KinematicRL: A Sim-to-Real Reinforcement Learning Framework For Social Navigation With Kinodynamic Feasibility
Pith reviewed 2026-06-27 09:27 UTC · model grok-4.3
The pith
Higher-order control inputs in reinforcement learning close the sim-to-real gap for differential-drive social navigation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
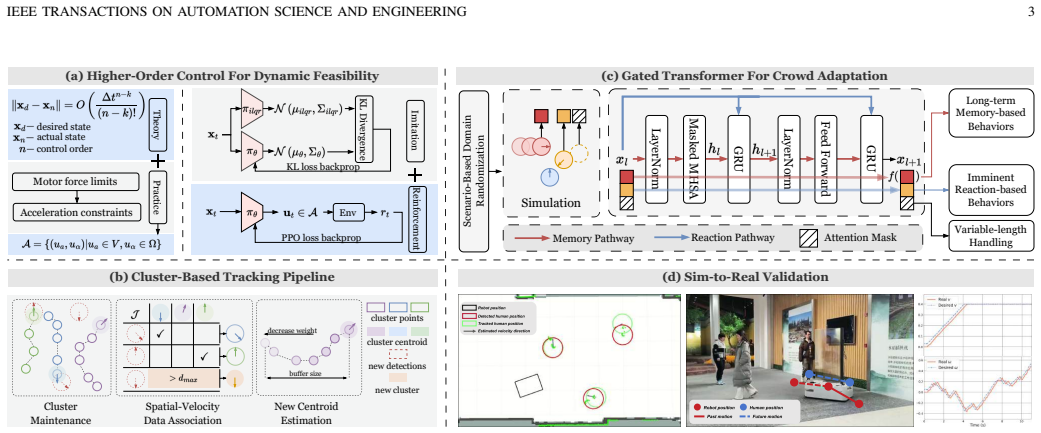
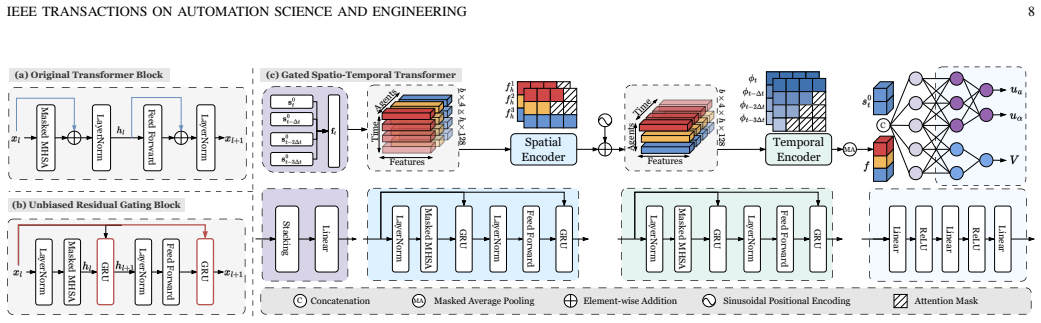
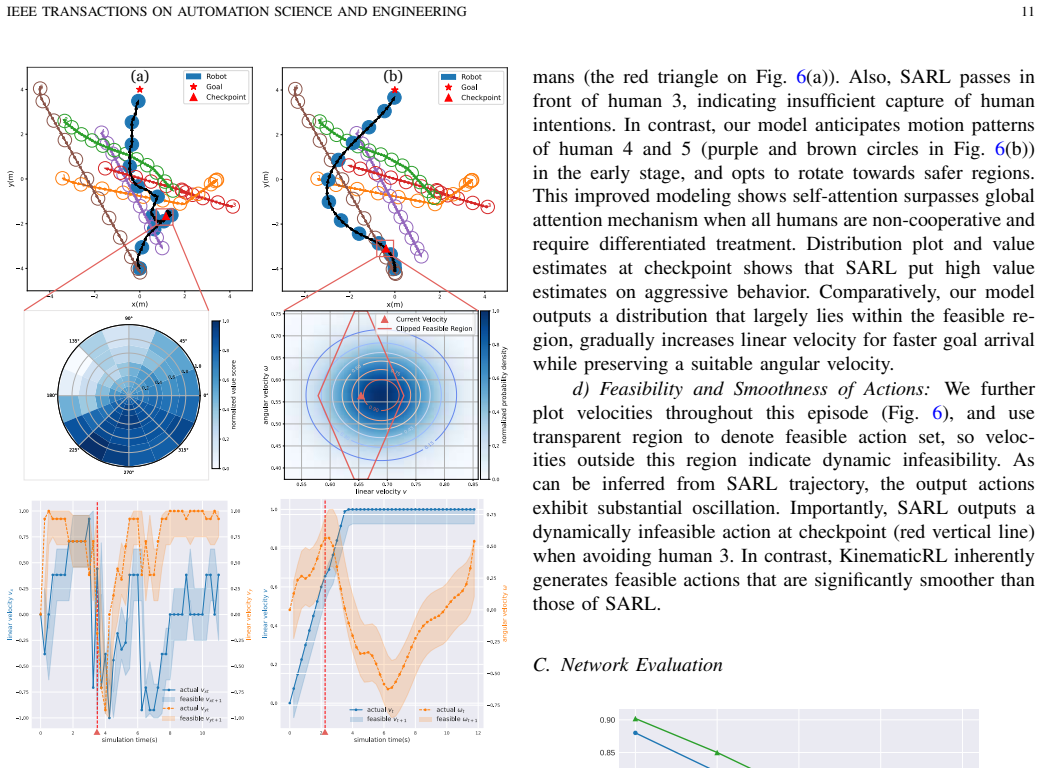
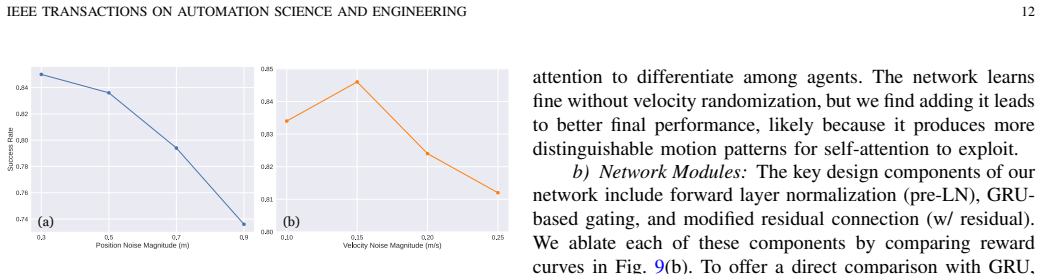
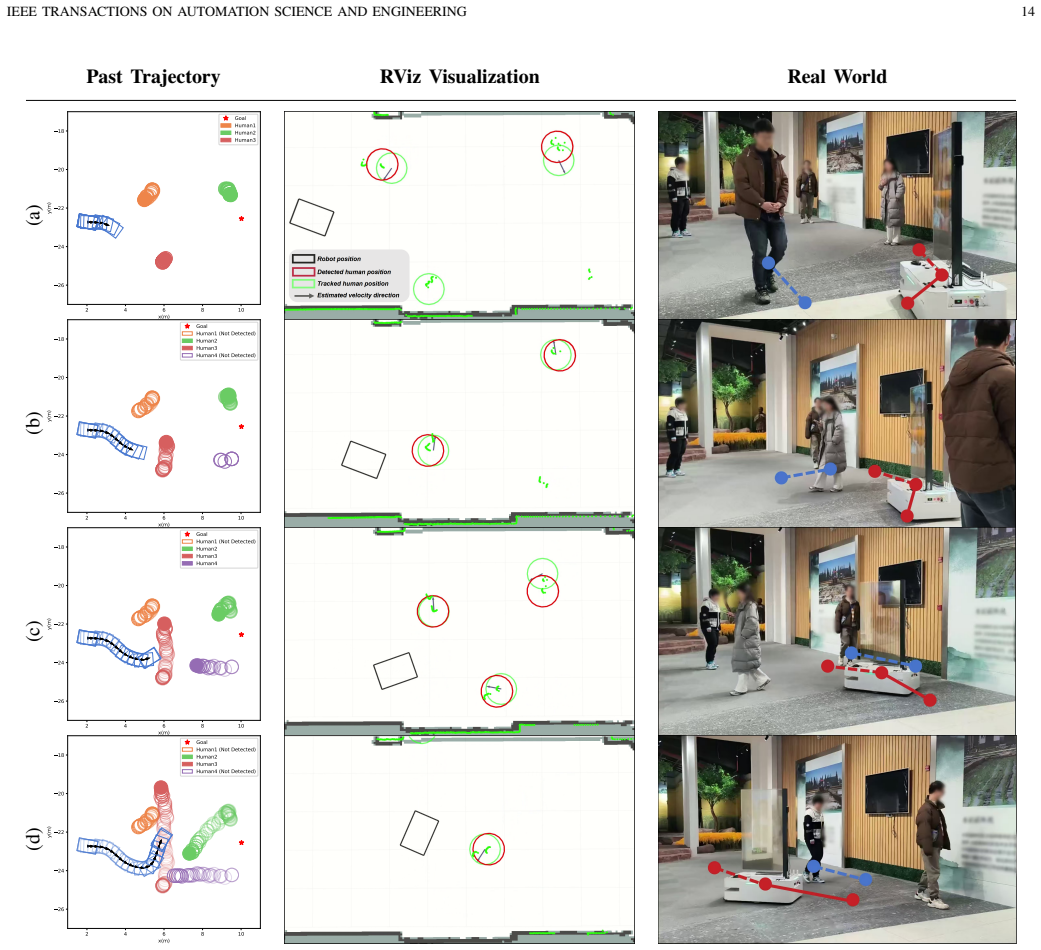
The central claim is that a second-order control action space whose tracking error decays exponentially, paired with stochastic iLQR pretraining, a proximity-and-velocity 2D LiDAR association pipeline, and an unbiased residual gating block, produces kinodynamically feasible social navigation policies that deploy on real differential-drive robots with minimal modifications.
What carries the argument
The second-order control formulation for differential-drive robots, which replaces first-order velocity commands and produces exponential decay in sim-to-real position tracking error.
If this is right
- Kinematic performance improves consistently compared with first-order baselines.
- The policy adapts its behavior to different numbers of detected humans without retraining.
- Real-world deployment on differential-drive platforms requires only small changes once the LiDAR tracking pipeline is attached.
- The same higher-order control approach can be applied to other differential-drive social navigation tasks.
Where Pith is reading between the lines
- The exponential-error argument may apply to other robot platforms whose dynamics admit higher-order input formulations.
- Removing the need for camera fusion could lower hardware cost and calibration effort for future social robots.
- The gating block's handling of time-varying crowd size suggests similar mechanisms could help other RL agents manage variable observation counts.
Load-bearing premise
Tracking error between simulated and actual robot position decays exponentially with increased control order, and the cluster-based 2D LiDAR pipeline can reliably separate nearby pedestrians and produce stable velocity estimates without any camera data.
What would settle it
Real-robot experiments in which measured position tracking error fails to shrink exponentially when moving from first-order to second-order controls, or in which the LiDAR pipeline merges or loses tracks of pedestrians closer than one meter.
Figures


read the original abstract
Deep Reinforcement Learning (DRL) has shown promise for social navigation, yet its real-world deployment remains hindered by a persistent sim-to-real gap arising from simplified first-order dynamics and context-specific human state estimation pipelines. This work presents a unified framework that addresses these limitations to produce dynamically feasible navigation policies suitable for real-world deployment. First, theoretical analysis reveals that tracking error between simulated and actual robot position decays exponentially with increased control order, motivating the use of higher-order control inputs as DRL action space. A second-order control formulation tailored to differential drive robots is developed, complemented by a stochastic iterative Linear Quadratic Regulator (iLQR) that pretrains the policy via a divergence minimization objective. Second, to avoid the added system complexity of camera-LiDAR fusion, a cluster-based human tracking pipeline using only 2D LiDAR is introduced. Human detections are associated according to both spatial proximity and velocity similarity, enabling reliable differentiation of nearby pedestrians and yielding stable velocity estimates through temporal aggregation. Third, we introduce an unbiased residual gating block to balance reaction- and memory-based behaviors while handling time-varying crowd sizes, both critical for social navigation. The resulting policy, KinematicRL, consistently improves kinematic performance and adapts to varying number of detected humans. Experiments in real-world environments demonstrate that, when combined with the proposed tracking pipeline, KinematicRL can be deployed on a real differential drive robot with minimal modifications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces KinematicRL, a sim-to-real DRL framework for social navigation on differential-drive robots. It motivates a second-order action space via a theoretical result that position tracking error decays exponentially with control order, uses stochastic iLQR for pretraining via divergence minimization, proposes a cluster-based 2D-LiDAR-only human tracking pipeline that associates detections by spatial proximity and velocity similarity, and adds an unbiased residual gating block to handle variable crowd sizes. The central claim is that the resulting policy improves kinematic performance and transfers to real robots with only minimal modifications.
Significance. If the exponential-decay result and real-world transfer claims hold, the work would provide a concrete route to kinodynamically feasible policies without camera-LiDAR fusion, which is a practical bottleneck in social navigation. The combination of higher-order actions, iLQR pretraining, and the gating mechanism is a coherent attempt to close the sim-to-real gap at both the dynamics and perception levels.
major comments (2)
- [Abstract / theoretical analysis] Abstract / theoretical analysis section: the claim that tracking error decays exponentially with increased control order is the load-bearing justification for adopting a second-order action space. The derivation is not supplied in the provided text, and the skeptic correctly notes that it implicitly assumes perfect state observation and exact dynamics matching; any sensor noise, wheel slip, or latency (precisely the sim-to-real issues the framework targets) can reduce the decay to linear or worse. The manuscript must include the full derivation (with explicit assumptions) and a robustness analysis under realistic perturbations.
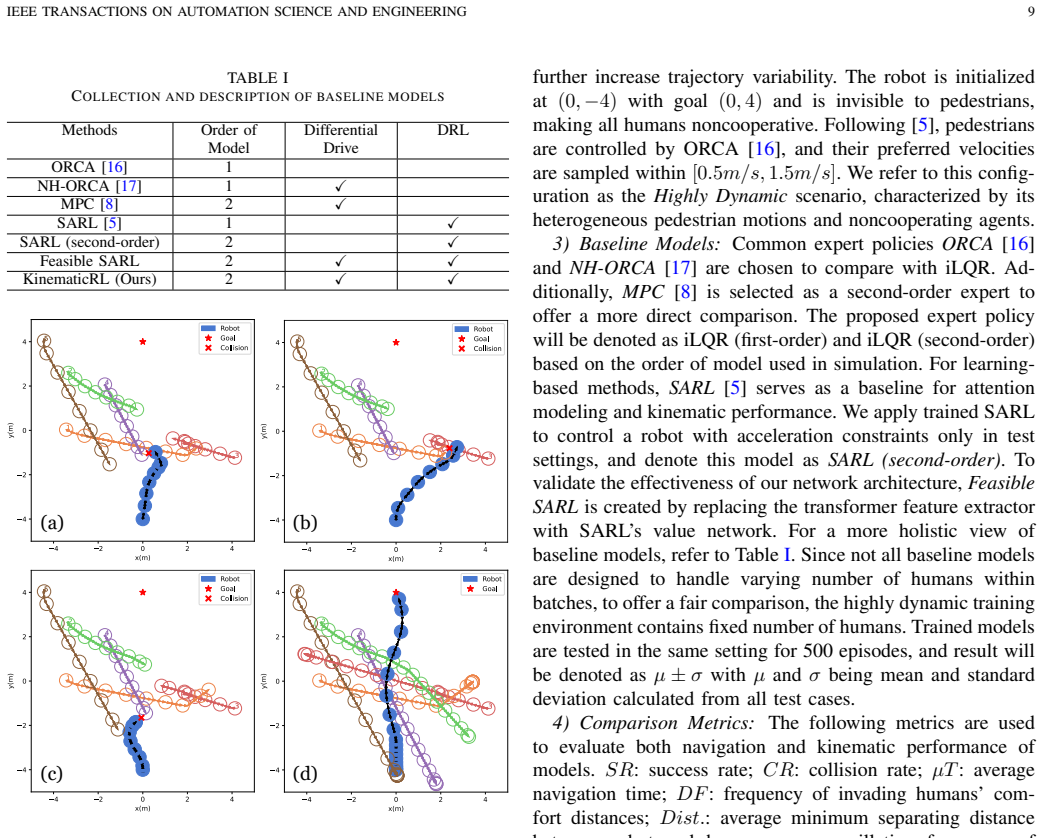
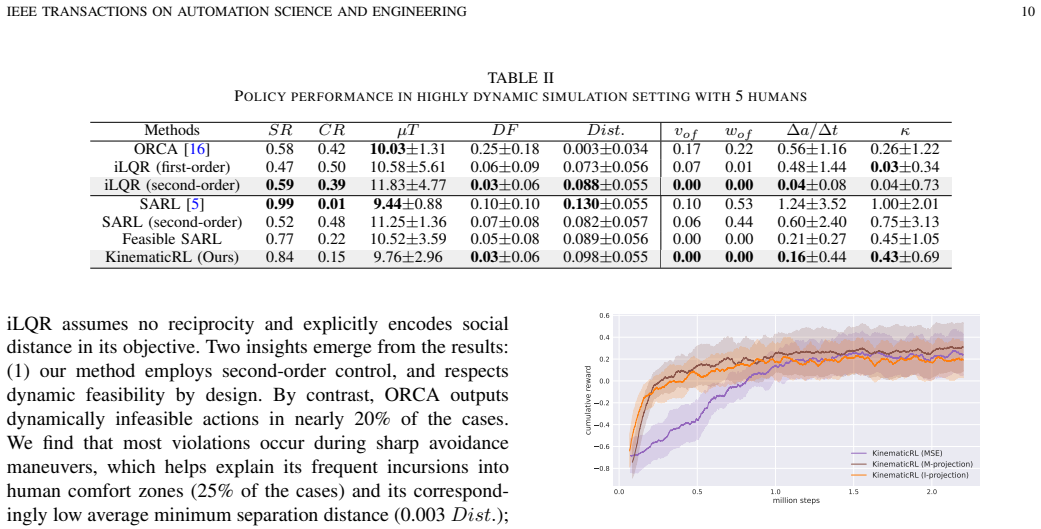
- [Experiments] Experiments / real-world deployment claim: the abstract states that KinematicRL deploys on a real differential-drive robot with minimal modifications when combined with the proposed tracking pipeline, yet no quantitative metrics, ablation results, success rates, or comparison against first-order baselines are visible in the supplied material. Without these data it is impossible to assess whether the claimed kinematic improvements and successful transfer actually materialize.
minor comments (2)
- The description of the cluster-based association (spatial proximity + velocity similarity) and the unbiased residual gating block would benefit from explicit pseudocode or a small diagram showing the data flow.
- Notation for the second-order control inputs and the stochastic iLQR objective should be introduced with a short table of symbols to avoid ambiguity when the full equations appear.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the theoretical justification and experimental validation. We address each major comment below and commit to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / theoretical analysis] Abstract / theoretical analysis section: the claim that tracking error decays exponentially with increased control order is the load-bearing justification for adopting a second-order action space. The derivation is not supplied in the provided text, and the skeptic correctly notes that it implicitly assumes perfect state observation and exact dynamics matching; any sensor noise, wheel slip, or latency (precisely the sim-to-real issues the framework targets) can reduce the decay to linear or worse. The manuscript must include the full derivation (with explicit assumptions) and a robustness analysis under realistic perturbations.
Authors: We agree the full derivation with explicit assumptions must be supplied. The result is derived under perfect state observation and exact dynamics matching; we will insert the complete derivation (including all steps) into the theoretical analysis section. We will also add an explicit discussion of how sensor noise, wheel slip, and latency can degrade the exponential decay toward linear behavior, together with a limited robustness analysis (e.g., Monte-Carlo perturbation sweeps) placed in the appendix. revision: yes
-
Referee: [Experiments] Experiments / real-world deployment claim: the abstract states that KinematicRL deploys on a real differential-drive robot with minimal modifications when combined with the proposed tracking pipeline, yet no quantitative metrics, ablation results, success rates, or comparison against first-order baselines are visible in the supplied material. Without these data it is impossible to assess whether the claimed kinematic improvements and successful transfer actually materialize.
Authors: The manuscript contains a real-world deployment section, yet we acknowledge that quantitative metrics, ablations, success rates, and first-order baseline comparisons are not presented with sufficient detail. We will expand the experiments section to report success rates, kinematic error statistics, ablation studies on the second-order action space and gating block, and direct comparisons against first-order policies, all evaluated on the physical robot. revision: yes
Circularity Check
No circularity: theoretical derivation and experimental claims remain independent of fitted inputs or self-citation chains
full rationale
The abstract and provided text describe a theoretical analysis deriving exponential tracking-error decay from control order, a second-order action space for differential-drive robots, an iLQR pretraining step, a LiDAR-only clustering pipeline, and a residual gating block, followed by real-world experiments. None of these steps are shown to reduce by construction to their own inputs (no fitted parameter renamed as prediction, no self-definitional loop, no load-bearing self-citation). The deployment claim is presented as an empirical outcome rather than a quantity forced by the derivation itself. This matches the default expectation of a self-contained paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tracking error between simulated and actual robot position decays exponentially with increased control order
Reference graph
Works this paper leans on
-
[1]
Decentralized non- communicating multiagent collision avoidance with deep reinforcement learning,
Y . F. Chen, M. Liu, M. Everett, and J. P. How, “Decentralized non- communicating multiagent collision avoidance with deep reinforcement learning,” inProc. IEEE Int. Conf. Robot. Automat., May 2017, pp. 285–292
2017
-
[2]
Socially aware motion planning with deep reinforcement learning,
Y . F. Chen, M. Everett, M. Liu, and J. P. How, “Socially aware motion planning with deep reinforcement learning,” inProc. IEEE/RSJ Int. Conf. Intell. Robots Syst., Sep. 2017, pp. 1343–1350
2017
-
[3]
Motion planning among dynamic, decision-making agents with deep reinforcement learning,
M. Everett, Y . F. Chen, and J. P. How, “Motion planning among dynamic, decision-making agents with deep reinforcement learning,” inProc. IEEE/RSJ Int. Conf. Intell. Robots Syst., Oct. 2018, pp. 3052–3059
2018
-
[4]
Intention aware robot crowd navigation with attention-based interaction graph,
S. Liu, P. Chang, Z. Huang, N. Chakraborty, K. Hong, W. Liang, D. L. McPherson, J. Geng, and K. Driggs-Campbell, “Intention aware robot crowd navigation with attention-based interaction graph,” inProc. IEEE Int. Conf. Robot. Automat., May 2023, pp. 12 015–12 021
2023
-
[5]
Crowd-robot interaction: Crowd-aware robot navigation with attention-based deep reinforcement learning,
C. Chen, Y . Liu, S. Kreiss, and A. Alahi, “Crowd-robot interaction: Crowd-aware robot navigation with attention-based deep reinforcement learning,” inProc. IEEE Int. Conf. Robot. Automat., May 2019, pp. 6015–6022
2019
-
[6]
Rmrl: Robot navigation in crowd environments with risk map-based deep reinforcement learning,
H. Yang, C. Yao, C. Liu, and Q. Chen, “Rmrl: Robot navigation in crowd environments with risk map-based deep reinforcement learning,” IEEE Robot. Autom. Lett., vol. 8, no. 12, pp. 7930–7937, Dec. 2023
2023
-
[7]
Combining op- timal control and learning for visual navigation in novel environments,
S. Bansal, V . Tolani, S. Gupta, J. Malik, and C. Tomlin, “Combining op- timal control and learning for visual navigation in novel environments,” inProc. Conf. Robot Learn., Oct. 2019, pp. 420–429
2019
-
[8]
Where to go next: Learning a subgoal recommendation policy for navigation in dynamic environments,
B. Brito, M. Everett, J. P. How, and J. Alonso-Mora, “Where to go next: Learning a subgoal recommendation policy for navigation in dynamic environments,”IEEE Robot. Autom. Lett., vol. 6, no. 3, pp. 4616–4623, Jul. 2021. IEEE TRANSACTIONS ON AUTOMATION SCIENCE AND ENGINEERING 15
2021
-
[9]
Sim-to-real transfer for vision-and-language navigation,
P. Anderson, A. Shrivastava, J. Truong, A. Majumdar, D. Parikh, D. Batra, and S. Lee, “Sim-to-real transfer for vision-and-language navigation,” inProc. Conf. Robot Learn., Nov. 2020, pp. 671–681
2020
-
[10]
Navigating robots in dynamic environment with deep reinforcement learning,
Z. Zhou, Z. Zeng, L. Lang, W. Yao, H. Lu, Z. Zheng, and Z. Zhou, “Navigating robots in dynamic environment with deep reinforcement learning,”IEEE Trans. Intell. Transp. Syst., vol. 23, no. 12, pp. 25 201– 25 211, Dec. 2022
2022
-
[11]
Dwa- rl: Dynamically feasible deep reinforcement learning policy for robot navigation among mobile obstacles,
U. Patel, N. K. S. Kumar, A. J. Sathyamoorthy, and D. Manocha, “Dwa- rl: Dynamically feasible deep reinforcement learning policy for robot navigation among mobile obstacles,” inProc. IEEE Int. Conf. Robot. Automat., May 2021, pp. 6057–6063
2021
-
[12]
Multi-robot cooperative socially-aware navigation using multi-agent reinforcement learning,
W. Wang, L. Mao, R. Wang, and B.-C. Min, “Multi-robot cooperative socially-aware navigation using multi-agent reinforcement learning,” in Proc. IEEE Int. Conf. Robot. Automat., May 2024, pp. 12 353–12 360
2024
-
[13]
End-to-end safe reinforcement learning through barrier functions for safety-critical continuous control tasks,
R. Cheng, G. Orosz, R. M. Murray, and J. W. Burdick, “End-to-end safe reinforcement learning through barrier functions for safety-critical continuous control tasks,” inProc. AAAI Conf. Artif. Intell., vol. 33, no. 01, 2019, pp. 3387–3395
2019
-
[14]
Li2former: Omni- dimension aggregation transformer for person detection in 2-d range data,
H. Yang, Y . Yang, C. Yao, C. Liu, and Q. Chen, “Li2former: Omni- dimension aggregation transformer for person detection in 2-d range data,”IEEE Trans. Instrum. Meas., vol. 73, pp. 1–12, 2024
2024
-
[15]
Reciprocal velocity obstacles for real-time multi-agent navigation,
J. van den Berg, M. Lin, and D. Manocha, “Reciprocal velocity obstacles for real-time multi-agent navigation,” inProc. IEEE Int. Conf. Robot. Automat., May 2008, pp. 1928–1935
2008
-
[16]
Reciprocal n- body collision avoidance,
J. Van Den Berg, S. J. Guy, M. Lin, and D. Manocha, “Reciprocal n- body collision avoidance,” inProc. Conf. Robot. Res., 2011, pp. 3–19
2011
-
[17]
Smooth and collision-free navigation for multiple robots under differential-drive constraints,
J. Snape, J. Van Den Berg, S. J. Guy, and D. Manocha, “Smooth and collision-free navigation for multiple robots under differential-drive constraints,” inProc. IEEE/RSJ Int. Conf. Intell. Robots Syst., Oct. 2010, pp. 4584–4589
2010
-
[18]
Control barrier functions in dynamic uavs for kinematic obstacle avoidance: A collision cone approach,
M. Tayal, R. Singh, J. Keshavan, and S. Kolathaya, “Control barrier functions in dynamic uavs for kinematic obstacle avoidance: A collision cone approach,” inProc. Amer. Control Conf. (ACC), Jul. 2024, pp. 3722–3727
2024
-
[19]
Safety- critical control of nonholonomic vehicles in dynamic environments using velocity obstacles,
A. Haraldsen, M. S. Wiig, A. D. Ames, and K. Y . Pattersen, “Safety- critical control of nonholonomic vehicles in dynamic environments using velocity obstacles,” inProc. Amer. Control Conf. (ACC), Jul. 2024, pp. 3152–3159
2024
-
[20]
Applr: Adaptive planner parameter learning from rein- forcement,
Z. Xu, G. Dhamankar, A. Nair, X. Xiao, G. Warnell, B. Liu, Z. Wang, and P. Stone, “Applr: Adaptive planner parameter learning from rein- forcement,” inProc. IEEE Int. Conf. Robot. Automat., 2021, pp. 6086– 6092
2021
-
[21]
Robot navigation in crowded environments using deep reinforcement learning,
L. Liu, D. Dugas, G. Cesari, R. Siegwart, and R. Dube, “Robot navigation in crowded environments using deep reinforcement learning,” inProc. IEEE/RSJ Int. Conf. Intell. Robots Syst., Oct. 2020, pp. 5671– 5677
2020
-
[22]
Learning kinematic fea- sibility for mobile manipulation through deep reinforcement learning,
D. Honerkamp, T. Welschehold, and A. Valada, “Learning kinematic fea- sibility for mobile manipulation through deep reinforcement learning,” IEEE Robot. Autom. Lett., vol. 6, no. 4, pp. 6289–6296, 2021
2021
-
[23]
Dr-spaam: A spatial-attention and auto-regressive model for person detection in 2d range data,
D. Jia, A. Hermans, and B. Leibe, “Dr-spaam: A spatial-attention and auto-regressive model for person detection in 2d range data,” inProc. IEEE/RSJ Int. Conf. Intell. Robots Syst., Oct. 2020, pp. 10 270–10 277
2020
-
[24]
Simple online and realtime tracking,
A. Bewley, Z. Ge, L. Ott, F. Ramos, and B. Upcroft, “Simple online and realtime tracking,” inProc. IEEE Int. Conf. Image Process., Sep. 2016, pp. 3464–3468
2016
-
[25]
Simple online and realtime tracking with a deep association metric,
N. Wojke, A. Bewley, and D. Paulus, “Simple online and realtime tracking with a deep association metric,” inProc. IEEE Int. Conf. Image Process., Sep. 2017, pp. 3645–3649
2017
-
[26]
Understanding domain randomization for sim-to-real transfer,
X. Chen, J. Hu, C. Jin, L. Li, and L. Wang, “Understanding domain randomization for sim-to-real transfer,” inProc. Int. Conf. Learn. Representations, Apr. 2022
2022
-
[27]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, “Attention is all you need,”Proc. Int. Conf. Adv. Neural Inf. Process. Syst., pp. 1–11, Dec. 2017
2017
-
[28]
St2: Spatial-temporal state transformer for crowd-aware autonomous navigation,
Y . Yang, J. Jiang, J. Zhang, J. Huang, and M. Gao, “St2: Spatial-temporal state transformer for crowd-aware autonomous navigation,”IEEE Robot. Autom. Lett., vol. 8, no. 2, pp. 912–919, Feb. 2023
2023
-
[29]
Stabilizing transformers for reinforcement learning,
E. Parisotto, F. Song, J. Rae, R. Pascanu, C. Gulcehre, S. Jayakumar, M. Jaderberg, R. L. Kaufman, A. Clark, S. Nouryet al., “Stabilizing transformers for reinforcement learning,” inProc. Int. Conf. Mach. Learn., Jul. 2020, pp. 7487–7498
2020
-
[30]
A simple neural attentive meta-learner,
N. Mishra, M. Rohaninejad, X. Chen, and P. Abbeel, “A simple neural attentive meta-learner,” inProc. Int. Conf. Learn. Representations, May 2018
2018
-
[31]
Improving transformer optimization through better initialization,
X. S. Huang, F. Perez, J. Ba, and M. V olkovs, “Improving transformer optimization through better initialization,” inProc. Int. Conf. Mach. Learn., Jul. 2020, pp. 4425–4433
2020
-
[32]
S. M. LaValle,Planning algorithms. Cambridge university press, 2006
2006
-
[33]
B. D. Ziebart,Modeling purposeful adaptive behavior with the principle of maximum causal entropy. Carnegie Mellon University, 2010
2010
-
[34]
Guided policy search,
S. Levine and V . Koltun, “Guided policy search,” inProc. Int. Conf. Mach. Learn., 2013, pp. 1–9
2013
-
[35]
Im- itation learning as f-divergence minimization,
L. Ke, S. Choudhury, M. Barnes, W. Sun, G. Lee, and S. Srinivasa, “Im- itation learning as f-divergence minimization,” inWorkshp Algorithmic Found. Robot., 2020, pp. 313–329
2020
-
[36]
A divergence minimization perspective on imitation learning methods,
S. K. S. Ghasemipour, R. Zemel, and S. Gu, “A divergence minimization perspective on imitation learning methods,” inProc. Conf. Robot Learn., 2020, pp. 1259–1277
2020
-
[37]
Synthesis and stabilization of complex behaviors through online trajectory optimization,
Y . Tassa, T. Erez, and E. Todorov, “Synthesis and stabilization of complex behaviors through online trajectory optimization,” inProc. IEEE/RSJ Int. Conf. Intell. Robots Syst., Oct. 2012, pp. 4906–4913
2012
-
[38]
A reduction of imitation learning and structured prediction to no-regret online learning,
S. Ross, G. Gordon, and D. Bagnell, “A reduction of imitation learning and structured prediction to no-regret online learning,” inProc. Int. Conf. on Artif. Intell. and Statist., Apr. 2011, pp. 627–635
2011
-
[39]
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
J. Chung, C. Gulcehre, K. Cho, and Y . Bengio, “Empirical evaluation of gated recurrent neural networks on sequence modeling,” 2014, arXiv:1412.3555
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[40]
Domain randomization for transferring deep neural networks from simulation to the real world,
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel, “Domain randomization for transferring deep neural networks from simulation to the real world,” inProc. IEEE/RSJ Int. Conf. Intell. Robots Syst., Sep. 2017, pp. 23–30
2017
-
[41]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” 2017,arXiv:1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
J. Schulman, P. Moritz, S. Levine, M. Jordan, and P. Abbeel, “High- dimensional continuous control using generalized advantage estimation,” 2015,arXiv:1506.02438
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[43]
Stable-baselines3: Reliable reinforcement learning implementa- tions,
A. Raffin, A. Hill, A. Gleave, A. Kanervisto, M. Ernestus, and N. Dor- mann, “Stable-baselines3: Reliable reinforcement learning implementa- tions,”J. Mach. Learn. Res., vol. 22, no. 268, pp. 1–8, 2021
2021
-
[44]
Adam: A Method for Stochastic Optimization
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” 2014,arXiv:1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[45]
Fast-tracker: A robust aerial system for tracking agile target in cluttered environments,
Z. Han, R. Zhang, N. Pan, C. Xu, and F. Gao, “Fast-tracker: A robust aerial system for tracking agile target in cluttered environments,” inProc. IEEE Int. Conf. Robot. Automat., May 2021, pp. 328–334
2021
-
[46]
Safe navigation in uncertain crowded environments using risk adaptive cvar barrier functions,
X. Wang, T. Kim, B. Hoxha, G. Fainekos, and D. Panagou, “Safe navigation in uncertain crowded environments using risk adaptive cvar barrier functions,” inProc. IEEE/RSJ Int. Conf. Intell. Robots Syst., 2025, pp. 7669–7676
2025
-
[47]
Agile but safe: Learning collision-free high-speed legged locomotion,
T. He, C. Zhang, W. Xiao, G. He, C. Liu, and G. Shi, “Agile but safe: Learning collision-free high-speed legged locomotion,” 2024, arXiv:2401.17583
-
[48]
Q-detr: An efficient low-bit quantized detection transformer,
S. Xu, Y . Li, M. Lin, P. Gao, G. Guo, J. L ¨u, and B. Zhang, “Q-detr: An efficient low-bit quantized detection transformer,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit., 2023, pp. 3842–3851. Zhiming Xuis expected to receive the B.Eng. degree in computer science from Tongji Univer- sity, Shanghai, China, in 2026. He will pursue the M.S. degree in ro...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.