SpheRoPE: Zero-Shot Optimization-Free 360 Panorama Generation with Spherical RoPE
Pith reviewed 2026-07-01 05:26 UTC · model grok-4.3
The pith
Spherical RoPE adapts rotary position embeddings in pre-trained diffusion models to enforce spherical topology for 360 panorama generation without any training or optimization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
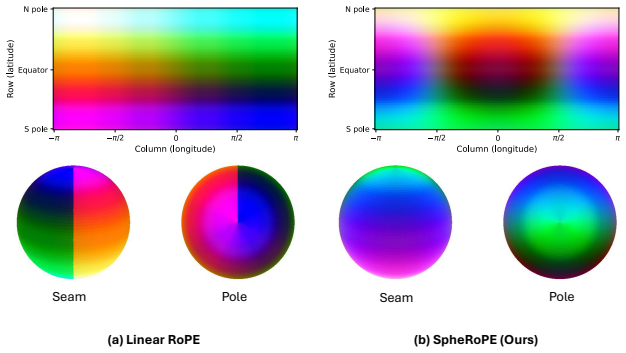
Spherical RoPE replaces standard rotary position embeddings: low-frequency channels are re-parameterized as 3D Cartesian coordinates to natively encode the spherical manifold, while high-frequency channels are harmonically quantized to enforce exact periodicity; when paired with Semantic Distortion classifier-free guidance, this change steers pre-trained diffusion transformers to satisfy equirectangular constraints at inference time without retraining.
What carries the argument
Spherical RoPE, which re-parameterizes rotary position embeddings by using 3D Cartesian coordinates for low-frequency channels and harmonic quantization for high-frequency channels to match the spherical manifold.
If this is right
- The method works across multiple diffusion transformer backbones including Flux.1, Flux.2, and LTX-Video for both images and video.
- No fine-tuning on panoramic data or multi-step optimization is required at inference time.
- The original creative range of the base model is preserved while satisfying spherical topology.
- The approach directly addresses failures in equirectangular projection that standard models exhibit.
Where Pith is reading between the lines
- Similar manifold-specific position encodings could be applied to other non-Euclidean generation tasks such as spherical or hyperbolic outputs.
- The success implies that many existing models hold latent panoramic structure that only needs the correct positional signal to activate.
- Future training runs might incorporate spherical embeddings from the start to reduce reliance on post-hoc fixes.
Load-bearing premise
Pre-trained models already contain enough implicit panoramic knowledge that an embedding change plus guidance is sufficient to enforce correct spherical geometry.
What would settle it
Generate a panorama with the method and check whether the left and right edges match seamlessly when the image is projected onto a sphere; visible seams or mismatched geometry would falsify the claim.
Figures













read the original abstract
We present a zero-shot, training-free and optimization-free framework for generating 360 panoramic images and videos by directly injecting spherical priors into pre-trained diffusion transformers. Existing methods either rely on costly fine-tuning on scarce panoramic data that limits generalization, or leverage multi-step optimization that incurs prohibitive inference latency. We observe that contemporary generative models natively exhibit some panoramic priors from large-scale training. However, these emergent capabilities are insufficient, as the models fundamentally fail to satisfy the rigorous topological constraints imposed by equirectangular projection (ERP). We introduce a zero-shot and optimization-free approach that resolves these constraints at inference time. Spherical RoPE replaces standard rotary position embeddings: low-frequency channels are re-parameterized as 3D Cartesian coordinates to natively encode the spherical manifold, while high-frequency channels are harmonically quantized to enforce exact periodicity. Coupled with complementary Semantic Distortion classifier-free guidance (CFG) that explicitly steers geometry, we avoid retraining and inherit the full creative breadth of state-of-the-art models. Our approach generalizes across diverse backbones and 360 generation modalities. We demonstrate this across text-to-panorama using Flux.1, Flux.2, and LTX-Video backbones, achieving competitive performance against baselines, all while remaining training-free. Project page: https://orhir.github.io/SpheRoPE
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SpheRoPE, a zero-shot, training-free and optimization-free framework for generating 360° panoramic images and videos. It replaces standard rotary position embeddings in pre-trained diffusion transformers (Flux.1, Flux.2, LTX-Video) with Spherical RoPE: low-frequency channels are re-parameterized as 3D Cartesian coordinates to encode the spherical manifold, while high-frequency channels are harmonically quantized to enforce exact periodicity. This is paired with Semantic Distortion classifier-free guidance to steer geometry at inference time, allowing the models to satisfy equirectangular projection constraints without retraining or fine-tuning on panoramic data. The approach is claimed to generalize across backbones and modalities while achieving competitive performance against baselines.
Significance. If the central claim holds, the work would be significant for enabling high-quality 360 generation by steering emergent panoramic priors in large-scale pre-trained models via a targeted, inference-time embedding modification plus guidance term. This sidesteps the data scarcity and latency issues of fine-tuning or optimization-based methods and inherits the creative breadth of existing backbones. The concrete mechanism (Cartesian re-parameterization of low-frequency channels and harmonic quantization) is a strength that could be directly tested.
major comments (2)
- Abstract: the claim of 'achieving competitive performance against baselines' is unsupported by any quantitative metrics, tables, ablation studies, or specific comparisons in the provided text, which is load-bearing for evaluating whether the Spherical RoPE change plus guidance term actually enforces spherical topology on the tested backbones.
- Method description (Spherical RoPE): the re-parameterization of low-frequency channels as 3D Cartesian coordinates and harmonic quantization of high-frequency channels are described at a high level without explicit equations, integration into the rotary embedding formula, or derivation showing how periodicity and manifold encoding are achieved, preventing verification of internal consistency.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below and commit to revisions that strengthen the submission without altering its core claims.
read point-by-point responses
-
Referee: Abstract: the claim of 'achieving competitive performance against baselines' is unsupported by any quantitative metrics, tables, ablation studies, or specific comparisons in the provided text, which is load-bearing for evaluating whether the Spherical RoPE change plus guidance term actually enforces spherical topology on the tested backbones.
Authors: We acknowledge that the abstract's performance claim requires explicit support in the submission. The full manuscript includes qualitative results and backbone-specific demonstrations, but we agree that quantitative backing is needed for the claim to be verifiable. In the revised version we will add a results table reporting standard metrics (e.g., FID, CLIP similarity, geometric consistency scores) against the cited baselines, plus a short ablation on the contribution of Spherical RoPE and Semantic Distortion CFG. revision: yes
-
Referee: Method description (Spherical RoPE): the re-parameterization of low-frequency channels as 3D Cartesian coordinates and harmonic quantization of high-frequency channels are described at a high level without explicit equations, integration into the rotary embedding formula, or derivation showing how periodicity and manifold encoding are achieved, preventing verification of internal consistency.
Authors: We agree that the current description is insufficient for independent verification. The revised manuscript will expand the Method section with the full mathematical formulation: the precise mapping of low-frequency channels to 3D Cartesian coordinates on the sphere, the harmonic quantization rule for high-frequency channels, the modified rotary embedding equation, and a short derivation showing how these choices enforce exact 2π periodicity along longitude while preserving the spherical manifold geometry. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces Spherical RoPE as an inference-time replacement for standard rotary embeddings in pre-trained diffusion transformers, with low-frequency channels re-parameterized as 3D Cartesian coordinates and high-frequency channels harmonically quantized, plus a complementary guidance term. This is framed as a direct architectural modification that leverages emergent priors without retraining, fitting, or optimization. No equations, parameters, or derivations are shown that reduce the claimed output to a self-referential definition or fitted input. No load-bearing self-citations, uniqueness theorems imported from the authors' prior work, or ansatzes smuggled via citation are present in the provided description. The central claim remains an independent proposal whose internal consistency does not collapse to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introducing claude opus 4.7, 2026
Anthropic. Introducing claude opus 4.7, 2026. URL https://www.anthropic.com/news/ claude-opus-4-7. Accessed: 2026-05-06
2026
-
[2]
Multidiffusion: Fusing diffusion paths for controlled image generation
Omer Bar-Tal, Lior Yariv, Yaron Lipman, and Tali Dekel. Multidiffusion: Fusing diffusion paths for controlled image generation. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors,International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, Proceedings of Ma...
2023
-
[3]
Sutherland, Michael Arbel, and Arthur Gretton
Mikolaj Binkowski, Danica J. Sutherland, Michael Arbel, and Arthur Gretton. Demystifying MMD gans. In6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net, 2018. URLhttps://openreview. net/forum?id=r1lUOzWCW
2018
-
[4]
Eleonora Brivio, Silvia Serino, Erica Negro Cousa, Andrea Zini, Giuseppe Riva, and Gianluca De Leo. Virtual reality and 360° panorama technology: a media comparison to study changes in sense of presence, anxiety, and positive emotions.Virtual Real., 25(2):303–311, 2021. doi: 10.1007/S10055-020-00453-7. URLhttps://doi.org/10.1007/s10055-020-00453-7
-
[5]
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. In2021 IEEE/CVF International Con- ference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021, pages 9630–9640. IEEE, 2021. doi: 10.1109/ICCV48922.2021.00951. URL http...
-
[7]
Text2light: Zero-shot text-driven hdr panorama generation
Zhaoxi Chen, Guangcong Wang, and Ziwei Liu. Text2light: Zero-shot text-driven hdr panorama generation. ACM Transactions on Graphics (TOG), 41(6):1–16, 2022
2022
-
[8]
Geometry fidelity for spherical images
Anders Christensen, Nooshin Mojab, Khushman Patel, Karan Ahuja, Zeynep Akata, Ole Winther, Mar González-Franco, and Andrea Colaco. Geometry fidelity for spherical images. In Ales Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattler, and Gül Varol, editors,Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-...
-
[9]
In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021
Xin Deng, Hao Wang, Mai Xu, Yichen Guo, Yuhang Song, and Li Yang. Lau-net: Latitude adaptive upscaling network for omnidirectional image super-resolution. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021, pages 9189–9198. Computer Vision Foundation / IEEE, 2021. doi: 10.1109/CVPR46437.2021.00907. URL https...
-
[10]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: pre-training of deep bidirectional transformers for language understanding. In Jill Burstein, Christy Doran, and Thamar Solorio, editors,Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAAC...
-
[12]
Mengyang Feng, Jinlin Liu, Miaomiao Cui, and Xuansong Xie. Diffusion360: Seamless 360 degree panoramic image generation based on diffusion models.CoRR, abs/2311.13141, 2023. doi: 10.48550/ ARXIV .2311.13141. URLhttps://doi.org/10.48550/arXiv.2311.13141
-
[13]
Image as a world: Generating interactive world from single image via panoramic video generation
Dongnan Gui, Xun Guo, Wengang Zhou, and Yan Lu. Image as a world: Generating interactive world from single image via panoramic video generation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=PA47sKU8CU
2025
-
[15]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V . N. Vishwanathan, and Roman Garnett, editors,Advances in Neural Information Processing Systems ...
2017
-
[16]
Classifier-free diffusion guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. InNeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications
2021
-
[17]
Gritsenko, William Chan, Mohammad Norouzi, and David J
Jonathan Ho, Tim Salimans, Alexey A. Gritsenko, William Chan, Mohammad Norouzi, and David J. Fleet. Video diffusion models. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems 35: Annual Con- ference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans...
2022
-
[18]
LoRA: Low-rank adaptation of large language models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations, 2022. URLhttps://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[19]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. Vbench: Comprehensive benchmark suite for video generative models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seat...
-
[20]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Dype: Dynamic position extrapolation for ultra high resolution diffusion.CoRR, abs/2510.20766, 2025
Noam Issachar, Guy Yariv, Sagie Benaim, Yossi Adi, Dani Lischinski, and Raanan Fattal. Dype: Dynamic position extrapolation for ultra high resolution diffusion.CoRR, abs/2510.20766, 2025. doi: 10.48550/ ARXIV .2510.20766. URLhttps://doi.org/10.48550/arXiv.2510.20766
-
[22]
Cubediff: Repurposing diffusion-based image models for panorama generation
Nikolai Kalischek, Michael Oechsle, Fabian Manhardt, Philipp Henzler, Konrad Schindler, and Federico Tombari. Cubediff: Repurposing diffusion-based image models for panorama generation. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum? id=M2SsqpxGtc
2025
-
[23]
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. MUSIQ: multi-scale image quality transformer. In2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021, pages 5128–5137. IEEE, 2021. doi: 10.1109/ICCV48922.2021.00510. URLhttps://doi.org/10.1109/ICCV48922.2021.00510. 11
-
[24]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Amt: All-pairs multi-field transforms for efficient frame interpolation
Zhen Li, Zuo-Liang Zhu, Ling-Hao Han, Qibin Hou, Chun-Le Guo, and Ming-Ming Cheng. Amt: All-pairs multi-field transforms for efficient frame interpolation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9801–9810, 2023
2023
-
[26]
Aoming Liu, Zhong Li, Zhang Chen, Nannan Li, Yi Xu, and Bryan A. Plummer. Panofree: Tuning-free holistic multi-view image generation with cross-view self-guidance. In Ales Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattler, and Gül Varol, editors,Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October...
-
[27]
Dynamicscaler: Seamless and scalable video generation for panoramic scenes
Jinxiu Liu, Shaoheng Lin, Yinxiao Li, and Ming-Hsuan Yang. Dynamicscaler: Seamless and scalable video generation for panoramic scenes. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 6144–
2025
-
[28]
Computer Vision Foundation / IEEE, 2025. doi: 10.1109/CVPR52734.2025.00576. URL https://openaccess.thecvf.com/content/CVPR2025/html/Liu_DynamicScaler_Seamless_ and_Scalable_Video_Generation_for_Panoramic_Scenes_CVPR_2025_paper.html
-
[29]
Fit: Flexible vision transformer for diffusion model
Zeyu Lu, Zidong Wang, Di Huang, Chengyue Wu, Xihui Liu, Wanli Ouyang, and Lei Bai. Fit: Flexible vision transformer for diffusion model. In Ruslan Salakhutdinov, Zico Kolter, Katherine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austri...
2024
-
[30]
Beyond the Frame: Generating 360 Panoramic Videos from Perspective Videos
Rundong Luo, Matthew Wallingford, Ali Farhadi, Noah Snavely, and Wei-Chiu Ma. Beyond the frame: Generating 360° panoramic videos from perspective videos.CoRR, abs/2504.07940, 2025. doi: 10.48550/ ARXIV .2504.07940. URLhttps://doi.org/10.48550/arXiv.2504.07940
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.07940 2025
-
[31]
What makes for text to 360-degree panorama generation with stable diffusion? InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16555–16564, 2025
Jinhong Ni, Chang-Bin Zhang, Qiang Zhang, and Jing Zhang. What makes for text to 360-degree panorama generation with stable diffusion? InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16555–16564, 2025
2025
-
[32]
BIPS: bi- modal indoor panorama synthesis via residual depth-aided adversarial learning
Changgyoon Oh, Wonjune Cho, Yujeong Chae, Daehee Park, Lin Wang, and Kuk-Jin Yoon. BIPS: bi- modal indoor panorama synthesis via residual depth-aided adversarial learning. In Shai Avidan, Gabriel J. Brostow, Moustapha Cissé, Giovanni Maria Farinella, and Tal Hassner, editors,Computer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October...
-
[33]
Minho Park, Taewoong Kang, Jooyeol Yun, Sungwon Hwang, and Jaegul Choo. Spherediff: Tuning-free 360° static and dynamic panorama generation via spherical latent representation. In Sven Koenig, Chad Jenkins, and Matthew E. Taylor, editors,Fortieth AAAI Conference on Artificial Intelligence, Thirty-Eighth Conference on Innovative Applications of Artificial ...
-
[34]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 4172–4182. IEEE,
2023
-
[35]
doi: 10.1109/ICCV51070.2023.00387. URL https://doi.org/10.1109/ICCV51070.2023. 00387
-
[36]
NTK-aware scaled RoPE
Bowen Peng. NTK-aware scaled RoPE. 2023. https://www.reddit.com/r/LocalLLaMA/comments/ 14lz7j5/
2023
-
[37]
YaRN: Efficient context window extension of large language models
Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. YaRN: Efficient context window extension of large language models. InThe Twelfth International Conference on Learning Representations,
-
[38]
URLhttps://openreview.net/forum?id=wHBfxhZu1u
-
[39]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Marina Meila and Tong Zhang, editors, 12 Proceedings of the 38th International Conference on Mach...
2021
-
[41]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 10674–10685. IEEE, 2022. doi: 10.1109/CVPR52688.2022.01042. URLhttps://doi.org/10.1109/CVP...
-
[42]
In���� �������� ���������� �� �������� ������ ��� ������� ����������� ������
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation. InIEEE/CVF Con- ference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17- 24, 2023, pages 22500–22510. IEEE, 2023. doi: 10.1109/CVPR52729....
-
[43]
Photorealistic text-to- image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to- image diffusion models with deep language understanding.Advances in neural information processing systems, 35:36479–36494, 2022
2022
-
[44]
Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen
Tim Salimans, Ian J. Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. In Daniel D. Lee, Masashi Sugiyama, Ulrike von Luxburg, Isabelle Guyon, and Roman Garnett, editors,Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, December...
2016
-
[45]
Jianlin Su, Murtadha H. M. Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024. doi: 10.1016/ J.NEUCOM.2023.127063. URLhttps://doi.org/10.1016/j.neucom.2023.127063
-
[46]
Xiancheng Sun, Mai Xu, Shengxi Li, Senmao Ma, Xin Deng, Lai Jiang, and Gang Shen. Spher- ical manifold guided diffusion model for panoramic image generation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 5824–5834. Computer Vision Foundation / IEEE, 2025. doi: 10.1109/CVPR52734.202...
-
[47]
Imagine360: Immersive 360 video generation from perspective anchor
Jing Tan, Shuai Yang, Tong Wu, Jingwen He, Yuwei Guo, Ziwei Liu, and Dahua Lin. Imagine360: Immersive 360 video generation from perspective anchor. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=BcYfsMMpV1
2025
-
[49]
Spherical position encoding for transformers.CoRR, abs/2310.04454, 2023
Eren Unlu. Spherical position encoding for transformers.CoRR, abs/2310.04454, 2023. doi: 10.48550/ ARXIV .2310.04454. URLhttps://doi.org/10.48550/arXiv.2310.04454
-
[51]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Isabelle Guyon, Ulrike von Luxburg, Samy Bengio, Hanna M. Wallach, Rob Fergus, S. V . N. Vishwanathan, and Roman Garnett, editors,Advances in Neural Information Processing Systems 30: Annual Conference...
2017
-
[52]
Conditional panoramic image generation via masked autoregressive modeling
Chaoyang Wang, Xiangtai Li, Lu Qi, Xiaofan Lin, Jinbin Bai, Qianyu Zhou, and Yunhai Tong. Conditional panoramic image generation via masked autoregressive modeling. InThe Thirty-ninth Annual Confer- ence on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id= 2YxtR50mho. 13
2025
-
[53]
360pant: Training-free text-driven 360-degree panorama-to-panorama translation
Hai Wang and Jing-Hao Xue. 360pant: Training-free text-driven 360-degree panorama-to-panorama translation. InIEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2025, Tucson, AZ, USA, February 26 - March 6, 2025, pages 212–221. IEEE, 2025. doi: 10.1109/W ACV61041.2025.00031. URLhttps://doi.org/10.1109/WACV61041.2025.00031
work page doi:10.1109/w 2025
-
[54]
Customizing 360-degree panoramas through text-to-image diffusion models
Hai Wang, Xiaoyu Xiang, Yuchen Fan, and Jing-Hao Xue. Customizing 360-degree panoramas through text-to-image diffusion models. InIEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2024, Waikoloa, HI, USA, January 3-8, 2024, pages 4921–4931. IEEE, 2024. doi: 10.1109/ W ACV57701.2024.00486. URLhttps://doi.org/10.1109/WACV57701.2024.00486
-
[56]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Qian Wang, Weiqi Li, Chong Mou, Xinhua Cheng, and Jian Zhang. 360dvd: Controllable panorama video generation with 360-degree video diffusion model. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 6913–6923. IEEE, 2024. doi: 10.1109/CVPR52733.2024.00660. URLhttps://doi.org/10.1109/CVPR5...
-
[57]
Zidong Wang, Zeyu Lu, Di Huang, Cai Zhou, Wanli Ouyang, and Lei Bai. Fitv2: Scalable and improved flexible vision transformer for diffusion model.CoRR, abs/2410.13925, 2024. doi: 10.48550/ARXIV .2410. 13925. URLhttps://doi.org/10.48550/arXiv.2410.13925
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[58]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems 35: Annual Conference on Neu- ...
2022
-
[59]
360Anything: Geometry-Free Lifting of Images and Videos to 360{\deg}
Ziyi Wu, Daniel Watson, Andrea Tagliasacchi, David J Fleet, Marcus A Brubaker, and Saurabh Saxena. 360anything: Geometry-free lifting of images and videos to 360 {\deg}.arXiv preprint arXiv:2601.16192, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[60]
Panowan: Lifting diffusion video generation models to 360 with latitude/longitude-aware mechanisms
Yifei Xia, Shuchen Weng, Siqi Yang, Jingqi Liu, Chengxuan Zhu, Minggui Teng, Zijian Jia, Han Jiang, and Boxin Shi. Panowan: Lifting diffusion video generation models to 360 with latitude/longitude-aware mechanisms. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[61]
Diffpano: Scalable and consistent text to panorama generation with spherical epipolar-aware diffusion
Weicai Ye, Chenhao Ji, Zheng Chen, Junyao Gao, Xiaoshui Huang, Song-Hai Zhang, Wanli Ouyang, Tong He, Cairong Zhao, and Guofeng Zhang. Diffpano: Scalable and consistent text to panorama generation with spherical epipolar-aware diffusion. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URLhttps://openreview.net/forum?i...
2024
-
[62]
In: 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Cheng Zhang, Qianyi Wu, Camilo Cruz Gambardella, Xiaoshui Huang, Dinh Phung, Wanli Ouyang, and Jianfei Cai. Taming stable diffusion for text to 360° panorama image generation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 6347–6357. IEEE, 2024. doi: 10.1109/CVPR52733.2024.00607. URL ...
-
[63]
Panodit: Panoramic videos generation with diffusion transformer
Muyang Zhang, Yuzhi Chen, Rongtao Xu, Changwei Wang, Jinming Yang, Weiliang Meng, Jianwei Guo, Huihuang Zhao, and Xiaopeng Zhang. Panodit: Panoramic videos generation with diffusion transformer. In Toby Walsh, Julie Shah, and Zico Kolter, editors,Thirty-Ninth AAAI Conference on Artificial Intelligence, Thirty-Seventh Conference on Innovative Applications ...
-
[64]
Diffcollage: Parallel generation of large content with diffusion models
Qinsheng Zhang, Jiaming Song, Xun Huang, Yongxin Chen, and Ming-Yu Liu. Diffcollage: Parallel generation of large content with diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, pages 10188–10198. IEEE,
2023
-
[65]
In���� �������� ���������� �� �������� ������ ��� ������� ����������� ������
doi: 10.1109/CVPR52729.2023.00982. URL https://doi.org/10.1109/CVPR52729.2023. 00982
-
[66]
Riflex: A free lunch for length extrapolation in video diffusion transformers
Min Zhao, Guande He, Yixiao Chen, Hongzhou Zhu, Chongxuan Li, and Jun Zhu. Riflex: A free lunch for length extrapolation in video diffusion transformers. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Maharaj, Kiri Wagstaff, and Jerry Zhu, editors, 14 Forty-second International Conference on Machine Learning, ICML ...
2025
-
[67]
Dian Zheng, Cheng Zhang, Xiao-Ming Wu, Cao Li, Chengfei Lv, Jian-Fang Hu, and Wei- Shi Zheng. Panorama generation from nfov image done right. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 21610–21619. Computer Vision Foundation / IEEE, 2025. doi: 10.1109/CVPR52734.2025. 02013. URL ...
-
[68]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a- judge with mt-bench and chatbot arena. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors,Advances in Neural I...
2023
-
[69]
Le Zhuo, Ruoyi Du, Han Xiao, Yangguang Li, Dongyang Liu, Rongjie Huang, Wenze Liu, Xiangyang Zhu, Fu-Yun Wang, Zhanyu Ma, Xu Luo, Zehan Wang, Kaipeng Zhang, Lirui Zhao, Si Liu, Xiangyu Yue, Wanli Ouyang, Yu Qiao, Hongsheng Li, and Peng Gao. Lumina-next : Making lumina-t2x stronger and faster with next-dit. In Amir Globersons, Lester Mackey, Danielle Belgr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.