Plans Don't Persist: Why Context Management Is Load Bearing for LLM Agents
Pith reviewed 2026-06-26 08:25 UTC · model grok-4.3
The pith
LLM agents do not keep plans as persistent internal state and instead need the plan text to stay in context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
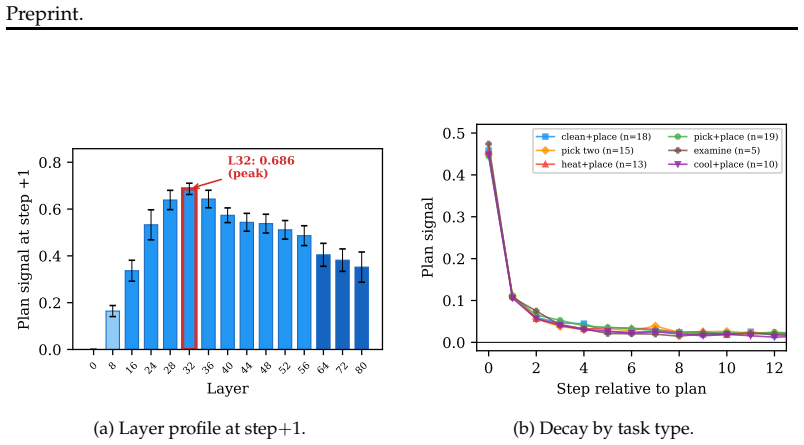
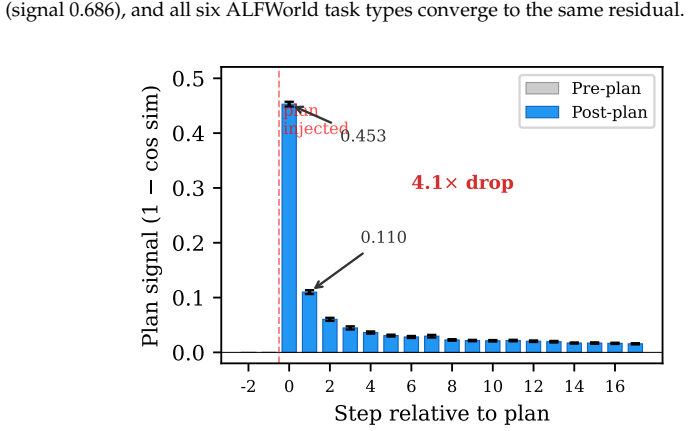
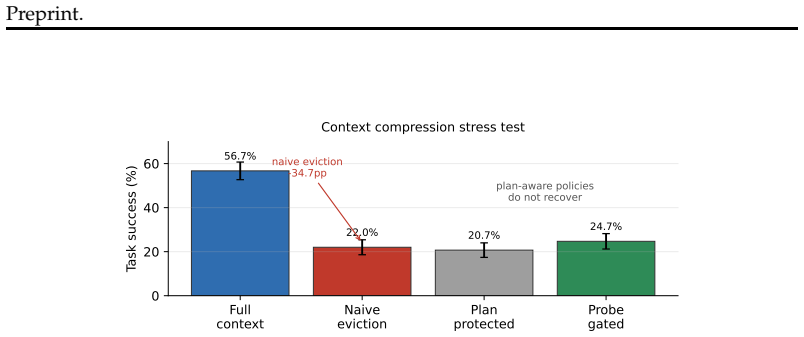
Standard LLM agents do not carry plans forward as persistent state, and instead depend on the plan remaining in context. Replay pairing on Llama-3.1-70B shows plan signal in hidden states reaching 0.453 one step after the plan then dropping 4.1 times in a single action-observation step. A compression stress test finds that naive plan eviction lowers ALFWorld success by 34.7 percentage points. Reasoning models require strict stripping of prior thinking traces to isolate plan effects, recovering over 150 percent of the signal while leaving non-reasoning models largely unchanged.
What carries the argument
Replay pairing, a diagnostic that runs matched trajectories differing only in whether the plan appears in history and measures cosine distance between the resulting hidden states.
If this is right
- Plan signal decays rapidly after the plan is written, so context windows must retain it for continued use.
- Naive eviction of plans from context produces large drops in downstream task success.
- Reasoning models need strict removal of prior thinking traces before plan effects can be measured accurately.
- Probe transfer between models is only partial, indicating plan information may be encoded in different directions.
Where Pith is reading between the lines
- Long-horizon agent systems will need explicit detection and protection of plan-like information during compression.
- The observed decay suggests plans act more like temporary prompts than stored knowledge the model can recall unaided.
- Extending the same pairing method to other critical information such as goals or constraints could reveal similar context dependence.
Load-bearing premise
The cosine distance between hidden states isolates the plan's own contribution rather than other differences between the two runs.
What would settle it
Hidden-state cosine distances between the paired runs stay large across many subsequent steps even when the plan has been removed from context.
Figures


read the original abstract
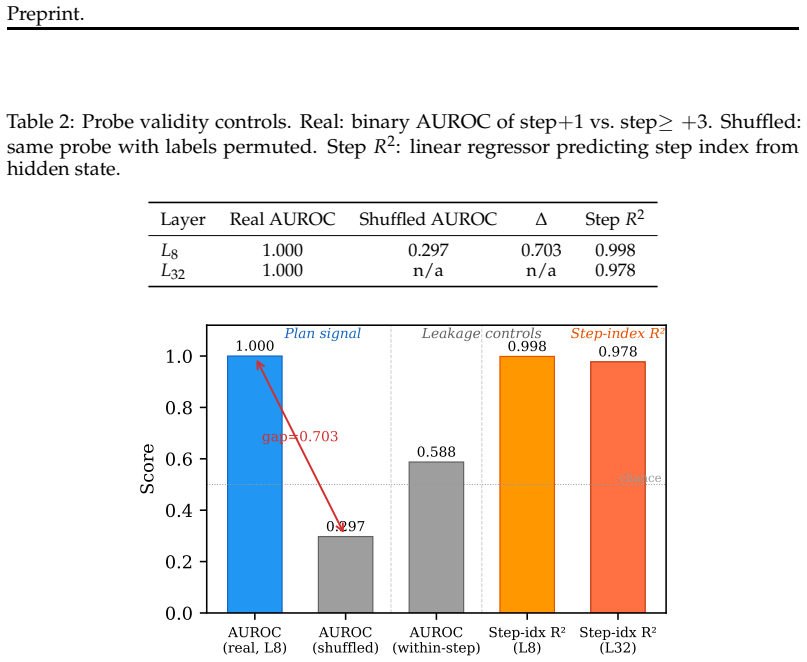
Long-horizon agents depend on context management: systems compress, summarize, and evict old tokens so tasks can continue beyond finite windows. That is safe only when dropped information is no longer needed or has been internalized. Plans are the stress case: they are written early, used for many steps, and first to be evicted. We introduce replay pairing, a diagnostic that runs the same trajectory with and without the plan in history and measures hidden-state cosine distance. On Llama-3.1-70B, plan signal spikes to 0.453 one step after the plan, then falls 4.1x in a single action-observation step; HotpotQA falls 12.4x. This is evidence that standard LLM agents do not carry plans forward as persistent state, and instead depend on the plan remaining in context. A layer-L32 probe detects this decay as a diagnostic, not as proof that it reads plan content itself. Reasoning models add a measurement confound: their `<think>` traces re-derive plan content, so standard stripping leaves plan evidence in the stripped condition. We name this the reasoning-trace confound and fix it with strict stripping, which removes prior `<think>` blocks from the stripped run only. It recovers +163% of the step+1 signal in-sample and +153% held out, while not meaningfully changing non-reasoning Llama (+4.8%). On DeepSeek-R1-Distill-Llama-70B, a Llama-trained probe transfers at AUROC 0.748 (p=6e-4), while R1-specific probes reach 1.000, suggesting R1 encodes plan signal in a different hidden-state direction. Finally, a compression stress test shows the practical cost: naive plan eviction cuts ALFWorld success by 34.7pp, while probe-gated re-surfacing does not recover it. The contribution is a measurement and stress-test framework showing that agent-critical information can be context-resident rather than persistent. Context management is load bearing, but plan protection alone is not enough.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that plans in standard LLM agents do not persist as internal state but remain context-resident, demonstrated via replay pairing: identical trajectories run with/without the initial plan yield hidden-state cosine distance that spikes to 0.453 one step after the plan then decays 4.1× (Llama-3.1-70B) or 12.4× (HotpotQA) after a single action-observation step. A layer-L32 probe serves as a diagnostic; reasoning models introduce a trace confound addressed by strict stripping (+153% held-out recovery); probe transfer reaches AUROC 0.748 on DeepSeek-R1-Distill-Llama-70B; and a compression stress test shows naive plan eviction drops ALFWorld success by 34.7pp while probe-gated resurfacing does not recover it. The contribution is a measurement framework showing context management is load-bearing for agent-critical information.
Significance. If the central measurements hold, the work supplies a concrete diagnostic (replay pairing + probe) for distinguishing context-resident versus internalized information in LLM agents, with direct implications for compression and eviction policies. Credit is due for the use of held-out data, external task-success metrics (ALFWorld), the explicit handling of the reasoning-trace confound, and the probe-transfer result across model families. These elements make the empirical case stronger than purely in-sample observations.
major comments (2)
- [replay pairing setup] Replay pairing (abstract and §3): the claim that cosine-distance decay demonstrates plan non-persistence specifically requires that the measured difference isolates the plan token sequence rather than any early-context token. No control is reported that replaces the plan prefix with a matched-length non-plan sequence while keeping subsequent tokens identical; without it the observed 0.453 spike and rapid fall after one step remains consistent with generic early-context overwriting.
- [compression stress test] Compression stress test (abstract): the reported 34.7pp ALFWorld drop under naive eviction is load-bearing for the practical claim, yet the manuscript provides no variance, number of episodes, or statistical test; this weakens the assertion that probe-gated resurfacing “does not recover it” relative to the baseline.
minor comments (2)
- [probe interpretation] The abstract states the probe is “a diagnostic, not … proof that it reads plan content itself,” but the main text should explicitly restate this caveat when interpreting the L32 probe and transfer AUROC numbers.
- [methods] Notation for the strict-stripping procedure and the reasoning-trace confound should be introduced with a short equation or pseudocode block to make the +163% / +153% recovery numbers easier to replicate.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the strengths of the measurement framework, including the use of held-out data, external metrics, and handling of the reasoning-trace confound. We address each major comment below, indicating revisions where appropriate.
read point-by-point responses
-
Referee: [replay pairing setup] Replay pairing (abstract and §3): the claim that cosine-distance decay demonstrates plan non-persistence specifically requires that the measured difference isolates the plan token sequence rather than any early-context token. No control is reported that replaces the plan prefix with a matched-length non-plan sequence while keeping subsequent tokens identical; without it the observed 0.453 spike and rapid fall after one step remains consistent with generic early-context overwriting.
Authors: We agree that a matched-length non-plan prefix control would better isolate plan-specific effects from generic early-context overwriting. The current design holds all post-prefix tokens fixed, so observed differences are due to the prefix, but this does not rule out that any distinctive early prefix could produce similar dynamics. In the revised manuscript we will add results from such a control (neutral instructions and random token sequences of matched length) and report the resulting cosine-distance trajectories to quantify specificity. revision: yes
-
Referee: [compression stress test] Compression stress test (abstract): the reported 34.7pp ALFWorld drop under naive eviction is load-bearing for the practical claim, yet the manuscript provides no variance, number of episodes, or statistical test; this weakens the assertion that probe-gated resurfacing “does not recover it” relative to the baseline.
Authors: We agree that variance, episode count, and statistical testing are required to support the practical claim. The ALFWorld results were obtained on a fixed evaluation set; the revised manuscript will report the exact number of episodes, per-condition success rates with standard deviation, and an appropriate statistical comparison (e.g., McNemar’s test) between naive eviction and the probe-gated condition. revision: yes
Circularity Check
No significant circularity; empirical measurements are self-contained
full rationale
The paper's central claims rest on replay-pairing experiments that directly compare hidden-state cosine distances and probe AUROCs between matched trajectories (with/without plan prefix) on held-out data and external task success rates (ALFWorld). No equations, fitted parameters, or self-citations are used to derive the reported decay factors (4.1×, 12.4×) or the +163% recovery; these are raw measurements. The reasoning-trace confound is addressed by an explicit control (strict stripping) whose effect is quantified on the same data. No load-bearing step reduces to a definition, prior self-citation, or ansatz smuggled in; the work is a measurement framework against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
replay pairing
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Nora Belrose, Zach Furman, Logan Smith, Danny Halawi, Igor Ostrovsky, Lev McKinney, Stella Biderman, and Jacob Steinhardt. Eliciting latent predictions from transformers with the tuned lens.arXiv preprint arXiv:2303.08112,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Discovering Latent Knowledge in Language Models Without Supervision
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Discovering latent knowledge in language models without supervision.arXiv preprint arXiv:2212.03827,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Tracing the traces: Latent temporal signals for efficient and accurate reasoning
Chen et al. Tracing the traces: Latent temporal signals for efficient and accurate reasoning. arXiv preprint arXiv:2510.10494,
-
[4]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aieleen Letman, Akhil Mathur, Alan Schelten, Amy Yang, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Inner Monologue: Embodied Reasoning through Planning with Language Models
9 Preprint. Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, et al. Inner monologue: Embodied reasoning through planning with language models.arXiv preprint arXiv:2207.05608,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
LLMs Get Lost In Multi-Turn Conversation
Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, and Jennifer Neville. LLMs get lost in multi-turn conversation.arXiv preprint arXiv:2505.06120,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Liu et al. Reasoning models know when they’re right: Probing hidden states for self- verification.arXiv preprint arXiv:2504.05419,
-
[8]
Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets.arXiv preprint arXiv:2310.06824,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
When Agents Disagree With Themselves: Measuring Behavioral Consistency in LLM -Based Agents
Aman Mehta. When agents disagree with themselves: Measuring behavioral consistency in LLM-based agents.arXiv preprint arXiv:2602.11619, 2026a. Aman Mehta. Consistency amplifies: How behavioral variance shapes agent accuracy.arXiv preprint arXiv:2603.25764, 2026b. nostalgebraist. interpreting GPT: the logit lens. LessWrong,
-
[10]
Qwen Team. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. ALFWorld: Aligning text and embodied environments for interac- tive learning.arXiv preprint arXiv:2010.03768,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[12]
Alessandro Stolfo et al. Improving instruction-following in language models through activation steering.arXiv preprint arXiv:2410.12877,
-
[13]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, David Udell, Gavin Leech, Ulisse Mini, and Leela Castricato. Steering language models with activation engineering.arXiv preprint arXiv:2308.10248,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Wang et al. From reasoning to answer: Empirical, attention-based and mechanistic insights into distilled deepseek r1 models.arXiv preprint arXiv:2509.23676, 2025a. Wang et al. Reasonif: Large reasoning models fail to follow instructions during reasoning. arXiv preprint arXiv:2510.15211, 2025b. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian ...
-
[15]
Wu et al. Effectively controlling reasoning models through thinking intervention.arXiv preprint arXiv:2503.24370,
-
[16]
Retrieval head mechanistically explains long-context factuality.arXiv preprint arXiv:2404.15574,
Wenhao Wu et al. Retrieval head mechanistically explains long-context factuality.arXiv preprint arXiv:2404.15574,
-
[17]
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering
ICLR 2025 Oral. 10 Preprint. Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W Cohen, Ruslan Salakhutdi- nov, and Christopher D Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering.arXiv preprint arXiv:1809.09600,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to AI transparency.arXiv preprint arXiv:2310.01405,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
A Implementation Details Models, decoding, infrastructure.Llama-3.1-70B-Instruct (Grattafiori et al., 2024), Llama- 3.1-8B-Instruct, and DeepSeek-R1-Distill-Llama-70B (DeepSeek-AI,
2024
-
[21]
Strong-form dilution is ruled out
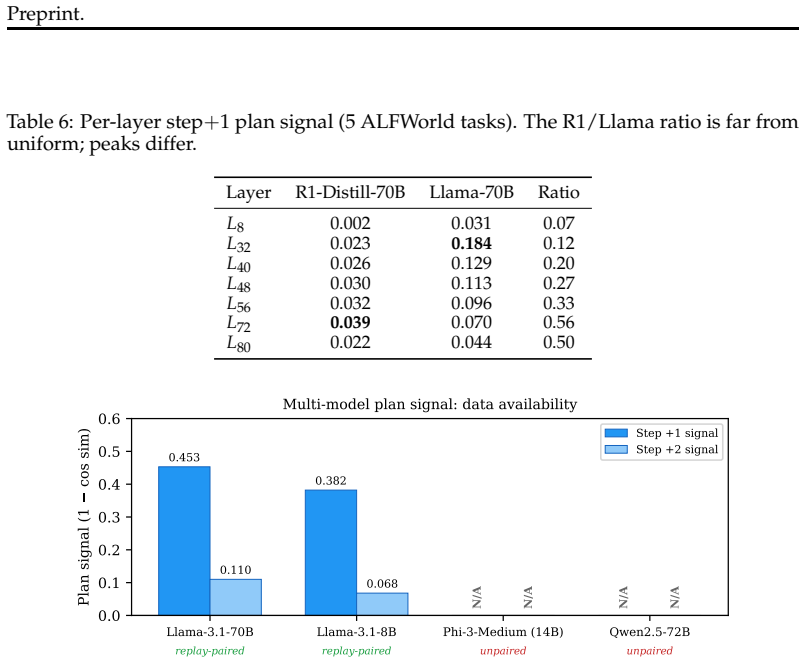
The R1/Llama ratio varies 4.4× across depth and the two models peak at different absolute layers (L72 for R1, L32 for Llama). Strong-form dilution is ruled out. A.7 Cross-Scale Multi-Model Panel Table 7 collects the cross-model decay results referenced in Section 6; Figure 7 summarizes them graphically. A.8 Intervention Sweeps and Head-Level Analysis Cont...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.