Where Does Toxicity Live? Mechanistic Localization and Targeted Suppression in Language Models
Pith reviewed 2026-06-29 13:23 UTC · model grok-4.3
The pith
Toxicity in language models concentrates in early MLP layers and can be suppressed by targeted activation scaling or rank-one weight edits without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Toxicity is disproportionately encoded in early MLP layers, varies across architectures, and is systematically underestimated by single-evaluator setups. The authors develop Meow2X and TRNE to localize toxicity via activation differentials between toxic and neutral prompts, then suppress it through inference-time scaling or minimal rank-one weight edits, achieving consistent toxicity reduction on two benchmarks while preserving language modeling quality across five LMs and 90 configurations.
What carries the argument
Activation differentials between toxic and neutral prompts, which identify toxic layers and neurons in early MLPs for suppression via inference-time scaling or rank-one weight edits.
If this is right
- Toxicity can be reduced at inference time without any retraining or gradient updates.
- Early MLP layers serve as the main sites where toxicity is encoded in the tested models.
- Suppression strategies must account for differences across model architectures.
- Reliable safety measurement requires multiple independent evaluators rather than a single one.
- Minimal rank-one weight edits can achieve targeted detoxification while maintaining overall model quality.
Where Pith is reading between the lines
- The localization approach might apply to other unwanted model behaviors such as bias or factual errors.
- Concentrating on early layers suggests that data curation during pretraining could reduce toxicity before it becomes embedded.
- This method offers a way to audit and edit models internally rather than relying solely on output filtering.
Load-bearing premise
Differences in activations between toxic and neutral prompts directly mark the internal sources of toxicity rather than merely correlated patterns.
What would settle it
An experiment in which suppressing the identified early MLP neurons and layers fails to reduce toxic generations on held-out prompts or causes measurable drops in general language modeling performance.
Figures

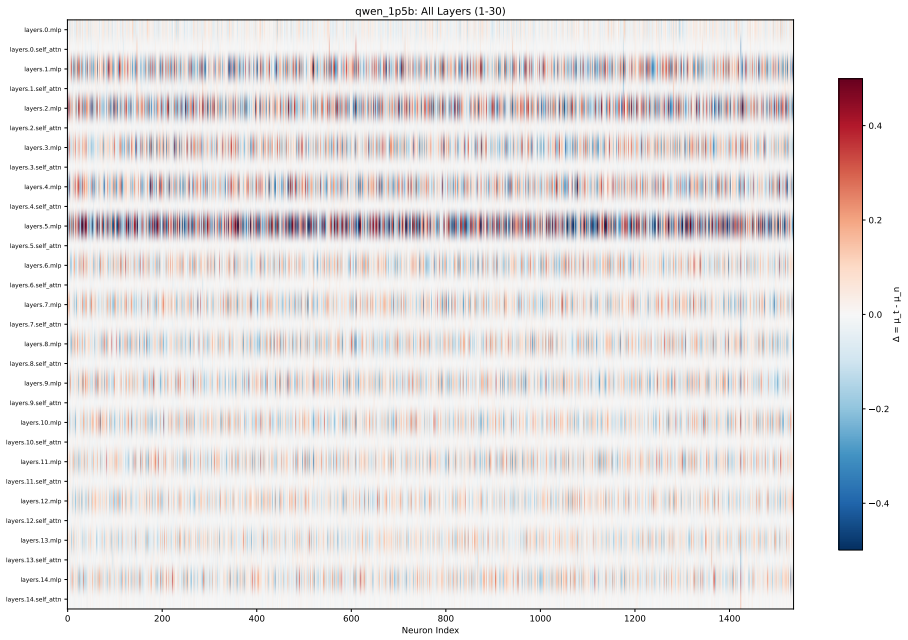
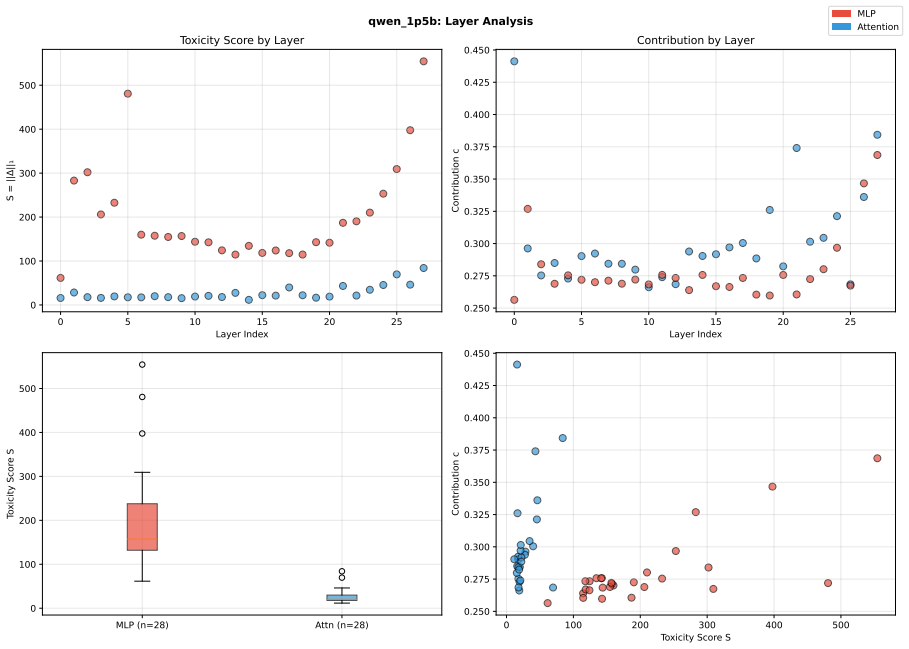
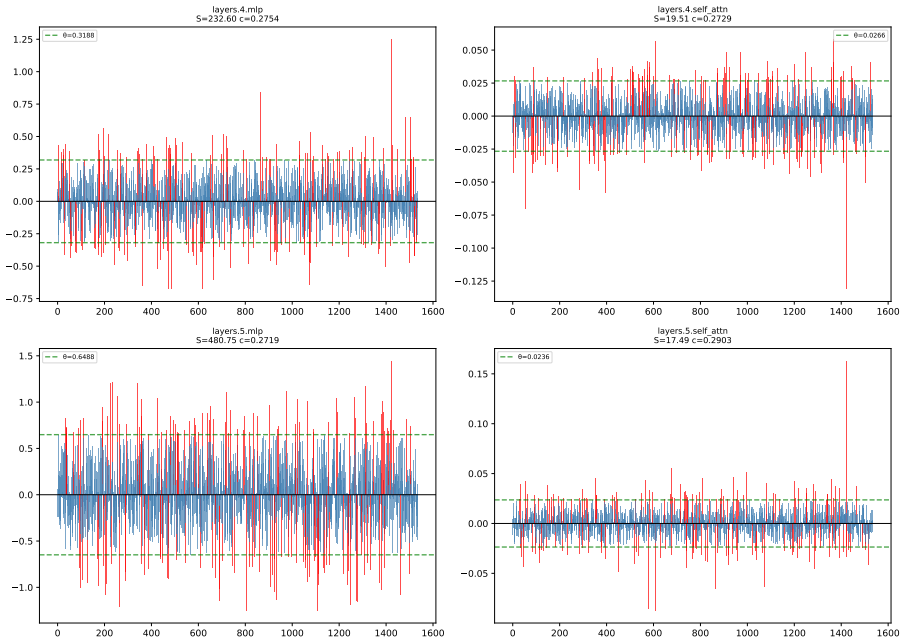
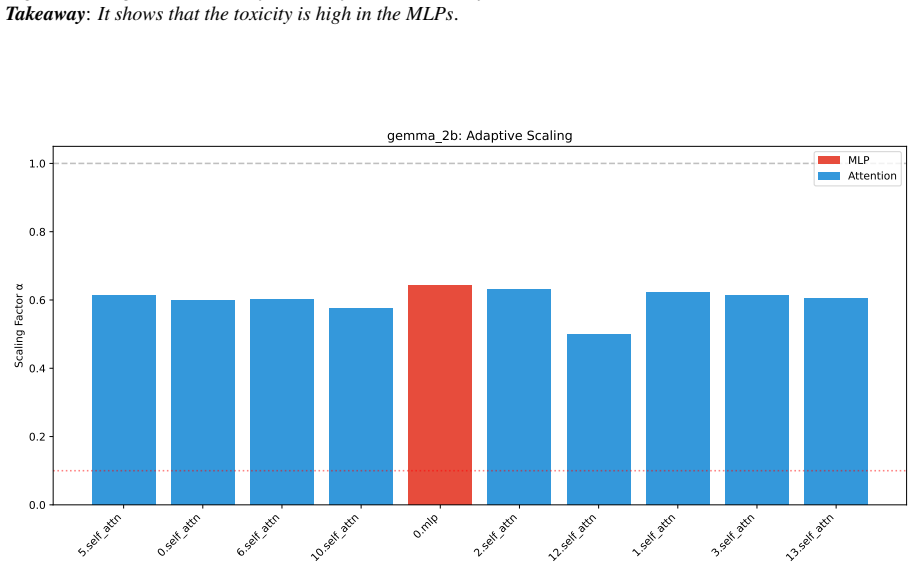
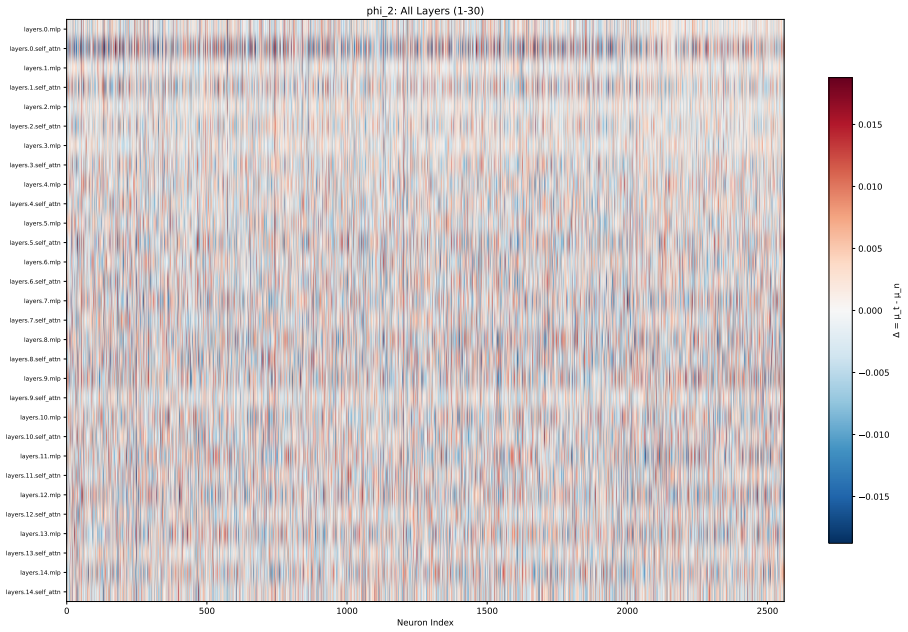
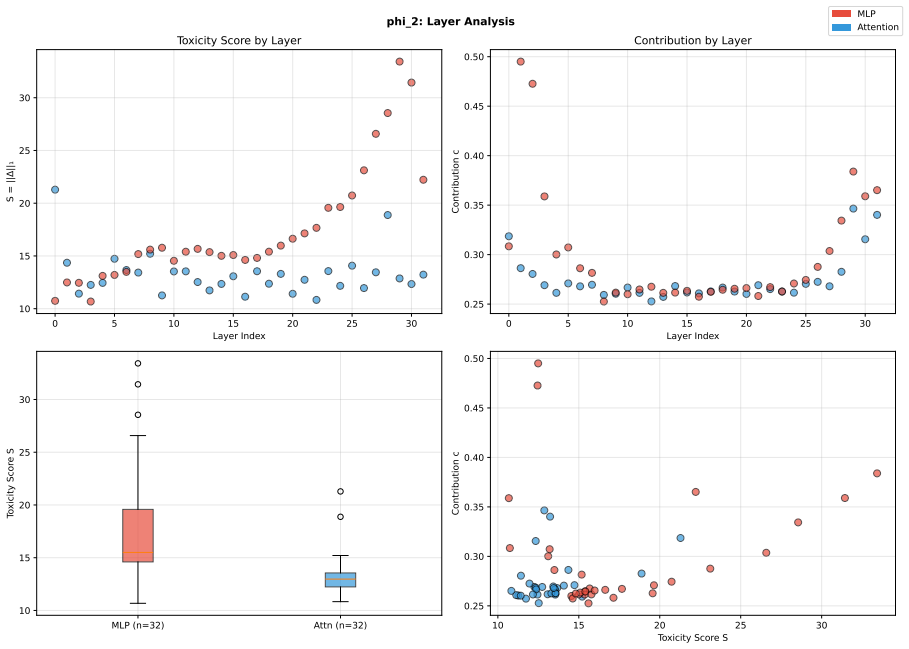

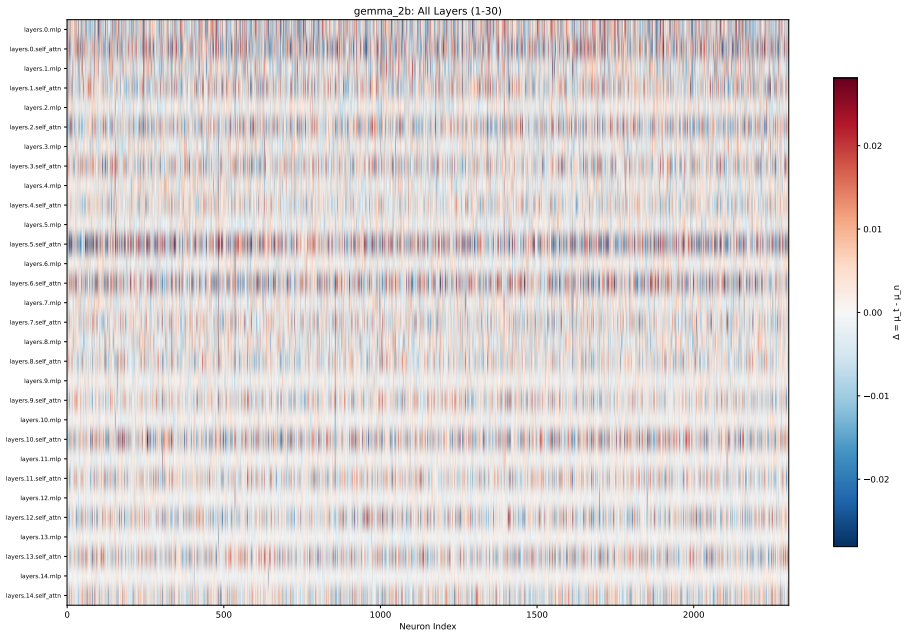

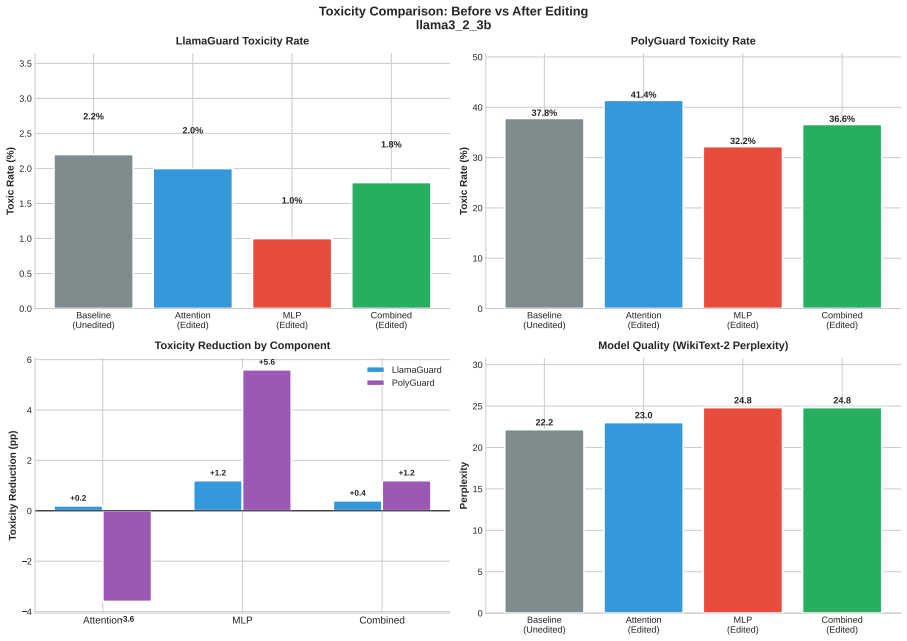
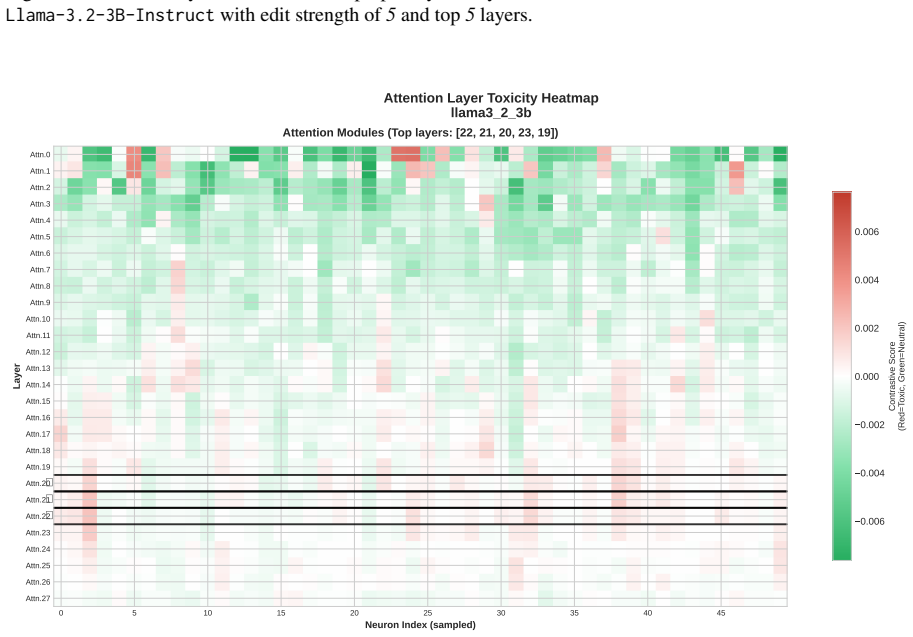




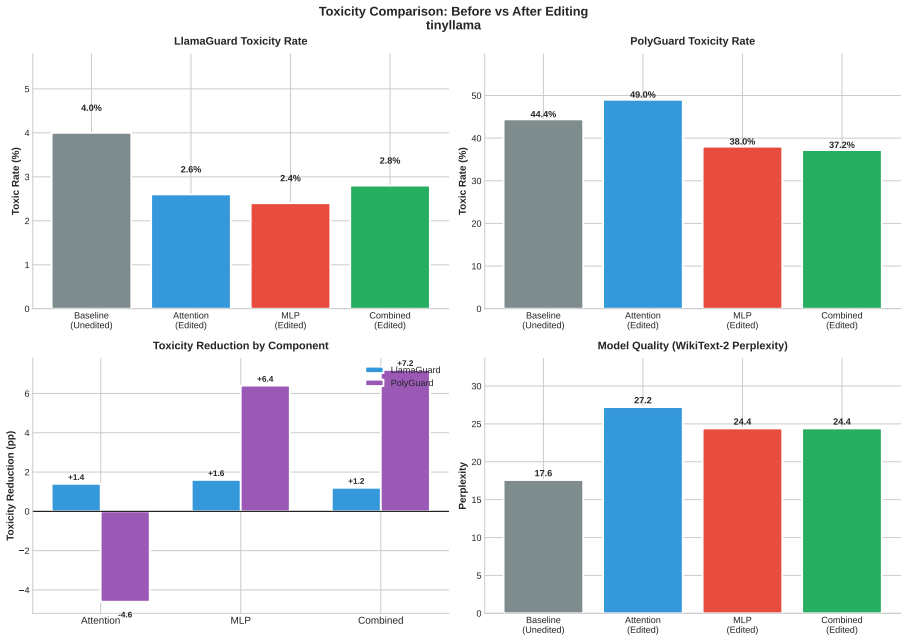
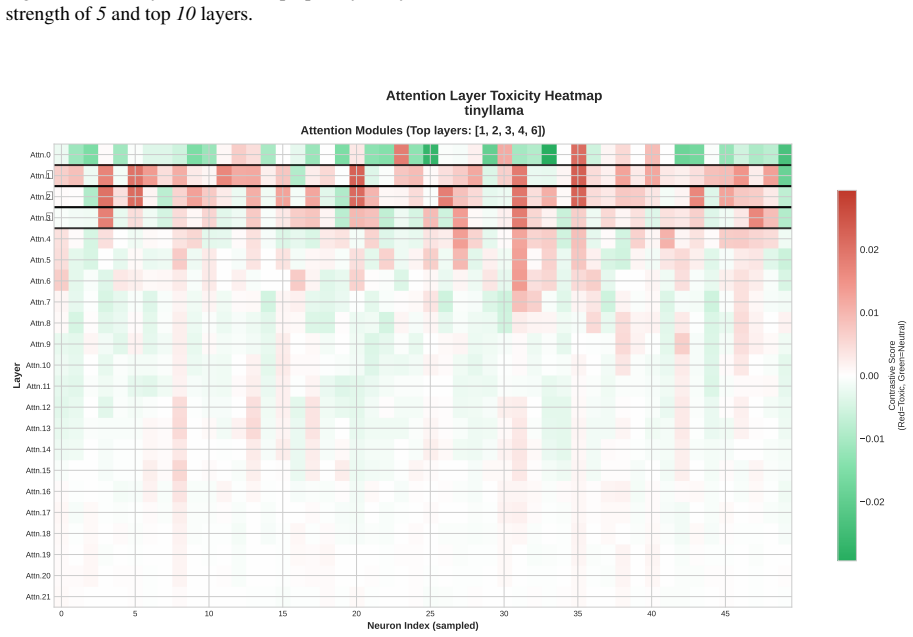
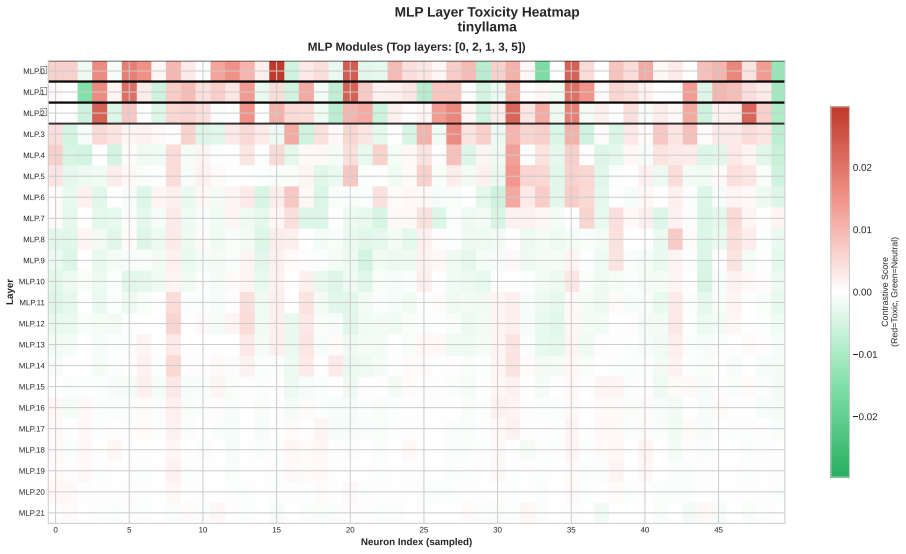
read the original abstract
Large language models frequently generate toxic, hateful, or harmful content, yet existing mitigation methods rely on costly retraining or output-level filtering with no mechanistic insight into where toxicity originates internally. We introduce Meow2X and TRNE, two complementary retraining-free frameworks that localize toxicity to specific layers and neurons by analyzing activation differentials between toxic and neutral prompts, then suppress them via inference-time scaling or minimal rank-one weight edits -- without any gradient descent. Evaluations across five LMs, two benchmarks, and 90 configurations using dual safety evaluators demonstrate consistent toxicity reduction while preserving language modeling quality. Our analysis reveals that toxicity is disproportionately encoded in early MLP layers, varies across architectures, and is systematically underestimated by single-evaluator setups -- underscoring the need for multi-evaluator safety assessment. By bridging mechanistic interpretability with practical detoxification, our framework offers a principled path toward safer, more transparent language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Meow2X and TRNE, two retraining-free frameworks that localize toxicity in LLMs by analyzing activation differentials between toxic and neutral prompts, then suppress it via inference-time scaling or minimal rank-one weight edits. Evaluations across five models, two benchmarks, and 90 configurations with dual safety evaluators show consistent toxicity reduction while preserving language modeling quality. The analysis concludes that toxicity is disproportionately encoded in early MLP layers, varies across architectures, and is systematically underestimated by single-evaluator setups.
Significance. If the localization is shown to be causal rather than correlational, the work would provide mechanistic insight into toxicity encoding and practical inference-time mitigation methods that avoid retraining. The multi-model, multi-benchmark, and dual-evaluator design is a clear strength, as is the explicit call for multi-evaluator safety assessment. These elements would advance both interpretability and safety research if the central causal premise holds.
major comments (2)
- [Abstract and §3] Abstract and §3 (Localization via Meow2X): the premise that activation differentials between toxic and neutral prompts isolate internal toxicity-encoding mechanisms is load-bearing for all downstream claims about early-MLP concentration and suppression efficacy, yet the manuscript provides no causal interventions (activation patching, neuron ablation, or counterfactual edits) to distinguish these differentials from correlated but non-causal features such as prompt length or lexical style.
- [§4 and Table 2] §4 (TRNE suppression) and Table 2: the reported toxicity reductions are obtained after layer/neuron selection based on the same activation differentials; without an independent causal test or held-out validation, it is unclear whether the rank-one edits and scaling factors demonstrate mechanistic control or merely exploit the selection criterion.
minor comments (2)
- [Abstract] The abstract states results across “90 configurations” but does not specify how these were sampled or whether any post-hoc filtering occurred; a brief methods paragraph clarifying the configuration space would improve reproducibility.
- [§4] Notation for the rank-one edit (e.g., the precise form of the update matrix) is introduced without an equation number; adding an explicit equation in §4 would aid readers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need to strengthen causal claims in our localization and suppression methods. We address each major comment below and propose targeted revisions to clarify the correlational basis of our approach while preserving the empirical contributions.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Localization via Meow2X): the premise that activation differentials between toxic and neutral prompts isolate internal toxicity-encoding mechanisms is load-bearing for all downstream claims about early-MLP concentration and suppression efficacy, yet the manuscript provides no causal interventions (activation patching, neuron ablation, or counterfactual edits) to distinguish these differentials from correlated but non-causal features such as prompt length or lexical style.
Authors: We acknowledge that Meow2X relies on activation differentials, which are correlational rather than established through causal interventions such as activation patching or ablation. The manuscript does not include these experiments. The suppression results in later sections provide indirect support by showing functional impact when intervening on the identified components, but this does not fully resolve the concern. We will revise §3 and the abstract to explicitly describe the method as identifying candidate toxicity-related features via differentials and add a limitations paragraph discussing the correlational nature and potential confounds like prompt style. revision: partial
-
Referee: [§4 and Table 2] §4 (TRNE suppression) and Table 2: the reported toxicity reductions are obtained after layer/neuron selection based on the same activation differentials; without an independent causal test or held-out validation, it is unclear whether the rank-one edits and scaling factors demonstrate mechanistic control or merely exploit the selection criterion.
Authors: The selection of layers and neurons for TRNE is performed using the same differentials as Meow2X, creating potential circularity in the evaluation. The manuscript reports consistent toxicity reduction across five models and dual evaluators with minimal impact on perplexity, which offers some evidence against pure exploitation, but no independent held-out validation or causal tests are presented. We will revise §4 to clarify this dependency, add discussion of the selection-suppression relationship, and include a note on the need for future causal validation experiments. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper introduces Meow2X and TRNE frameworks that localize toxicity via activation differentials between toxic and neutral prompts and apply suppression through scaling or rank-one edits. No quoted steps reduce predictions or results to inputs by construction, no self-citation chains bear the central claims, and no fitted parameters are renamed as independent predictions. Evaluations across five models, two benchmarks, and dual evaluators provide external empirical content independent of the localization method itself.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
David Bau, Bolei Zhou, Aditya Khosla, Aude Oliva, and Antonio Torralba. 2017. Network dissection: Quantifying interpretability of deep visual representations. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6541--6549
2017
- [2]
-
[3]
Towards understanding safety alignment: A mechanistic perspective from safety neurons
Jianhui Chen, Xiaozhi Wang, Zijun Yao, Yushi Bai, Lei Hou, and Juanzi Li. Towards understanding safety alignment: A mechanistic perspective from safety neurons. In The Thirty-ninth Annual Conference on Neural Information Processing Systems
- [4]
-
[5]
Marta Costa-juss \`a , David Dale, Maha Elbayad, and Bokai Yu. 2024. https://aclanthology.org/2024.eamt-1.31/ Added toxicity mitigation at inference time for multimodal and massively multilingual translation . In Proceedings of the 25th Annual Conference of the European Association for Machine Translation (Volume 1), pages 360--372, Sheffield, UK. Europea...
2024
-
[6]
Damai Dai, Li Dong, Yaru Hao, Zhifang Sui, Baobao Chang, and Furu Wei. 2022. https://doi.org/10.18653/v1/2022.acl-long.581 Knowledge neurons in pretrained transformers . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8493--8502, Dublin, Ireland. Association for Computational Linguistics
- [8]
-
[9]
Daryna Dementieva, Nikolay Babakov, and Alexander Panchenko. 2024. Multiparadetox: Extending text detoxification with parallel data to new languages. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Papers), pages 124--140
2024
-
[10]
Daryna Dementieva, Nikolay Babakov, Amit Ronen, Abinew Ali Ayele, Naquee Rizwan, Florian Schneider, Xintong Wang, Seid Muhie Yimam, Daniil Alekhseevich Moskovskiy, Elisei Stakovskii, and 1 others. 2025. Multilingual and explainable text detoxification with parallel corpora. In Proceedings of the 31st International Conference on Computational Linguistics, ...
2025
-
[11]
Daryna Dementieva, Sergey Ustyantsev, David Dale, Olga Kozlova, Nikita Semenov, Alexander Panchenko, and Varvara Logacheva. 2021. http://ceur-ws.org/Vol-2932/paper2.pdf Crowdsourcing of parallel corpora: the case of style transfer for detoxification . In Proceedings of the 2nd Crowd Science Workshop: Trust, Ethics, and Excellence in Crowdsourced Data Mana...
2021
-
[12]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, and 1 others. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Ritik Dutta. 2024. Benchmarking stereotype bias and toxicity in large language models. Ph.D. thesis, University of Illinois at Urbana-Champaign
2024
-
[14]
Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A. Smith. 2020. https://doi.org/10.18653/v1/2020.findings-emnlp.301 R eal T oxicity P rompts: Evaluating neural toxic degeneration in language models . In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 3356--3369, Online. Association for Computational Linguistics
-
[15]
Atticus Geiger, Hanson Lu, Thomas Icard, and Christopher Potts. 2021. Causal abstractions of neural networks. Advances in Neural Information Processing Systems, 34:9574--9586
2021
- [16]
- [17]
-
[18]
Hyukhun Koh, Dohyung Kim, Minwoo Lee, and Kyomin Jung. 2024. Can llms recognize toxicity? a structured investigation framework and toxicity metric. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 6092--6114
2024
-
[19]
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. 2019. Similarity of neural network representations revisited. In International conference on machine learning, pages 3519--3529. PMlR
2019
- [20]
-
[21]
Jaewook Lee, Junseo Jang, Oh-Woog Kwon, and Harksoo Kim. 2025. Small changes, big impact: How manipulating a few neurons can drastically alter llm aggression. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 23478--23505
2025
-
[22]
Maximilian Li and Lucas Janson. 2024. Optimal ablation for interpretability. Advances in Neural Information Processing Systems, 37:109233--109282
2024
-
[23]
Xiaochen Li, Zheng-Xin Yong, and Stephen Bach. 2024. Preference tuning for toxicity mitigation generalizes across languages. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 13422--13440
2024
- [24]
-
[25]
Alisa Liu, Maarten Sap, Ximing Lu, Swabha Swayamdipta, Chandra Bhagavatula, Noah A. Smith, and Yejin Choi. 2021. https://doi.org/10.18653/v1/2021.acl-long.522 DE xperts: Decoding-time controlled text generation with experts and anti-experts . In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th Internatio...
-
[26]
Varvara Logacheva, Daryna Dementieva, Sergey Ustyantsev, Daniil Moskovskiy, David Dale, Irina Krotova, Nikita Semenov, and Alexander Panchenko. 2022. https://aclanthology.org/2022.acl-long.469 P ara D etox: Detoxification with parallel data . In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)...
2022
- [27]
-
[28]
Kevin Meng, David Bau, Alex J Andonian, and Yonatan Belinkov. 2022. Locating and editing factual associations in gpt. In Advances in Neural Information Processing Systems
2022
- [29]
-
[30]
Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, and Shan Carter. 2020. Zoom in: An introduction to circuits. Distill, 5(3):e00024--001
2020
-
[31]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, and 1 others. 2022. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730--27744
2022
- [32]
- [33]
-
[34]
Maarten Sap, Dallas Card, Saadia Gabriel, Yejin Choi, and Noah A. Smith. 2019 a . https://doi.org/10.18653/v1/P19-1163 The risk of racial bias in hate speech detection . In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 1668--1678, Florence, Italy. Association for Computational Linguistics
-
[35]
Maarten Sap, Dallas Card, Saadia Gabriel, Yejin Choi, and Noah A Smith. 2019 b . The risk of racial bias in hate speech detection. In Proceedings of the 57th annual meeting of the association for computational linguistics, pages 1668--1678
2019
- [36]
- [37]
-
[38]
Xavier Suau, Pieter Delobelle, Katherine Metcalf, Armand Joulin, Nicholas Apostoloff, Luca Zappella, and Pau Rodriguez. 2024. Whispering experts: Neural interventions for toxicity mitigation in language models. In International Conference on Machine Learning, pages 46843--46867. PMLR
2024
-
[39]
Guillermo Villate-Castillo, Javier Del Ser, and Borja Sanz Urquijo. 2024. A systematic review of toxicity in large language models: Definitions, datasets, detectors, detoxification methods and challenges
2024
-
[40]
Mengru Wang, Ningyu Zhang, Ziwen Xu, Zekun Xi, Shumin Deng, Yunzhi Yao, Qishen Zhang, Linyi Yang, Jindong Wang, and Huajun Chen. 2024. https://doi.org/10.18653/v1/2024.acl-long.171 Detoxifying large language models via knowledge editing . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pa...
- [41]
- [42]
-
[43]
Yushi Yang, Filip Sondej, Harry Mayne, Andrew Lee, and Adam Mahdi. 2025 b . How does dpo reduce toxicity? a mechanistic neuron-level analysis. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 29512--29531
2025
- [44]
-
[45]
Fred Zhang and Neel Nanda. 2023. Towards best practices of activation patching in language models: Metrics and methods. arXiv preprint arXiv:2309.16042
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [46]
-
[47]
Yiran Zhao, Wenxuan Zhang, Yuxi Xie, Anirudh Goyal, Kenji Kawaguchi, and Michael Shieh. 2025. Understanding and enhancing safety mechanisms of llms via safety-specific neuron. In The Thirteenth International Conference on Learning Representations
2025
- [48]
-
[49]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[50]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.