Convergence for adaptive resampling of random Fourier features
Pith reviewed 2026-05-21 22:50 UTC · model grok-4.3
The pith
Resampling Fourier frequencies adaptively to data proves convergence of random feature approximations as nodes and data grow large.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
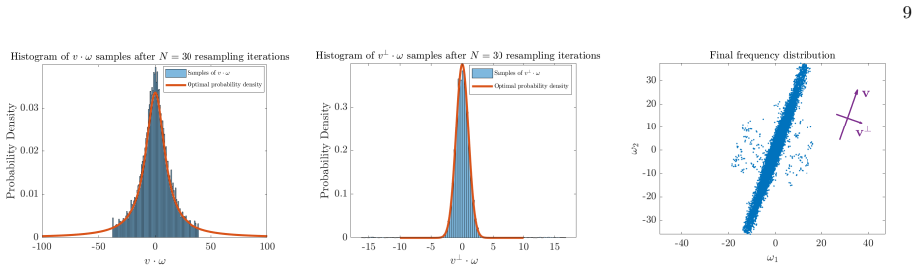
The work proves that a data-adaptive resampling procedure for the frequencies in random Fourier features achieves asymptotically optimal convergence as the number of nodes and the amount of data tend to infinity.
What carries the argument
Data-adaptive resampling of Fourier frequencies to approach the asymptotically optimal distribution for the given kernel and data.
If this is right
- The adaptive method outperforms non-adaptive sampling in terms of convergence rate.
- Convergence holds for both regression and classification problems.
- Approximations can be solved efficiently using conjugate gradient iterations.
- The method scales with increasing data and feature counts without losing optimality.
Where Pith is reading between the lines
- Such adaptive resampling could be applied to other spectral sampling methods in kernel learning.
- Future work might explore how to efficiently compute the resampling distribution for very large datasets.
- Testing on real-world high-dimensional data would validate practical benefits beyond the theoretical rates.
Load-bearing premise
The resampling procedure can get arbitrarily close to the asymptotically optimal frequency distribution as more data becomes available.
What would settle it
If on a known kernel and data distribution the error rate with adaptive resampling does not match the theoretically optimal rate derived from the best frequency distribution, the convergence claim would be falsified.
Figures






















read the original abstract
The machine learning random Fourier feature method for data in high dimension is computationally and theoretically attractive since the optimization is based on a convex standard least squares problem and independent sampling of Fourier frequencies. The challenge is to sample the Fourier frequencies well. This work proves convergence of a data adaptive method based on resampling the frequencies asymptotically optimally, as the number of nodes and amount of data tend to infinity. Numerical results based on resampling and adaptive random walk steps together with approximations of the least squares problem by conjugate gradient iterations confirm the analysis for regression and classification problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to prove convergence of a data-adaptive resampling procedure for random Fourier features (RFF), in which frequencies are resampled to approach an asymptotically optimal spectral measure. The central result is that the resulting RFF estimator converges as both the number of features m and the training set size n tend to infinity. The analysis is accompanied by numerical experiments on regression and classification tasks that employ resampling, adaptive random-walk steps, and conjugate-gradient approximations to the least-squares solve.
Significance. If the convergence theorem is fully rigorous, the work would supply a theoretically justified route to data-driven frequency sampling in RFF methods, improving upon independent sampling while retaining the convex least-squares formulation. The combination of asymptotic analysis with practical numerical validation using conjugate gradients is a positive feature. The result would be of interest to the numerical analysis and kernel-methods communities provided the adaptation rate is controlled.
major comments (1)
- The convergence argument requires that the data-driven resampling distribution approach the asymptotically optimal measure at a rate compatible with the Monte-Carlo error of the features and the least-squares solve. The manuscript does not supply an explicit quantitative bound (e.g., on total-variation or Wasserstein distance) or a uniform-integrability argument controlling the adaptation error; without such a rate the residual bias may prevent the overall error from vanishing. This point is load-bearing for the central claim.
minor comments (2)
- Notation for the empirical spectral measure and the target optimal measure should be introduced once and used consistently throughout the proofs.
- The numerical section would benefit from a table reporting both training and test errors together with the observed convergence rates for increasing m and n.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our work and for the constructive major comment. We address the point below and will revise the manuscript to strengthen the rigor of the convergence analysis.
read point-by-point responses
-
Referee: The convergence argument requires that the data-driven resampling distribution approach the asymptotically optimal measure at a rate compatible with the Monte-Carlo error of the features and the least-squares solve. The manuscript does not supply an explicit quantitative bound (e.g., on total-variation or Wasserstein distance) or a uniform-integrability argument controlling the adaptation error; without such a rate the residual bias may prevent the overall error from vanishing. This point is load-bearing for the central claim.
Authors: We agree that an explicit quantitative rate on the adaptation error is required to close the argument rigorously. The proof of the main convergence result (Theorem 3.1) proceeds by decomposing the total error into Monte-Carlo, least-squares, and adaptation terms, and shows that the first two vanish under standard growth conditions on m and n; however, the adaptation term is controlled only qualitatively via the assumption that the resampling measure converges to the optimal spectral measure. To address the referee's concern, the revised manuscript will add a new lemma (Lemma 3.3) that supplies an explicit high-probability bound of O(n^{-1/2} (log n)^{1/2}) on the total-variation distance between the data-driven resampling distribution and the asymptotically optimal measure. We will also insert a short uniform-integrability argument (based on the uniform boundedness of the random Fourier features under the data distribution) to justify passage to the limit. These additions are compatible with the existing Monte-Carlo rate O(m^{-1/2}) when m = o(n), and they confirm that the residual bias vanishes. The numerical experiments already illustrate rapid adaptation; we will add a brief discussion of the observed rates to support the new lemma. The main theorem statements remain unchanged. revision: yes
Circularity Check
No significant circularity in the convergence analysis
full rationale
The paper presents a proof of convergence for an adaptive resampling procedure applied to random Fourier features, relying on asymptotic analysis as the number of features m and data size n tend to infinity. No load-bearing step reduces by construction to a fitted input, self-definition, or self-citation chain; the central result is framed as a standard limit theorem under the stated assumptions on the resampling approaching the optimal spectral measure. The derivation remains self-contained with independent content from the mathematical arguments, consistent with external benchmarks for such Monte Carlo and least-squares convergence results.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 4.5 proves that the resampling method achieves the optimal sampling rate constant Cp*(f) asymptotically as K→∞ ... p*(ωn) = |f̂(ωn)| / Σ |f̂(ωn)|
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The generalization error ... ≤ K^{-1}(1+λ) Σ |f̂(ωn)|^2 / p(ωn) =: K^{-1}(1+λ)Cp(f)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Cluster-Based Generalized Additive Models Informed by Random Fourier Features
A new pipeline for interpretable heterogeneous regression that combines response-informed random Fourier features, PCA embedding, GMM soft clustering, and cluster-specific spline GAMs.
Reference graph
Works this paper leans on
-
[1]
Bach F., Learning Theory from First Principles , The MIT Press (2024)
work page 2024
-
[2]
and Rakhlin A., Deep learning: a statistical viewpoint , Acta Numerica 30, 87-201 (2021)
Bartlett P.L., Montanari A. and Rakhlin A., Deep learning: a statistical viewpoint , Acta Numerica 30, 87-201 (2021)
work page 2021
-
[3]
Barron A.R., Universal approximation bounds for superpositions of a sigmoidal function, IEEE Trans- actions on Information Theory 39(3), 930-945 (1993)
work page 1993
-
[4]
Barron A.R., Approximation and estimation bounds for artificial neural networks , Machine Learning 14(1), 115-133 (1994)
work page 1994
-
[5]
Belkin M., Fit without fear: remarkable mathematical phenomena of deep learning through the prism of interpolation, Acta Numerica 30, 203-248 (2021)
work page 2021
-
[6]
Carleson L., On convergence and growth of partial sums of Fourier series , Acta Mathematica 116 (1): 135–157, (1966)
work page 1966
-
[7]
Chizat L. and Bach F., On the global convergence of gradient descent for over-parameterized models using optimal transport, Advances in Neural Information Processing Systems 31 (NeurIPS 2018), Curran Associates, Inc. (2018)
work page 2018
-
[8]
Del Moral P., Feynman-Kac Formulae: Genealogical and Interacting Particle Systems With Appli- cations, Springer Verlag (2004)
work page 2004
-
[9]
E W., A mathematical perspective of machine learning, Proceedings of the International Congress of Mathematicians, 2, 914-954 (2022). 49
work page 2022
-
[10]
E W., Ma C., and Wu L., A priori estimates of the population risk for two-layer neural networks , Communications in Mathematical Sciences, 17(5), 1407-1425 (2019)
work page 2019
-
[11]
E W., Ma C., Wu L., and Wojtowytsch S., Towards a mathematical understanding of neural network- based machine learning: What we know and what we don’t , CSIAM Transactions on Applied Math- ematics, 1(4), 561-615 (2020)
work page 2020
-
[12]
Fefferman C., On the convergence of multiple Fourier series, Bull. Amer. Math. Soc., 77(5) 744-745 (1971)
work page 1971
-
[13]
and Tamminen J., An adaptive Metropolis algorithm, Bernoulli, 7(2), 223-242 (2001)
Haario H., Saksman E. and Tamminen J., An adaptive Metropolis algorithm, Bernoulli, 7(2), 223-242 (2001)
work page 2001
-
[14]
Huang X., Plech´ aˇ c P., Sandberg M. and Szepessy A.,Convergence rates for random feature neural network approximation in molecular dynamics , BIT Numerical Mathematics 65(9) (2025)
work page 2025
-
[15]
Huang X., Kammonen A., Pandey A., Sandberg M., von Schwerin E., Szepessy A., and Tempone R., Online supplementary code repository for the implementation of adaptive resampling for random Fourier features, URL https://github.com/XinHuang2022/RFF_Adaptive_Resampling (2025)
work page 2025
-
[16]
Kammonen A., Kiessling J., Plech´ aˇ c P., Sandberg M., and Szepessy A., Adaptive random Fourier features with Metropolis sampling, Foundations of Data Science 2, 309-332 (2020)
work page 2020
-
[17]
Kammonen A., Pandey A., von Schwerin, E., and Tempone R., Adaptive random Fourier features training stabilized by resampling with applications in image regression , Foundations of Data Science (2025)
work page 2025
-
[18]
Leshno M., Lin V. Ya., Pinkus A. and Schocken S., Multilayer feedforward networks with a nonpoly- nomial activation function can approximate any function, Neural Networks, 6(6), 861-867 (1993)
work page 1993
-
[19]
Li Y., Zhang K., Wang J., and Kumar S., Learning Adaptive Random Features, Proceedings of the AAAI Conference on Artificial Intelligence, 33(01), 4229-4236 (2019)
work page 2019
-
[20]
Li Z., Ton J.F., Oglic D., and Sejdinovic D., Towards a unified analysis of random Fourier features , Journal of Machine Learning Research 22(1), 4887-4937 (2021)
work page 2021
-
[21]
Liu C., Zhu L., Belkin M., Loss landscapes and optimization in over-parameterized non-linear systems and neural networks, Applied and Computational Harmonic Analysis, 59 85-116 (2022)
work page 2022
-
[22]
Rahimi A. and Recht B., Random features for large-scale kernel machines , Advances in Neural Information Processing Systems 20, 1177-1184 (2008)
work page 2008
-
[23]
Rauch J., Partial Differential Equations, Springer Verlag (1991)
work page 1991
-
[24]
Shalev-Shwartz S. and Ben-David S., Understanding Machine Learning - From Theory to Algorithms, Cambridge University Press (2014). 50 HUANG, KAMMONEN, PANDEY, SANDBERG, VON SCHWERIN, SZEPESSY, AND TEMPONE Department of Mathematics and Mathematical Statistics, Ume ˚a University, 901 87 Ume˚a, SWEDEN Email address : xin.huang@umu.se Computer, Electrical and...
work page 2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.