A Practical Recipe Towards Improving Sim-and-Real Correlation for VLA Evaluation
Pith reviewed 2026-06-27 13:05 UTC · model grok-4.3
The pith
Systematic experiments show that only certain simulation signals reliably predict real-world VLA policy performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
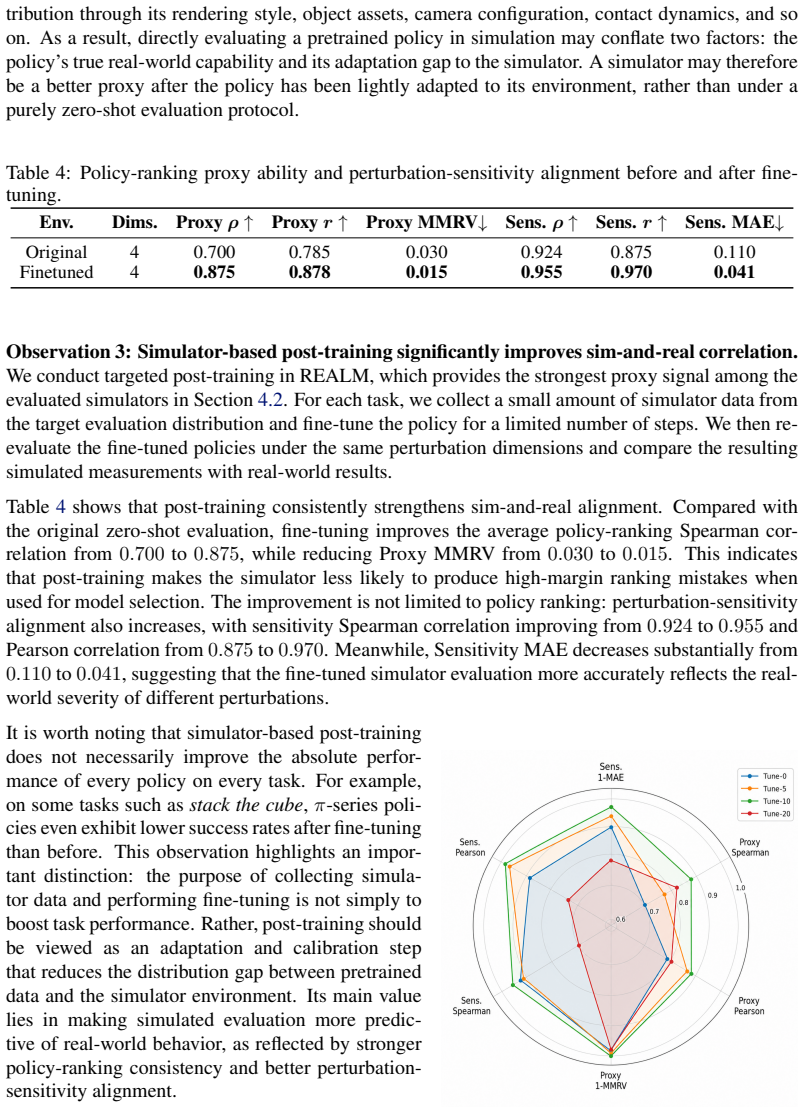
By measuring policy ranking consistency, performance correlation, and perturbation-wise failure patterns, the study characterizes the limitations of existing simulators and identifies simulation signals more aligned with real-world deployment. It shows that simulator-based finetuning can be beneficial under certain conditions and that the amount of post-training data influences sim-and-real alignment.
What carries the argument
Measurement of sim-and-real correlation via ranking consistency, performance correlation, and failure pattern matching across platforms, policies, tasks, and perturbations.
If this is right
- Simulator designers can focus on signals that better match real perturbation responses to improve correlation.
- Users should apply simulator-based finetuning only when it leads to better real-world outcomes.
- The volume of post-training real data impacts how well simulation predicts real performance.
- Simulation is more useful for VLA policy development when aligned signals are used.
Where Pith is reading between the lines
- Applying the same correlation analysis to non-VLA policies could reveal domain-specific differences.
- Future simulators might be designed around the identified aligned signals from the start.
- Practitioners could use this framework to decide the mix of sim and real evaluation in their pipeline.
Load-bearing premise
The selected simulation platforms, VLA policies, tasks, and perturbation factors are representative enough for the observed patterns to apply more broadly.
What would settle it
A follow-up study using different simulators, policies, or tasks that finds opposite patterns in which signals align or when finetuning helps.
Figures



read the original abstract
Simulation has become an essential tool for evaluating and improving vision-language-action (VLA) policies, offering scalable, reproducible, and controllable alternatives to costly real-world robot evaluation. Recent simulation benchmarks have made substantial progress on realism and diversity, yet these platforms have not been widely adopted as reliable proxies for real-world policy evaluation. In this work, we investigate this issue through the lens of sim-and-real correlation. We conduct a systematic study across multiple simulation platforms, VLA policies, tasks, and perturbation factors, measuring whether simulated evaluation preserves real-world conclusions in terms of policy ranking consistency, performance correlation, and perturbation-wise failure patterns. This analysis allows us to characterize the limitations of existing simulators and identify what kinds of simulation signals are more aligned with real-world deployment. We further examine how users should exploit simulation for policy improvement, including when simulator-based finetuning is beneficial and how the amount of post-training data affects sim-and-real alignment. Overall, our work provides a unified framework for measuring, interpreting, and improving the usefulness of simulation for VLA policies, offering guidance both for simulator designers and for practitioners who use simulation as part of the policy development pipeline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to investigate sim-and-real correlation for vision-language-action (VLA) policies via a systematic empirical study across multiple simulation platforms, VLA policies, tasks, and perturbation factors. It measures policy ranking consistency, performance correlation, and perturbation-wise failure patterns to characterize simulator limitations, identify aligned simulation signals, and provide guidance on exploiting simulation for policy improvement (including when simulator-based finetuning is beneficial and how post-training data volume affects alignment). The work positions itself as offering a unified framework for measuring, interpreting, and improving simulation usefulness for VLA policies.
Significance. If the empirical measurements and derived recommendations hold under broader sampling, the work could supply a practical, reusable methodology for simulator evaluation in robotics, helping practitioners decide when and how to use simulation in VLA development pipelines. The explicit focus on ranking consistency and failure patterns, rather than raw performance, is a constructive angle. However, the provided abstract supplies no quantitative results, statistical tests, or enumeration of the chosen platforms/policies/tasks/perturbations, so the actual strength of the conclusions cannot yet be assessed.
major comments (2)
- [Abstract] Abstract: The central claim that the study 'characterizes the limitations of existing simulators' and 'provides a unified framework' for sim-and-real alignment rests on the assumption that the selected platforms, policies, tasks, and perturbation factors are representative. The abstract asserts a 'systematic study across multiple' items but gives no enumeration, sampling justification, or diversity metrics; if the set is small or convenience-sampled, the observed correlations and recommendations on post-training data volume will not reliably generalize.
- [Abstract] Abstract: The description of the experimental design and intended measurements supplies no quantitative results, statistical tests, or details on how correlation, ranking consistency, and failure patterns were computed. Without these, it is impossible to judge whether the data support the stated conclusions about simulator alignment and finetuning guidance.
Simulated Author's Rebuttal
We thank the referee for their review and for highlighting the need for greater specificity in the abstract. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the study 'characterizes the limitations of existing simulators' and 'provides a unified framework' for sim-and-real alignment rests on the assumption that the selected platforms, policies, tasks, and perturbation factors are representative. The abstract asserts a 'systematic study across multiple' items but gives no enumeration, sampling justification, or diversity metrics; if the set is small or convenience-sampled, the observed correlations and recommendations on post-training data volume will not reliably generalize.
Authors: The abstract is intentionally concise. The full manuscript (Section 3) enumerates the platforms (Isaac Sim, Habitat, MuJoCo), policies (OpenVLA, RT-2, Octo), tasks (pick-and-place, drawer opening, etc.), and perturbation factors, with explicit sampling rationale based on coverage of physics engines, rendering pipelines, and task diversity. Diversity metrics and selection criteria are reported in Section 3.1 to support representativeness; the observed correlations are therefore tied to this documented scope rather than an unstated convenience sample. revision: no
-
Referee: [Abstract] Abstract: The description of the experimental design and intended measurements supplies no quantitative results, statistical tests, or details on how correlation, ranking consistency, and failure patterns were computed. Without these, it is impossible to judge whether the data support the stated conclusions about simulator alignment and finetuning guidance.
Authors: Abstracts conventionally omit numerical results and computation details. Section 3.3 defines the metrics (Spearman rank correlation, Kendall tau for ranking consistency, per-perturbation failure overlap) and Section 4 reports the quantitative values together with statistical tests (p-values, confidence intervals). Full protocols, including how each metric is computed from raw success rates, appear in the experimental setup and will be accompanied by released code. revision: no
Circularity Check
No circularity: empirical measurement study with no derivations or self-referential predictions
full rationale
The paper is an empirical study measuring sim-real correlations across platforms, policies, tasks, and perturbations. No equations, fitted parameters renamed as predictions, self-citations as load-bearing premises, or ansatzes are present in the provided text. The central claims rest on experimental observations rather than any derivation chain that reduces to its inputs by construction. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, et al. RT-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv:2212.06817, 2022
Pith/arXiv arXiv 2022
-
[2]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. arXiv preprint arXiv:2307.15818, 2023
Pith/arXiv arXiv 2023
-
[3]
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, O. Mees, et al. Octo: An open-source generalist robot policy. arXiv preprint arXiv:2405.12213, 2024
Pith/arXiv arXiv 2024
-
[4]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, et al. OpenVLA: An open- source vision-language-action model. arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[5]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, et al.π 0: A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[6]
R. Sapkota, Y . Cao, K. I. Roumeliotis, and M. Karkee. Vision-language-action models: Con- cepts, progress, applications and challenges. arXiv preprint arXiv:2505.04769, 2025
arXiv 2025
-
[7]
Open x-embodiment: Robotic learning datasets and RT-X models
Open X-Embodiment Collaboration. Open x-embodiment: Robotic learning datasets and RT-X models. arXiv preprint arXiv:2310.08864, 2023
Pith/arXiv arXiv 2023
-
[8]
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, et al. DROID: A large-scale in-the-wild robot manipulation dataset. arXiv preprint arXiv:2403.12945, 2024
Pith/arXiv arXiv 2024
-
[9]
Z. Zhou, P. Atreya, Y . L. Tan, K. Pertsch, and S. Levine. AutoEval: Autonomous evaluation of generalist robot manipulation policies in the real world. arXiv preprint arXiv:2503.24278, 2025
arXiv 2025
- [11]
-
[12]
Y . Zhu, J. Wong, A. Mandlekar, R. Mart ´ın-Mart´ın, A. Joshi, S. Nasiriany, and Y . Zhu. ro- bosuite: A modular simulation framework and benchmark for robot learning. arXiv preprint arXiv:2009.12293, 2020
Pith/arXiv arXiv 2009
-
[13]
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parikh, A. Lo, A. Joshi, A. Mandlekar, and Y . Zhu. RoboCasa: Large-scale simulation of everyday tasks for generalist robots. arXiv preprint arXiv:2406.02523, 2024
Pith/arXiv arXiv 2024
- [14]
-
[15]
J. Gu, F. Xiang, X. Li, Z. Ling, X. Liu, T. Mu, Y . Tang, S. Tao, X. Wei, Y . Yao, X. Yuan, P. Xie, Z. Huang, R. Chen, and H. Su. ManiSkill2: A unified benchmark for generalizable manipulation skills. In International Conference on Learning Representations, 2023
2023
-
[16]
James, Z
S. James, Z. Ma, D. R. Arrojo, and A. J. Davison. RLBench: The robot learning benchmark & learning environment. IEEE Robotics and Automation Letters, 5(2):3019–3026, 2020
2020
-
[17]
X. Li, K. Hsu, J. Gu, K. Pertsch, O. Mees, H. R. Walke, C. Fu, I. Lunawat, I. Sieh, S. Kir- mani, S. Levine, J. Wu, C. Finn, H. Su, Q. Vuong, and T. Xiao. Evaluating real-world robot manipulation policies in simulation. arXiv preprint arXiv:2405.05941, 2024. 9
Pith/arXiv arXiv 2024
-
[18]
Kadian, J
A. Kadian, J. Truong, A. Gokaslan, A. Clegg, E. Wijmans, S. Lee, M. Savva, S. Chernova, and D. Batra. Sim2real predictivity: Does evaluation in simulation predict real-world performance? IEEE Robotics and Automation Letters, 5(4):6670–6677, 2020
2020
-
[19]
Y . Chebotar, A. Handa, V . Makoviychuk, M. Macklin, J. Issac, N. Ratliff, and D. Fox. Closing the sim-to-real loop: Adapting simulation randomization with real world experience. arXiv preprint arXiv:1810.05687, 2018
Pith/arXiv arXiv 2018
-
[20]
M. Sedlacek, P. Yefanov, G. Ponimatkin, J. Bardhan, S. Pilc, M. Fourmy, E. Kazakos, C. G. M. Snoek, J. Sivic, and V . Petrik. REALM: A real-to-sim validated benchmark for generalization in robotic manipulation. arXiv preprint arXiv:2512.19562, 2025
arXiv 2025
-
[21]
B. Zhang, J. Li, J. Shen, Y . Cai, Y . Zhang, Y . Chen, J. Dai, J. Ji, and Y . Yang. VLA-Arena: An open-source framework for benchmarking vision-language-action models. arXiv preprint arXiv:2512.22539, 2025
Pith/arXiv arXiv 2025
-
[22]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success. arXiv preprint arXiv:2502.19645, 2025
Pith/arXiv arXiv 2025
-
[24]
O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard. CALVIN: A benchmark for language- conditioned policy learning for long-horizon robot manipulation tasks. IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022
2022
-
[25]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. LIBERO: Benchmarking knowledge transfer for lifelong robot learning. In Advances in Neural Information Processing Systems, 2023
2023
-
[26]
Shridhar, J
M. Shridhar, J. Thomason, D. Gordon, Y . Bisk, W. Han, R. Mottaghi, L. Zettlemoyer, and D. Fox. Alfred: A benchmark for interpreting grounded instructions for everyday tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020
2020
-
[27]
A. Szot, A. Clegg, E. Undersander, E. Wijmans, Y . Zhao, J. Turner, N. Maestre, M. Mukadam, D. Chaplot, O. Maksymets, A. Gokaslan, V . V ondrus, S. Dharur, F. Meier, W. Galuba, A. Chang, Z. Kira, V . Koltun, J. Malik, M. Savva, and D. Batra. Habitat 2.0: Training home assistants to rearrange their habitat. In Advances in Neural Information Processing Syst...
2021
-
[28]
C. Li, R. Zhang, J. Wong, C. Gokmen, S. Srivastava, R. Mart ´ın-Mart´ın, C. Wang, G. Levine, W. Ai, B. Martinez, et al. BEHA VIOR-1k: A human-centered, embodied ai benchmark with 1,000 everyday activities and realistic simulation. arXiv preprint arXiv:2403.09227, 2024
Pith/arXiv arXiv 2024
-
[29]
H. Fu, W. Xu, R. Ye, H. Xue, Z. Yu, T. Tang, Y . Li, W. Du, J. Zhang, and C. Lu. RFUniverse: A multiphysics simulation platform for embodied ai. arXiv preprint arXiv:2202.00199, 2022
arXiv 2022
-
[30]
R. Gong, J. Huang, Y . Zhao, H. Geng, X. Gao, Q. Wu, W. Ai, Z. Zhou, D. Terzopoulos, S.-C. Zhu, B. Jia, and S. Huang. ARNOLD: A benchmark for language-grounded task learning with continuous states in realistic 3d scenes. arXiv preprint arXiv:2304.04321, 2023
arXiv 2023
-
[31]
S. Nasiriany, S. Nasiriany, A. Maddukuri, and Y . Zhu. Robocasa365: A large-scale simulation framework for training and benchmarking generalist robots. arXiv preprint arXiv:2603.04356, 2026
arXiv 2026
-
[32]
J.-W. Choi, Y . Yoon, H. Ong, J. Kim, and M. Jang. LoTa-Bench: Benchmarking language- oriented task planners for embodied agents. In International Conference on Learning Representations, 2024. 10
2024
-
[33]
X. Liu, T. Zhang, Y . Gu, I. L. Iong, Y . Xu, X. Song, S. Zhang, H. Lai, X. Liu, H. Zhao, et al. VisualAgentBench: Towards large multimodal models as visual foundation agents.arXiv preprint arXiv:2408.06327, 2024
arXiv 2024
- [34]
-
[35]
R. Yang, H. Chen, J. Zhang, M. Zhao, C. Qian, K. Wang, Q. Wang, T. V . Koripella, M. Mova- hedi, M. Li, H. Ji, H. Zhang, and T. Zhang. EmbodiedBench: Comprehensive benchmark- ing multi-modal large language models for vision-driven embodied agents. In International Conference on Machine Learning, 2025
2025
- [36]
-
[37]
E. Zhao, V . Raval, H. Zhang, J. Mao, Z. Shangguan, S. Nikolaidis, Y . Wang, and D. Seita. ManipBench: Benchmarking vision-language models for low-level robot manipulation. In Conference on Robot Learning, 2025
2025
-
[39]
E. Xing, A. Gupta, S. Powers, and V . Dean. Kitchenshift: Evaluating zero-shot generaliza- tion of imitation-based policy learning under domain shifts. In NeurIPS 2021 Workshop on Distribution Shifts: Connecting Methods and Applications, 2021
2021
-
[40]
Y . Tian, Y . Yang, Y . Xie, Z. Cai, X. Shi, N. Gao, H. Liu, X. Jiang, Z. Qiu, F. Yuan, Y . Li, P. Wang, J. Cai, J. Zeng, H. Dong, and J. Pang. InternData-A1: Pioneering high-fidelity synthetic data for pre-training generalist policy. arXiv preprint arXiv:2511.16651, 2025
arXiv 2025
- [41]
-
[42]
Ayub and A
A. Ayub and A. R. Wagner. F-siol-310: A robotic dataset and benchmark for few-shot incre- mental object learning. In 2021 IEEE International Conference on Robotics and Automation (ICRA), pages 13496–13502. IEEE, 2021
2021
-
[43]
Manivasagam, S
S. Manivasagam, S. Wang, K. Wong, W. Zeng, M. Sazanovich, S. Tan, B. Yang, W.-C. Ma, and R. Urtasun. Lidarsim: Realistic lidar simulation by leveraging the real world. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11167–11176, 2020
2020
-
[44]
Mittal, C
M. Mittal, C. Yu, Q. Yu, J. Liu, N. Rudin, D. Hoeller, J. L. Yuan, R. Singh, Y . Guo, H. Mazhar, et al. Orbit: A unified simulation framework for interactive robot learning environments.IEEE Robotics and Automation Letters, 8(6):3740–3747, 2023
2023
-
[45]
A. Maddukuri, Z. Jiang, L. Y . Chen, S. Nasiriany, Y . Xie, Y . Fang, W. Huang, Z. Wang, Z. Xu, N. Chernyadev, et al. Sim-and-real co-training: A simple recipe for vision-based robotic ma- nipulation. arXiv preprint arXiv:2503.24361, 2025
arXiv 2025
- [46]
-
[47]
J. Abou-Chakra, L. Sun, K. Rana, B. May, K. Schmeckpeper, N. Suenderhauf, M. V . Minniti, and L. Herlant. Real-is-sim: Bridging the sim-to-real gap with a dynamic digital twin. arXiv preprint arXiv:2504.03597, 2025
arXiv 2025
-
[48]
J. Barreiros, A. Beaulieu, A. Bhat, R. Cory, E. Cousineau, H. Dai, C.-H. Fang, K. Hashimoto, M. Z. Irshad, et al. A careful examination of large behavior models for multitask dexterous manipulation. arXiv preprint arXiv:2507.05331, 2025
Pith/arXiv arXiv 2025
-
[49]
Agarwal, M
R. Agarwal, M. Schwarzer, P. S. Castro, A. Courville, and M. G. Bellemare. Deep rein- forcement learning at the edge of the statistical precipice. In Advances in Neural Information Processing Systems, 2021
2021
-
[50]
J. Bjorck et al. Gr00t n1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[51]
Z. Fu, T. Z. Zhao, and C. Finn. Mobile aloha: Learning bimanual mobile manipulation with low-cost whole-body teleoperation. arXiv preprint arXiv:2401.02117, 2024. 12 A Visualization of aligned tasks We visualize the nine aligned tasks in Figure 5. Due to the limited availability of corresponding training data, two rotation tasks are not evaluated in SIMPL...
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.