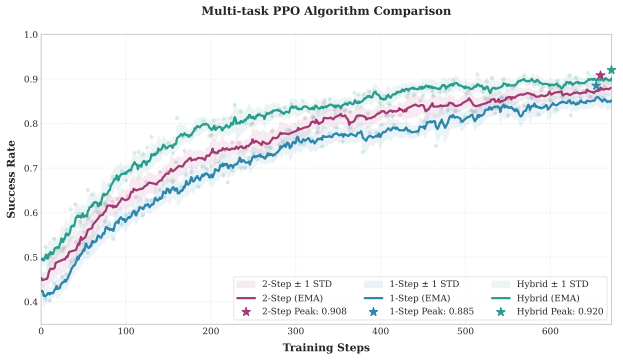
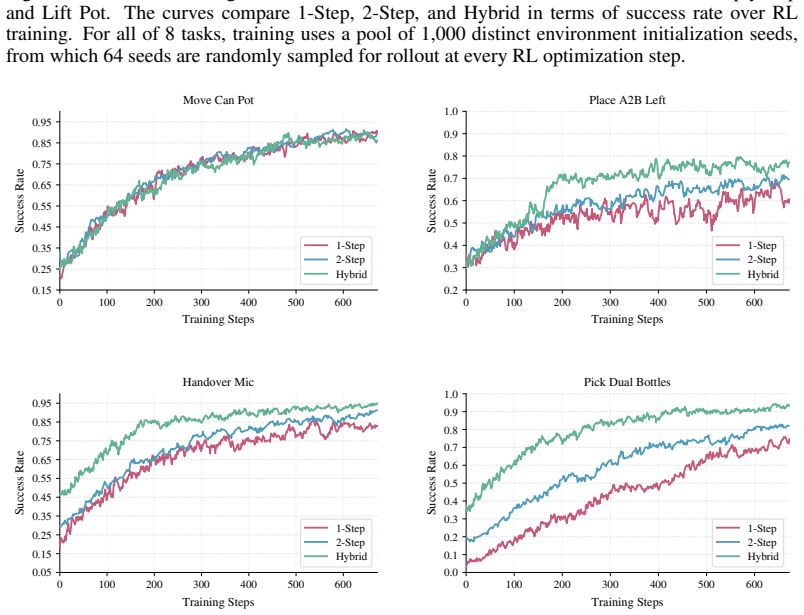
- A single training run can accommodate tasks that require different numbers of denoising steps without changing the loss formulation.
- Success rate reaches 99.7 percent on the LIBERO benchmark suite.
- The same method produces a 30.6 percent absolute gain over its SFT baseline on RoboTwin 2.0 while remaining competitive with strong world-action-model approaches.
Where Pith is reading between the lines
- The same MDP framing could be applied to any iterative generative process whose marginal likelihood is hard to evaluate, not only discrete diffusion VLAs.
- Adaptive step scheduling learned from task complexity might translate into variable compute budgets during online robot deployment.
- If the path probability correlates with downstream task success, similar trajectory objectives could be tested on continuous diffusion or flow-matching policies in robotics.
Load-bearing premise
The joint probability along the sampled denoising trajectory serves as an effective surrogate for the true marginal action probability when the latter is intractable.
What would settle it
A controlled experiment in which policies trained with the trajectory objective show no improvement, or degrade, relative to the SFT baseline when both are evaluated on the same held-out tasks with identical inference budgets.
Figures



read the original abstract
Vision-Language-Action (VLA) models have established a powerful paradigm for generalist robotic manipulation by grounding control into the semantic reasoning of VLMs. Prevailing architectures typically model actions continuously via diffusion or flow processes, or discretely through either autoregressive generation or parallel decoding. Recently, Discrete Diffusion VLAs (dVLAs) have emerged as a distinct alternative, unifying vision, language, and action into a single discrete token space via masked generative modeling. While combining iterative refinement with unified representations, its training has thus far been restricted to Supervised Fine-Tuning (SFT), leaving the potential of Reinforcement Learning (RL) for further policy refinement largely unexplored. A fundamental challenge in RL for dVLAs is that the marginal probability of the final action generated by dVLAs remains intractable. To solve this problem, we propose \textbf{dVLA-RL}, shifting the learning objective from the marginal action probability to the joint probability of the sampled generation path. Specifically, by modeling the denoising process as a Markov Decision Process (MDP), we mathematically formulate this path probability as a product of step-wise transitions. This trajectory-level objective provides a unified formulation that natively accommodates variable denoising steps. Leveraging this intrinsic fexibility, we introduce a unified step scheduling approach for complex multi-task learning, tailoring denoising steps to specific task complexities to maximize both success rates and computational effciency. Extensive evaluations demonstrate that our approach achieves a success rate of \textbf{99.7\%} on LIBERO. Furthermore, it establishes strong VLA-based results on RoboTwin 2.0 by delivering a \textbf{30.6\%} improvement over the SFT baseline, remaining competitive with strong World-Action Model baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes dVLA-RL for discrete diffusion Vision-Language-Action models. It reformulates the RL objective from the intractable marginal probability of the final action to the joint probability of the full denoising trajectory by modeling the denoising process as an MDP whose transitions are optimized directly; this is claimed to natively support variable denoising step counts. A unified step-scheduling method is introduced for multi-task settings. The work reports a 99.7% success rate on LIBERO and a 30.6% improvement over the SFT baseline on RoboTwin 2.0.
Significance. If the trajectory-level objective can be shown to be a valid, unbiased surrogate for the marginal action policy and the performance numbers hold under standard controls, the approach would provide a practical route to apply RL to masked discrete diffusion VLAs, extending beyond SFT and potentially improving sample efficiency and task success in robotic manipulation.
major comments (2)
- [Abstract] Abstract: the central claim that 'modeling the denoising process as a Markov Decision Process' and optimizing the joint trajectory probability yields an effective RL surrogate for the marginal action distribution is stated without any derivation, equivalence proof, or bias analysis. No equations are supplied showing the product of step-wise transitions, the resulting policy gradient, or why credit assignment to intermediate denoising steps improves (rather than biases) the final-action marginal when step counts vary across tasks.
- [Abstract] Abstract: the reported 99.7% success rate on LIBERO and 30.6% improvement on RoboTwin 2.0 are presented without error bars, number of evaluation seeds, ablation on the step-scheduling component, or comparison against an RL baseline that directly optimizes a tractable marginal, rendering the quantitative claims impossible to assess for statistical reliability or attribution to the proposed objective.
minor comments (1)
- [Abstract] Abstract: typographical errors ('fexibility', 'effciency') should be corrected.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the manuscript. We address each major comment point-by-point below, clarifying the content of the full paper and noting revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'modeling the denoising process as a Markov Decision Process' and optimizing the joint trajectory probability yields an effective RL surrogate for the marginal action distribution is stated without any derivation, equivalence proof, or bias analysis. No equations are supplied showing the product of step-wise transitions, the resulting policy gradient, or why credit assignment to intermediate denoising steps improves (rather than biases) the final-action marginal when step counts vary across tasks.
Authors: The abstract is intentionally concise, but Section 3.2 of the manuscript provides the full derivation: the denoising process is formalized as an MDP whose states are partially denoised token sequences, actions are per-step token predictions, and the joint trajectory probability is the product of the step-wise transition probabilities under the discrete diffusion kernel. The policy gradient is derived directly on this trajectory objective. Because the MDP exactly replicates the generative process, the trajectory objective is an unbiased surrogate for the marginal action probability; variable step counts are accommodated without bias by the unified scheduling that preserves the same effective generative distribution. We will revise the abstract to include a parenthetical reference to Section 3 for the derivation and equivalence. revision: partial
-
Referee: [Abstract] Abstract: the reported 99.7% success rate on LIBERO and 30.6% improvement on RoboTwin 2.0 are presented without error bars, number of evaluation seeds, ablation on the step-scheduling component, or comparison against an RL baseline that directly optimizes a tractable marginal, rendering the quantitative claims impossible to assess for statistical reliability or attribution to the proposed objective.
Authors: The abstract omits these details due to length constraints, but the experimental sections report results averaged over multiple seeds with standard deviations, include ablations isolating the step-scheduling component, and explain that no tractable marginal RL baseline exists for discrete diffusion VLAs (the intractability of the marginal is the central motivation stated in Section 3.1). We will revise the abstract to note that the reported figures are means over multiple evaluation seeds, with full statistical details and ablations provided in the experiments. revision: yes
Circularity Check
No circularity; new surrogate objective defined by construction but independent of fitted inputs
full rationale
The paper defines a new learning objective by explicitly modeling the denoising process as an MDP and setting the trajectory probability equal to the product of its step-wise transition probabilities. This is presented as a deliberate modeling shift to bypass the intractable marginal, not as a derivation that reduces to prior fitted quantities or self-citations. No load-bearing uniqueness theorems, ansatzes smuggled via citation, or renamings of known results appear in the provided text. The formulation is self-contained as a choice of surrogate; empirical gains are reported as outcomes of optimizing this defined objective rather than tautological re-expressions of the inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- task-specific denoising step counts
axioms (2)
- domain assumption The denoising process of dVLAs can be modeled as a Markov Decision Process
- domain assumption The joint probability of the generation path equals the product of individual step transitions
Reference graph
Works this paper leans on
-
[2]
URLhttps: //arxiv.org/abs/2107.03006. Hongzhe Bi, Hengkai Tan, Shenghao Xie, Zeyuan Wang, Shuhe Huang, Haitian Liu, Ruowen Zhao, Yao Feng, Chendong Xiang, Yinze Rong, et al. Motus: A unified latent action world model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 35101–35113,
-
[3]
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, brian ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Allen Z. Ren,...
-
[4]
doi: 10.15607/RSS.2025. XXI.014. Jiayi Chen, Wenxuan Song, Pengxiang Ding, Ziyang Zhou, Han Zhao, Feilong Tang, Donglin Wang, and Haoang Li. Unified diffusion VLA: Vision-language-action model via joint discrete denos- ing diffusion process. InThe F ourteenth International Conference on Learning Representations, 2026a. URLhttps://openreview.net/forum?id=U...
-
[5]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-Tuning Vision-Language-Action Models: Opti- mizing Speed and Success. InProceedings of Robotics: Science and Systems, LosAngeles, CA, USA, June 2025a. doi: 10.15607/RSS.2025.XXI.017. Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan P Foster, P...
-
[6]
URLhttps://openreview.net/forum?id=wPEIStHxYH. Haozhan Li, Yuxin Zuo, Jiale Yu, Yuhao Zhang, Yang Zhaohui, Kaiyan Zhang, Xuekai Zhu, Yuchen Zhang, Tianxing Chen, Ganqu Cui, Dehui Wang, Dingxiang Luo, Yuchen Fan, Youbang Sun, Jia Zeng, Jiangmiao Pang, Shanghang Zhang, Yu Wang, Yao Mu, Bowen Zhou, and Ning Ding. SimpleVLA-RL: Scaling VLA training via reinfo...
-
[7]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, qiang liu, Yuke Zhu, and Peter Stone
URLhttps://arxiv.org/abs/ 2508.20072. Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, qiang liu, Yuke Zhu, and Peter Stone. LIBERO: Benchmarking knowledge transfer for lifelong robot learning. InThirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track,
-
[8]
URLhttps: //openreview.net/forum?id=xzEtNSuDJk. Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang. Flow-grpo: Training flow matching models via online rl.Ad- vances in neural information processing systems, 38:40783–40818, 2026a. Yang Liu, Pengxiang Ding, Tengyue Jiang, Xudong Wang, Wenxuan ...
-
[9]
URLhttps://arxiv.org/abs/2505.18719. Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji- Rong Wen, and Chongxuan Li. Large language diffusion models.Advances in Neural Information Processing Systems, 38:50608–50646,
-
[11]
Shuhan Tan, Kairan Dou, Yue Zhao, and Philipp Kr ¨ahenb¨uhl
URLhttp://arxiv.org/abs/ 1707.06347. Shuhan Tan, Kairan Dou, Yue Zhao, and Philipp Kr ¨ahenb¨uhl. Interactive post-training for vision- language-action models,
-
[12]
Yinjie Wang, Ling Yang, Bowen Li, Ye Tian, Ke Shen, and Mengdi Wang
URLhttps://arxiv.org/abs/2505.17016. Yinjie Wang, Ling Yang, Bowen Li, Ye Tian, Ke Shen, and Mengdi Wang. Revolutionizing rein- forcement learning framework for diffusion large language models. InThe F ourteenth Interna- tional Conference on Learning Representations,
-
[14]
URLhttps://doi.org/10.48550/ arXiv.2509.25681. Charles Xu, Jost Tobias Springenberg, Michael Equi, Ali Amin, Adnan Esmail, Sergey Levine, and Liyiming Ke. Rl token: Bootstrapping online rl with vision-language-action models,
-
[15]
Ling Yang, Ye Tian, Bowen Li, Xinchen Zhang, Ke Shen, Yunhai Tong, and Mengdi Wang
URL https://arxiv.org/abs/2604.23073. Ling Yang, Ye Tian, Bowen Li, Xinchen Zhang, Ke Shen, Yunhai Tong, and Mengdi Wang. Mmada: Multimodal large diffusion language models.Advances in Neural Information Processing Sys- tems, 38:138867–138907,
-
[16]
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong
URL https://arxiv.org/abs/2603.17240. Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. Dream 7b: Diffusion large language models.arXiv preprint arXiv:2508.15487,
-
[17]
Tianyuan Yuan, Zibin Dong, Yicheng Liu, and Hang Zhao
URLhttps: //arxiv.org/abs/2509.15965. Tianyuan Yuan, Zibin Dong, Yicheng Liu, and Hang Zhao. Fast-wam: Do world action models need test-time future imagination?,
-
[18]
URLhttps://arxiv.org/abs/2603.16666. Hongzhi Zang, Mingjie Wei, Si Xu, Yongji Wu, Zhen Guo, Yuanqing Wang, Hao Lin, Peihong Wang, Liangzhi Shi, Yuqing Xie, Zhexuan Xu, Zhihao Liu, Kang Chen, Wenhao Tang, Quanlu Zhang, Weinan Zhang, Chao Yu, and Yu Wang. Rlinf-vla: A unified and efficient framework for reinforcement learning of vision-language-action models,
-
[19]
Mu Zhang, Tianren Ma, Yunfan Liu, Kun Hu, and Qixiang Ye
URLhttps://arxiv.org/ abs/2510.06710. Mu Zhang, Tianren Ma, Yunfan Liu, Kun Hu, and Qixiang Ye. Rebrl: Reinforcing discrete visual diffusion models with rebalanced timestep credits. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 43135–43144, June
-
[20]
URLhttps://proceedings.neurips.cc/paper_files/paper/2025/ file/52190a0362148d179f1cbd9080956872-Paper-Conference.pdf. A PSEUDOCODE OFUDVLA-RL Algorithm 1Unified Discrete VLA Reinforcement Learning (dVLA-RL) 1:Input:Pre-trained discrete diffusion VLA modelπ θ, Value networkV ϕ, EnvironmentE 2:Hyperparameters:Denoising stepsK, PPO clip ratioϵ, PPO epochsE, ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.